



前言
文本嵌入和重排序是自然语言处理和信息检索应用中的关键组件。
高质量的嵌入能够使模型捕捉文本之间的语义关系,而有效的重排序机制则确保最相关的结果被优先展示。
Qwen3 Embedding、 Qwen3 Rerank模型基于 Qwen3 基础模型的密集版本构建,提供 0.6B、4B 和 8B 参数三种尺寸。
模型架构
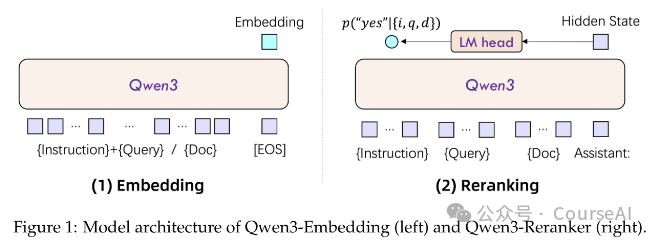
Embedding模型
- 使用带有因果注意力的 LLMs,并在输入序列末尾添加 [EOS] 令牌,最终嵌入从最后一层对应 [EOS] 令牌的隐藏状态中得出。
- 当输入一个查询 q\和文档 d时,模型首先将它们与指令i连接成一个单一的输入上下文,然后通过 LLMs 进行处理。
- 模型的输出是基于指令i的查询和文档的相似性分数,该分数通过计算 LLMs 最后一层对应 [EOS] 令牌的隐藏状态来得出。
- 这种基于指令的嵌入方式使得模型能够根据不同的任务需求调整嵌入的语义表示,从而提高在各种下游任务中的适用性和性能。
- 基于 InfoNCE 框架的改进对比损失函数进行优化。该损失函数定义为:
其中 s(·, ·) 为相似性函数(使用余弦相似性),为温度参数,为归一化因子,聚合正样本对与各种负样本对之间的相似性分数。
- 借助动态 Mask 策略(当某个批内示例与正例的相似度过高或本身就是正例时,将相应相似度置为 0,以减小“伪负例”对模型的干扰)。
ReRanker模型
- 采用点式重排序策略,将文本相似性评估任务转化为一个二元分类问题,即判断文档 d是否满足查询 q的要求。
- 为了实现这一目标,模型在输入上下文中包含了指令 i,并使用 LLMs 的聊天模板来处理输入。
- 对于重排序模型,优化监督微调(SFT)损失函数:
其中 表示由 LLM 赋予的概率,标签 l 对于正文档为“yes”,对于负文档为“no”。
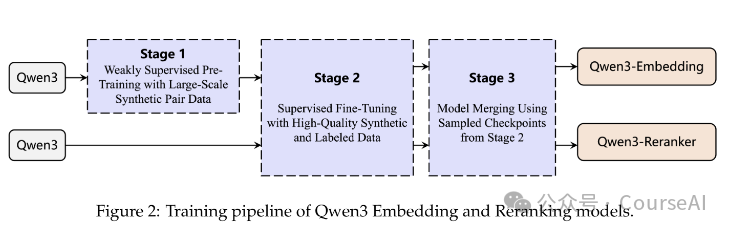
训练方案
-
stage1: 弱监督预训练(Weakly Supervised Pre-Training)
-
利用大规模“合成”数据进行初始训练,以提升模型的泛化能力与多任务适应性。
-
将原始多语种文档转化为“查询-文档”对。
-
例如,在“Configuration”阶段为每段文档挑选角色(Character)、问题类型(Question_Type)、难度(Difficulty);
-
再在“Query Generation”阶段根据上述配置生成用户角度的查询句。
-
最终合成约 1.5 亿 对多任务弱监督训练数据,涵盖信息检索、比对挖掘(bitext mining)、分类、语义相似度等多种任务类型。
-
stage2: 有监督微调(Supervised Fine-Tuning)
-
在弱监督预训练模型的基础上,利用“小而精”的有监督数据进一步提升模型性能
-
在弱监督阶段合成的 1.5 亿对数据中,先对每对样本计算余弦相似度(cosine similarity),保留相似度大于 0.7 的高质量样本,约 1200 万 对,作为辅助有监督训练数据。
-
对嵌入模型沿用 InfoNCE 损失进行微调;重排序模型直接采用(二分类交叉熵)
-
stage3: 模型合并(Model Merging)
-
在有监督微调阶段保存的多个检查点(checkpoints)之间,通过球面线性插值(slerp)技术,将不同阶段或不同任务偏好模型进行“合并”,提高最终模型的鲁棒性与稳健性。
-
球面线性插值(slerp):将多个检查点的参数按一定权重合成,生成新的“混合”模型。
实战
import torch
import torch.nn.functional as F
from torch import Tensor
from modelscope import AutoTokenizer, AutoModel
def last_token_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery:{query}'
def tokenize(tokenizer, input_texts, eod_id, max_length):
batch_dict = tokenizer(input_texts, padding=False, truncation=True, max_length=max_length-2)
for seq, att in zip(batch_dict["input_ids"], batch_dict["attention_mask"]):
seq.append(eod_id)
att.append(1)
batch_dict = tokenizer.pad(batch_dict, padding=True, return_tensors="pt")
return batch_dict
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'What is the capital of China?'),
get_detailed_instruct(task, 'Explain gravity')
]
# No need to add instruction for retrieval documents
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun."
]
input_texts = queries + documents
tokenizer = AutoTokenizer.from_pretrained('Qwen/Qwen3-Embedding-8B', padding_side='left')
model = AutoModel.from_pretrained('Qwen/Qwen3-Embedding-8B')
# We recommend enabling flash_attention_2 for better acceleration and memory saving.
# model = AutoModel.from_pretrained('Qwen/Qwen3-Embedding-8B', attn_implementation="flash_attention_2", torch_dtype=torch.float16).cuda()
eod_id = tokenizer.convert_tokens_to_ids("<|endoftext|>")
max_length = 8192
# Tokenize the input texts
batch_dict = tokenize(tokenizer, input_texts, eod_id, max_length)
batch_dict.to(model.device)
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T)
print(scores.tolist())
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的
核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

















 2474
2474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









