




Qwen3 Rerank模型:开源重排序领域的突破性进展

引言
2025年6月,阿里巴巴通义千问团队正式发布了Qwen3系列的重要组件——Qwen3-Reranker重排序模型。作为Qwen3大模型家族的核心成员,该模型凭借创新的架构设计、卓越的性能表现和全面的多语言支持,迅速在信息检索领域引起广泛关注。Qwen3-Reranker不仅在多项权威评测中刷新SOTA成绩,更以开源免费的方式向全球开发者开放,为构建高效、精准的检索系统提供了强大工具。
核心优势解析
1. 性能全面领先
Qwen3-Reranker在多个评测基准上展现出显著优势,其中4B参数版本在MTEB-R(多语言文本嵌入基准)中获得69.76分,8B版本更是达到77.45分的高分,远超BGE、GTE等主流开源模型。特别在代码检索任务上,Qwen3-Reranker-4B和8B版本得分均突破81.0,几乎是BGE模型的两倍性能。
2. 强大的多语言能力
支持119种自然语言及编程语言,包括中文、英文、阿拉伯语、日语等全球主流语言,以及Python、Java、C++等代码语言。跨语言检索误差降低30%,中文场景下以73.84分领先国际竞品,为全球化应用提供坚实基础。
3. 灵活的模型尺寸选择
提供0.6B、4B和8B三种参数规模,满足不同场景需求:
- 0.6B:轻量级模型,仅需2GB内存即可运行,适合边缘设备和移动端部署
- 4B:性能与效率平衡,适合中等规模云端部署,100文档排序延迟<100ms(A100)
- 8B:旗舰级性能,适合高精度检索场景,多语言检索能力突出
4. 创新的长文本处理能力
突破32K tokens上下文限制,采用双块注意力机制确保长文档(如法律合同、科研论文)语义连贯性,特别优化了法律、医疗等专业领域的长文本排序稳定性。
技术创新架构
1. 单塔交叉编码器结构
Qwen3-Reranker采用创新的单塔交叉编码架构,将用户查询与候选文档拼接输入,通过动态计算交互特征输出相关性得分,相比传统双塔模型能更精准捕捉细粒度语义关联。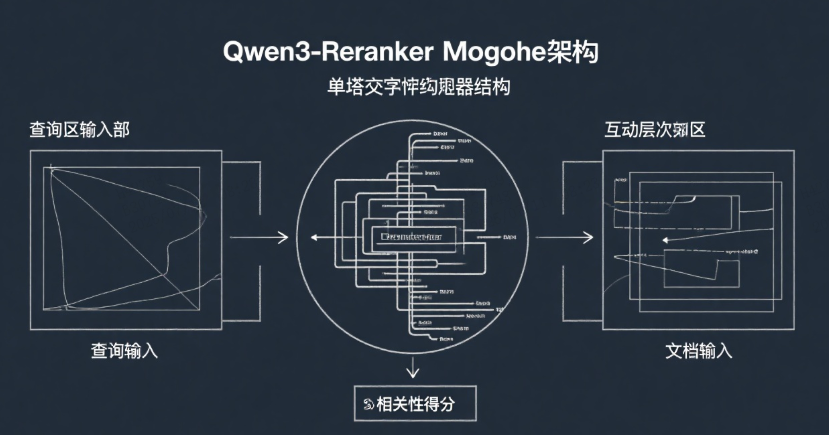
2. 多阶段训练范式
- 阶段一:利用Qwen3-32B基础模型生成1.5亿对多任务弱监督数据
- 阶段二:结合MS MARCO等高质量标注数据进行监督微调
- 阶段三:采用球面线性插值(slerp)技术合并多个模型检查点,提升鲁棒性
3. 指令感知能力
支持自定义指令模板,可针对特定任务(如"医疗报告分类")或领域优化性能,实测精度提升3%-5%,特别适合金融、法律等专业场景。
典型应用场景
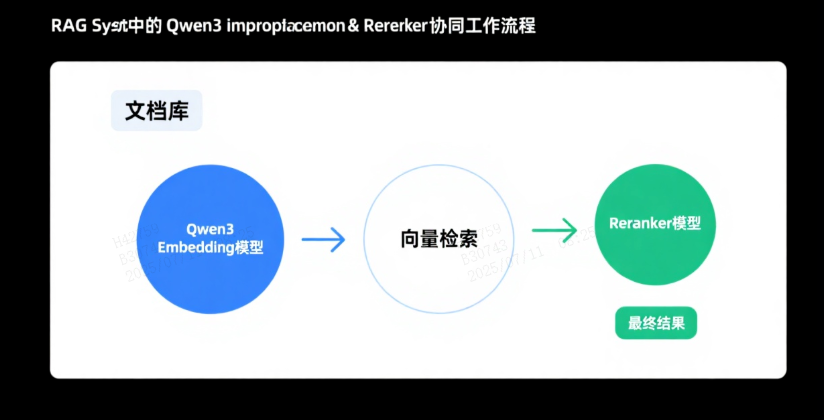
1. RAG系统优化
在检索增强生成(RAG)架构中,Qwen3-Reranker与Qwen3-Embedding形成黄金组合:
- Embedding模型负责从海量文档中快速召回候选结果
- Reranker模型对候选文档进行精细排序,提升相关性
2. 搜索引擎优化
显著提升电商商品搜索、学术论文检索的准确性,某跨境电商案例显示搜索转化率提升22%,用户检索时间减少35%。
3. 代码检索与开发
支持根据自然语言描述查找代码片段,代码检索准确率领先行业,帮助开发者快速定位功能模块,提高开发效率。
4. 专业领域应用
在法律案例检索、医疗文献分析等专业场景中表现出色,能够精准识别专业术语和复杂语义关系。
部署与可用性
Qwen3-Reranker系列模型已完全开源,遵循Apache 2.0许可证,可免费商用。开发者可通过Hugging Face、ModelScope及GitHub获取模型权重,或通过阿里云百炼平台API直接调用。
硬件需求参考:
- 0.6B版本:仅需2GB内存,可在树莓派或手机端运行
- 4B版本:建议16GB显存(如RTX 4090)
- 8B版本:最低24GB显存(如A100),支持AWQ量化后显存需求降至14GB
结论与展望
Qwen3-Reranker的发布标志着开源重排序模型进入新阶段,其在性能、效率和多语言支持方面的突破,为构建下一代信息检索系统提供了强大动力。随着模型的广泛应用,我们期待看到其在智能搜索、推荐系统、智能客服等领域的创新应用。
未来,Qwen3系列模型将进一步扩展多模态表征能力,探索图像、音频等模态的嵌入技术,推动跨模态语义理解的发展,为AI应用开辟更多可能性。


















 439
439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









