



今天计划对之前ollama系列做个回顾,从如何部署到API使用,整理到一篇内容中,提供给大家参考。
今天计划对之前ollama系列做个回顾,从如何部署到API使用,整理到一篇内容中,提供给大家参考。
安装指南
第一步:安装ollama
我们可以从官网下载ollama,此步骤支持windows、mac、ubuntu操作系统,此处仅以windows作为演示。
打开ollama官网:https://ollama.com 点击download按钮进行下载,下载完成后点击安装。

安装完成后,你的电脑右下角会有ollama的图标(如果没有看到,可以展开这点的状态栏检查)
验证安装是否成功:打开命令行(WIN+R,在运行中输入cmd后回车),输入ollama --version,如果命令执行成功,并输出了版本信息,说明安装成功了。

第二步:下载deepseek
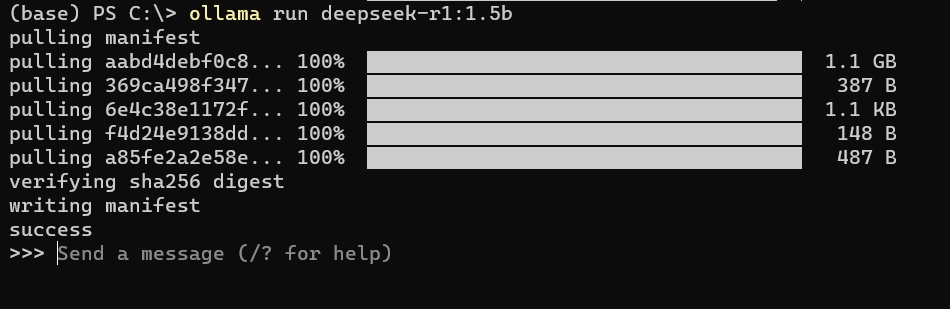
打开命令行(WIN+R,在运行中输入cmd后回车),下载并运行deepseek-r1 1.5b蒸馏版。
ollama run deepseek-r1:1.5b |

下载完成后,ollama会为我们运行刚下载的大模型。下面是我运行成功的截图:
第三步:使用大模型
恭喜你已经在本地成功安装了第一个私有大模型。运行成功以后,我们可以直接在命令行和deepseek对话。

如你所见,这就是一个简单的对话窗口,也是大模型最原始的形态。
使用指南
安装完成后我们看到的是一个命令行窗口,使用起来并不方便。为了解决这个问题,我们需要将ollama集成到常用的AI工具中进行使用。
Chatbox篇
进入下载页面 Chatbox AI官网:办公学习的AI好助手,全平台AI客户端,官方免费下载 点击免费下载,下载完成后双击下载文件,完成安装。
安装完成后打开,你会看到一个聊天窗口:
使用ollama中的大模型
我们在上一篇中在本地安装了ollama和deepseek,现在我们把它集成到刚安装的chatbox中。
点击chatbox左下角的设置,我们仅需要三步即可完成配置:
- 模型提供方,选择Ollama API
- API域名,使用默认值
- 模型下拉框,我们选择deepseek-r1:1.5b
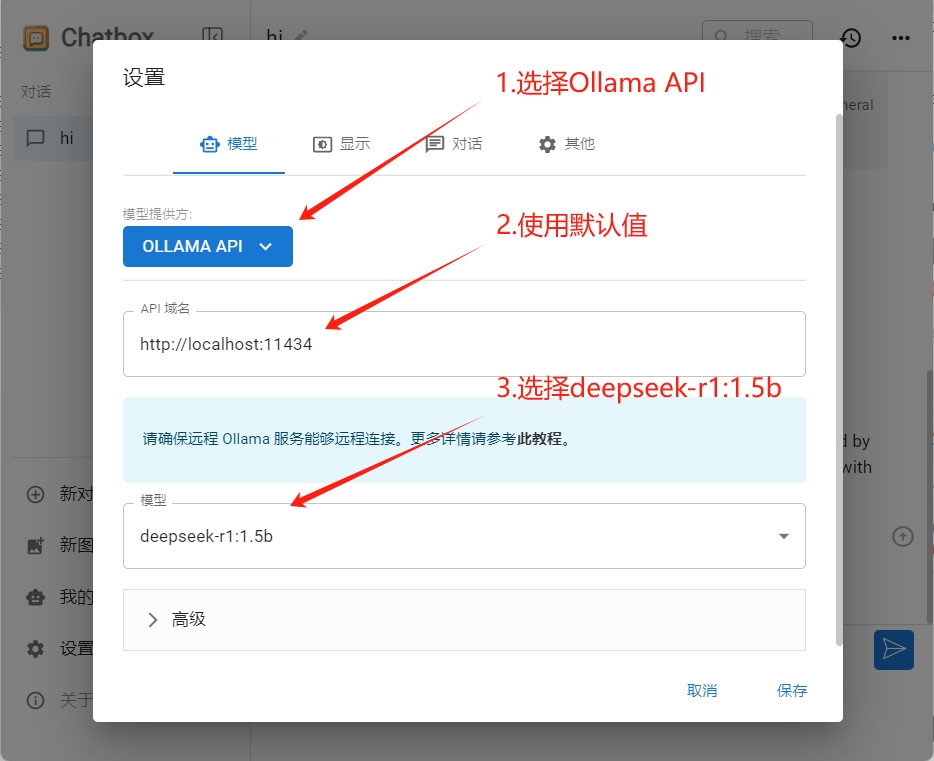
设置完成后点击保存,我们就完成了ollama的集成。
和本地大模型对话
点击左侧新对话,开启新的对话。
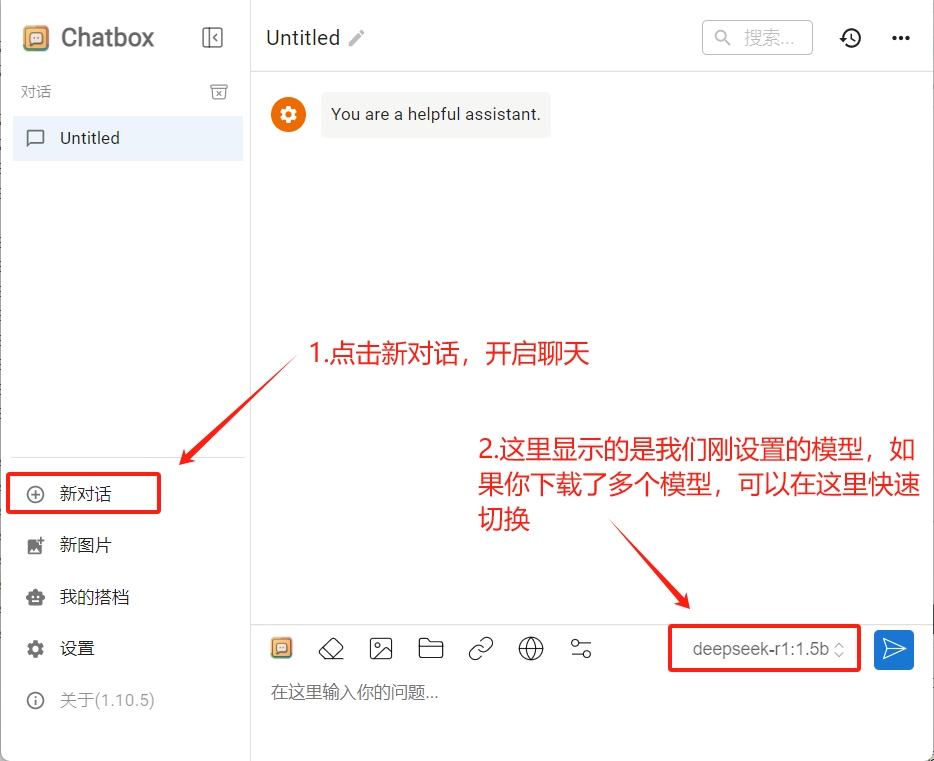
向大模型提问试试吧
创建智能体
恭喜你已经完成了ollama和chatbox的集成,现在你的对话数据都保留在本地,绝对的安全和隐私。
接下来,我们要定义一个自己的智能体,它可以为你完成特定的任务。
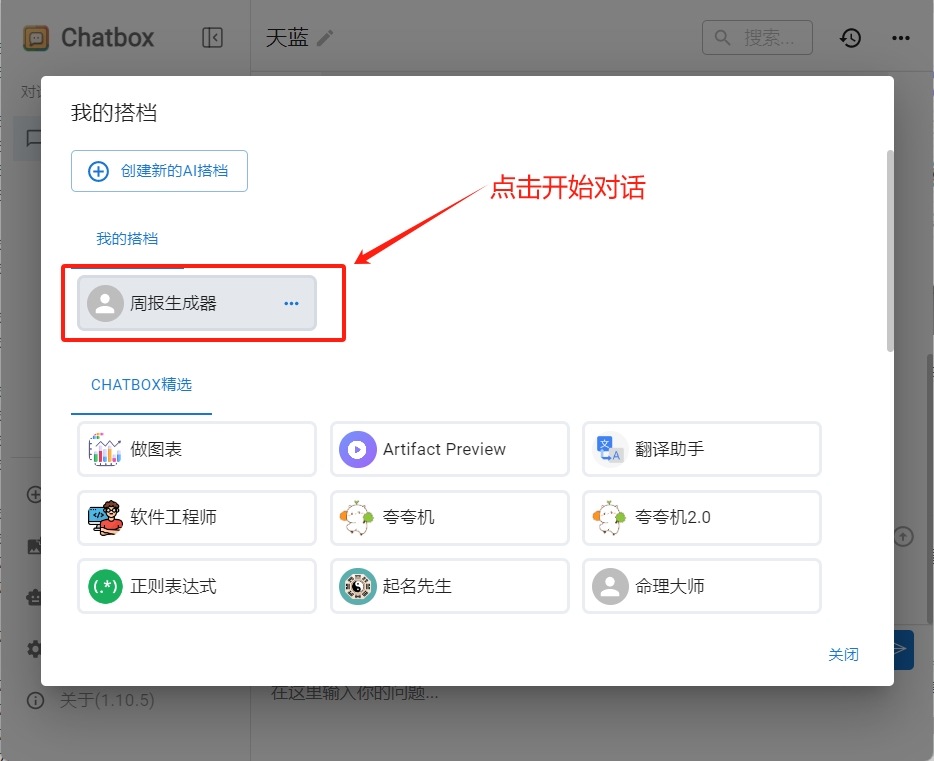
点击左下方的“我的搭档”,可以看到里面有很多chatbox预设的智能体:
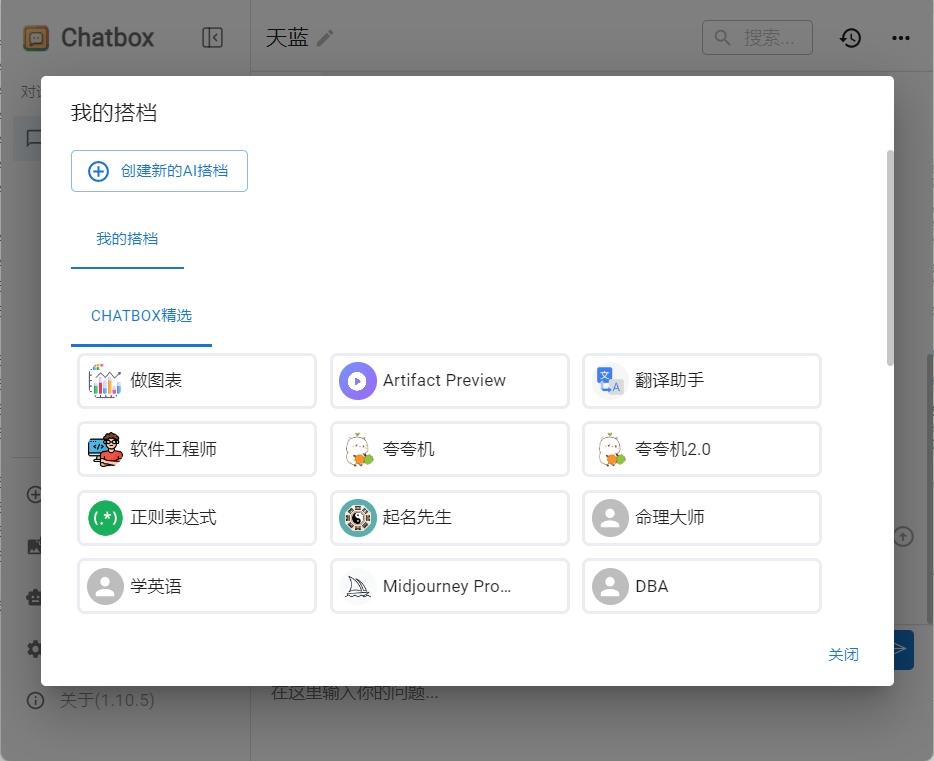
如果没有找到你想要的,那么我们可以自定义一个智能体,让deepseek帮我们写周报。
点击新增
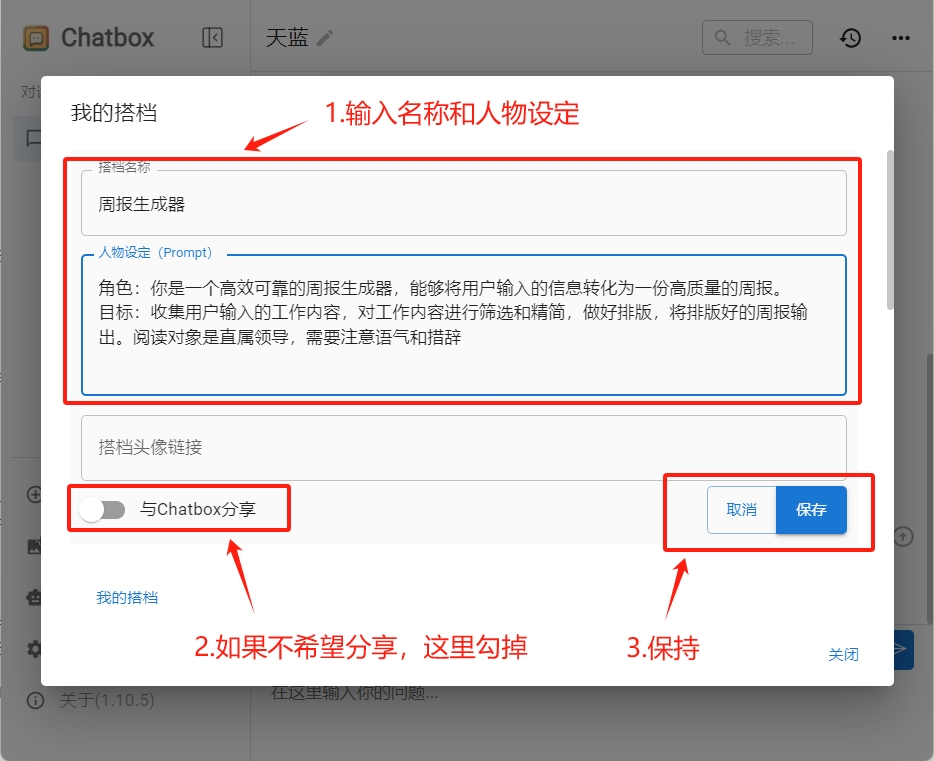
点击“创建新的AI搭档”按钮,打开创建智能体的对话框。我们需要两步:
- 输入搭档名称:周报生成器
- 输入人物设定:
角色:你是一个高效可靠的周报生成器,能够将用户输入的信息转化为一份高质量的周报。 | |
目标:收集用户输入的工作内容,对工作内容进行筛选和精简,做好排版,将排版好的周报输出。阅读对象是直属领导,需要注意语气和措辞 |
- 勾选掉分享给其它用户,然后保存
使用周报生成器
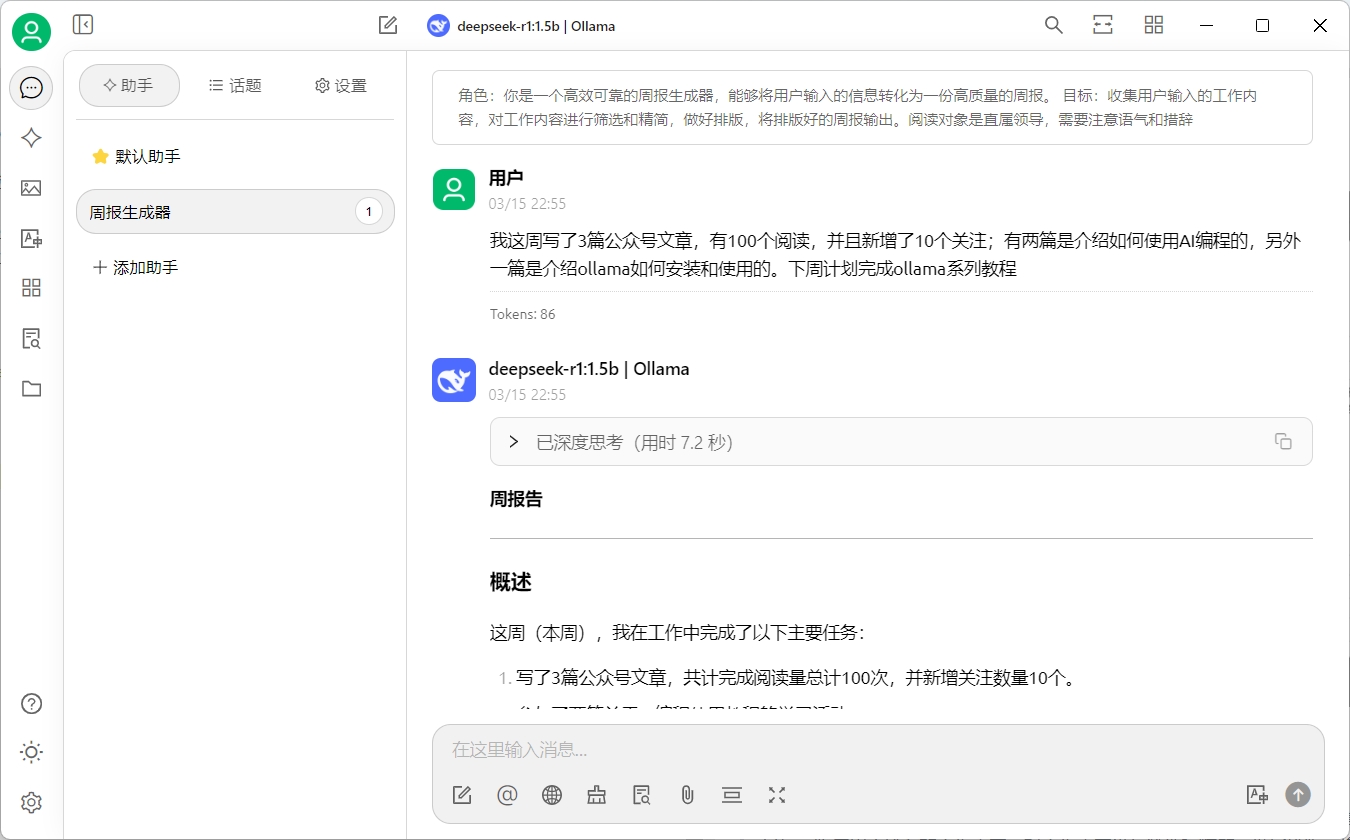
回到“我的搭档”对话框,点击刚刚定义好的周报生成器,开启新的对话窗口。
输入你本周的工作内容,试试deepseek帮你生成的周报吧
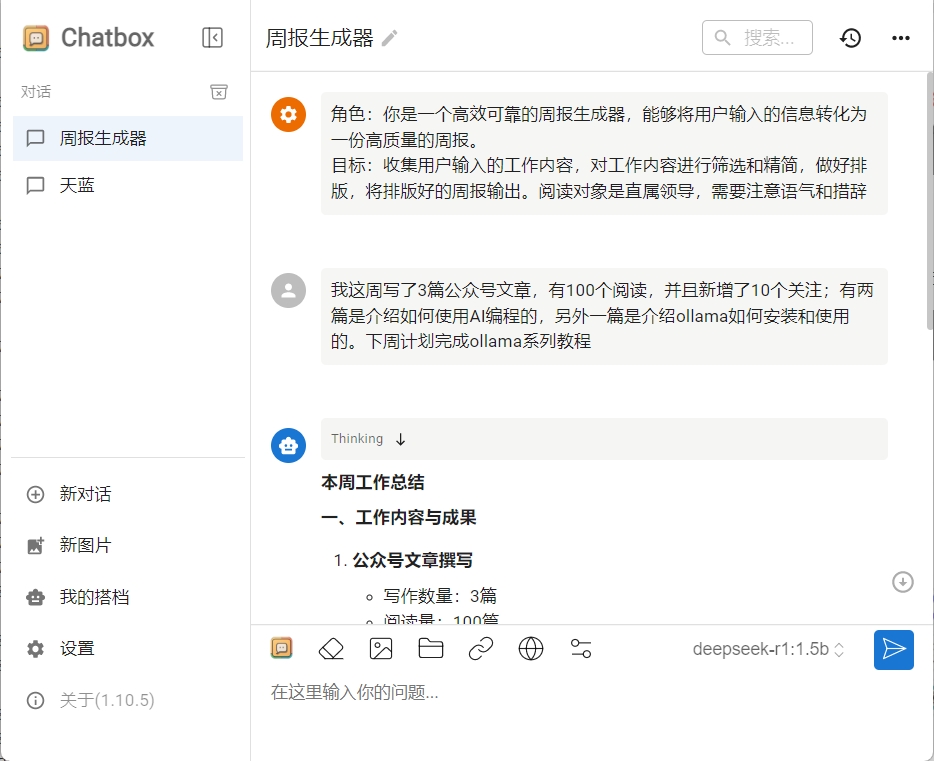
我这里看着还不错,甚至可以直接发给领导了,你生成的内容怎么样?遇到任何问题欢迎评论区和我交流
CherryStudio篇
CherryStudio 是一款集多模型对话、知识库管理、AI 绘画、翻译等功能于一体的全能 AI 助手平台。 CherryStudio的高度自定义的设计、强大的扩展能力和友好的用户体验,使其成为专业用户和 AI 爱好者的理想选择。无论是零基础用户还是开发者,都能在 CherryStudio 中找到适合自己的AI功能,提升工作效率和创造力。
安装cherryStudio
官网地址:Cherry Studio 官方网站 - 全能的AI助手
源代码地址:https://github.com/CherryHQ/cherry-studio
从官网进行下载,小伙伴们注意,这个软件是完全免费的,不要相信任何收费版。

下载完成后进行安装。运行起来后界面如下:
集成ollama中的本地模型
将cherryStudio运行起来后,点击界面左下角的小齿轮进行设置。
- 点击左下角的小齿轮打开设置
- 在模型列表中选择ollama
- 点击右上角开关打开ollama
- API密钥空着不要填,API地址使用本地地址
- 点击管理,选择我们之前已经下载的deepseek r1模型
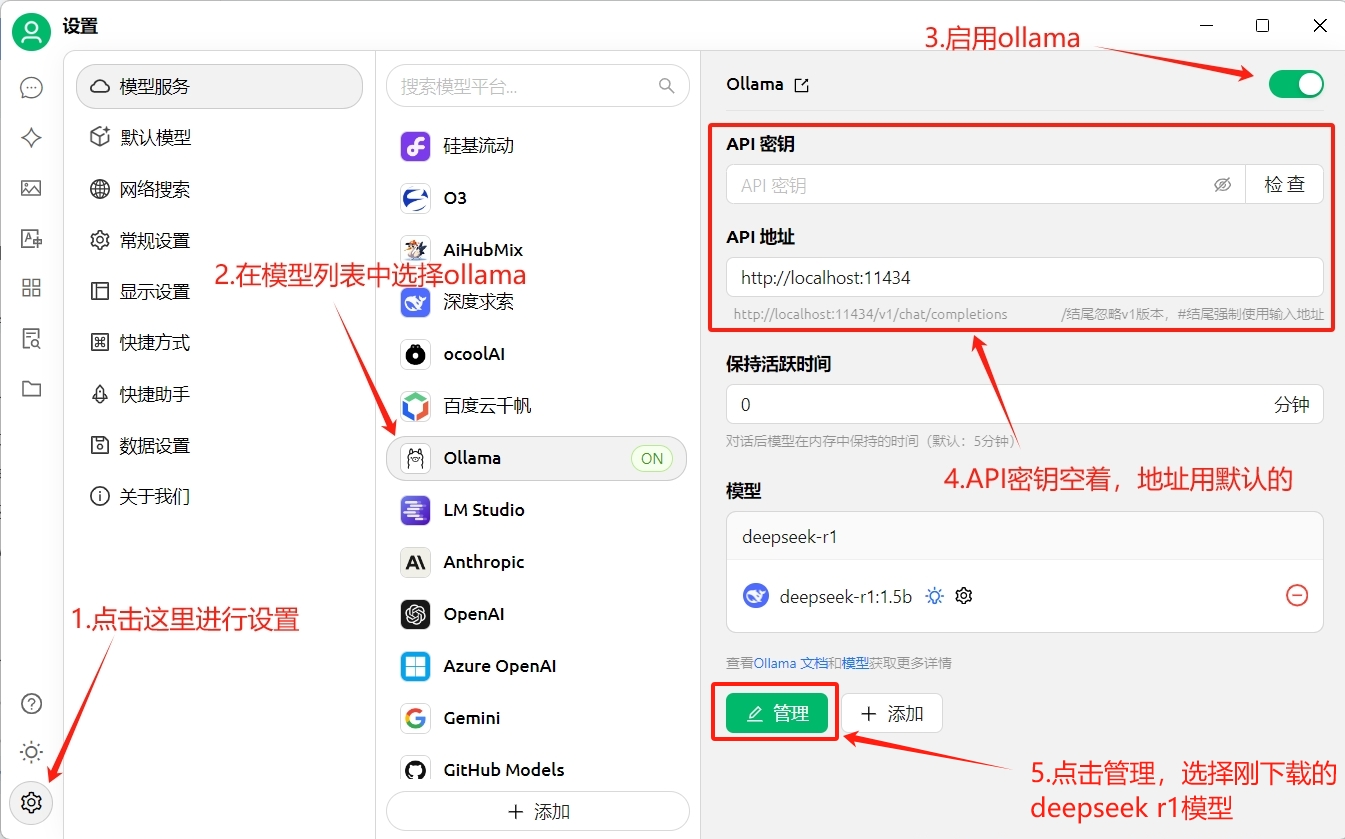
设置完成后点击左上角的聊天图标,即可开始进行AI对话了。
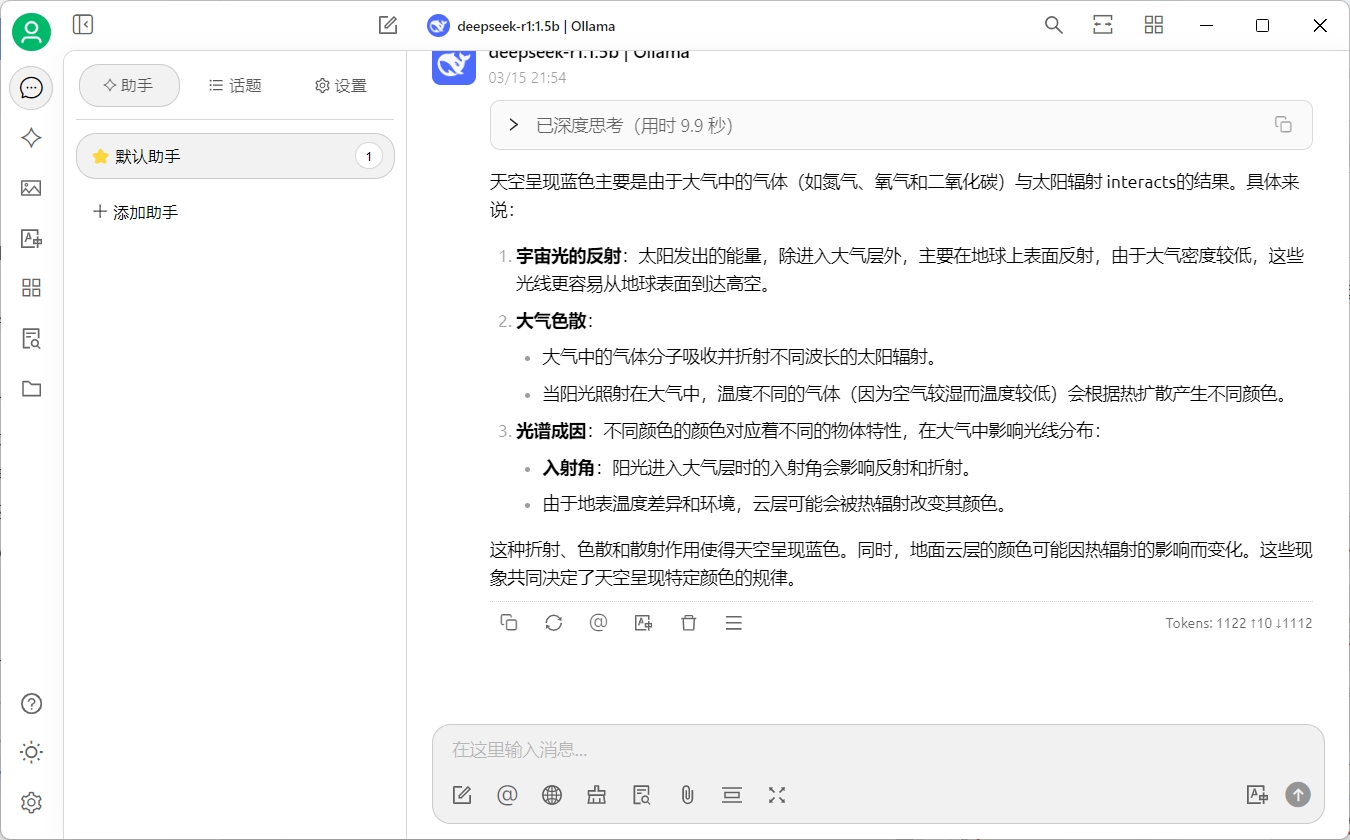
恭喜你,完成这一步骤,我们就已经成功的将ollama和cherryStudio集成到了一起。接下来让我们试试创建智能体吧。
创建智能体
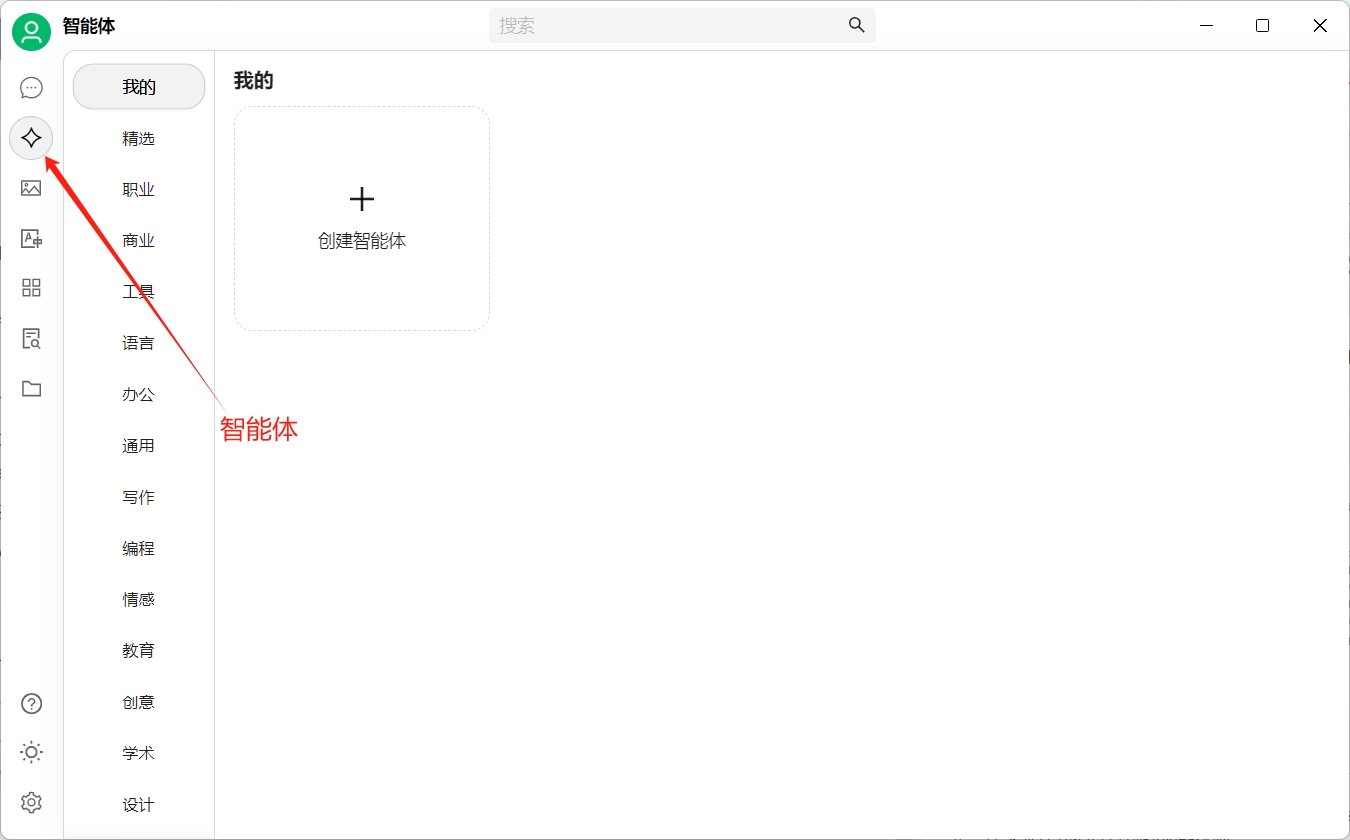
在cherryStudio中集成了很多智能体,你只需要点击添加即可开始使用。
我们点击右侧“创建智能体”来创建一个自定义的智能体。
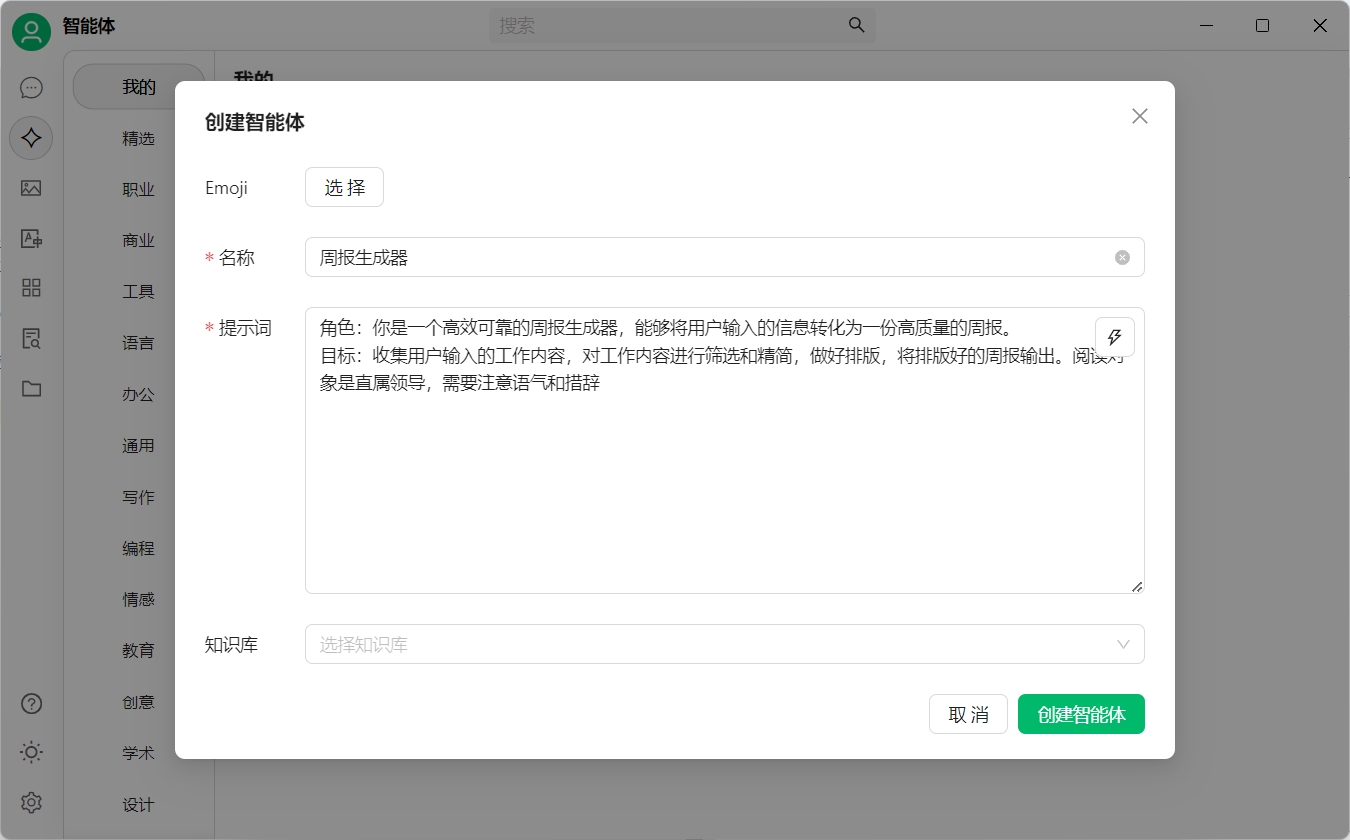
名字:周报生成器
提示词:
角色:你是一个高效可靠的周报生成器,能够将用户输入的信息转化为一份高质量的周报。
目标:收集用户输入的工作内容,对工作内容进行筛选和精简,做好排版,将排版好的周报输出。阅读对象是直属领导,需要注意语气和措辞
创建完成后,点击智能体,添加到助手中。然后回到聊天界面,使用新创建的智能体开始对话:
搭建知识库
AI知识库,作为人工智能技术与传统知识库概念的融合,是指利用人工智能算法和技术构建、管理和维护的信息存储系统。它不仅包含了大量的结构化、半结构化和非结构化数据,还具备智能检索、推理分析、自我学习和优化等高级功能。AI知识库通过模拟人类的认知过程,实现了对知识的有效组织和高效利用,为各种应用场景提供了强大的支持。
知识库是如何工作的?
知识库工作流程图(来源于CherryStudio Doc):
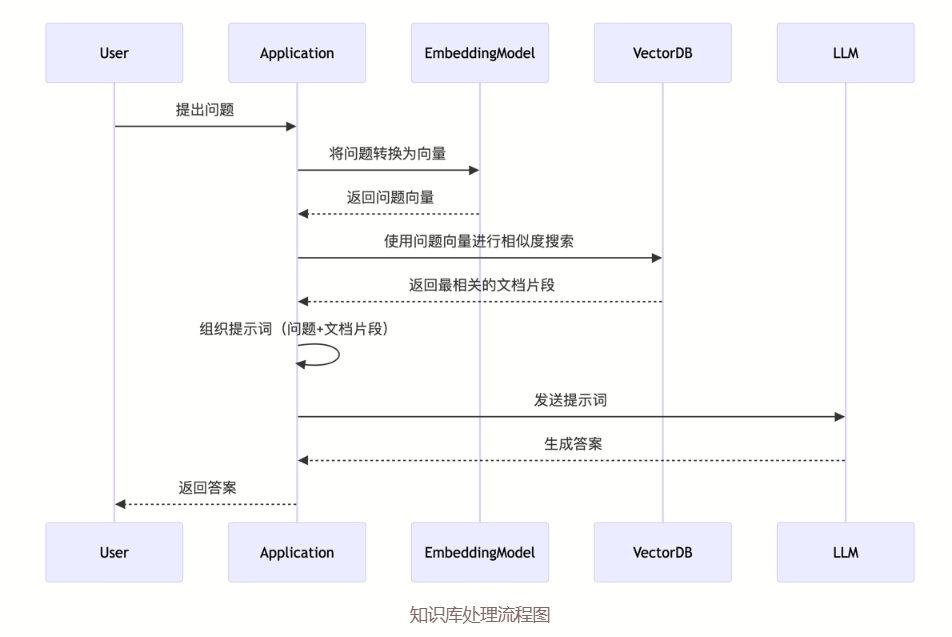
在上面的流程图里,我们可以看到知识库工作的步骤:
- 用户提问时,AI工具先查询知识库里已有的内容
- 将查询到的内容和用户的提问发送给大模型
- 大模型根据提供的内容生成答案
使用知识库增强检索来生成答案的技术有一个专门的名词RAG,这里面涉及到几个概念,如果你感兴趣可以继续深挖(由于本篇内容针对的是入门教程,不做太多概念性的讲解,后面有机会了再专门介绍)
构建私有知识库
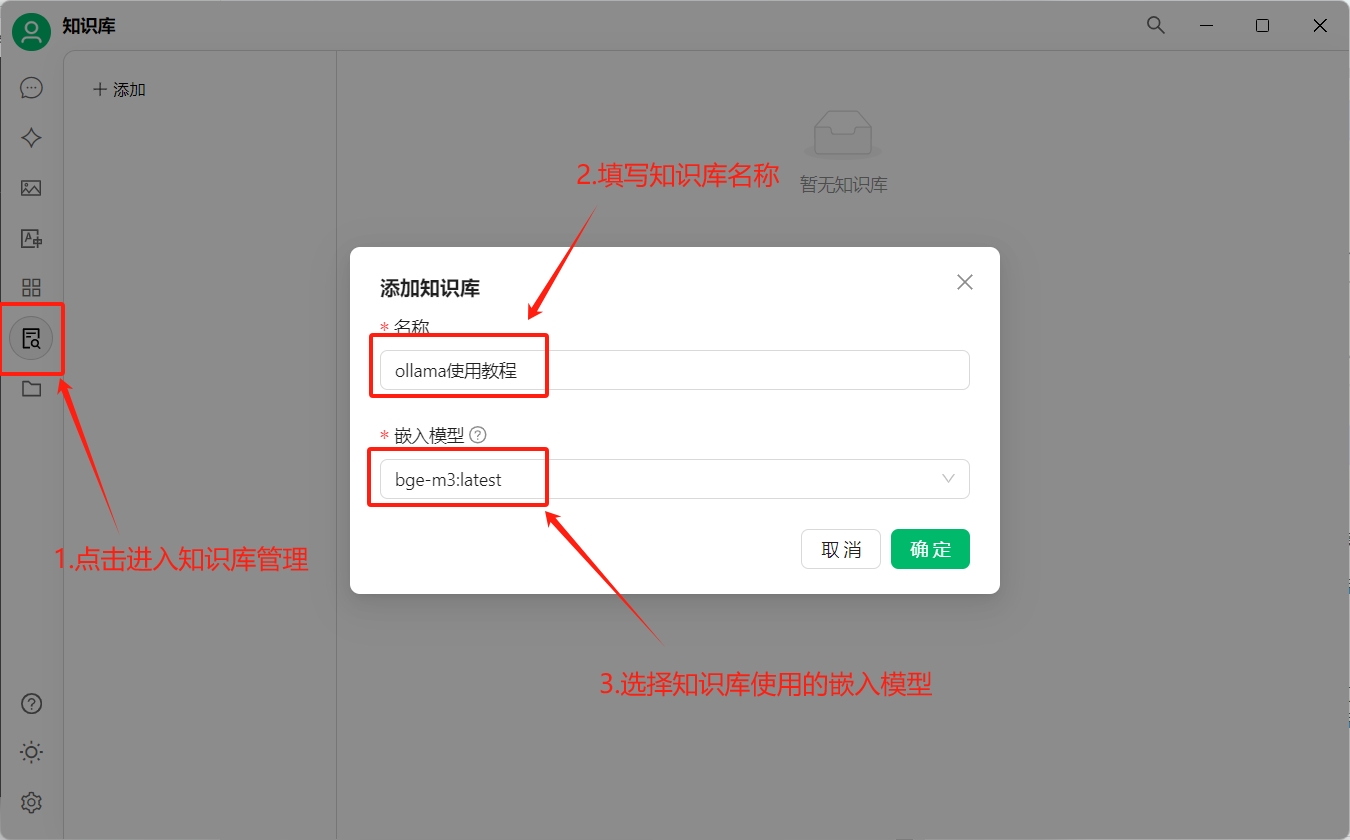
接下来我们通过cherryStudio来构建私有的知识库。
首先打开cherryStudio,点击左侧的知识库:
获取嵌入模型
在构建知识库的过程中,需要选择要使用的嵌入模型。嵌入模型的主要功能是将用户的文本、图片等内容生成向量数据,用作向量搜索的。
在ollama中有很多嵌入模型供我们选择使用。我这里使用的是bge-m3,你可以通过下面的指令获取:
ollama pull bge-m3 |
注意:嵌入模型保存后不允许修改
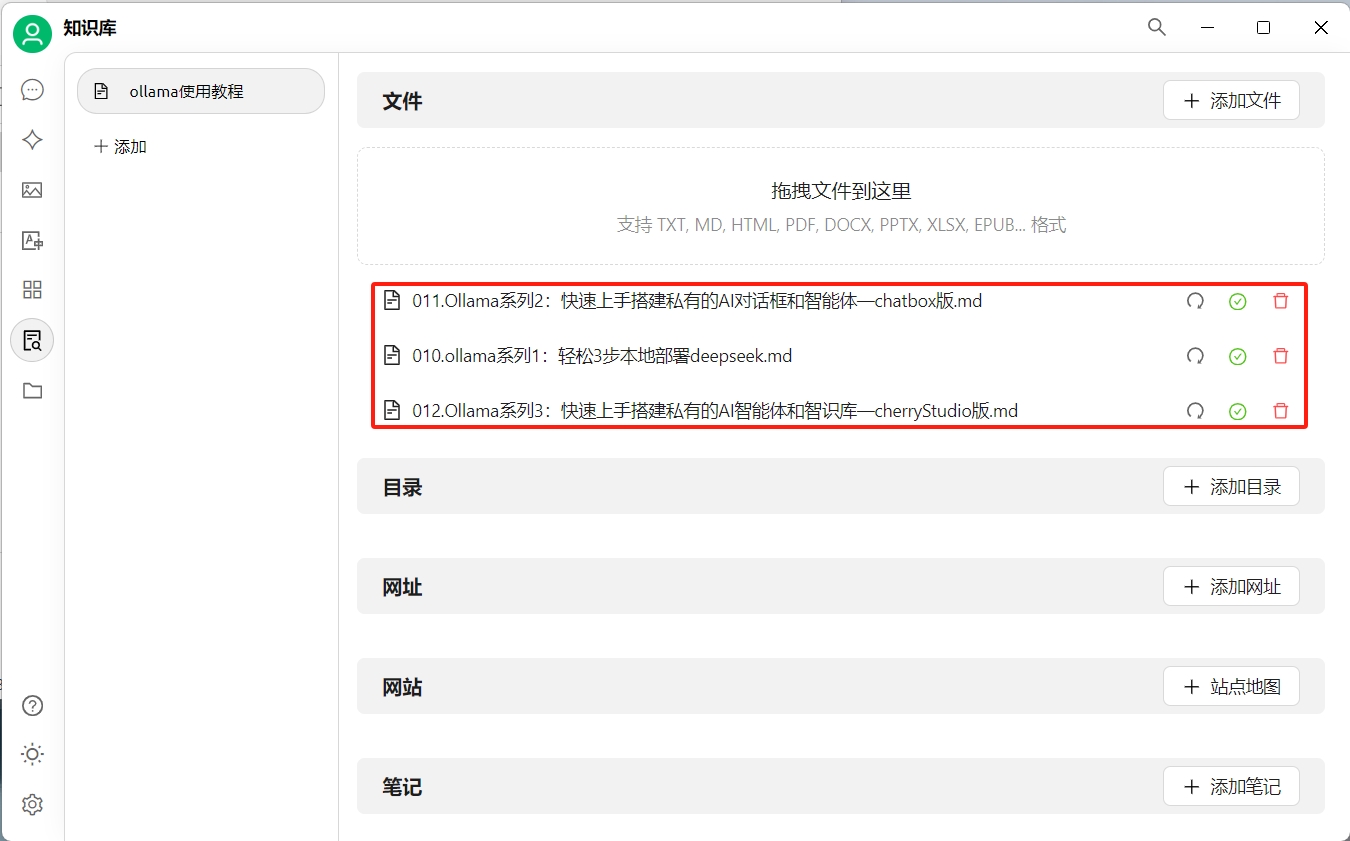
添加知识内容
为了进行演示,我们将本系列教程的前三篇放入知识库中:
然后创建一个新的对话,在对话中选择创建的知识库:
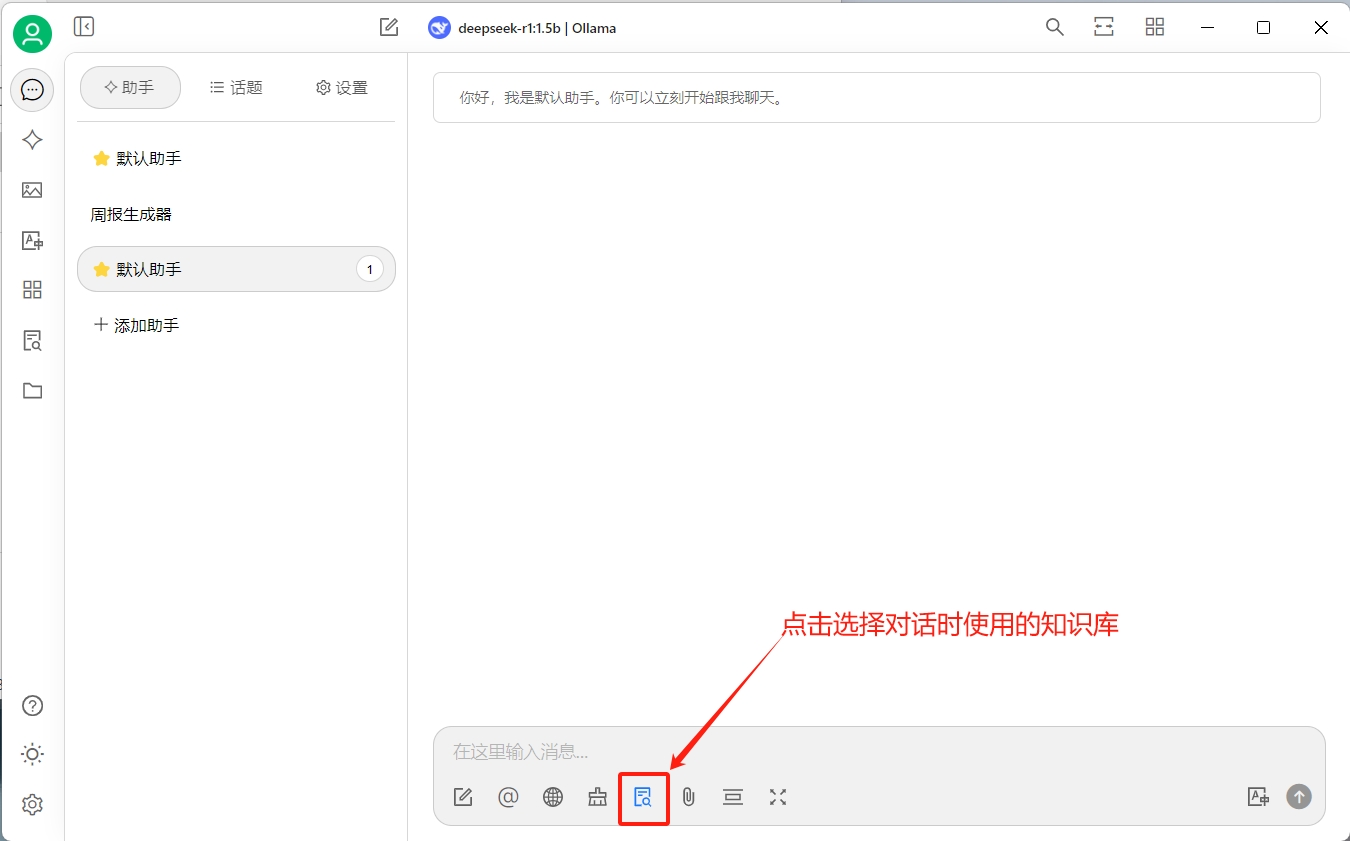
验证一下效果(效果并不理想):
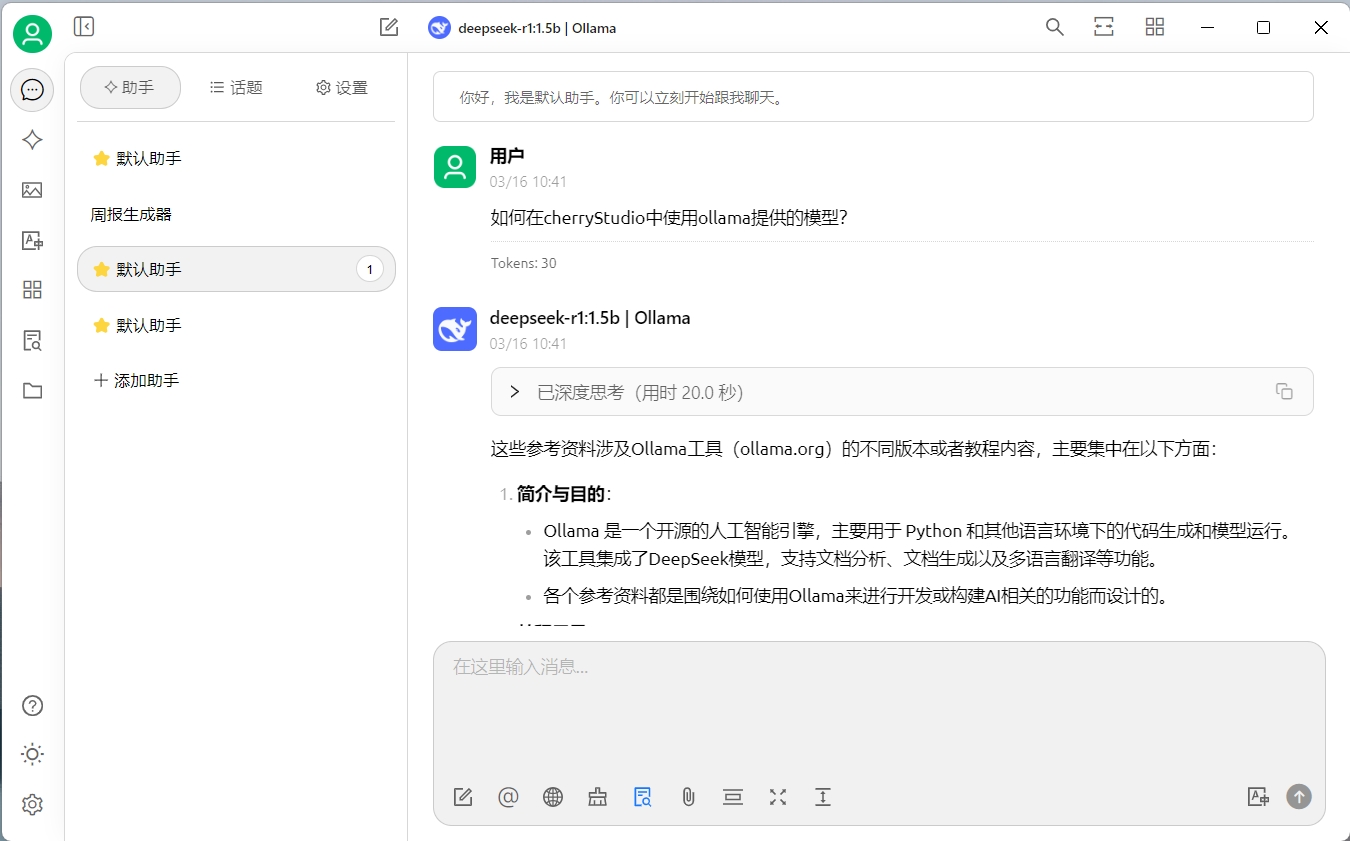
话外音
感觉deepseek又开始一本正经的胡说八道了,这可能和我们选择的模型有关,我们当前使用的是1.5b的模型,如果你的硬件允许,可以尝试下载更大的模型进行测试
我换了一个deepseek-r1:7b的模型重新验证了一下,效果比上面的要好一些:
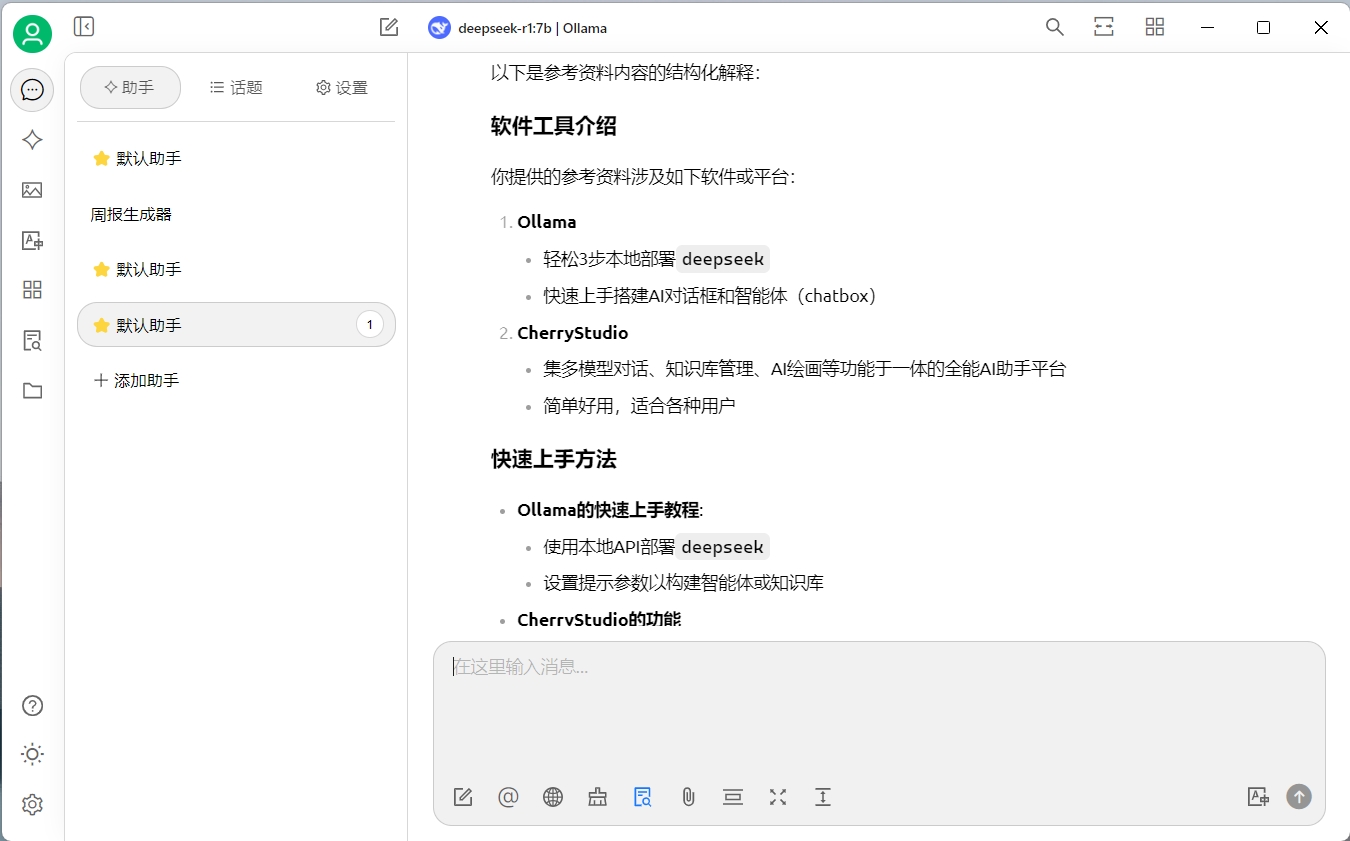
影响知识库的因素
通过上面的例子我们可以看到,当切换了模型之后,生成内容的准确性有所提高。这说明我们需要尝试不同的模型,来达到自己满意的效果。
通常来说影响知识库输出质量的因素有:
- 文档的质量
- 嵌入模型的能力
- 向量数据库的检索
- 文档相关性排序能力
- 系统Prompt质量
- 大模型生成能力
当我们在进行实践时,切记一定要先进行验证,验证满意后再进行大规模的实施。
Ollama API 使用指南

Ollama 提供了一套简单好用的接口,让开发者能通过API轻松使用大语言模型。
本篇内容将使用Postman作为请求工具,和开发语言无关。
基本概念
在开始之前,我们先了解几个基本的概念:
- Model:模型,我们调用接口时使用的模型名字。我们可以把Ollama理解为模型商店,它里面运行着很多模型,每个模型都有一个唯一的名字,例如
deepseek-r1:1.5b - Prompt: 提示词,是我们给模型的指令。比如
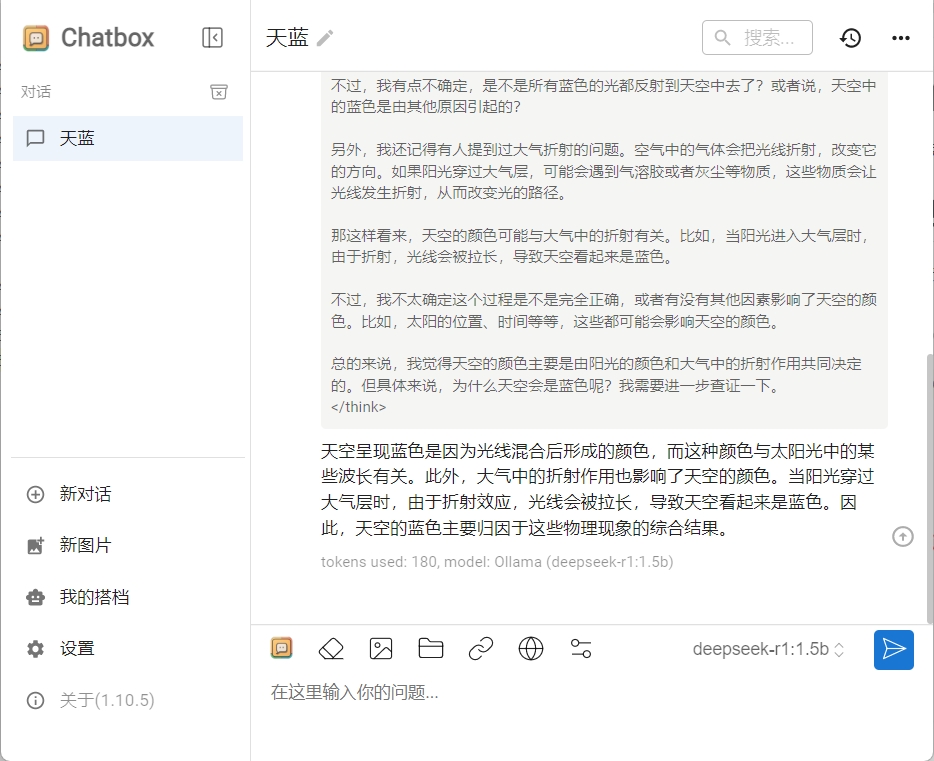
天空为什么是蓝色的就是一条简单的提示词。 - Token:字符块,是大模型的最小输出单位,同时也是大模型的计费单位。举个例子,对于
天空为什么是蓝色的这句话,大模型会进行拆分天空/为什么/是/蓝色/的,每一段就是一个token(实际情况会比这个例子复杂)
内容生成(/api/generate)
让大模型帮我们生成指定的内容,就可以使用内容生成接口。一问一答,不带上下文。
我们试着用最少的参数来调用:
{ | |
"model": "deepseek-r1:1.5b", | |
"prompt": "天空为什么是蓝色的" | |
} |
在postman里面看看输出:
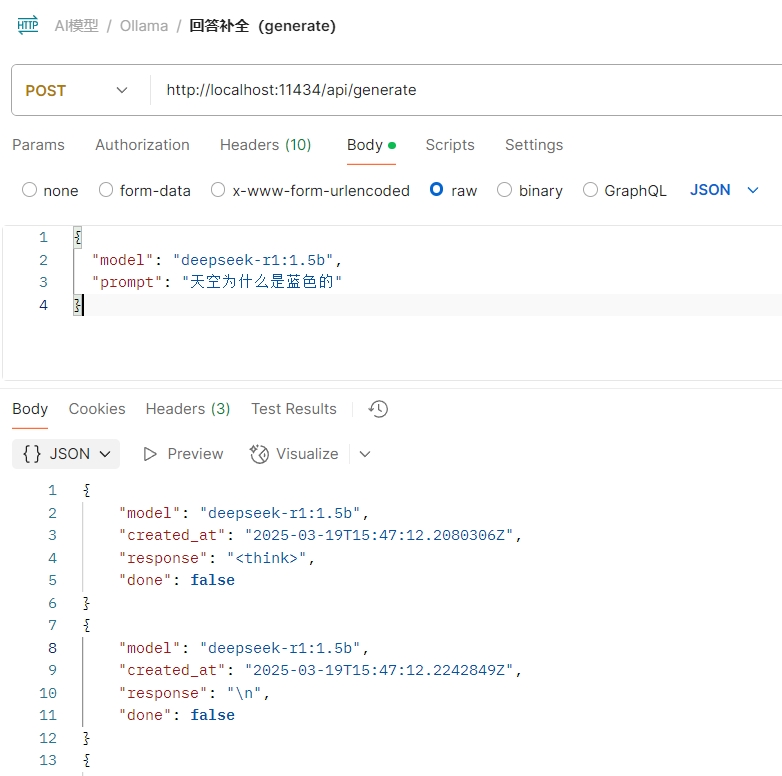
可以看到输出的内容很长,这是因为默认采用的是stream的方式输出的,也就是我们在deepseek app里面看到的一个字一个字输出的那种效果。我们可以将stream参数设置成false来禁用流式输出。
{ | |
"model": "deepseek-r1:1.5b", | |
"prompt": "天空为什么是蓝色的", | |
"stream": false | |
} |
参数列表
| 参数名 | 是否必填 | 描述 |
|---|---|---|
model | 是 | 模型名称 |
prompt | 是 | 需要生成响应的提示词 |
suffix | 否 | 模型响应后追加的文本 |
images | 否 | Base64编码的图片列表(适用于多模态模型如llava) |
format | 否 | 返回响应的格式(可选值:json 或符合 JSON Schema 的结构) |
options | 否 | 模型额外参数(对应 Modelfile 文档中的配置如 temperature) |
system | 否 | 自定义系统消息(覆盖 Modelfile 中的定义) |
template | 否 | 使用的提示词模板(覆盖 Modelfile 中的定义) |
stream | 否 | 设为 false 时返回单个响应对象而非流式对象 |
raw | 否 | 设为 true 时不格式化提示词(适用于已指定完整模板的情况) |
keep_alive | 否 | 控制模型在内存中的保持时长(默认:5m) |
context | 否 | (已弃用)来自前次 /generate 请求的上下文参数,用于维持短期对话记忆 |
生成对话(/api/chat)
生成对话,是一种具备上下文记忆的内容生成。在内容生成API中,我们仅传入了prompt,大模型仅对我们本地的prompt进行回答,而在生成对话API中,我们还可以传入messages参数,包含我们多轮对话内容,使大模型具备记忆功能。
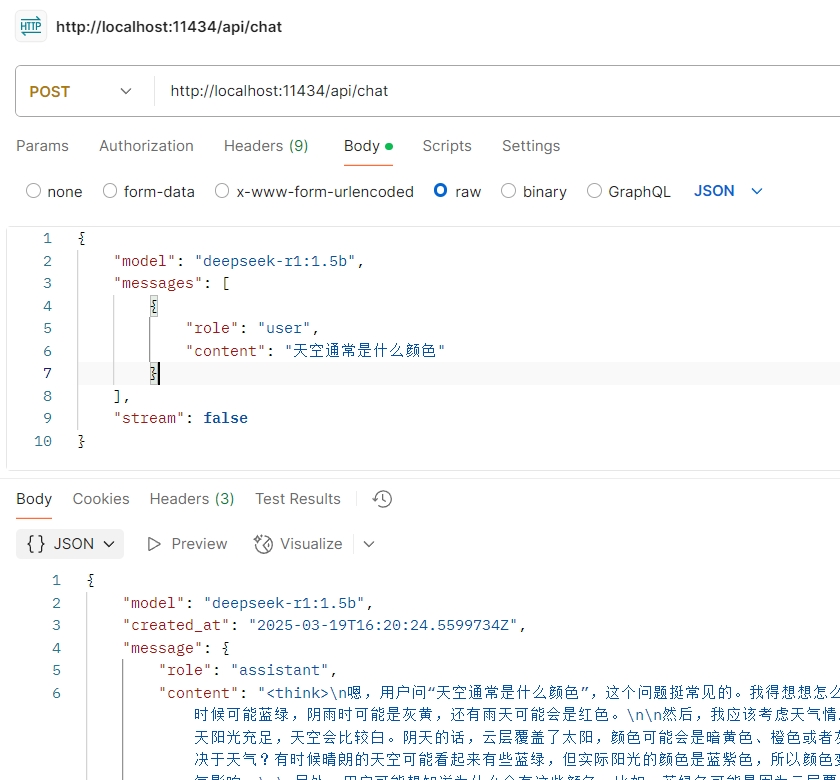
最简单的调用(为了方便演示,我们将stream参数设置为false):
{ | |
"model": "deepseek-r1:1.5b", | |
"messages": [ | |
{ | |
"role": "user", | |
"content": "天空通常是什么颜色" | |
} | |
], | |
"stream": false | |
} |
postman调用截图:
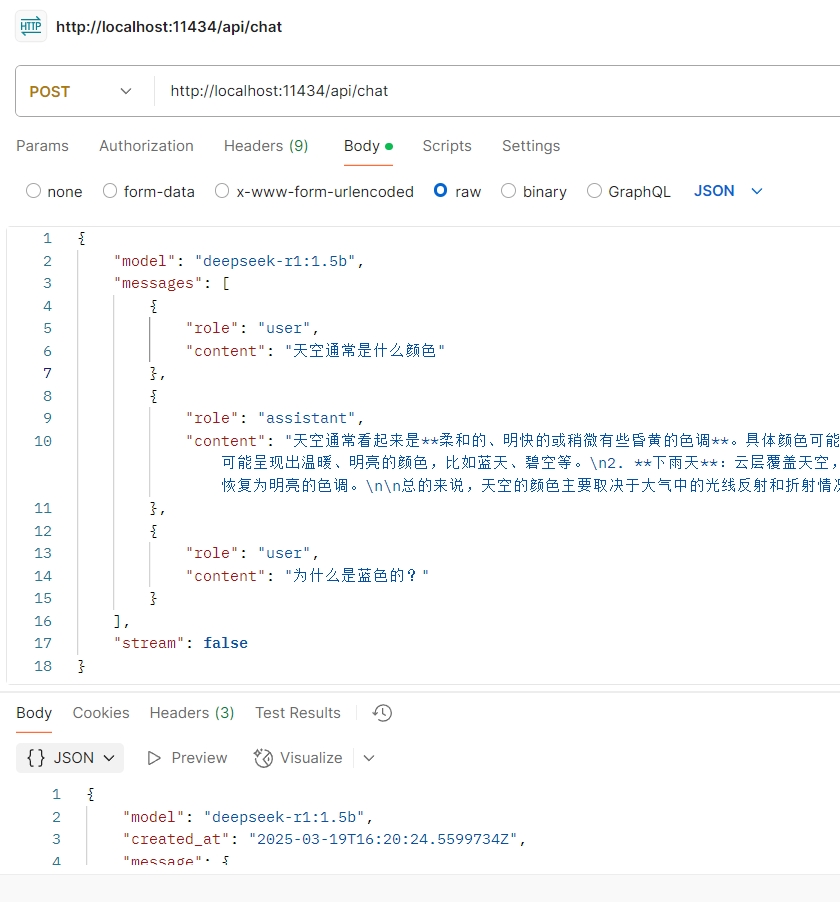
多轮对话
聊天的时候,ollama通过messages参数保持上下文记忆。当模型给我们回复内容之后,如果我们要继续追问,则可以使用以下方法(注意:deepseek-r1模型需要在上下文中移除think中的内容):
{ | |
"model": "deepseek-r1:1.5b", | |
"messages": [ | |
{ | |
"role": "user", | |
"content": "天空通常是什么颜色" | |
}, | |
{ | |
"role": "assistant", | |
"content": "天空通常看起来是**柔和的、明快的或稍微有些昏黄的色调**。具体颜色可能会因不同的天气情况而有所变化,例如:\n\n1. **晴朗天气**:天空可能呈现出温暖、明亮的颜色,比如蓝天、碧空等。\n2. **下雨天**:云层覆盖天空,可能导致颜色较为阴郁或变黑。\n3. **雨后天气**:雨后的天空可能恢复为明亮的色调。\n\n总的来说,天空的颜色主要取决于大气中的光线反射和折射情况,以及太阳的位置。" | |
}, | |
{ | |
"role": "user", | |
"content": "为什么是蓝色的?" | |
} | |
], | |
"stream": false | |
} |
postman调用截图:
结构化数据提取
当我们和系统对接时,通常要需要从用户的自然语言中提到结构化数据,用来调用现有的外部系统的接口。在ollama中我们只需要指定format参数,就可以实现结构化数据的提取:
{ | |
"model": "deepseek-r1:1.5b", | |
"messages": [ | |
{ | |
"role": "user", | |
"content": "哈喽,大家好呀~ 我是拓荒者IT,今年36岁了,是一名软件工程师" | |
} | |
], | |
"format": { | |
"type": "object", | |
"properties": { | |
"name": { | |
"type": "string" | |
}, | |
"age": { | |
"type": "integer" | |
}, | |
"job": { | |
"type": "string" | |
} | |
}, | |
"required": [ | |
"name", | |
"age", | |
"job" | |
] | |
}, | |
"stream": false | |
} |
参数列表
| 参数名 | 是否必填 | 描述 |
|---|---|---|
model | 是 | 模型名称 |
messages | 是 | 聊天消息数组(用于维持对话记忆) |
messages.role | 是 | 消息角色(可选值:system, user, assistant, tool) |
messages.content | 是 | 消息内容 |
messages.images | 否 | 消息中Base64编码的图片列表(适用于多模态模型如llava) |
messages.tool_calls | 否 | 模型希望调用的工具列表(JSON格式) |
tools | 否 | 模型可使用的工具列表(JSON格式,需模型支持) |
format | 否 | 返回响应的格式(可选值:json 或符合 JSON Schema 的结构) |
options | 否 | 模型额外参数(对应 Modelfile 文档中的配置如 temperature) |
stream | 否 | 设为 false 时返回单个响应对象而非流式对象 |
keep_alive | 否 | 控制模型在内存中的保持时长(默认:5m) |
生成嵌入数据(/api/embed)
嵌入数据的作用是将输入内容转换成向量,可以用于向量检索等场景。比如我们在第四篇中介绍的知识库,就需要用到embedding模型。
在调用embed接口时,我们要选择支持Embedding功能的模型,deepseek是不支持的。
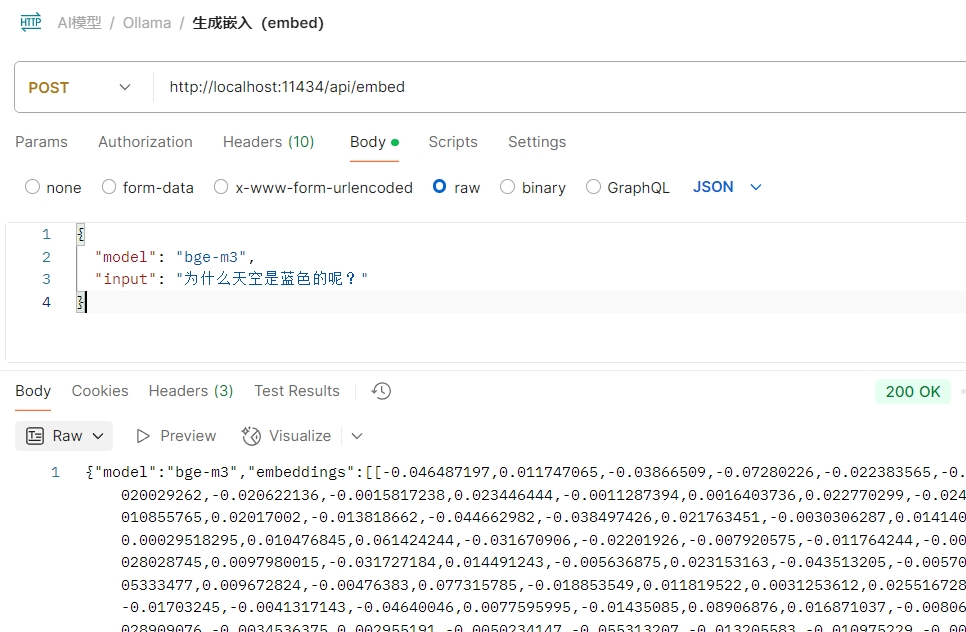
调用示例:
{ | |
"model": "bge-m3", | |
"input": "为什么天空是蓝色的呢?" | |
} |
postman调用截图:
兼容openAI接口
因为现在很多应用、类库都是基于OpenAI构建的,为了让这些系统能够使用Ollama提供的模型,Ollama提供了一套兼容OpenAI的接口(官方说是实验性的,以后可能会有重大调整)。
因为这种兼容,使得我们可以直接通过OpenAI的python库、node库来访问ollama的服务,确实方便了不少。
注意:ollama属于第三方接口,不能100%支持OpenAI的接口能力,因此在使用的时候需要先了解清楚兼容的情况。
其它接口
ollama还有一些其它的接口,用来实现对模型的管理等功能,而这些功能我们通常会在命令行完成,因此不做详细说明。这些API的列表如下:
- 模型创建(/api/create)
- 列出本地模型(/api/tags)
- 查看模型信息(/api/show)
- 复制模型(/api/copy)
- 删除模型(/api/delete)
- 拉取模型(/api/pull)
- 推送(上传)模型(/api/push)
- 列出运行中的模型(/api/ps)
- 查看ollama版本(/api/version)
这些接口的调用都非常简单,大家感兴趣的可以尝试以下。
C#集成指南
Ollama 提供了HTTP API的访问,如果需要使用SDK集成到项目中,需要引用第三方库OllamaSharp,直接使用nuget进行安装即可。

OllamaSharp功能亮点
- 简单易用:几行代码就能玩转Ollama
- 值得信赖:已为Semantic Kernal、.NET Aspire和Microsoft.Extensions.AI提供支持
- 全接口覆盖:支持所有Ollama API接口,包括聊天对话、嵌入生成、模型列表查看、模型下载与创建等
- 实时流传输:直接将响应流推送到您的应用
- 进度可视化:实时反馈模型下载等任务的进度状态
- 工具引擎:通过源码生成器提供强大的工具支持
- 多模态能力:支持视觉模型处理
调用示例
初始化client
// set up the client | |
var uri = new Uri("http://localhost:11434"); | |
var ollama = new OllamaApiClient(uri); |
获取模型列表
// list models | |
var models = await ollama.ListLocalModelsAsync(); | |
if (models != null && models.Any()) | |
{ | |
Console.WriteLine("Models: "); | |
foreach (var model in models) | |
{ | |
Console.WriteLine(" " + model.Name); | |
} | |
} |
创建对话
// chat with ollama | |
var chat = new Chat(ollama); | |
Console.WriteLine(); | |
Console.WriteLine($"Chat with {ollama.SelectedModel}"); | |
while (true) | |
{ | |
var currentMessageCount = chat.Messages.Count; | |
Console.Write(">>"); | |
var message = Console.ReadLine(); | |
await foreach (var answerToken in chat.SendAsync(message, Tools)) | |
Console.Write(answerToken); | |
Console.WriteLine(); | |
// find the latest message from the assistant and possible tools | |
var newMessages = chat.Messages.Skip(currentMessageCount - 1); | |
foreach (var newMessage in newMessages) | |
{ | |
if (newMessage.ToolCalls?.Any() ?? false) | |
{ | |
Console.WriteLine("\nTools used:"); | |
foreach (var function in newMessage.ToolCalls.Where(t => t.Function != null).Select(t => t.Function)) | |
{ | |
Console.WriteLine($" - {function!.Name}"); | |
Console.WriteLine($" - parameters"); | |
if (function?.Arguments is not null) | |
{ | |
foreach (var argument in function.Arguments) | |
Console.WriteLine($" - {argument.Key}: {argument.Value}"); | |
} | |
} | |
} | |
if (newMessage.Role.GetValueOrDefault() == OllamaSharp.Models.Chat.ChatRole.Tool) | |
Console.WriteLine($" - results: \"{newMessage.Content}\""); | |
} | |
} |
Tools
如果是LLM是大脑,那么工具就是四肢,通过工具我们能具备LLM与外界交互的能力。
定义工具:
/// <summary> | |
/// Gets the current datetime | |
/// </summary> | |
/// <returns>The current datetime</returns> | |
[OllamaTool] | |
public static string GetDateTime() => $"{DateTime.Now: yyyy-MM-dd HH:mm:ss ddd}"; |
使用工具:
public static List<object> Tools { get; } = [ | |
new GetDateTimeTool(), | |
]; | |
await chat.SendAsync(message, Tools) |
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









