







目录
常用命令
输入 Ollama 命令,正常的得出命令行输出,表示已经安装成功,下面有 ollama 的常用命令:
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.常用模型
我们可以在 https://ollama.com/library 中搜索已有我们想要的模型库。以下是一些流行的模型:
| 模型 | 参数 | 尺寸 | 执行下载 |
|---|---|---|---|
| Llama 2 | 7B | 3.8GB | ollama run llama2 |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| Llama 2 13B | 13B | 7.3GB | ollama run llama2:13b |
| Llama 2 70B | 70B | 39GB | ollama run llama2:70b |
| Gemma | 2B | 1.4GB | ollama run gemma:2b |
| Gemma | 7B | 4.8GB | ollama run gemma:7b |
这里大概列出了 Llama、Mistral 以及 Gemma 我们景见的模型以及参数以及尺寸大小。由图表可以看出 Gemma 2B 模型的尺寸还是比较小的,初学者入门。
运行模型
ollama run qwen # 运行千问大模型
因为qwen 模型对中文支持比较好,这里使用 qwen 模型进行聊天
直接使用 run 命令 + 模型名字就可以运行模型。如果之前没有下载过,那么会自动下载。下载完毕之后可以在终端中直接进行对话 qwen 模型了。
直接在终端中对话

使用 api 方式运行
curl http://localhost:11434/api/chat -d '{
"model": "qwen",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'
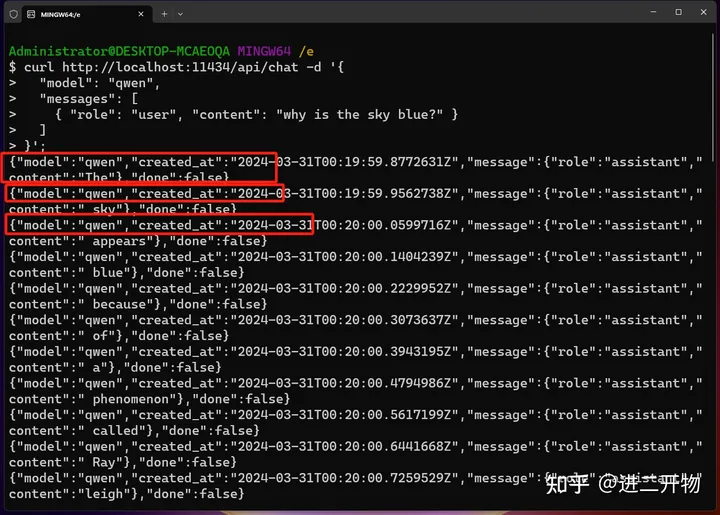
api 访问的方式:模型在不断推送字段。我们需要自己处理。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









