



前言
之前使用langserve可以特别轻松的封装langchain服务为API,这些API开放了链的各种能力。
有时候我们实际上只是需要更加简单的接口,并且希望能够更加灵活的对接口进行控制。此时直接使用flask及相关框架可能是更好的解决方案。
概述
本文讲述了如何使用一个利用本地大模型`llama3.1`实现语言翻译功能的API。
它用`flask`很轻松的将langchian服务开放为API,结合`flasgger`给文档添加注释并生成playground,并且使用`jsonschema`做json数据校验<,轻松验证接口参数。
麻雀虽小,但五脏俱全,应该*langchain入门者有较大帮助。
安装依赖
pip install flask flask-restful
pip install flasgger
pip install jsonschema
定义翻译方法
下面的方法需要两个参数,其中:language是翻译目标语言,text是需要翻译的文本。
\# 翻译方法
def translate(language,text):
# 1. 创建提示词模板
system\_template = "Translate the following into {language}:"
prompt\_template = ChatPromptTemplate.from\_messages(\[
('system', system\_template),
('user', '{text}')
\])
# 2. 创建本地大模型
model = OllamaLLM(model="llama3.1")
# 3. 创建解析器
parser = StrOutputParser()
# 4. 创建链
chain = prompt\_template | model | parser
#5. 调用链
result = chain.invoke({"language": language,"text":text})
return result
定义请求的json数据格式
当前比较流行的做法是客户端的请求以json格式提交给服务端。
使用jsonschema可以轻松的对客户端的输入参数进行校验。
\# 定义请求数据json的格式。l:language;t:text
schema={
"type": "object",
'required': \['l','t'\],
'properties': {
'l': {'type': 'string',"minLength": 2,"maxLength": 100},
't': {'type': 'string',"minLength": 2,"maxLength": 1000}
}
}
关于jsonschema的详细内容,可参见:[jsonschema官网文档]
定义接口和路由
使用`@app.route`可以指定接口路由,接口方法内部的注释可以被`flasgger`渲染生成playground。
#翻译API
@app.route("/trans", methods=\['POST'\])
def trans\_api():
# 以下注释将会被flasgger使用。
"""
翻译文本。
---
tags:
- 翻译
description:
将文本翻译为目标语言。
consumes:
- application/json
produces:
- application/json
parameters:
- name: query
in: body
required: true
description: json格式。例如:{"l":"简体中文","t":"good morning"}
responses:
code==ok:
description: 成功。msg的值为返回的内容。
code==err:
description: 失败。例如:{"code":"err","msg":"抱歉,我不知道。"} 。
"""
try:
j = request.get\_json()
validate(instance=j, schema=schema)
r = translate(j\["l"\].strip(),j\["t"\].strip())
return jsonify({"code":"ok","msg":r})
except Exception as e:
return jsonify({"code":"err","msg":str(e)})
关于flasgger详细的说明,请参考:[https://github.com/flasgger/flasgger](https://github.com/flasgger/flasgger。
启动API
if \_\_name\_\_ == '\_\_main\_\_':
#r = translate("简体中文","good morning")
#print(r)
# 设置API 文档。API文档访问地址:http://127.0.0.1:5001/apidocs/
swagger = Swagger(app=app)
app.run(port=5001)
出现下图所示,即表示API启动成功。

验证API
显然,上述API的地址为:`http://127.0.0.1:5001/trans`。可以使用多种方法验证API。
1. 使用第三方工具
下图使用`ApiFox`来验证接口。

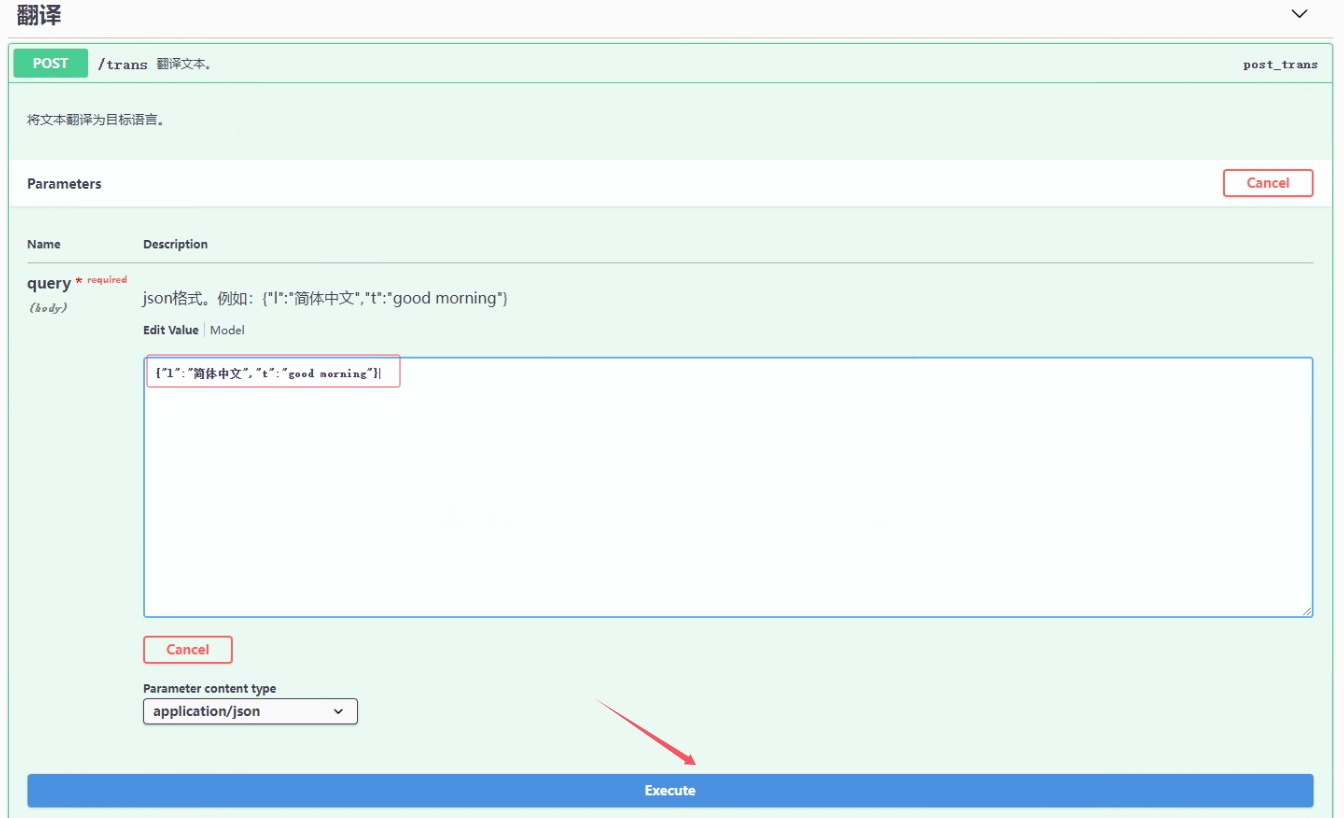
2. 使用`flasgger`生成的API
使用浏览器打开地址:`http://127.0.0.1:5001/apidocs/`,依图示对接口进行测试。


## 下载源代码
- [gitee](https://gitee.com/liupras/langchain-llama3-Chroma-RAG-demo)
- [github](https://github.com/liupras/langchain-llama3-Chroma-RAG-demo)
程序员为什么要学大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 185
185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









