






 本文通过使用机器学习中的线性回归和随机梯度下降法,对波士顿房价数据集进行预测分析。通过对数据集的预处理、特征选择、模型训练及评估,展示了如何建立并优化预测模型。
本文通过使用机器学习中的线性回归和随机梯度下降法,对波士顿房价数据集进行预测分析。通过对数据集的预处理、特征选择、模型训练及评估,展示了如何建立并优化预测模型。
需要数据集见文章最下方
数据说明在文末
背景介绍
波士顿房地产市场竞争激烈,而你想成为该地区最好的房地产经纪人。为了更好地与同行竞争,你决定运用机器学习的一些基本概念,帮助客户为自己的房产定下最佳售价。幸运的是,你找到了波士顿房价的数据集,里面聚合了波士顿郊区包含多个特征维度的房价数据。你的任务是用可用的工具进行统计分析,并基于分析建立优化模型。这个模型将用来为你的客户评估房产的最佳售价。
1.导入模块
from sklearn.linear_model import SGDRegressor
from sklearn.linear_model import LinearRegression
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
#⽤来正常显示中⽂标签
plt.rcParams['axes.unicode_minus']=False
#⽤来正常显示负号 #有中⽂出现的情况,需要u'内容'
2.分割数据集为训练集和测试集
#分割数据集为训练集和测试集
data = pd.read_csv('E:\Desktop\housing.csv')
x =data[['CRIM','ZN','INDUS','CHAS','NOX','RM','AGE','DIS','RAD','TAX','PIRATIO','B','LSTAT']]
y = data['MEDV']
x_train,x_test,y_train,y_test = train_test_split(x,y,train_size=0.25)
3.标准化处理
# 进行标准化处理
# 特征值和目标值进行标准化
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train.values.reshape(-1,1))
y_test = std_y.transform(y_test.values.reshape(-1,1))
4.用正规方程和梯度下降进行房价预测
lr = LinearRegression()
lr.fit(x_train,y_train)
print('正规方程预测回归系数',lr.coef_)
y_lr_pre = std_y.inverse_transform(lr.predict(x_test))
print('正规方程预测结果',y_lr_pre)
#SGD预测结果
ld = SGDRegressor()
ld.fit(x_train,y_train)
print('SGD预测回归系数',ld.coef_)
y_sgd_pre = std_y.inverse_transform(ld.predict(x_test))
print('SGD预测结果',y_sgd_pre)
result_lr = mean_squared_error(std_y.inverse_transform(y_test),y_lr_pre)
result_sgd = mean_squared_error(std_y.inverse_transform(y_test),y_sgd_pre)
print('lr均方误差',result_lr,'sgd均方误差',result_sgd)
print(lr.score(x_test,y_test))
print(ld.score(x_test,y_test))
5.完整代码
from sklearn.linear_model import SGDRegressor
from sklearn.linear_model import LinearRegression
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
def My_Linear():
#分割数据集为训练集和测试集
data = pd.read_csv('E:\Desktop\housing.csv')
x = data[['CRIM','ZN','INDUS','CHAS','NOX','RM','AGE','DIS','RAD','TAX','PIRATIO','B','LSTAT']]
y = data['MEDV']
x_train,x_test,y_train,y_test = train_test_split(x,y,train_size=0.25)
# 进行标准化处理
# 特征值和目标值进行标准化
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train.values.reshape(-1,1))
y_test = std_y.transform(y_test.values.reshape(-1,1))
#正规方程预测结果
lr = LinearRegression()
lr.fit(x_train,y_train)
print('正规方程预测回归系数',lr.coef_)
y_lr_pre = std_y.inverse_transform(lr.predict(x_test))
print('正规方程预测结果',y_lr_pre)
#SGD预测结果
ld = SGDRegressor()
ld.fit(x_train,y_train)
print('SGD预测回归系数',ld.coef_)
y_sgd_pre = std_y.inverse_transform(ld.predict(x_test))
print('SGD预测结果',y_sgd_pre)
result_lr = mean_squared_error(std_y.inverse_transform(y_test),y_lr_pre)
result_sgd = mean_squared_error(std_y.inverse_transform(y_test),y_sgd_pre)
print('lr均方误差',result_lr,'sgd均方误差',result_sgd)
print(lr.score(x_test,y_test))
print(ld.score(x_test,y_test))
return None
if __name__=='__main__':
My_Linear()
数据说明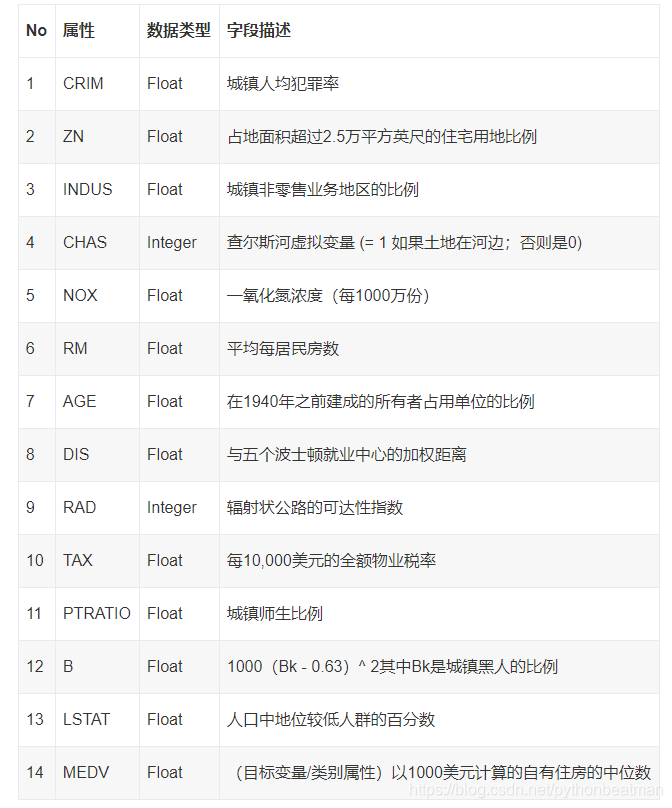
数据集:https://zhuanlan.zhihu.com/p/149676447
小伙伴们对数据分析/机器学习/数据挖掘感兴趣的话,可以关注我的知乎账号,大家一起交流学习

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









