



本文将介绍qwen-coder, qwen-math, qwq等模型
这些模型都是在基座模型基础上continue pretrain+post train获得的,因此其训练过程可以看做行业模型的适配流程;我将简单讨论这两年Qwen团队的适配技术,最后介绍一个旅游行业大模型的比赛和一些简单的思路
从版本发布的时间交叉可以看出,Code起步较早,应该是两个团队有些节奏差异
Coder系列
常用评测集: HumanEval 和 MBPP,LiveCodeBench (不断地从 LeetCode、AtCoder 和 CodeForces 三个竞赛平台中收集问题来测试模型的泛化能力)
Code-Qwen
we have created domain-specific models for coding by leveraging the base language models of QWEN, including continued pretrained model, CODE-QWENand supervised finetuned model, CODE-QWEN-CHAT.
新加入的Code tokens : 90B,规模不算大
为了处理Code任务的超长上下文(Tool use+code interpreation),拉长训练上下文到8K,同期qwen只有2K
多阶段的SFT,细节未能公开;从效果上看,超过了当时的开源模型,距离GPT4存在鸿沟
Qwen团队是在Pretrain Model的基础上研发的,没有考虑RLHF,自然不存在对齐税的问题,但这样的有害性仍有待考量;
Code-Qwen1.5
7B 参数的base和chat model,基于qwen1.5开发,其拥有 GQA 架构,经过了 ~3T tokens 代码相关的数据进行continue 预训练,共计支持 92 种编程语言、且最长支持 64K 的上下文输入。效果方面,CodeQwen1.5 展现出了非凡的代码生成、长序列建模、代码修改、SQL 能力
Qwen2.5 Coder
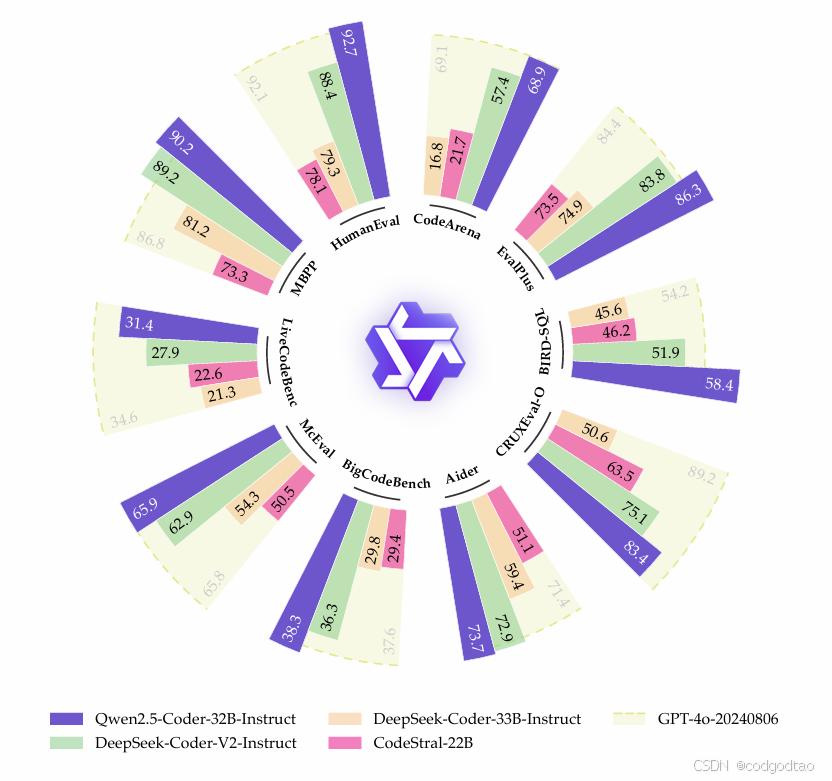
一句话总结: Qwen2.5-Coder-(0.5B/1.5B/3B/7B/14B/32B)。作为一个特定于代码的模型,Qwen2.5-coder建立在Qwen2.5架构之上,并继续在超过5.5万亿token的庞大语料库上进行预训练。效果上很不错,32B的模型接近4o的代码能力,但是livecodebench上差距不小,拿来做leetcode通过率较低。采用Fill-in-the-Middle技术预测中间缺失代码片段
模型架构
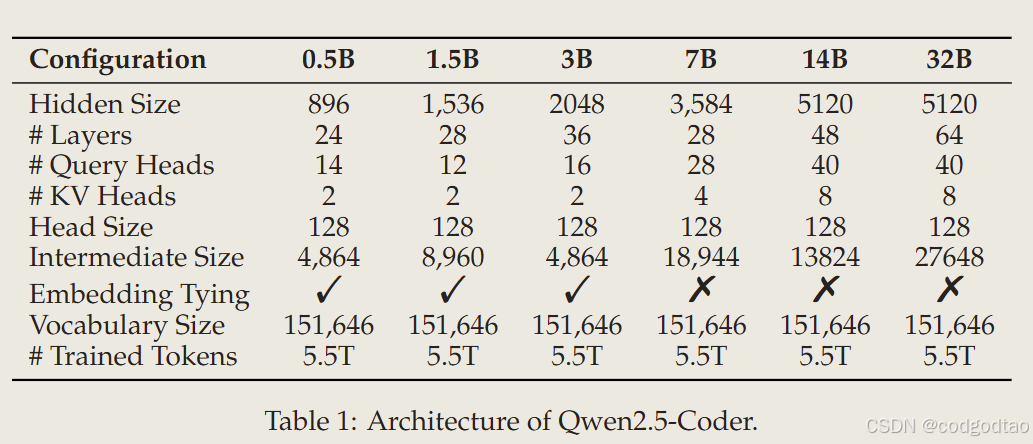
intermediate size的设置越来越trick了,以往设置为8/3倍比较符合直觉,但是现在看起来3-6都有例子,MLP的参数设计是否真的对模型效果存在正比例的影响?Hidden, MLP, Layer与Embedding size的参数敏感度是个值得研究的问题。
预训练细节

预训练包含文件级预训练和仓库级预训练两部分得到Coder-base Model
类似于通用模型如LLAMA的短文-长文两阶段训练,训练序列长度分别8K到32K,这一阶段使用高质量、长上下文的代码数据进行next-token预测,并拓展repo-level FIM
Fill in the Middle算法:


FIM的训练方式仍然采用next-token prediction的范式,但是数据的format整理为前缀和后缀放在前面,OpenAI的论文Efficient Training of Language Models to Fill in the Middle鼓励自回归模型采用FIM进行默认的训练, we keep the loss on all three sections prefix, middle, and suffix, so FIM training does not cause a decrease in the autoregressive learning signal
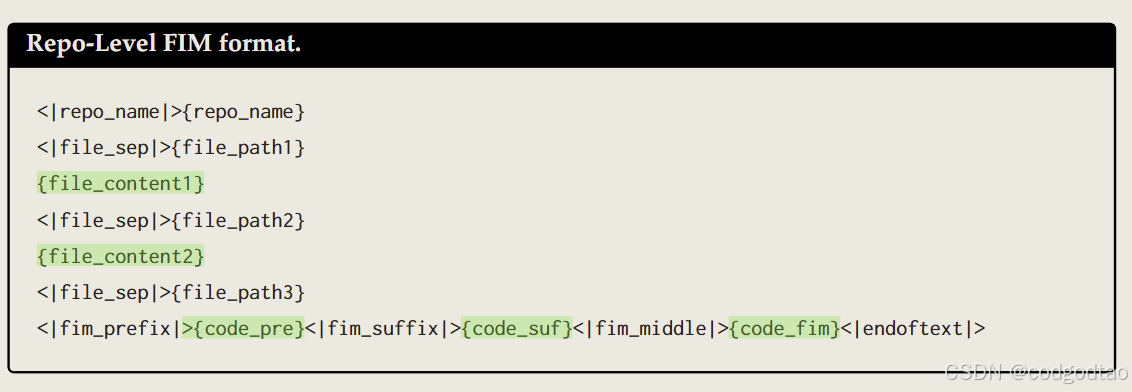
可以看到仓库级别的FIM,在FIM的前面加上了很多相关的其他文件进行代码仓库的理解;训练上下文从8K-32K提升,用一下NTK内插提高ROPE base,最后用YARN调整模型可以处理128K长上下文
数据集构造:
多阶段过滤Fasttext的文本-代码混合数据(教程、文档博文等)
合成数据基于CodeQwen1.5生成->验证器过滤
Qwen2.5-math模型的语料数据,Qwen2.5原来的高质量通用数据, 代码数学文本分别721的比例混合
后训练细节
Instruction Data的构造充满了技巧和经验,包含大量来利用LLM本身生成数据的方式。
- 基于CodeBert的代码语言识别与过滤
- 开源指令微调数据McEval+Github代码片段和LLM生成指令与response的微调数据
- 多语言多Agent协作框架 构造多语言SFT数据:
- 全面的指令数据评分标准
- 代码片段评估沙盒
千万级别的一般质量多样化指令微调样本
百万级别的高质量指令微调样本
小部分的FIM数据集微调
combine the code DPO data and common data for offline DPO train, 基于沙盒与LLM判断response的好坏
评估细节
Math系列
Math-Qwen
没有pretrain,直接构造math的SFT数据,在qwen base的基础上得到两个不同参数规模的chat模型,报告中提到微调Sample都是1024长度内的考试题目,成本相比不高。
Qwen2 Math
基础模型使用 Qwen2进行初始化,然后在精心设计的数学专用语料库上进行预训练,该语料库包含大规模高质量的数学网络文本、书籍、代码、考试题目以及由 Qwen2 模型合成的数学预训练数据。
微调模型: 首先基于 Qwen2-Math-72B 训练了一个数学专用的奖励模型。然后,我们将这个密集的奖励信号与一个二元信号结合,该二元信号指示模型是否正确回答了问题。这个组合信号被用作监督来通过拒绝采样构建 SFT 数据,并在此SFT模型的基础上进一步使用 GRPO 来优化模型。
但我看Math的指标没有超过qwen-base多少,不知道实际提升有多大
Qwen2.5 Math
一句话总结:(1)在预训练阶段,利用Qwen2-Math-Instruct生成大规模、高质量的数学数据。(2)在训练后阶段,通过对Qwen2-Math-Instruct进行大量采样,开发了一个奖励模型(RM)。然后将该RM应用于监督微调(SFT)中的数据迭代演化。有了更强的SFT模型,就可以迭代地训练和更新RM,进而指导下一轮SFT数据迭代。在最终的SFT模型上,采用终极RM进行强化学习,得到Qwen2.5-Math-Instruct。(3)在推理阶段,利用RM指导采样,优化模型性能。

预训练
Math 语料库v1:
基于高质量数学seed数据训练了FastText分类器,进行数学数据检索
MinHash重复数据过滤
基于Qwen2通用模型评估数据质量过滤
基于Qwen2-72B通用模型提取、生成数学问答对
在Qwen2的小模型进行数据混合配比的消融实验研究,得到700B的v1数据集,上下文4K
Math 语料库v2:
用Qwen2-Math-72B-Instruct在优化后生成预训练数据
采集了更多的中文数学数据
构造1T的预料对qwen2.5进行预训练
后训练
Math模型应该能够超长推理并且利用外部工具处理难题,构造了专门的数据集训练3epoch;数据的构造遵循query-response的分步骤生成,大量依赖rejection和RM之间的迭代循环
- COT数据合成
2000K en and 500K ch的数据,包含从GSM8K,MATG,NuminaMATH数据集提取的有注释问题、从中文K12考试拿的中文数学问题,基于MuggleMath从注释问题中进化的合成问题等;
有注释的query,从rejection sampling中答案正确的top-k
无注释的,进行加权投票推断正确路径的topk
topk是通过Reward model的分数判断的,训练后的SFT model会作用于RM的提升
- TIR数据合成
对于求根、特征值运算等高精度问题,需要使用Code辅助
包含190K个标注问题和250K个合成问题,思路同上,其中合成问题有75K是中文翻译的来增强多语言能力
在response构造中使用online rejection Finetuning, RFT在线拒绝微调方法迭代生成推理路径,根据是否存在注释,获得路径参考答案一致或者采用投票法;增加困难query的样本并应用重复数据过滤。
RFT技术:在SFT模型上应用rejection sampling来抽样并选择正确的推理路径作为增强数据集,影响RFT性能的关键因素是不同的推理路径量,可以通过多次采样或组合多个模型的样本来增加推理路径量
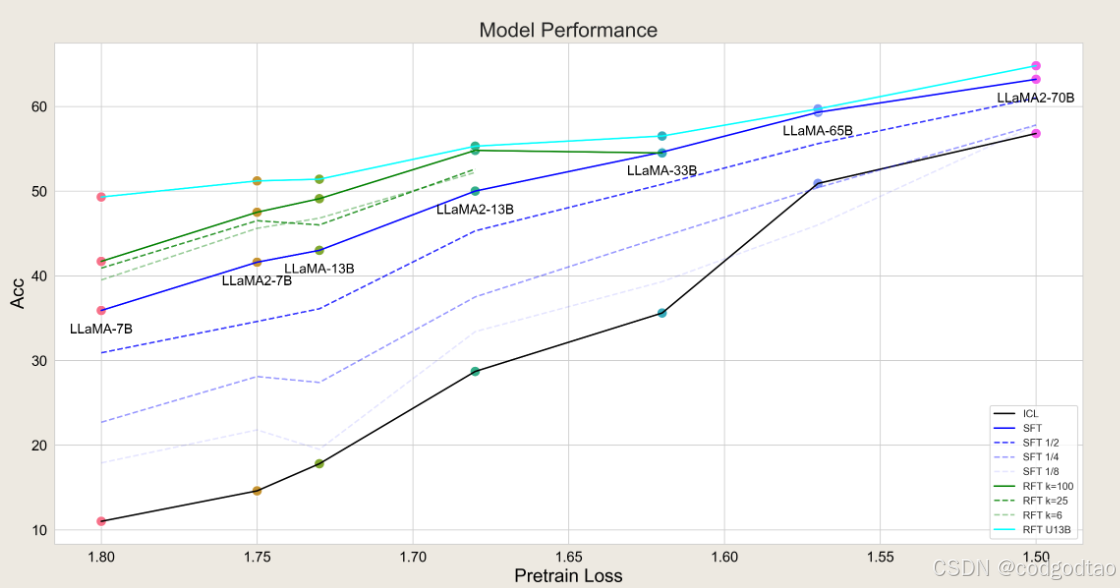
RFT是个比较节约成本的方案,对于比较差的base model, SFT的效果弱于从RFT,rejection sampling的路径越多越好;
- Reward Model
问题规模600K,每个问题有6个回复response
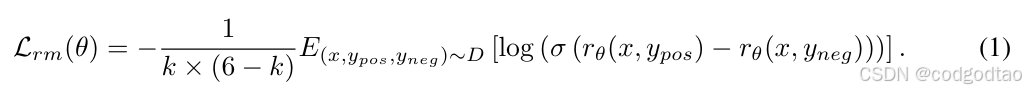
包含k个正样本和6-k个负样本,期望正样本的奖励》负样本奖励
这里采用sigmod(positive-negetive),值越接近1越好,则其-log运算后最小接近0值;
此外,除了Reward model进行评分,还引入了参考答案相关的verifier进行打分,确保正确response始终比错误response的Reward更高
GPRO原理

采用了Deepseekmath提出的后训练策略,使用一组采样输出的平均奖励作为基准来计算每个输出的优势A

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









