



参数定义
parser = argparse.ArgumentParser()
parser.add_argument() #在这里定义所有训练相关的参数,可以通过命令行方式传参
args = parser.parse_args()
...
在huggingface的trainer类中,需要传入TrainingArguments()类,指定训练有关的所有参数
training_args = TrainingArguments(...)
数据集加载与预处理
在huggingface的TRL中,支持最常见的SFT数据格式,以下两种格式不需要任何预处理,直接load_dataset后传入Trainer,格式的处理方式会按照tokenizer的chat_template进行处理,本文按照conversational format处理数据
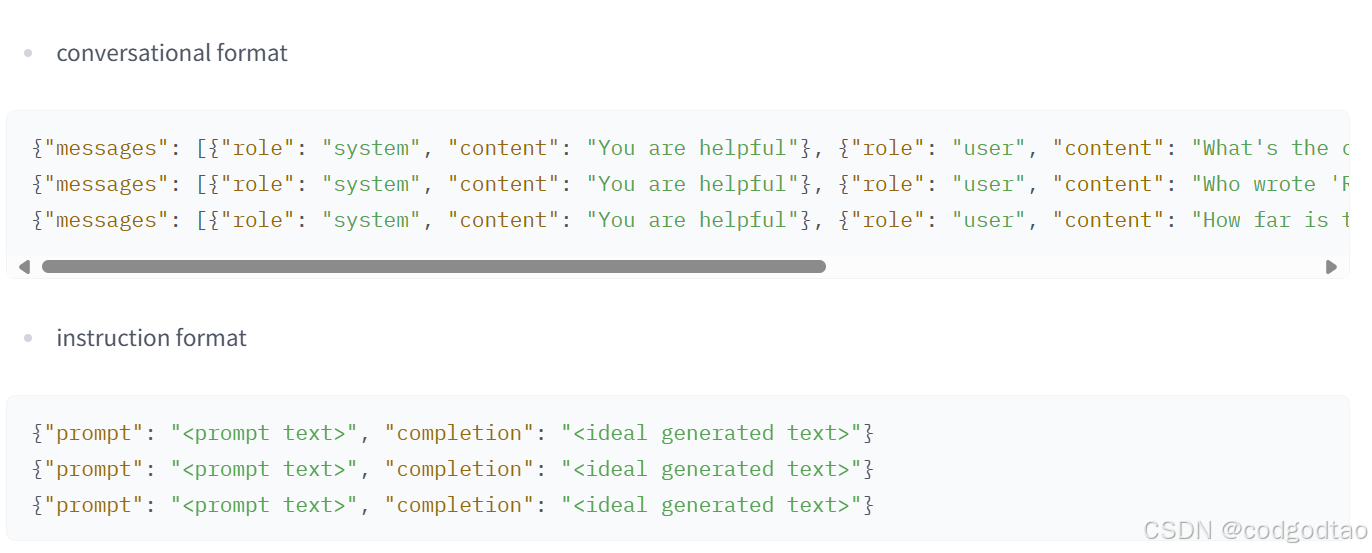
def create_datasets(tokenizer, args):
dataset = load_dataset(
args.dataset_name,
data_dir=args.subset,
split=args.split, # 这里只是读取了train部分的数据
num_proc=args.num_workers if not args.streaming else None,
streaming=args.streaming,
)
if args.streaming:
print("Loading the dataset in streaming mode")
valid_data = dataset.take(args.size_valid_set)
train_data = dataset.skip(args.size_valid_set)
train_data = train_data.shuffle(buffer_size=args.shuffle_buffer, seed=args.seed)
else:
dataset = dataset.train_test_split(test_size=0.005, seed=args.seed)
train_data = dataset["train"]
valid_data = dataset["test"]
print(f"Size of the train set: {len(train_data)}. Size of the validation set: {len(valid_data)}")
chars_per_token = chars_token_ratio(train_data, tokenizer)
print(f"The character to token ratio of the dataset is: {chars_per_token:.2f}")
可以看到dataset的细节如下:

其中train_data和test_data可以迭代或index获取数据

当然可以自己定义数据格式,但是需要format函数指定对每个json object的格式整理
def formatting_prompts_func(example):
output_texts = []
for i in range(len(example['question'])):
text = f"### Question: {example['question'][i]}\n ### Answer: {example['answer'][i]}"
output_texts.append(text)
return output_texts
trainer = SFTTrainer(
model,
args=training_args,
train_dataset=dataset,
formatting_func=formatting_prompts_func,
)
trainer.train()
训练流程总览
"""
# LoRA
python sft_qwen.py \
--model_name_or_path /home/wangsong/qwen \
--dataset_name /home/wangsong/qwen/Capybara \
--output_dir Qwen2-0.5B-SFT \
Fine-Tune Qwen2.5_Instruct 0.5B on Capybara dataset
Capybara是一个标准的Conversational格式数据集,由role和content组成的Messages列表组成
"""
import argparse
import os
from accelerate import Accelerator
from datasets import load_dataset
from peft import LoraConfig
from tqdm import tqdm
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, logging, set_seed
from trl import SFTTrainer
from trl.trainer import ConstantLengthDataset
"""
Fine-Tune Llama-7b on SE paired dataset
"""
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--model_path", type=str, default="/home/wangsong/qwen")
parser.add_argument("--dataset_name", type=str, default="/home/wangsong/qwen/Capybara")
parser.add_argument("--subset", type=str, default="data")
parser.add_argument("--split", type=str, default="train")
parser.add_argument("--size_valid_set", type=int, default=200)
parser.add_argument("--streaming", action="store_true")
parser.add_argument("--shuffle_buffer", type=int, default=5000)
parser.add_argument("--seq_length", type=int, default=1024)
parser.add_argument("--max_steps", type=int, default=10000)
parser.add_argument("--batch_size", type=int, default=4)
parser.add_argument("--gradient_accumulation_steps", type=int, default=1)
parser.add_argument("--learning_rate", type=float, default=1e-4)
parser.add_argument("--lr_scheduler_type", type=str, default="cosine")
parser.add_argument("--num_warmup_steps", type=int, default=100)
parser.add_argument("--weight_decay", type=float, default=0.05)
parser.add_argument("--local_rank", type=int, default=0)
parser.add_argument("--fp16", action="store_true", default=False)
parser.add_argument("--bf16", action="store_true", default=False)
parser.add_argument("--gradient_checkpointing", action="store_true", default=False)
parser.add_argument("--seed", type=int, default=0)
parser.add_argument("--num_workers", type=int, default=None)
parser.add_argument("--output_dir", type=str, default="./checkpoints")
parser.add_argument("--log_freq", default=1, type=int)
parser.add_argument("--eval_freq", default=1000, type=int)
parser.add_argument("--save_freq", default=1000, type=int)
return parser.parse_args()
def chars_token_ratio(dataset, tokenizer, nb_examples=400):
"""
Estimate the average number of characters per token in the dataset.
"""
total_characters, total_tokens = 0, 0
for _, example in tqdm(zip(range(nb_examples), iter(dataset)), total=nb_examples):
text = tokenizer.apply_chat_template(example['messages'], tokenize=False, add_generation_prompt=False)
total_characters += len(text)
if tokenizer.is_fast:
total_tokens += len(tokenizer(text).tokens())
else:
total_tokens += len(tokenizer.tokenize(text))
return total_characters / total_tokens
def print_trainable_parameters(model):
"""
Prints the number of trainable parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
)
def create_datasets(tokenizer, args):
dataset = load_dataset(
args.dataset_name,
data_dir=args.subset,
split=args.split, # 这里只是读取了train部分的数据
num_proc=args.num_workers if not args.streaming else None,
streaming=args.streaming,
)
if args.streaming:
print("Loading the dataset in streaming mode")
valid_data = dataset.take(args.size_valid_set)
train_data = dataset.skip(args.size_valid_set)
train_data = train_data.shuffle(buffer_size=args.shuffle_buffer, seed=args.seed)
else:
dataset = dataset.train_test_split(test_size=0.005, seed=args.seed)
train_data = dataset["train"]
valid_data = dataset["test"]
print(f"Size of the train set: {len(train_data)}. Size of the validation set: {len(valid_data)}")
chars_per_token = chars_token_ratio(train_data, tokenizer)
print(f"The character to token ratio of the dataset is: {chars_per_token:.2f}")
# while using custom format dataset, design prepare_sample_text
# train_dataset = ConstantLengthDataset(
# tokenizer,
# train_data,
# formatting_func=prepare_sample_text,
# infinite=True,
# seq_length=args.seq_length,
# chars_per_token=chars_per_token,
# )
# valid_dataset = ConstantLengthDataset(
# tokenizer,
# valid_data,
# formatting_func=prepare_sample_text,
# infinite=False,
# seq_length=args.seq_length,
# chars_per_token=chars_per_token,
# )
return train_data, valid_data
def run_training(args, train_data, val_data):
print("Loading the model")
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
target_modules=["q_proj", "v_proj"],
task_type="CAUSAL_LM",
)
train_data.start_iteration = 0
print("Starting main loop")
training_args = TrainingArguments(
output_dir=args.output_dir,
dataloader_drop_last=True,
eval_strategy="steps",
max_steps=args.max_steps,
eval_steps=args.eval_freq,
save_steps=args.save_freq,
logging_steps=args.log_freq,
per_device_train_batch_size=args.batch_size,
per_device_eval_batch_size=args.batch_size,
learning_rate=args.learning_rate,
lr_scheduler_type=args.lr_scheduler_type,
warmup_steps=args.num_warmup_steps,
gradient_accumulation_steps=args.gradient_accumulation_steps,
gradient_checkpointing=args.gradient_checkpointing,
fp16=args.fp16,
bf16=args.bf16,
weight_decay=args.weight_decay,
run_name="llama-7b-finetuned",
report_to="wandb",
ddp_find_unused_parameters=False,
)
model = AutoModelForCausalLM.from_pretrained(
args.model_path, load_in_8bit=True, device_map={"": Accelerator().process_index}
)
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=train_data,
eval_dataset=val_data,
peft_config=lora_config,
packing=True, #example packing, where multiple short examples are packed in the same input sequence to increase training efficiency
)
print_trainable_parameters(trainer.model)
print("Training...")
trainer.train()
print("Saving last checkpoint of the model")
trainer.model.save_pretrained(os.path.join(args.output_dir, "final_checkpoint/"))
def main(args):
tokenizer = AutoTokenizer.from_pretrained(args.model_path)
train_dataset, eval_dataset = create_datasets(tokenizer, args)
run_training(args, train_dataset, eval_dataset)
if __name__ == "__main__":
args = get_args()
assert args.model_path != "", "Please provide the llama model path"
set_seed(args.seed)
os.makedirs(args.output_dir, exist_ok=True)
logging.set_verbosity_error()
main(args)
训练细节说明
load_in_8bit: Whether to use 8 bit precision for the base model. Works only with LoRA
load_in_4bit: Whether to use 4 bit precision for the base model. Works only with LoRA.
load_in_8bit和load_in_4bit的模型参数量化,显著降低模型显存要求,加速base model的运算,只在PEFT使用
packing=True, #example packing, where multiple short examples are packed in the same input sequence to increase training efficiency
当训练期间只希望在模型输出部分进行微调(Qwen技术报告推荐做法),可以采用DataCollatorForCompletionOnlyLM ,packing=False,将collator传入SFTTrainer
instruction_template = "### Human:" #修改对应的Instruct Model特定指令
response_template = "### Assistant:" #修改对应的Instruct Model特定指令
collator = DataCollatorForCompletionOnlyLM(instruction_template=instruction_template, response_template=response_template, tokenizer=tokenizer, mlm=False)
lora_r (int, optional, defaults to 16) — LoRA R value.
lora_alpha (int, optional, defaults to 32) — LoRA alpha.
lora_dropout (float, optional, defaults to 0.05) — LoRA dropout.
lora_alpha 一般是lora_r的两倍,超参数trick

















 3053
3053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









