



接下来是本博客的第三部分,即Qwen团队的多模态技术发展,也是我个人觉得技术tricks最多的部分,多的一个输入条件为LLM架构和训练方式带来了很多可操作的“创新点”,包括token对齐、token压缩、图片视频处理、音频处理、多模态数据集的构造、多阶段训练pipeline、多维度ROPE编码等
自从BLIP2,LLAVA带火了多模态大模型技术后,这两项先锋工作陆续都不更新了(LLAVA-NEXT之后已经7个月没有消息),感谢这些工作带来MLP|Qformer+多阶段开放训练+指令微调等想法,但是后续的研究可能除了META和Qwen,只有InternVL在开源社区能探索多模态LLM的scaling law了,想出效果没有大力是不行了
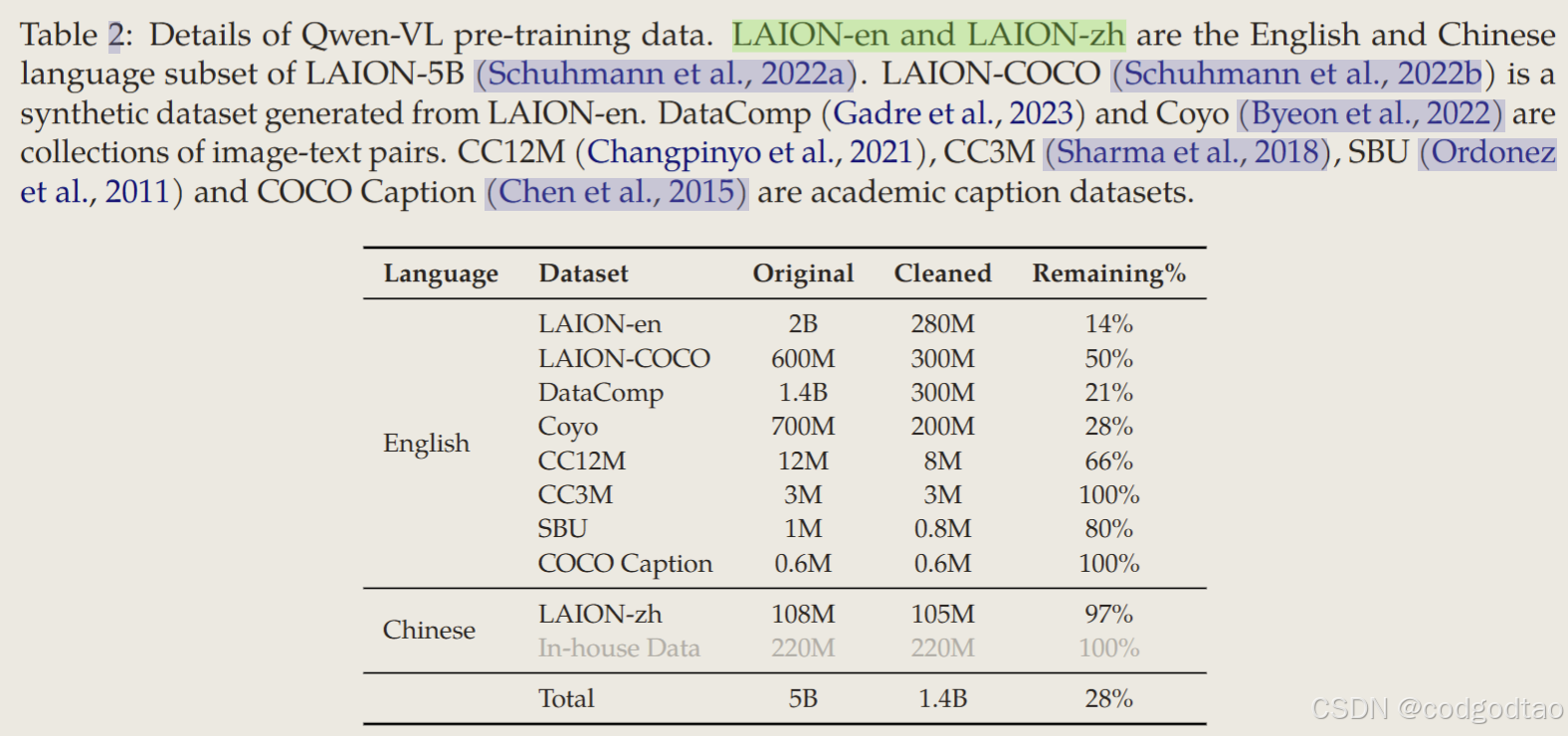
Qwen-VL数据规模只有1.4B+多任务50M sample +高质量350K sample;Qwen2VL在预训练阶段起码有1.4T的tokens,且使用的数据集不再公开来源,完全的in-house datasets;关于Vision端的位置编码部分,1D 2D 3D Rope和Dynamic Resolution(upper limit 16K,外推到128K tokens),值得深入研究一番。
Qwen-VL
数据规模只有1.4B+多任务50M+高质量350K;
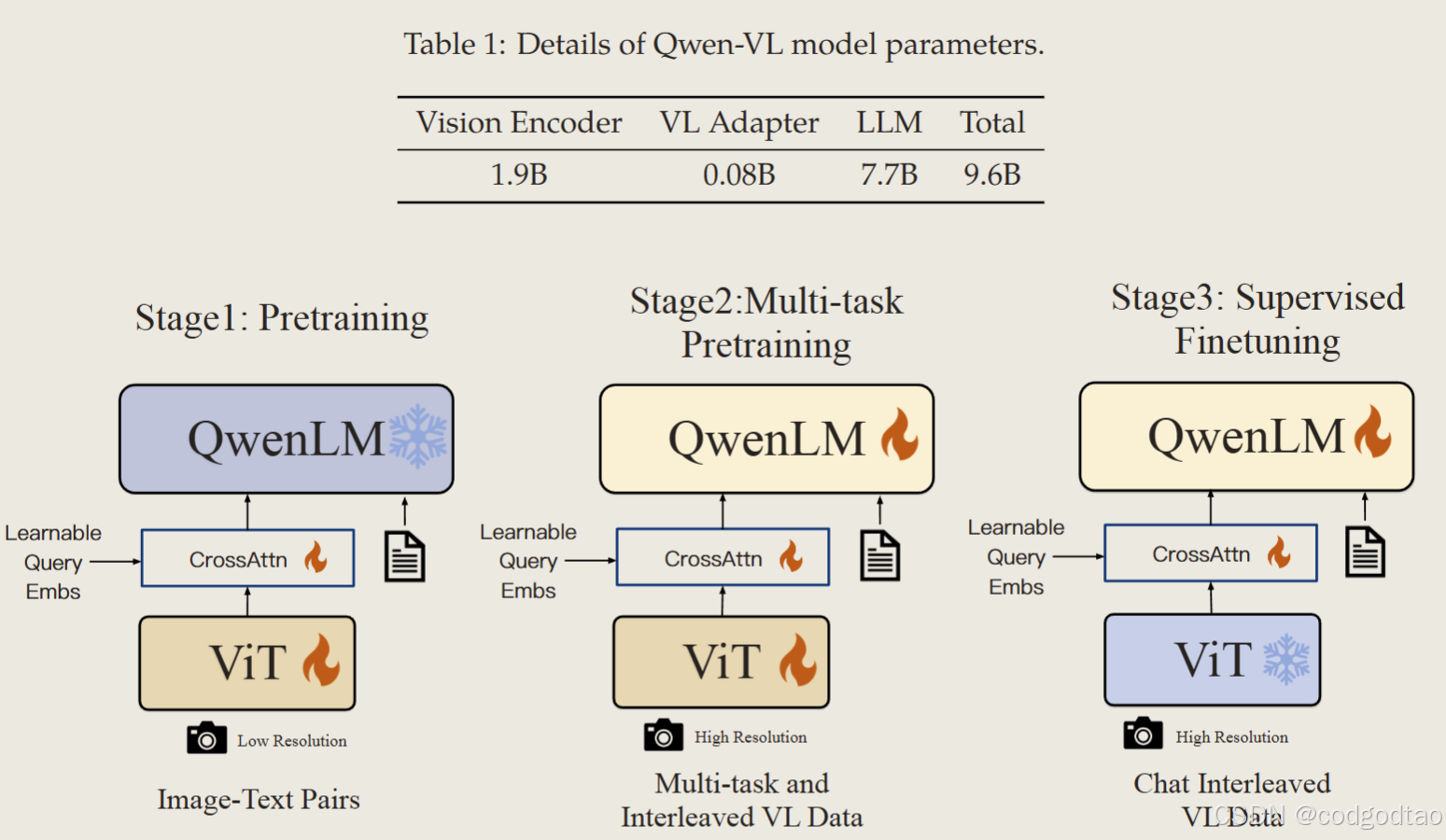
只有一个10B参数的版本,其中VIT使用了OpenCLIP VIT-bigG
input images are resized to a specific resolution, patch size 14*14
一层随机初始化的Cross-attention,基于256个learnable query压缩图像Tokens的数量;
2D absolute positional encodings are incorporated into the cross-attention mechanism’s query-key pairs
stage1: pretraining
使用大规模的caption低质量数据集增强对齐能力;大概1.4B的数据规模
stage2: multi-task pretraing
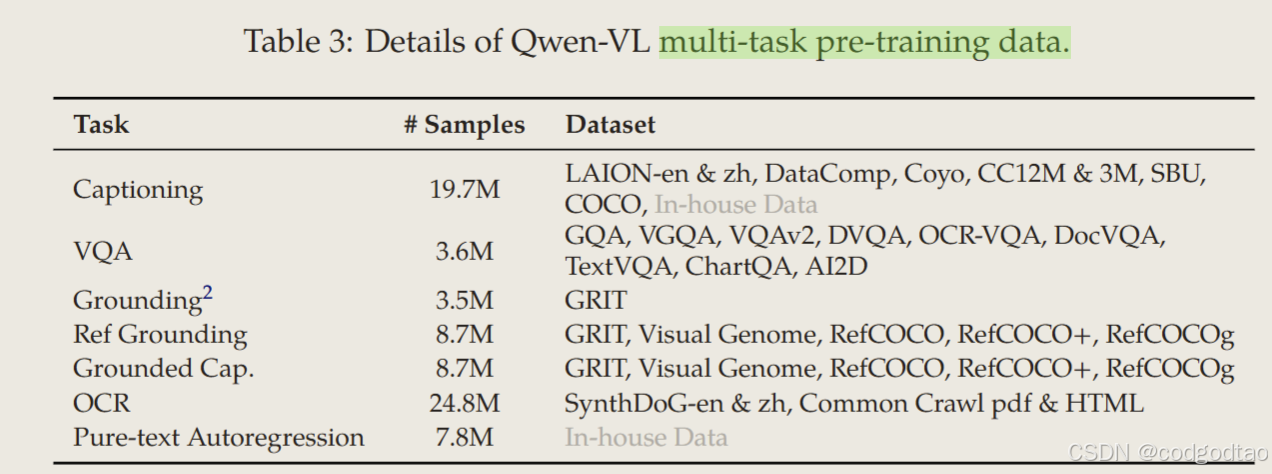
7中不同任务手机的训练数据集,并扩大VIT的image size为448*448,通过消融实验判断window attention一般,且更高分辨率会很慢
stage3: SFT
从caption和dialogue数据集基于self-instruct构造指令微调数据集;结合手工标注构造350K指令微调数据集
Qwen2-VL
Model Architecture
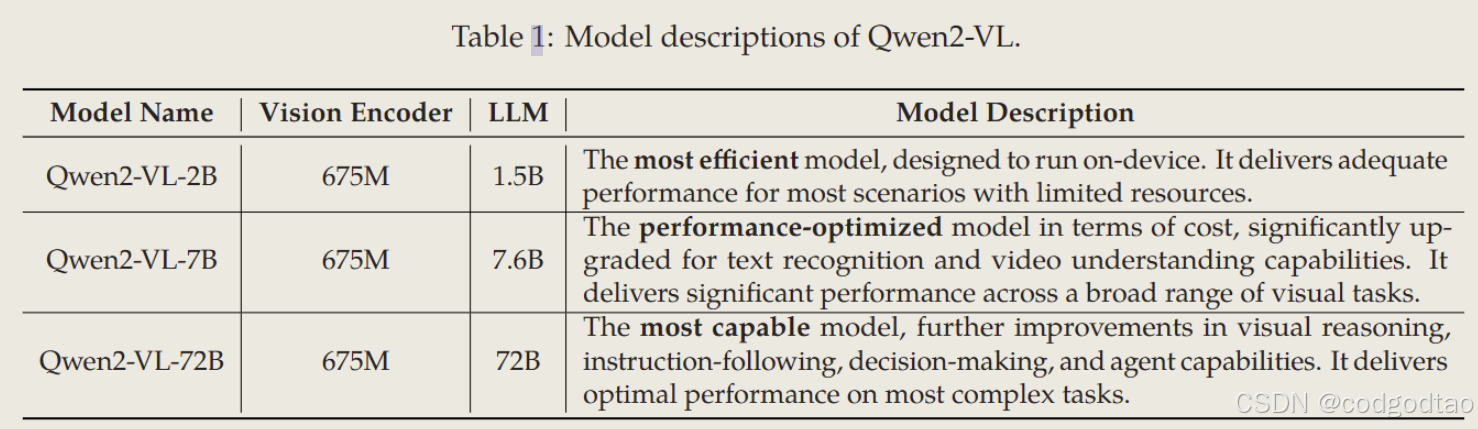
视觉部分:能够处理图片视频输入的VIT(675M);MLP token压缩4倍,14*14 的patch划分
语言部分:Qwen2系列
动态分辨率支持:VIT可以处理任意分辨率的图片或视频,移除了原本VIT的绝对位置编码而是用2D-Rope在任意分辨率上预训练
对token采用多模态ROPE。包含temporal,height and width三个维度的position id。在模型输入包含多个模态的场景中,通过将前一个模态的最大位置ID增加1来初始化每个模态的位置编号

图片视频混合训练方案:视频每秒采样两帧,使用3D卷积处理3D cube输入;图片当做两帧的视频输入统一当成3D cube处理,动态压缩分辨率控制toknes不超过16384
训练部分
在第一阶段,我们专注于ViT,利用大量的图像-文本对语料库来增强大型语言模型(LLM)中的语义理解。在第二阶段,我们解冻所有参数,用更大范围的数据进行训练,进行更全面的学习。在最后阶段,我们锁定ViT参数,并使用指令数据集微调。
预训练阶段:
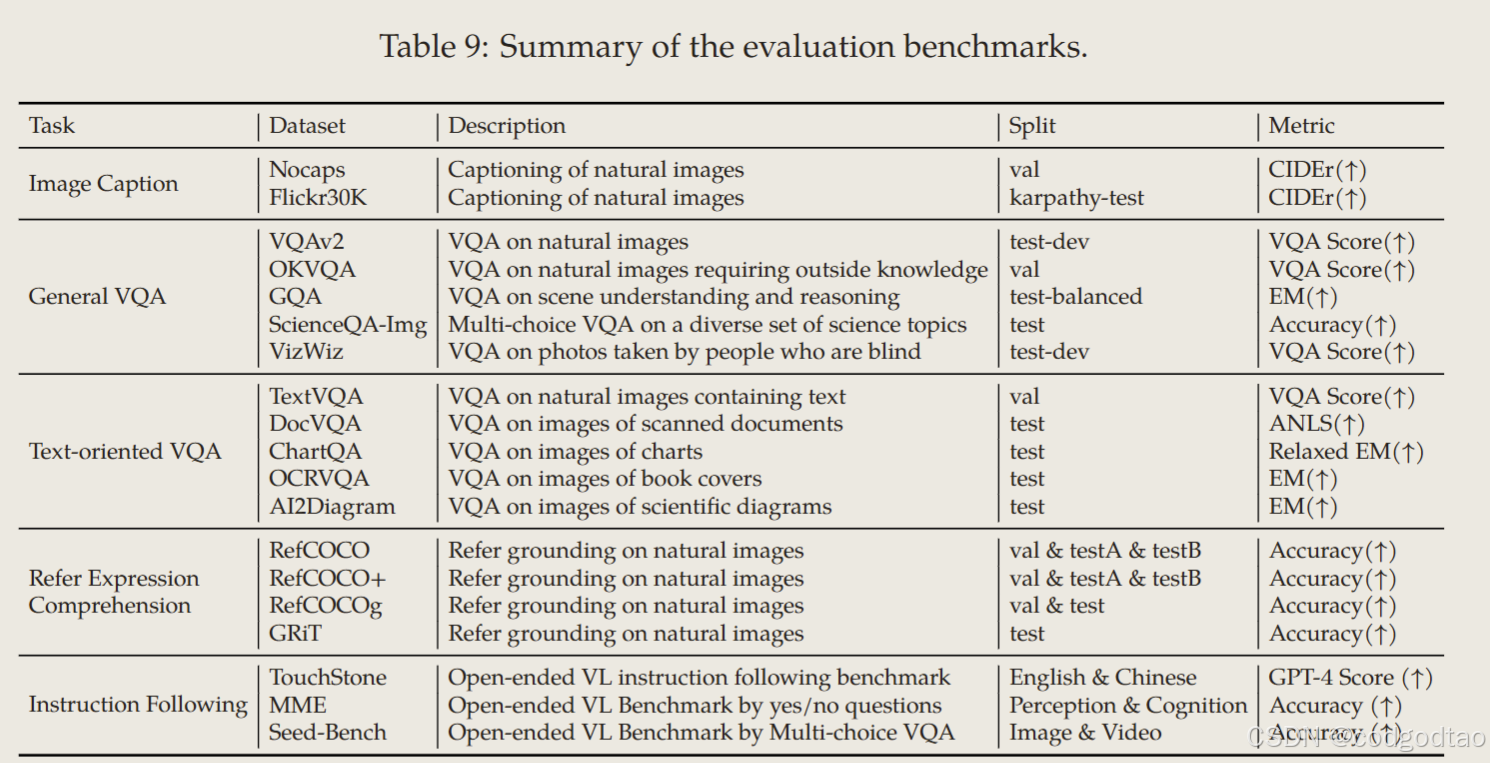
包括图像-文本对、光学字符识别(OCR)数据、交错图像-文本文章、视觉问答数据集、视频对话和图像知识数据集的各种数据集。我们的数据源主要包括清理过的网页、开源数据集和合成数据。
一阶段:DFN’s ViT的绝对位置编码修改为Rope2D
主要关注学习图像-文本关系,通过OCR识别图像中的文本内容,以及图像分类任务/600B tokens。这样的基础训练有助于使模型发展对核心视觉文本关联和对齐的强大理解
二阶段:800B tokens,包含混合图文内容,VQA数据集、多任务数据集和纯文本数据
训练期间只在text-tokens上进行交叉熵分类损失建模,图片tokens不需要算
指令微调阶段
数据集不仅包含纯文本对话数据,还包含多模态对话数据。多模态组件包括图像问答、文档解析、多图像比较、视频理解、视频流对话和Agent交互。我们对数据构建的综合方法旨在增强模型理解和执行各种模式的广泛指令的能力
Special Tokens数据格式整理
使用<vision_start> <vision_end>的方式包裹图片Tokens
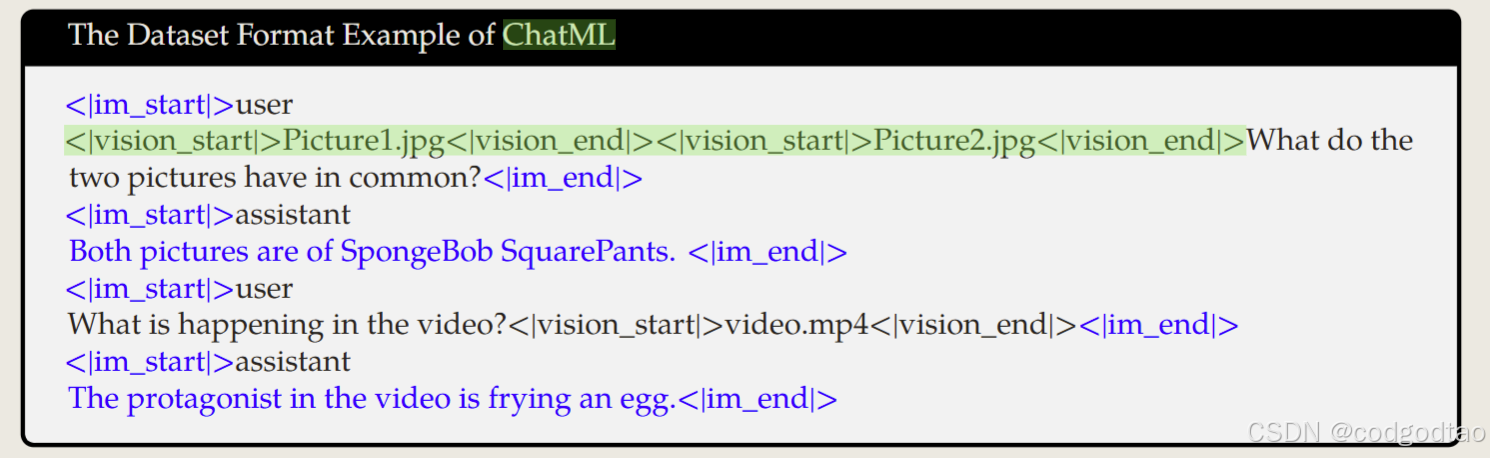
对于Grounding数据集的整理方式

Agent数据集需要定义Actions和相应描述,keywords pattern (underline) for function call

训练细节:
Parallelism. We use 3D parallelism which combines data parallelism (DP) (Li et al., 2020), tensor parallelism (TP) (Krizhevsky et al., 2012; Shoeybi et al., 2019) and pipeline parallelism (PP) (Huang et al., 2019; Narayanan et al., 2021; Lamy-Poirier, 2023) to scale Qwen2-VL model training. We also leverage deepspeed’s zero-1 redundancy optimizer (Rajbhandari et al., 2020) to shard states for memory saving. Sequence parallelism (SP) (Korthikanti et al., 2023) with selective checkpointing activation (Chen et al., 2016) was leveraged to reduce memory usage. When enabling TP training, we always shard the vision encoder and large language models together but not the vision merger due to its relatively few parameters. We found the TP training would result in different model shared-weights due to the convolution operator’s non-deterministic behavior 2. We resolved this issue by performing offline reduction of the shared weights, thereby avoiding an additional all-reduce communication step. This approach resulted in only a minimal impact on performance. We leverage 1F1B PP (Narayanan et al., 2021) for Qwen2-VL 72B training. We combine the vision encoder, vision adapter and several LLM’s decoder layers into one stage, and evenly split the remaining decoder layers. Note that the vision and text sequence lengths are dynamic for each data point. We broadcast the dynamic sequence lengths before initiating the 1F1B process and access the shape information using batch indices. We also implemented an interleaved 1F1B PP (Narayanan et al., 2021) but found it is slower than the standard 1F1B setting
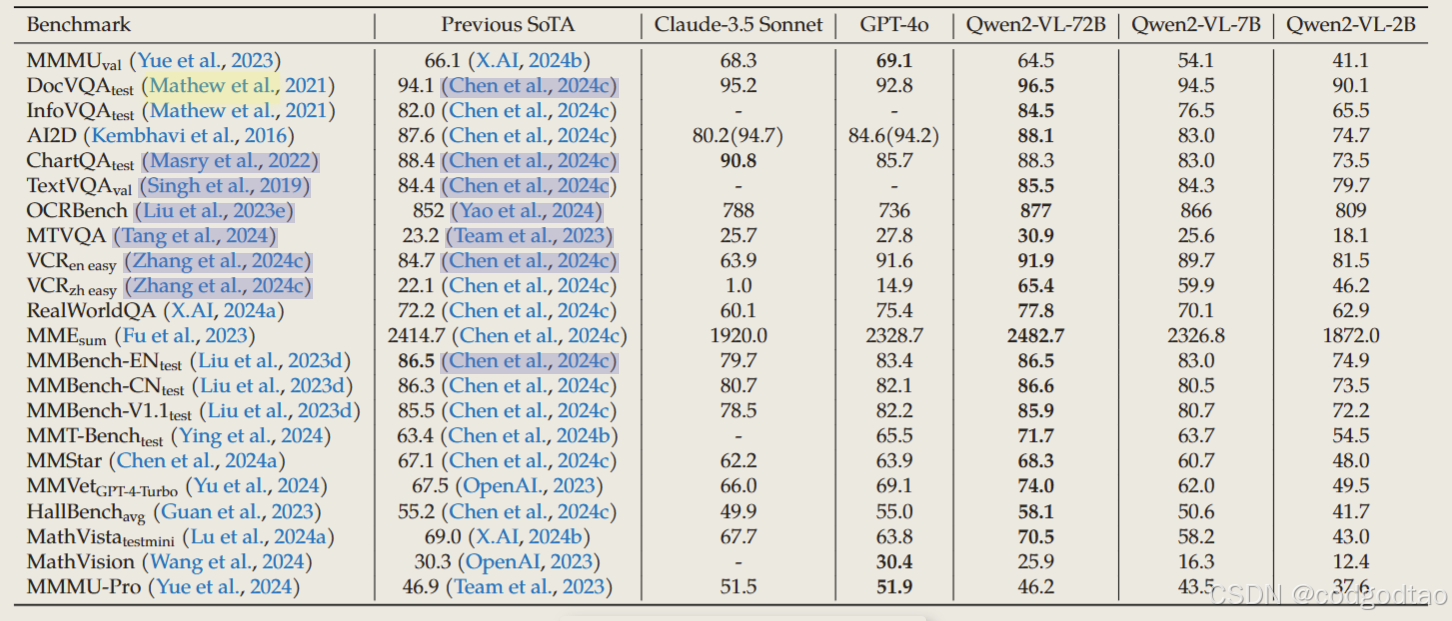
previous Sota主要是internvl2, 可以看到72B的Qwen很强,但是7B的模型基本弱于InternVL2


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









