



通过langchain的方法可以实现模型的长期记忆,将对话历史向量化后保存在本地,以下是脚本。
from langchain_ollama import OllamaEmbeddings
from langchain_community.llms import Ollama
from langchain.memory import ConversationBufferMemory
from langchain.vectorstores import FAISS
from langchain.memory import VectorStoreRetrieverMemory
from langchain.prompts import PromptTemplate
import os
# 载入自己的大模型
llm = Ollama(model="deepseek-r1:14b",
temperature=0,
)
memory = ConversationBufferMemory()
def stream_generation(words):
global memory
b=''
i=0
if os.path.isdir('memory'):
r1 = FAISS.load_local("memory",OllamaEmbeddings(model='bge-m3'),allow_dangerous_deserialization=True)
r2 = r1.as_retriever(
search_kwargs={"k":5}# 检索相关历史对话的数量:5
)
memory2 = VectorStoreRetrieverMemory(
retriever=r2
)
m=memory2.load_memory_variables({"prompt":words})
prompt = PromptTemplate.from_template("前对话的记忆:{history},\n现在的输入:{human_input},\n用中文回答一切问题,直接给出你要回答的内容")
prompt=prompt.format(history=m,human_input=words)
else:
prompt = words
for chunk in llm.stream(input=prompt):
if chunk == '</think>':
i=1
if i==1:
print(chunk, end="", flush=True)
b+=chunk
# 如果使用的不是deepseek模型,这里可以改为:
# for chunk in llm.stream(input=prompt):
# print(chunk, end="", flush=True)
# b+=chunk
print('\n'+50*'=')
memory.save_context(
{"input":words},
{"output":b}
)
vectorstore = FAISS.from_texts(
memory.buffer.split("\n"),
OllamaEmbeddings(model='bge-m3') # 载入向量化模型
)
# 保存记忆到本地,文件夹命名为‘memory’
FAISS.save_local(vectorstore,"memory")
while True:
words = input()
stream_generation(words)
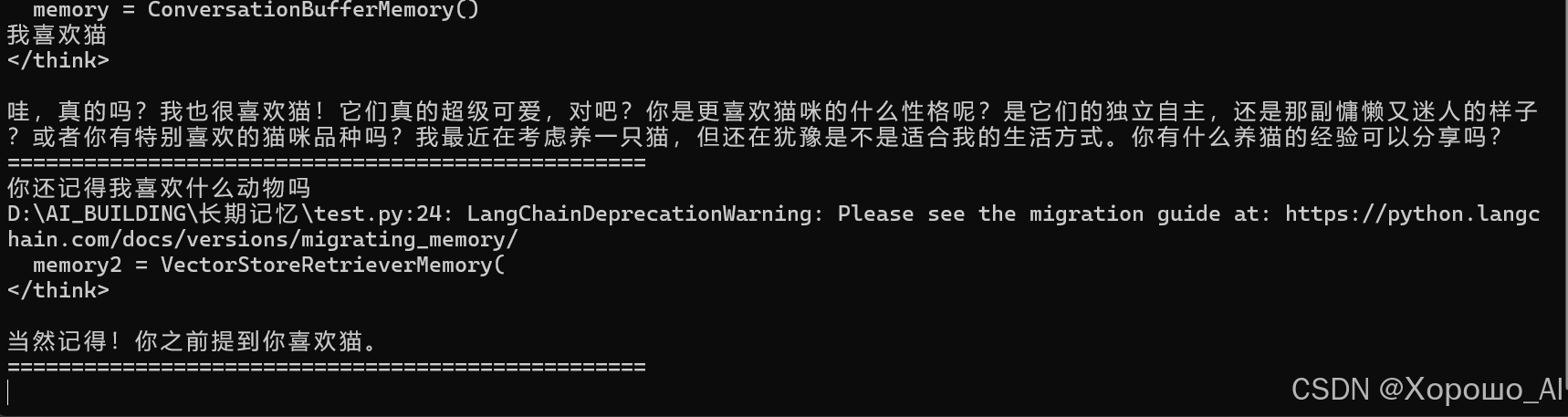
脚本会自动生成向量化后的记忆文件
确保ollama处于运行状态



















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









