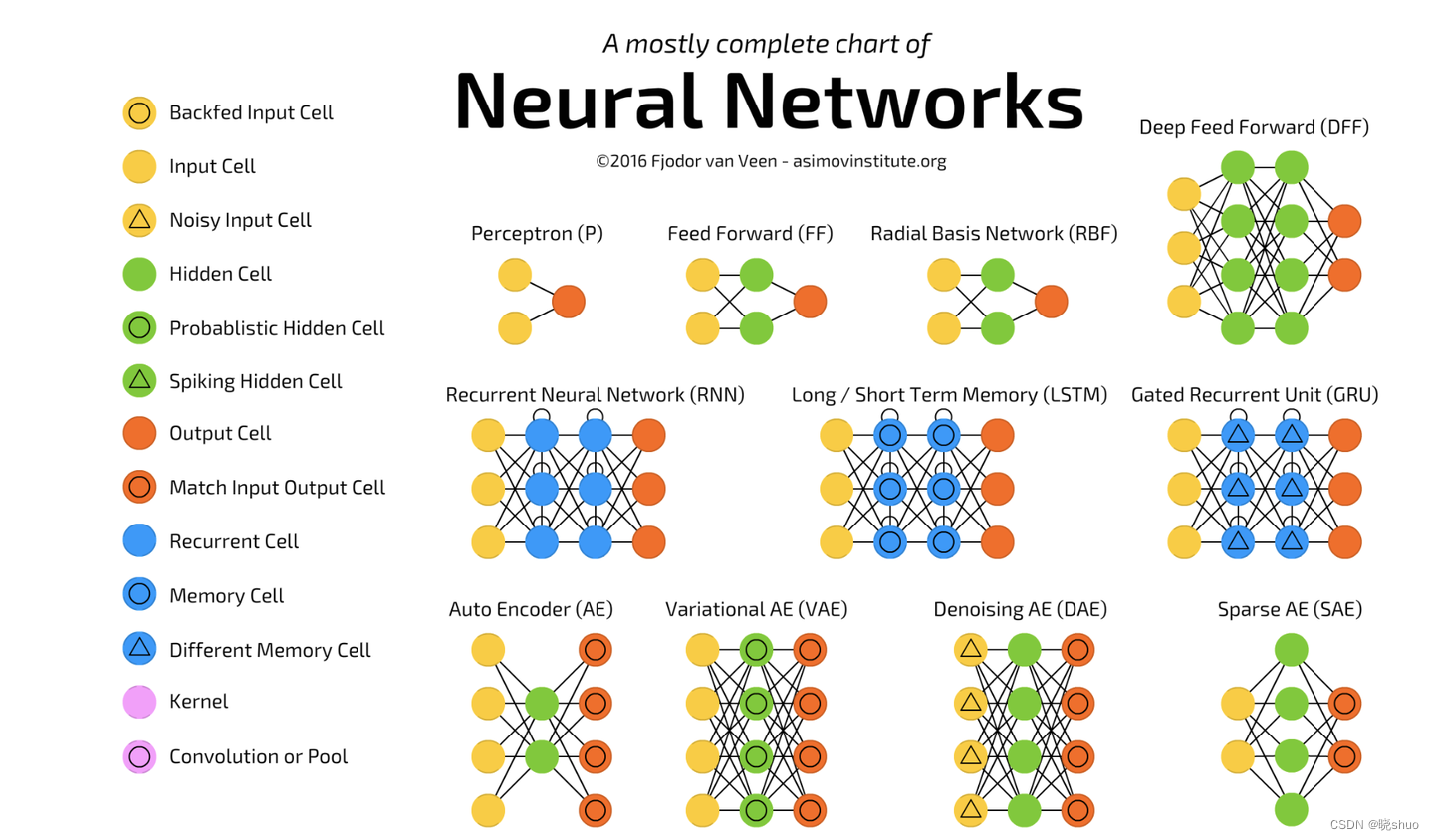
深度学习中的pipeline和baseline




于 2023-05-10 16:58:50 首次发布
 文章讨论了深度学习的流程,从数据读取和预处理开始,经过模型构建,到模型效果的评估和调参,最后介绍了作为基准的baseline模型在这一过程中的作用。
文章讨论了深度学习的流程,从数据读取和预处理开始,经过模型构建,到模型效果的评估和调参,最后介绍了作为基准的baseline模型在这一过程中的作用。
文章讨论了深度学习的流程,从数据读取和预处理开始,经过模型构建,到模型效果的评估和调参,最后介绍了作为基准的baseline模型在这一过程中的作用。
文章讨论了深度学习的流程,从数据读取和预处理开始,经过模型构建,到模型效果的评估和调参,最后介绍了作为基准的baseline模型在这一过程中的作用。
 1774
3585
1774
3585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言