




昨日,Meta公司发布了人工智能模型——Llama 3.1。
那么Llama 3.1 405B的效果怎么样?我们来对比一张图,横向对比一下GPT-4。
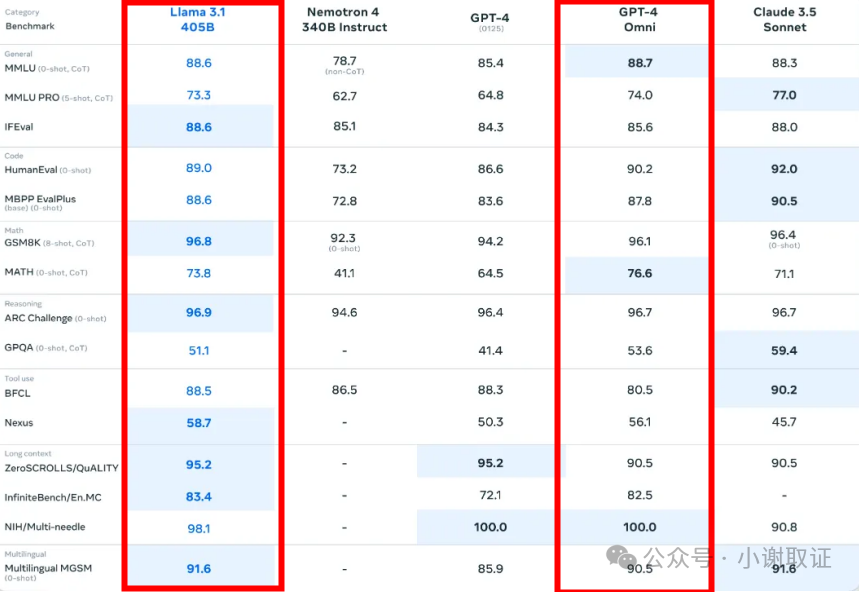
可以看出,Llama 3.1 405B在各类任务中的表现可以与GPT-4等顶级的模型相差无几。
那么,我们怎样才能用到这款强大的Llama 3.1 405B模型呢?最直接的方式是通过Meta.ai平台,但目前这一途径仅对美丽国的用户开放。

那有无适合平民用的大模型嘞。
接下来我们将在本地部署Llama 3.1 8B(环境所迫)
1.环境准备
(1)Windows10系统及以上的计算机
(2)内存要求:8GB内存可运行7B模型,16GB可运行13B模型,32GB运行可33B模型
(3)网络环境:不需要科学上网(翻墙)
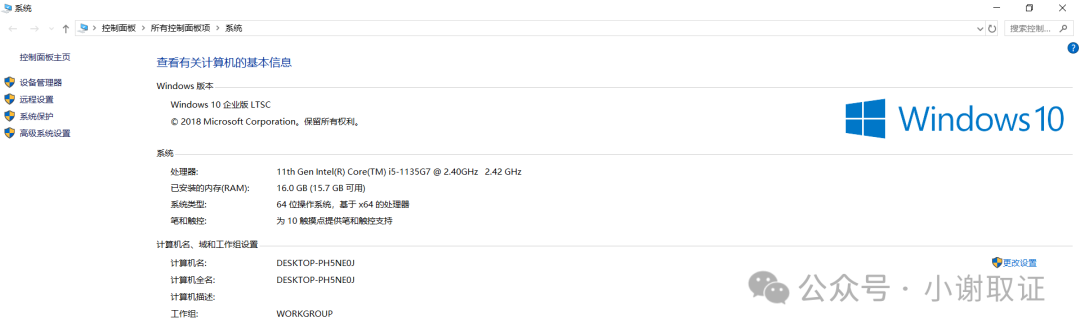
(4)小谢此次搭建的电脑环境如图,又无GPU,这配置只能搭个入门级别的大模型。若有GPU,响应速度则更快。
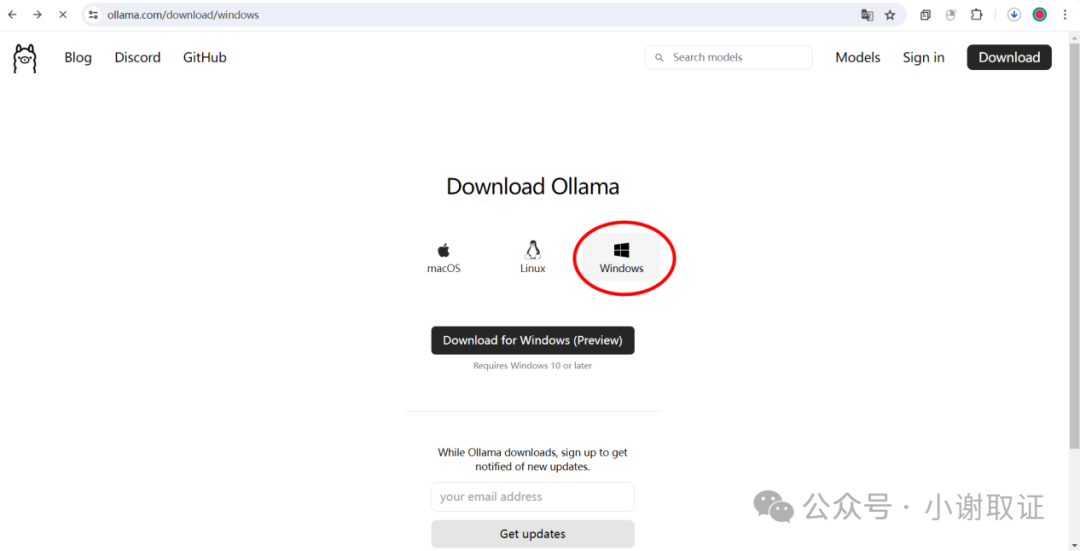
2.部署安装过程:
(1)从官网进行下载:https://ollama.com/download 选择windows系统版本,也可以看到它也同时支持mac系统和Linux系统。
但似乎它的下载速度对我来说太不友好了。于是进行科学上网下载了安装包,如有需要后台私信回复Ollama即可获取百度网盘下载地址。
安装包下载完成点击安装
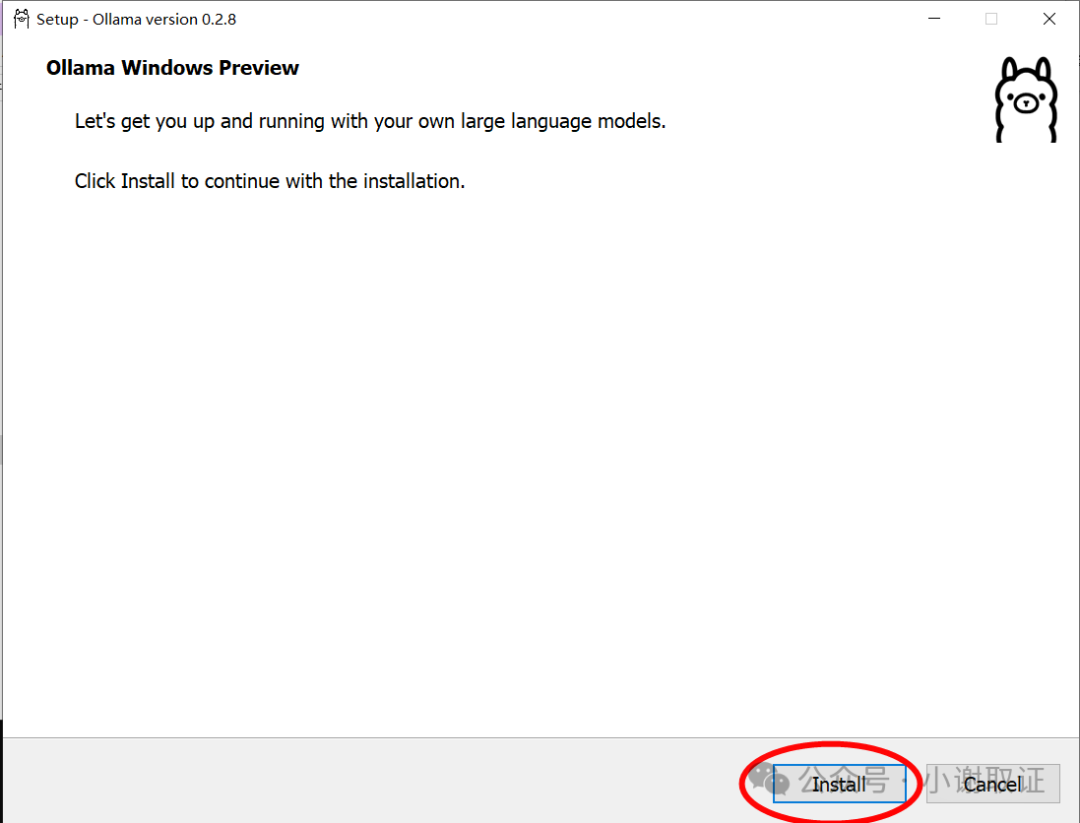
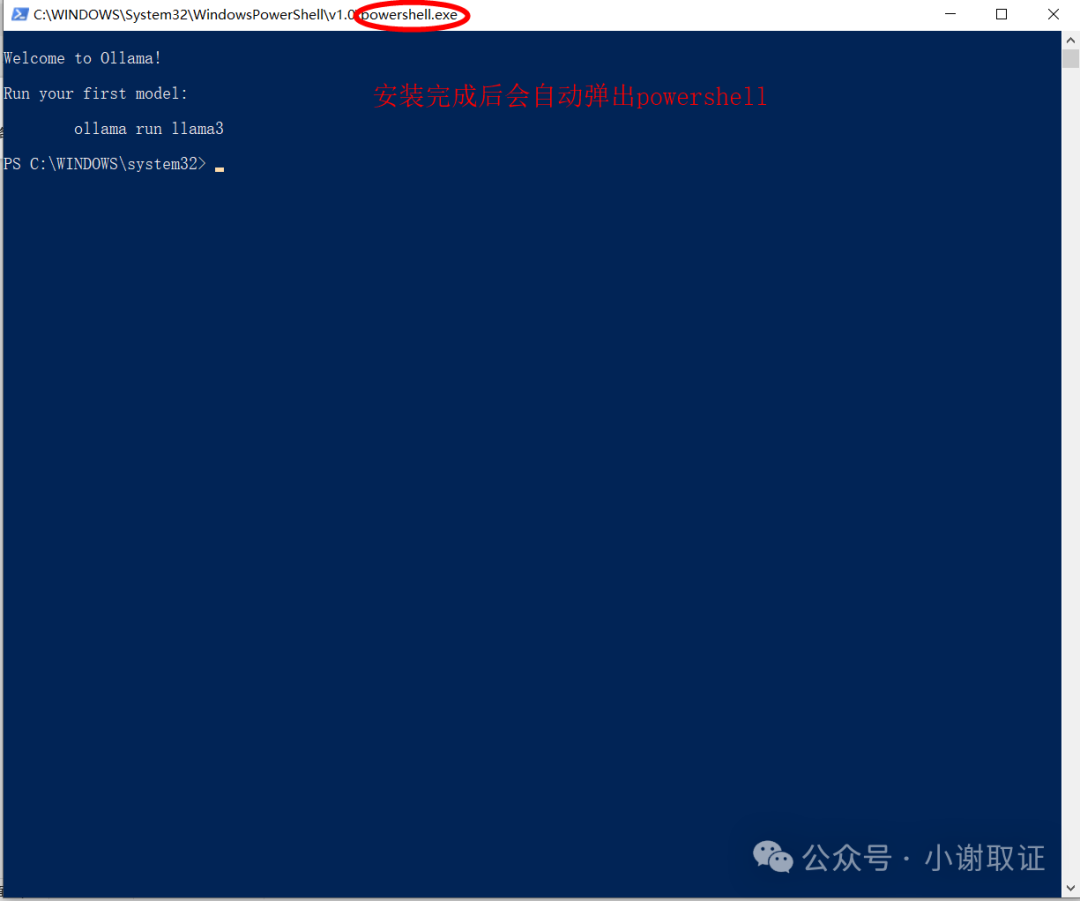
在此界面直接运行命令ollama run llama3.1,此时国内网络速度就非常快
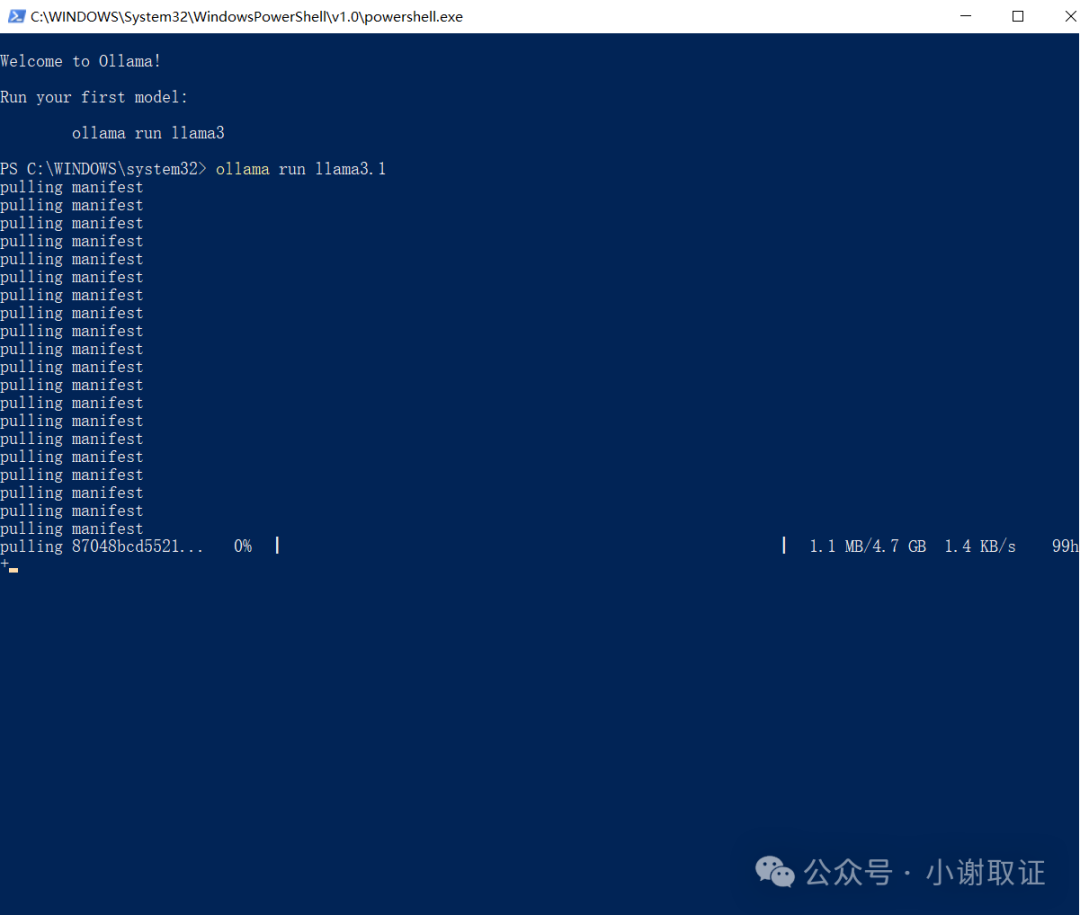
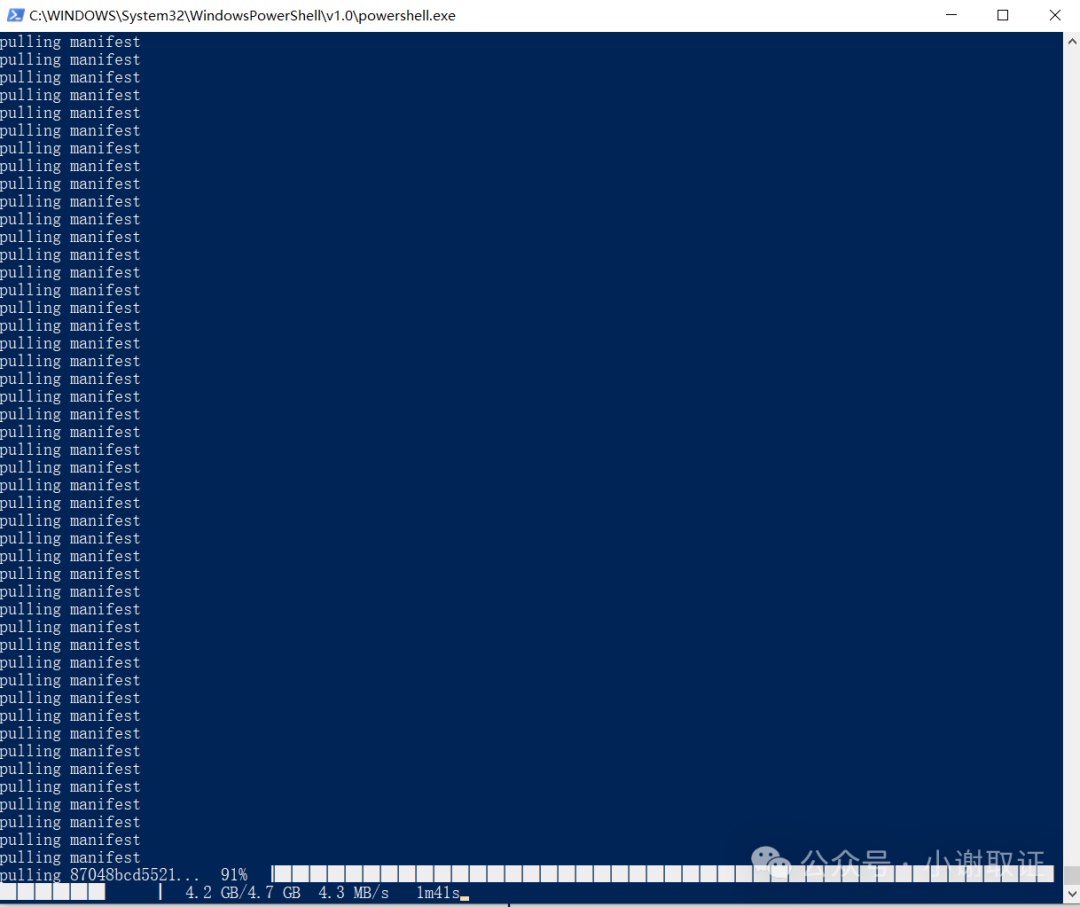
耐心等待进度条跑完即可。
当然你想要其他的大模型可以回到官网,点击Models
部署完成后可直接发送消息提问
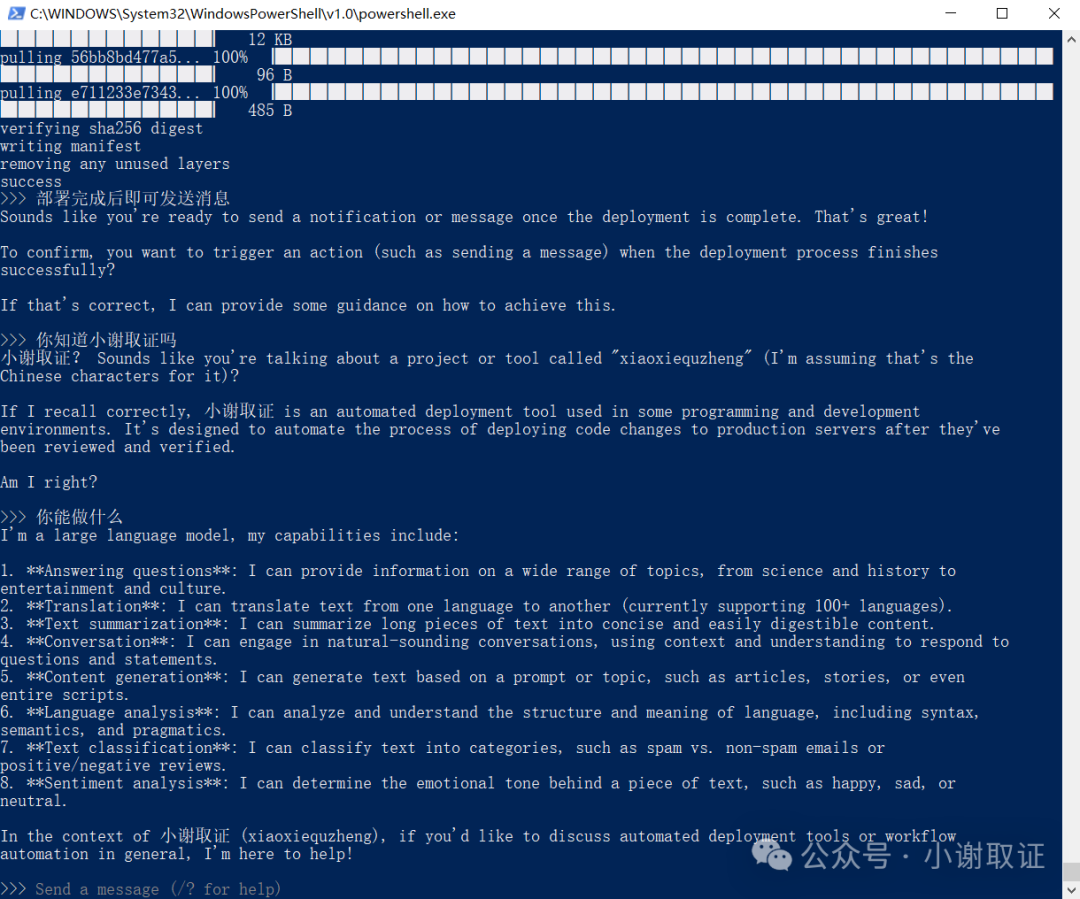
所以它能做什么呢?
我们来看看它的自述:
I’m a large language model, my capabilities include:
\1. Answering questions: I can provide information on a wide range of topics, from science and history to
entertainment and culture.
\2. Translation: I can translate text from one language to another (currently supporting 100+ languages).
\3. Text summarization: I can summarize long pieces of text into concise and easily digestible content.
\4. Conversation: I can engage in natural-sounding conversations, using context and understanding to respond to
questions and statements.
\5. Content generation: I can generate text based on a prompt or topic, such as articles, stories, or even
entire scripts.
\6. Language analysis: I can analyze and understand the structure and meaning of language, including syntax,
semantics, and pragmatics.
\7. Text classification: I can classify text into categories, such as spam vs. non-spam emails or
positive/negative reviews.
\8. Sentiment analysis: I can determine the emotional tone behind a piece of text, such as happy, sad, or
neutral.
那咱们来看它的效果!我向它抛出了一个问题:
为防止长期摸鱼导致变笨,特此准备了几道题考考你!
1.至今思项羽,不()过江东。
2.阳春布()泽,万物生光辉。
3.书籍是人类进步的阶梯。——高尔( )
4.世人笑我太()癫,我笑他人看不穿。
5.老夫聊发少年(),左牵黄,右擎苍。
6.危楼高百尺,手可摘()辰。
7.君问归期未有( ),巴山夜雨涨秋池。
8.( )面边声连角起,千嶂里,长烟落日孤城闭。
9.料峭春风吹酒醒,( )冷,山头斜照却相迎。
10.( )闻琵琶已叹息,又闻此语重唧唧。
11.锦瑟无端()()弦,一弦一柱思华年。
我们先来看一下部署在本地的大模型Llama 3.1 8B,看来效果不错。

对比一下“小谢取证”的回答:

“小谢取证”直接出答案,部署在本地的大模型Llama 3.1 8B提供了更为详细的翻译。但是两者给出的答案都有些许错误。当然,这也取决于他们的模型是否强大。
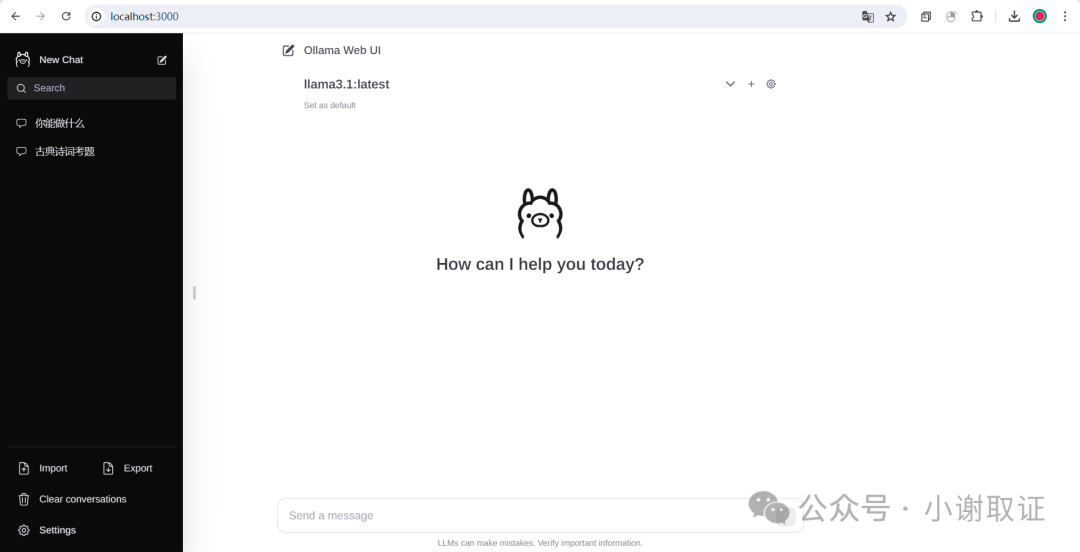
我们可以看到,我们部署到本地的界面是cmd界面下运行的,如果我们想可视化呢?先上效果图。
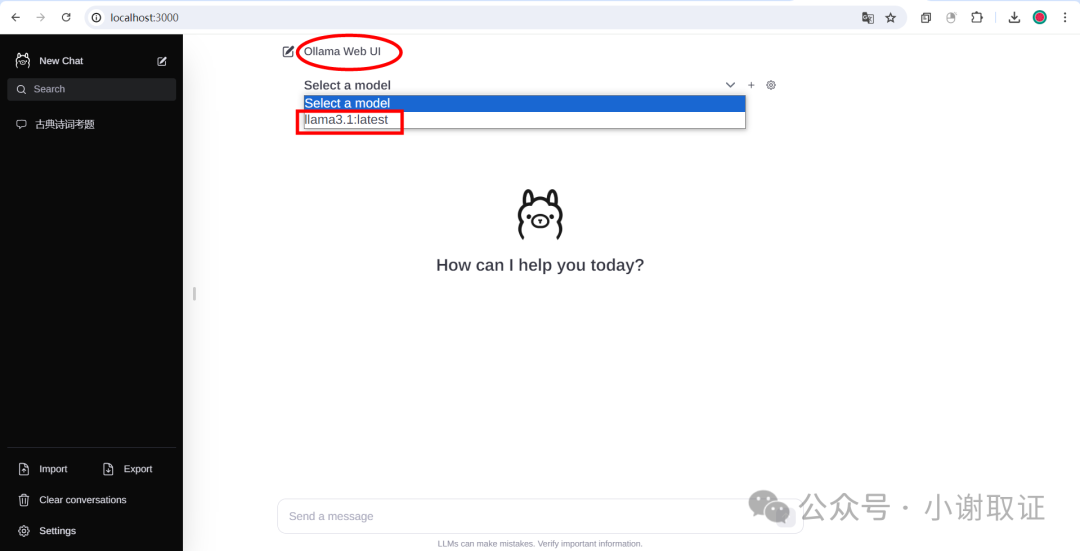
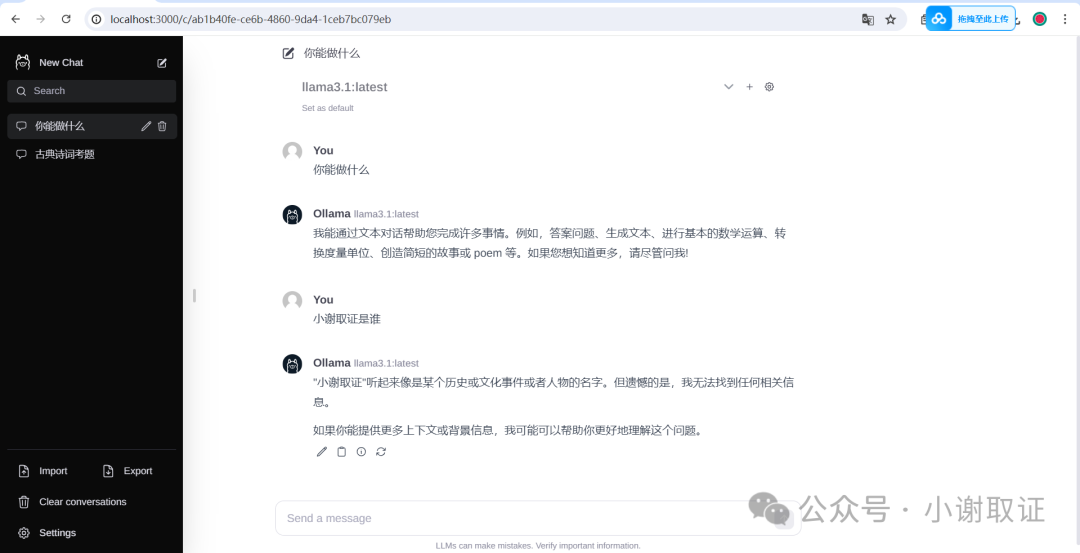
具体是用到Ollama Web UI,这边咱们直接使用大佬已集成好的环境直接使用。需要软件可后台私信。
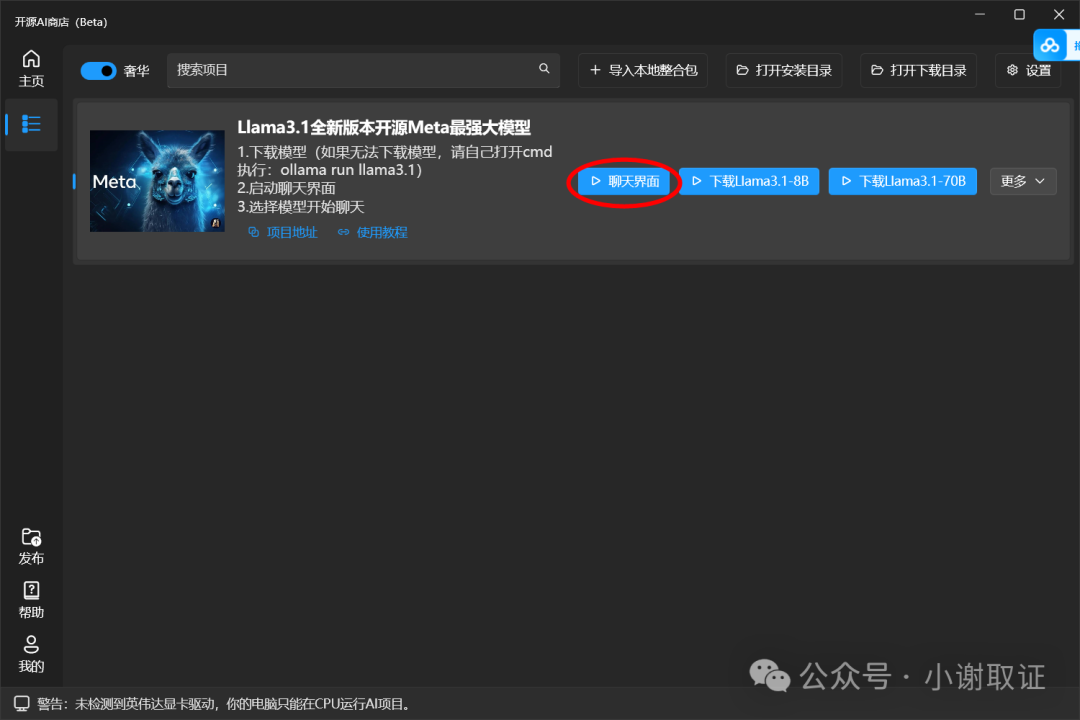
在我们使用完后,关闭该模型。那么我们下次如何重新打开呢
直接点击“开始”菜单,选择字母“O”,启动Ollama
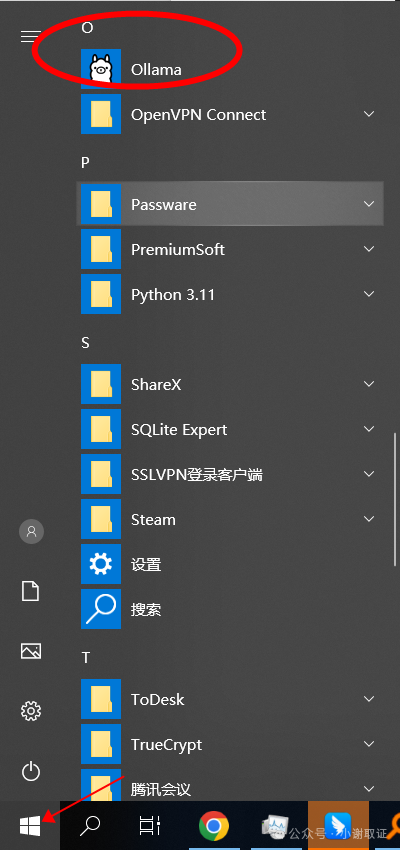
其次,直接打开该软件,点击聊天界面即可。
此时它就会自动调用命令。可以看到访问端口是3000
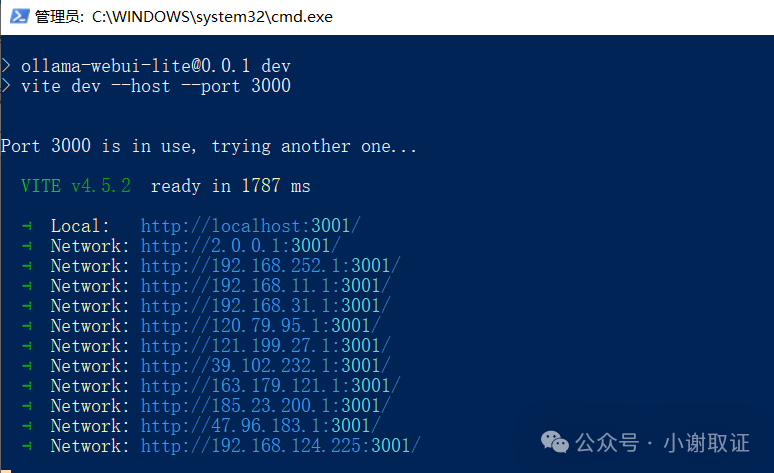
再使用http://localhost:3000/在浏览器访问即可。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 1191
1191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









