



本文系统介绍了大语言模型(LLM)的发展历程、核心特点及Scaling Law,详细分析了主流LLM采用Decoder-only架构的六大优势:更强的泛化性能、更好的语序区分能力、更适合对话场景、更高的计算效率、路径依赖以及避免低秩问题。通过对比Transformer的三种架构,阐明了Decoder-only架构在LLM领域的统治地位及其技术原理,为开发者理解大模型架构提供了全面视角。
一、大语言模型(LLM)的发展简介
1.1 简介
本部分内容主要来自[参考资料:1]
大语言模型(LLM,Large Language Model),是一种旨在理解和生成人类语言的人工智能模型。
LLM通常指包含数百亿或更多参数的语言模型,它们在海量的文本数据上进行训练,从而获得对语言深层次的理解。目前,国内外的知名LLM有GPT、LLaMA、Gemini、Claude和Grok等,国内的有DeepSeek、通义千问、豆包、Kimi、文心一言、GLM等。
为了探索性能的极限,许多研究人员开始训练越来越庞大的语言模型,例如拥有175B(1750亿)参数的GPT-3和540B(5400亿)参数的PalM、671B(6710亿)的DeepSeek-v3。尽管这些大语言模型与小型语言模型(例如3.3亿参数的BERT和15亿参数的GPT-2)使用相似架构(都是基于Transformer的架构)和预训练任务,但它们展现出截然不同的能力,尤其在解决复杂任务时表现出了惊人的潜力,这被称为“涌现能力”。以GPT-3和GPT-2为例,GPT-3可以通过学习上下文来解决少样本任务,而GPT-2在这方面表现较差。因此,科研界给这些庞大的语言模型起了个名字,称之为“大语言模型(LLM)”。LLM的一个杰出应用就是ChatGPT,它是GPT系列LLM用于与人类对话式应用的大胆尝试,展现出了非常流畅和自然的表现。
语言建模的研究可以追溯到20世纪90年代,当时的研究主要集中在采用统计学习方法来预测词汇,通过分析前面的词汇来预测下一个词汇。但在理解复杂语言规则方面存在一定局限性。
随后,研究人员不断尝试改进,2003年深度学习先驱Bengio在他的经典论文《A Neural Probalilistic Language Model》中,首次将深度学习的思想融入到语言模型中。
2017年,在论文《Attention is all you need》中提出的Transformer架构的神经网络模型开始崭露头角。Transformer架构,解决了语言建模中因为序列依赖导致的无法并行训练的问题,使得语言模型的训练速度得到了很大的提升,同时扩展了模型的上下文感知能力。也使得,使用更大的训练数据和模型参数进行训练成为了可能。
随着研究的深入,研究人员发现,语言模型规模的扩大(增加模型大小或使用更多数据),模型展现出了一些惊人的能力,在各种任务中的表现均显著提升(Scaling Law)。这一发现标志着大语言模型(LLM)时代的开启。
1.2 Scaling Law
通常大模型由三个阶段构成:预训练、后训练和在线推理。在2024年9月之前,大模型领域仅存在预训练阶段的Scaling Law。然而,随着OpenAI o1的推出,后训练和在线推荐阶段也各自拥有了Scaling Law,即后训练阶段的强化学习Scaling Law(RL Scaling Law)和在线推理阶段的Inference Scaling Law(Test Time Scaling Law)。如下图所示,随着各阶段计算的增加,大模型的性能不断增长。
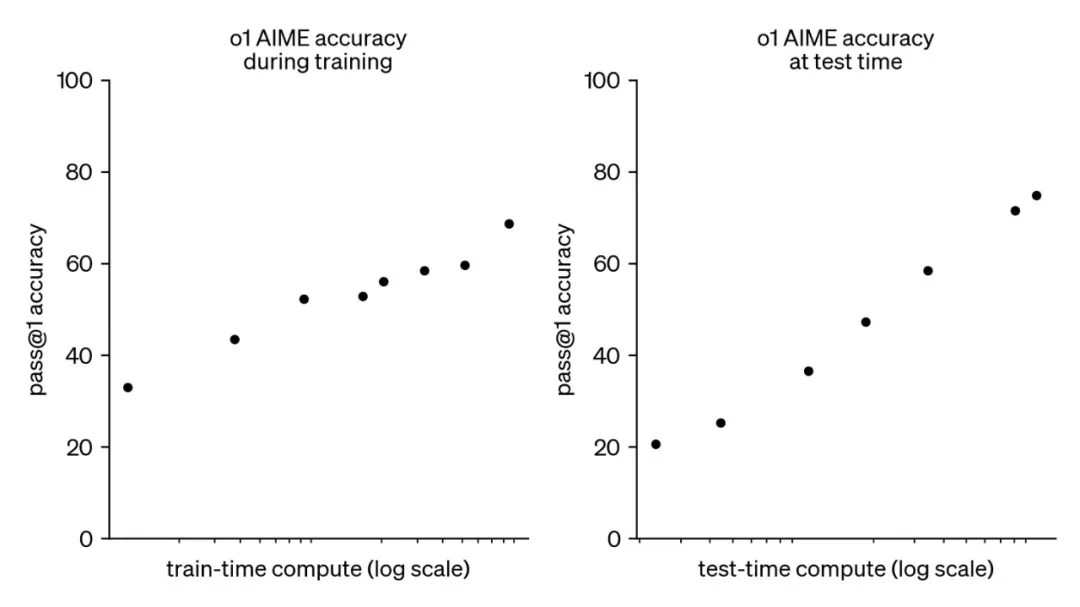
图1.1 train和test time的scaling law
1.3 大模型的特点
大语模型具有多种显著特点,这些特点使它们在自然语言处理和其他领域中引起了广泛的兴趣和研究。以下是大语言模型的一些主要特点:
- 巨大的规模和高计算资源需求:LLM通常具有巨大的参数规模,可以达到数十亿甚至数千亿个参数。这使得它们能够捕捉更多的语言知识和复杂的语法结构。同时,LLM参数规模庞大,需求大量的计算资源进行训练和推理。通常需要使用高性能的GPU集群来实现。
- 上下文感知:LLM在处理文本时具有强大的上下文感知能力,能够理解和生成依赖于前文的文本内容。这使得它们在对话、文章生成和情境理解方面表现出色。
- 多模态和多语言支持:当前部分LLM已经扩展到支持多模态数据,包括文本、图像和声音。使得它们可以理解和生成不同媒体类型的内容,实现更多样化的应用。同时,当前大部分LLM支持多语言交互,LLM的多语言能力使得跨文化和跨语言的应用变得更加容易。
- 伦理和风险问题:尽管LLM具有出色的能力,但它们也引发了伦理和风险问题,包括生成有害内容、隐私问题、认知偏差等。
大语言模型是一种具有强大语言处理能力的技术,已经在多个领域展示了潜力。它们为自然语言理解和生成任务提供了强大的工具,同时也引发了对其伦理和风险问题的关注。这些特点使LLM成为了当今计算机科学和人工智能领域的重要研究和应用方向。
1.4 大模型的发展路径
本部分内容主要来自[参考资料:5]
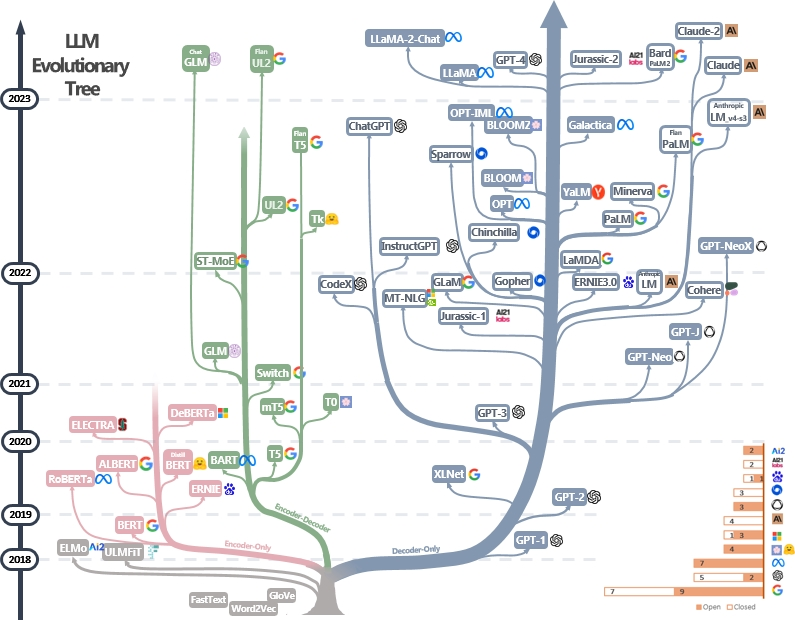
图1.2 LLM的进化树(来自[参考资料:6])
现代的语言模型,基于在2017的Transformer出来后,就被逐步统一了,如上图所示,除了左下角灰色部分的模型,不是基于此架构外,其它的模型基本都基于Transformer进行改造和优化。其中,蓝色分支为仅解码器模型(Decoder-only),也是GPT采用的路线,当前大模型的主流架构;粉红色分支为仅编码器模型(Encoder-only);绿色分支为编码器-解码器模型(Encoder-Decoder)。时间轴上模型的垂直位置代码其发布日期。开源模型由实心方块表示,而闭源模型由空心方块表示。右下解的堆叠条形图显示来自各公司和机构的模型数据。
仅解码器模型在语言模型的发展中逐渐占主导地位。在语言模型发展的早期阶段,仅解码器模型不如仅编码器模型、编码器-解码器模型流利。然后,在2021年之后,随着改变游戏规则的语言模型GPT-3推出,仅解码器模型经历了显著的繁荣。与此同时,在BERT带来的初始爆炸性增长后,仅编码器模型逐渐开始消失。
编码器-解码器模型仍然具有前景,因为这种体系结构仍在积极探索中,并且大多数都是开源的。Google对开源编码器-解码器架构做出了重大贡献,有传闻,Google最新推出的Gemini模型是基于编码器-解码器架构开发的([参考资料:2])。
1.4.1 OpenAI的研究路径
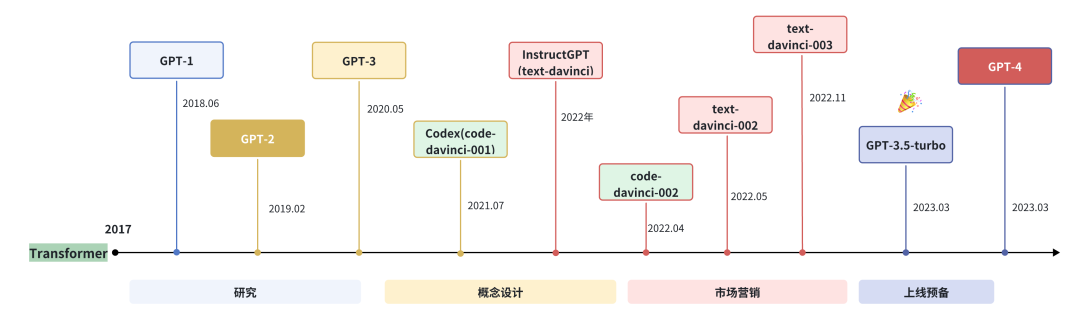
图1.3 GPT系列模型发展路径
OpenAI公司在2018年提出的GPT(Generative Pre-Training)模型是典型的生成式预训练语言模型之一。
GPT模型的基本思想是通过语言建模将世界知识压缩到仅解码器的Transformer模型中,这样它就可以记忆(或恢复)世界知识的语义,并充当通用任务求解器。它能够成功的两个关键点:
- 训练能够准确预测下一个单词的模型;
- 大大扩展了语言的大小。
目前,GPT系列模型已形成知识型和推理型两大技术分支。
- 知识型模型:
2022年11月,OpenAI发布了基于GPT模型(GPT3.5和GPT-4)的会话应用ChatGPT。由于与人类交流的出色能力,ChatGPT自发布以来就引发了人工智能社区的兴奋。上线后用户增长迅速,5天注册人数突破100万,两个月后月活用户破亿,成为当时史上用户增长最快的消费级应用程序(之前这一记录的保持者是Tiktok的9个月)。
2023年3月,发布的GPT-4引入了多模态能力,相比GPT-3.5的1750亿参数,GPT-4规模显著扩大(推测约1.8万亿参数),在解决复杂任务和评估任务上展现出较大的性能提升。
2024年5月,发布的GPT-4o(“o”代表“omni”全能)具备对文本、语音、图像三种模态的深度理解能力。
2024年7月,发布的GPT-4o mini是一款面向消费级应用的轻量级模型,价格更加亲民,适应日常对话和基础任务场景。
2025年2月,发布的GPT-4.5在知识广度、推理深度和创意表达方面有显著提升,特别强化了对客观事实的准确性,尤其是在情商方面异常优秀。上下文长度扩展至512K。
2025年4月,发布了GPT-4.1继承了 GPT-4o 和 GPT-4.5 的优点,并在多个方面进行了优化和提升,并将上下文长度扩展到了1M(100万)。
- 推理型模型:
2024年9月,发布的o1-mini、o1-preview是专为复杂推理设计的模型,在回答前会先生成一段思维链(不公开),优先考虑精确性和推理步骤的正确性。
2025年1月,发布的o3-mini可以显示部分思维链,与o1相比,响应速度更快。
2025年4月,发布了o3和o4-mini。o4-mini比o3较弱,精准稍低,但是预算更友好,速度更快。
1.4.2 LLaMA的研究路径
LLaMA系列模型是Meta开源的一组参数规模从8B到405B的基础语言模型。
2023年2月,发布LLaMA。
2023年7月,发布了LLaMA2模型。
2024年4月,发布了LLaMA3模型。
2024年7月,发布了LLaMA3.1模型,发布了8B、70B和405B三个规模的模型,分别提供基础版(Base)和指令微调版(Instruct)。
2024年12月,发布了LLaMA3.3模型(只开源了70B的指令模型)。
2025年4月,发现在了基于MoE架构的LLaMA4模型,包括109B、400B两个版本,以及参数量高达20T(2万亿)的未开源版本。
1.4.3 DeepSeek的研究路径
DeepSeek是由深度求索团队开发的开源大语言模型系列。
2023年11月,发布DeepSeek系列基础模型,包括7B和67B两种规模的Base和Chat版本。模型在12T(1.2万亿)token上进行训练,同时发布了DeepSeek-Coder专用代码生成模型。
2024年3月,发布DeepSeek-V2,提升了多语言能力、长文本理解和推理能力,同时发布了DeepSeek-MoE混合专家模型。
2024年5月,发布了DeepSeek-V2.5,性能得到进一步提升,上下文长度扩展至128K,并改进了工具调用和多模态能力。
2024年10月,发布DeepSeek-V3,参数量为671B,在推理能力、多语言理解和创意生成方面有显著提升,支持更复杂的系统提示词控制,并进一步提升了代码质量和多轮对话一致性。
2025年2月,发布DeepSeek-R1推理型大模型,是首个开源的推理型大模型,在多项基准测试中超越了o1系列。以及,DeepSeek-R1-Zero直接采用大规模强化学习(RL)训练的模型,无需SFT,在推理方面十分出色。同时,开源了用LLaMA和Qwen从DeepSeek-R1中蒸馏出的六个模型。其中,DeepSeek-R1-Distill-Qwen-32B在各种基准测试中均优于OpenAI的o1-mini。
后续DeepSeek还分别在2025年3月和5月,对DeepSeek-V3模型进行了两次升级,模型能力进一步提升。
借助着DeepSeek-R1的卓越能力,DeekSeep成为了现象级爆火应用。7天完成了1亿用户的增长,打破了ChatGPT的2个月的最快记录,成为史上增长最快的AI应用。
二、Why are decoder-only for most LLMs?
2.1 架构介绍
2.1.1 Transformer
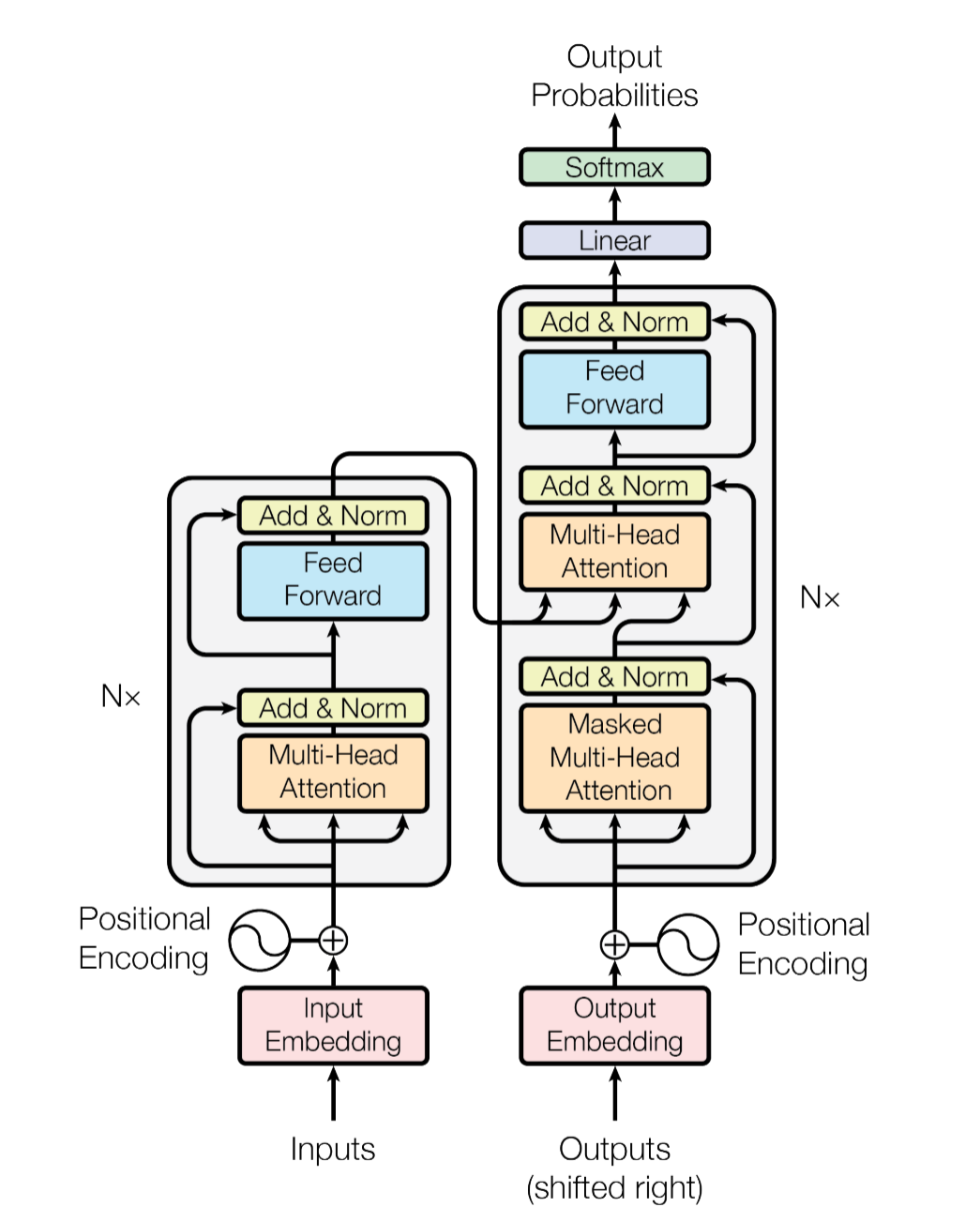
图2.1 Transformer模型架构(来自[参考资料:7])
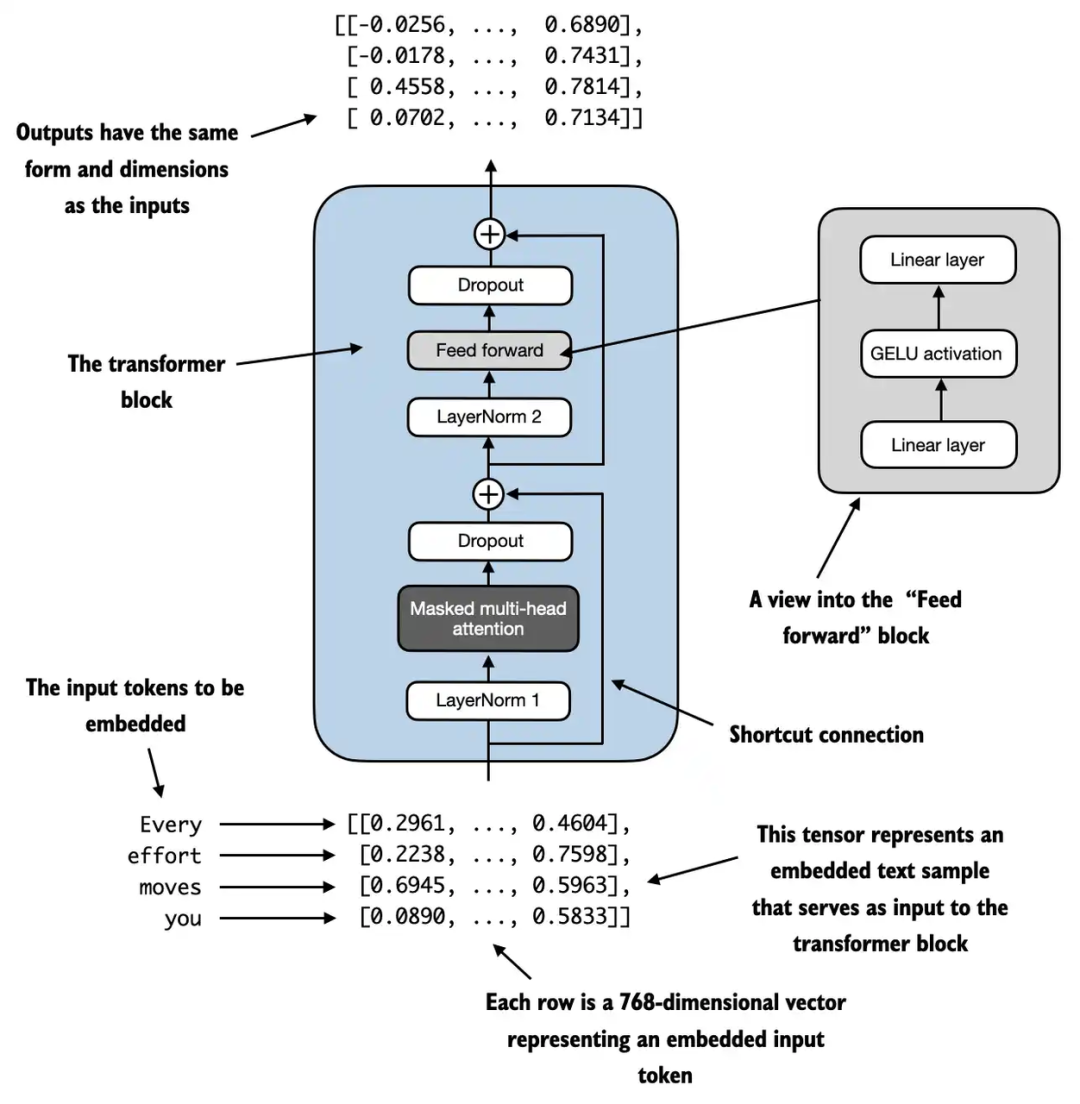
图2.2 GPT-2模块使用的Decoder-only的Transformer模块
在1.4的部分,我们已经介绍了,基于Transformer的模型,现在主要分为编码器-解码器(Encoder-Decoder)、仅编码器(Encoder-only)、仅解码器(Decoder-only)三种架构,目前来看,大语言模型采用的主要流的架构是仅解码器架构,编码器-解码器架构还有部分人在研究,而仅编码器架构由于并不适合“文本生成”的任务,基本没有采用。
如图2.1所示,我们从《Attention is all you need》论文中提出的架构开始。首先,需要知道的是,当时Transformer模型的提出,主要是用于解决序列到序列的建模任务(Seq-to-Seq),论文主要提到的是“德语-英语”翻译任务。而当时的翻译任务的模型架构就是以编码器-解码器为主的,处理流程是,先对源语言的信息进行编码,再通过解码器逐步进行解码实现翻译功能,这也是初版的Transformer采用编码器-解码器架构的原因。
图2.1左侧的部分是模型的编码器部分,主要由三部分组成:
嵌入层。
- 包括Token Embedding编码输入文本信息,Position Embedding编码文本的位置信息。
注意力模块。
- 这里是自注意力模块。
- 全连接模块。
图2.1右侧的部分是模型的解码器部分,主要由四部分组成:
- 嵌入层。
- 同上
- 注意力模块。
- 因果(causal)的自注意力模块,对未来信息进行了掩蔽(mask)。
- 交叉注意力模块。
- 用于整合编码器和解码器的交叉信息。
- 全连接模块。
结合之前分享的《从头构建大模型》中的GPT-2模型中使用的Decoder-only的Transformer架构,如图2.2所示,主要包括:
- • 嵌入层。
- • 同上
- • 注意力模块。
- • 同解码器中的因果自注意力模块。
- • 全连接模块。
我们可以发现,当前大模型使用的Decoder-only的结构,与原版模型的解码器部分有一些差异,因为去除了编码器,连带的解码器中的交叉注意力模块也移除了。可以看到,其实从结构上来讲,模型的结构更接近编码器,同样由嵌入层、注意力模块、全连接模块组成,但从功能上来讲,无疑是解码器的功能(用于文本生成)。
代码示例:Transformer模块
此处代码参考了[参考资料:8]
在之前分享的《从头构建大模型》的第三部分,已经给出了Decoder-only架构的代码示例,这里补充一下,原版的Encoder-Decoder的Transformer模型代码,部分重复的模块(如归一化层、前向网络层等),可以直接参考之前的文章。
1、 编码器。
- 嵌入层;
- 注意力模块;
- 全连接模块。
2、 解码器。
- 交叉注意力模块;
- 全连接模块。
- 嵌入层;
- 注意力模块;
值得一提:Transformer模型也采用ResNet的残差连接,具体可参考代码实现。
注意力模块
import math
class ScaleDotProductAttention(nn.Module):
"""
compute scale dot product attention
Query : given sentence that we focused on (decoder)
Key : every sentence to check relationship with Qeury(encoder)
Value : every sentence same with Key (encoder)
"""
def __init__(self):
super().__init__()
def forward(self, q, k, v, mask=None, e=1e-12):
# input is 4 dimension tensor
# [batch_size, head, length, d_tensor]
batch_size, head, length, d_tensor = k.shape
# 1. dot product Query with Key^T to compute similarity
k_t = k.transpose(2, 3) # transpose
score = (q @ k_t) / math.sqrt(d_tensor) # scaled dot product
# 2. apply masking (opt)
if mask is not None:
# 翻译第一个词时,会mask所有词,因此需要使用-1e9而不是-torch.inf,否则会出现nan
score.masked_fill_(~mask.bool(), -1e9)
# 3. pass them softmax to make [0, 1] range
score = torch.softmax(score, dim=-1)
# 4. multiply with Value
v = score @ v
return v, score
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_head):
super(MultiHeadAttention, self).__init__()
self.n_head = n_head
self.attention = ScaleDotProductAttention()
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_concat = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
# 1. dot product with weight matrices
q, k, v = self.w_q(q), self.w_k(k), self.w_v(v)
# 2. split tensor by number of heads
q, k, v = self.split(q), self.split(k), self.split(v)
# 3. do scale dot product to compute similarity
out, attention = self.attention(q, k, v, mask=mask)
# 4. concat and pass to linear layer
out = self.concat(out)
out = self.w_concat(out)
# 5. visualize attention map
# TODO : we should implement visualization
return out
def split(self, tensor):
"""
split tensor by number of head
:param tensor: [batch_size, length, d_model]
:return: [batch_size, head, length, d_tensor]
"""
batch_size, length, d_model = tensor.shape
head_dim = d_model // self.n_head
tensor = tensor.view(batch_size, length, self.n_head, head_dim).transpose(1, 2)
# it is similar with group convolution (split by number of heads)
return tensor
def concat(self, tensor):
"""
inverse function of self.split(tensor : torch.Tensor)
:param tensor: [batch_size, head, length, d_tensor]
:return: [batch_size, length, d_model]
"""
batch_size, head, length, d_tensor = tensor.shape
d_model = head * d_tensor
tensor = tensor.transpose(1, 2).contiguous().view(batch_size, length, d_model)
return tensor
编码器模块
class EncoderLayer(nn.Module):
def __init__(self, d_model, hidden_dim, num_heads, drop_prob):
super().__init__()
# att模块
self.att = MultiHeadAttention(d_model, num_heads)
self.norm1 = LayerNorm(d_model)
self.dropout1 = nn.Dropout(drop_prob)
# ffn模块
self.ffn = FeedForward(d_model, hidden_dim, drop_prob)
self.norm2 = LayerNorm(d_model)
self.dropout2 = nn.Dropout(drop_prob)
def forward(self, x, src_mask):
# att+shortcut
shortcut = x
x = self.att(x, x, x, src_mask)
x = self.dropout1(x)
x = self.norm1(x + shortcut)
# ffn+shortcut
shortcut = x
x = self.ffn(x)
x = self.dropout2(x)
x = self.norm2(x + shortcut)
return x
class Encoder(nn.Module):
def __init__(self, vocab_size, max_len, d_model, hidden_dim, num_heads, num_layers, drop_prob):
super().__init__()
self.emb = TransformerEmbedding(vocab_size, d_model, max_len, drop_prob)
self.layers = nn.ModuleList(
[EncoderLayer(
d_model,
hidden_dim,
num_heads,
drop_prob
) for _ in range(num_layers)]
)
def forward(self, x, src_mask):
x = self.emb(x)
for layer in self.layers:
x = layer(x, src_mask)
return x
解码器模块
class DecoderLayer(nn.Module):
def __init__(self, d_model, hidden_dim, num_heads, drop_prob):
super().__init__()
# att模块
self.self_att = MultiHeadAttention(d_model, num_heads)
self.norm1 = LayerNorm(d_model)
self.dropout1 = nn.Dropout(drop_prob)
# att模块
self.cross_att = MultiHeadAttention(d_model, num_heads)
self.norm2 = LayerNorm(d_model)
self.dropout2 = nn.Dropout(drop_prob)
# ffn模块
self.ffn = FeedForward(d_model, hidden_dim, drop_prob)
self.norm3 = LayerNorm(d_model)
self.dropout3 = nn.Dropout(drop_prob)
def forward(self, dec_x, enc_x, trg_mask, src_mask):
# att+shortcut
shortcut = dec_x
x = self.self_att(dec_x, dec_x, dec_x, trg_mask)
x = self.dropout1(x)
x = self.norm1(x + shortcut)
# cross att+shortcut
if enc_x is not None:
shortcut = x
x = self.cross_att(x, enc_x, enc_x, src_mask)
x = self.dropout2(x)
x = self.norm2(x + shortcut)
# ffn+shortcut
shortcut = x
x = self.ffn(x)
x = self.dropout3(x)
x = self.norm3(x + shortcut)
return x
class Decoder(nn.Module):
def __init__(self, vocab_size, max_len, d_model, hidden_dim, num_heads, num_layers, drop_prob):
super().__init__()
self.emb = TransformerEmbedding(vocab_size, d_model, max_len, drop_prob)
self.layers = nn.ModuleList(
[DecoderLayer(
d_model,
hidden_dim,
num_heads,
drop_prob
) for _ in range(num_layers)]
)
self.out_proj = nn.Linear(d_model, vocab_size)
def forward(self, dec_x, enc_x, trg_mask, src_mask):
x = self.emb(dec_x)
for layer in self.layers:
x = layer(x, enc_x, trg_mask, src_mask)
x = self.out_proj(x)
return x
Transformer模块
class Transformer(nn.Module):
def __init__(self, src_pad_idx, trg_pad_idx, trg_sos_idx, d_model, enc_voc_size, dec_voc_size, max_len, ffn_hidden, n_heads, n_layers, drop_prob):
super().__init__()
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
self.trg_sos_idx = trg_sos_idx
self.encoder = Encoder(
enc_voc_size,
max_len,
d_model,
ffn_hidden,
n_heads,
n_layers,
drop_prob
)
self.decoder = Decoder(
dec_voc_size,
max_len,
d_model,
ffn_hidden,
n_heads,
n_layers,
drop_prob
)
def forward(self, src, tgt):
src_mask = self.make_src_mask(src)
trg_mask = self.make_trg_mask(tgt)
enc_x = self.encoder(src, src_mask)
output = self.decoder(tgt, enc_x, trg_mask, src_mask)
return output
# 生成源语言的mask
def make_src_mask(self, src):
# 创建一个mask,用于屏蔽源语言的pad token
src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)
return src_mask
# 生成目标语言的mask
def make_trg_mask(self, tgt):
# 创建一个mask,用于屏蔽目标语言的pad token
trg_pad_mask = (tgt != self.trg_pad_idx).unsqueeze(1).unsqueeze(3)
# 创建一个mask,用于屏蔽目标语言的subsequent token
trg_len = tgt.shape[1]
trg_sub_mask = torch.tril(torch.ones(trg_len, trg_len)).type(torch.ByteTensor)
trg_mask = trg_pad_mask & trg_sub_mask
return trg_mask
2.2 decoder-only 架构的优势
此部分参考了[参考资料:2、4]
铺垫了这么久,终于要来回答该部分的标题“为什么现在的大模型都以Decoder-only的架构为主?”
- Decoder-only的架构泛化性能更好。相关的研究发现,用next toekn prediction方式进行训练的Decoder-only模型,在zero-shot和few-shot的场景下,都有比较强的泛化能力。
- Decoder-only的模型有更强的语序区分能力。Causal Attention具有隐式的位置编码功能,在双向Attention中部分token对换位置也不改变其表示,对语序的区分能力天生较弱。
- Decoder-only的架构更适合对话场景。研究表明,prompt信息可以视为对模型参数的隐式微调,而该微调会对Decoder-only架构的模型有更直接的效果,因为在用于生成文本前,prompt不需要先转换成中间语境(上下文向量)。虽然对Encoder-Decoder的架构应该也能起作用,但不如Decoder-only架构直接。
- Decoder-only的架构效率更高。Decoder-only架构的每个token的只和它之前的输入有关,因此支持利用KV-Cache保留历史计算后的token表示,对多轮对话更友好,计算成本更低。
- 路径依赖。由于OpenAI采用的就是Decoder-only的架构,且取得了很好的效果,后来者出于时间和成本的考虑,大多沿用该架构。
- 低秩问题(影响较小)。双向attention的注意力矩阵容易退化为低秩状态,而因果注意力的注意力矩阵是下三角矩阵,必然是满秩的,建模能力更强。需要强调的是,在模型训练充分的情况下,并不会带来显著的差异。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


为什么要学习大模型?
我国在A大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着AI技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国AI产业的创新步伐。加强人才培养,优化教育体系,国际合作并进是破解困局、推动AI发展的关键。


大模型入门到实战全套学习大礼包
1、大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!

2、大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。

3、AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

4、大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。

5、大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

适用人群

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 1243
1243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









