







LLaMA Factory
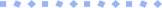
LLaMA Factory是一款开源低代码大模型微调框架,集成了业界最广泛使用的微调技术,支持通过 Web UI 界面零代码微调大模型,目前已经成为开源社区内最受欢迎的微调框架之一,GitHub 星标超过 4.7 万。
本教程将基于通义千问团队开源的新一代多模态大模型 Qwen2-VL-2B-Instruct,介绍如何使用 矩池云 平台及 LLaMA Factory 训练框架完成文旅领域大模型的构建。
GitHub地址:https://github.com/hiyouga/LLaMA-Factory
一
直接使用LLaMA-Factory镜像
注:最新版LLaMa-Factory已经上线
选择机器:显卡型号:4090 24G显存 (为保证下载速度,请选择亚太 2 区的机器)
租用实例时,请搜索关键词LLaMaFactory选择镜像LLaMA-Factory20250424(自动启动WebUI)或者LLaMA-Factory20250424(手动启动WebUI)即可使用
LLaMA-Factory20250424(自动启动WebUI)开机后,会自动启动Web UI服务
LLaMA-Factory20250424(手动启动WebUI)开机后,需要通过命令手动启动服务:llamafactory-cli webui
实例运行后,可通过「我的实例」页面中的服务链接进行访问。
二
亲自部署LLaMA-Factory
如果想亲自在实例上部署LLaMA-Factory,则步骤如下:
01
启动实例
- 显卡型号:4090 24G显存 (为保证下载速度,请选择亚太 2 区的机器)
- 镜像:Pytorch 2.5.1
- 配置端口号:8080(WebUI 服务) 11434(API 服务)
- 设置环境变量:GRADIO_SERVER_PORT=8080 (定义 Gradio webUI 服务的端口号,注:环境变量只能在 terminal 中查看,notebook 无法查看)
02
去除国内镜像源
如果您使用的是亚太 2 区的机器,则在部署之前,先去除默认的国内 pip 源:
具体方法在matpool主站右下角点击“客服”寻问AI客服:“如何去除pip源”
03
安装LLaMA-Factory
实例中运行:

实例中运行:
llamafactory-cli webui #注意请在LLaMA-Factory目录下运行这条命令
注:如果实例不在亚太2区,则配置modelhub下载模型
USE_MODELSCOPE_HUB=1 llamafactory-cli webui
# USE_MODELSCOPE_HUB 设为 1,表示模型从 ModelScope 魔搭社区下载。避免从 HuggingFace 下载模型导致网速不畅。
服务启动后,可通过“我的实例”页面中的服务链接进行访问。
三
使用LLaMA-Factory微调模型
01
准备数据集
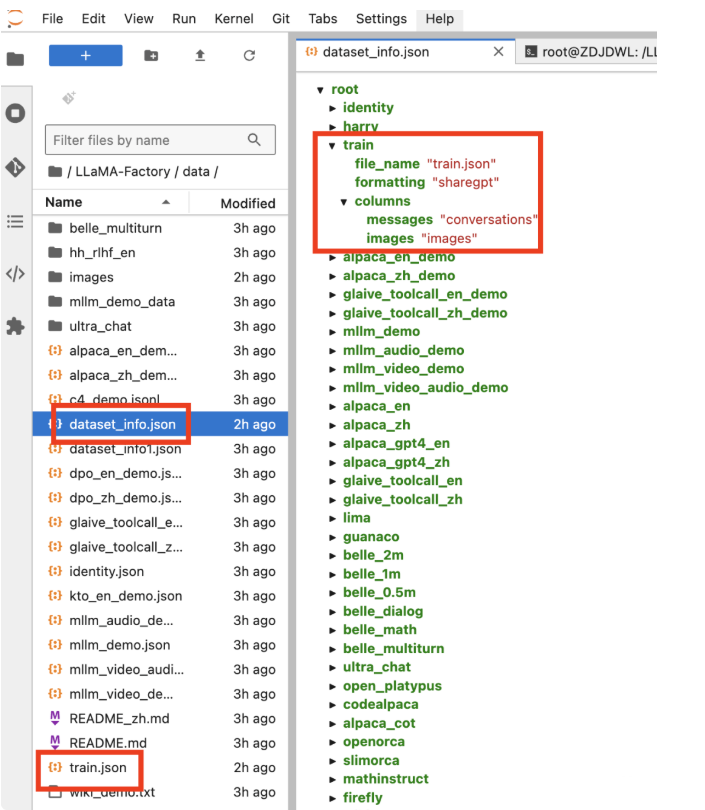
LLaMA-Factory 项目内置了丰富的数据集,放在了 data 目录下。您可以跳过本步骤,直接使用内置数据集。您也可以准备自定义数据集,将数据处理为框架特定的格式,放在 data 下,并且修改 dataset_info.json 文件。
如果直接使用了LLama-Factory镜像,则用户可直接在data目录下查看到images文件夹和train.json数据集,并且已经在dataset_info.json中加入train数据集。
如果是按照步骤二自己部署的 LLaMA-Factory,则可自行下载数据集并存放到 data 目录:
wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/llama_factory/Qwen2-VL-History.zip
mv data rawdata && unzip Qwen2-VL-History.zip -d data # 这一步会将原LLaMA-Facroty 目录下的 data 文件转移到rawdata中
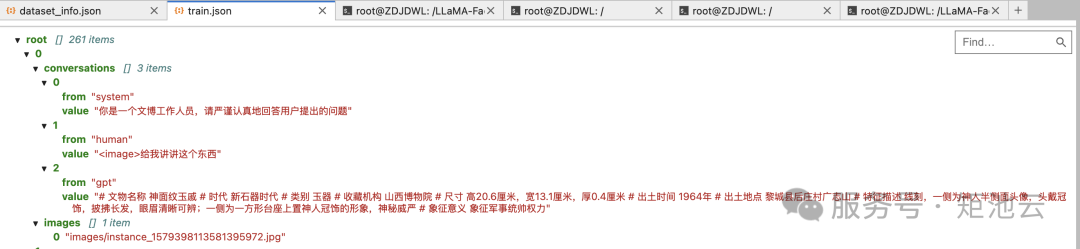
数据集中的样本为单轮对话形式,含有 261 条样本,每条样本都由一条系统提示、一条用户指令和一条模型回答组成,微调过程中模型不断学习样本中的回答风格,从而达到学习文旅知识的目的。
数据样例如下所示:
02
模型微调
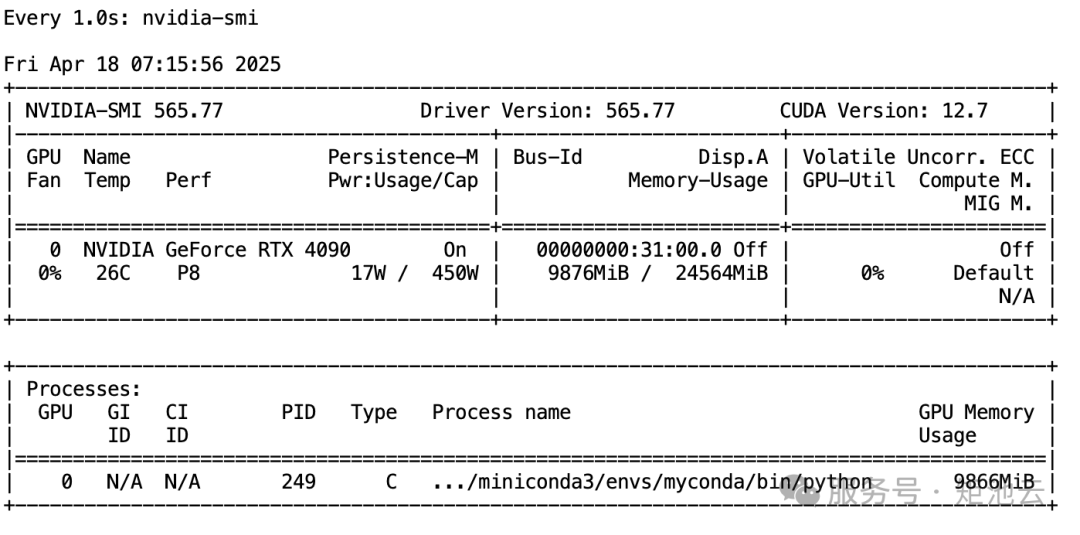
2.1 监控显存使用情况
在微调过程中,需要持续观测显存用量,及时发现显存用超的情况:
watch -n 1 nvidia-smi
2.2 配置参数
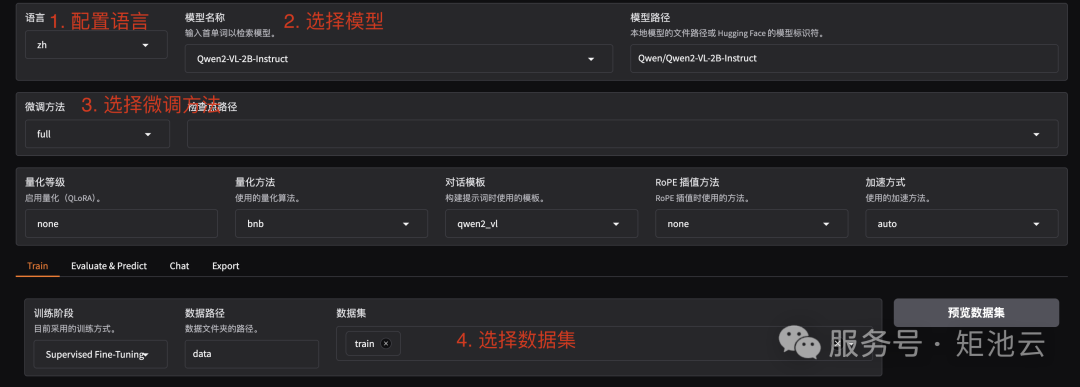
进入 WebUI 后,可以切换语言到中文(zh)。首先配置模型,本教程选择Qwen2-VL-2B-Instruct模型,微调方法修改为 full,针对小模型使用全参微调方法能带来更好的效果。
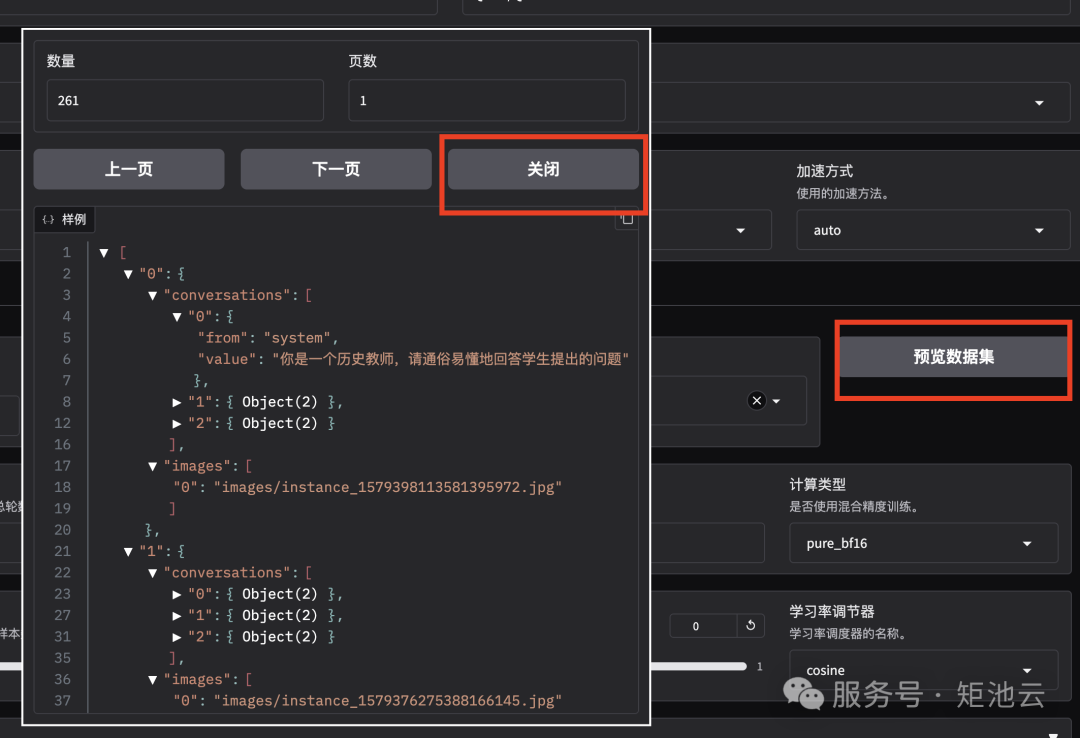
可以点击「预览数据集」按钮查看训练数据;点击「关闭」按钮返回训练界面:
设置学习率为 1e-4,训练轮数为 10,更改计算类型为 pure_bf16,梯度累积为 2,有利于模型拟合。在其他参数设置区域修改保存间隔为 1000,节省硬盘空间。
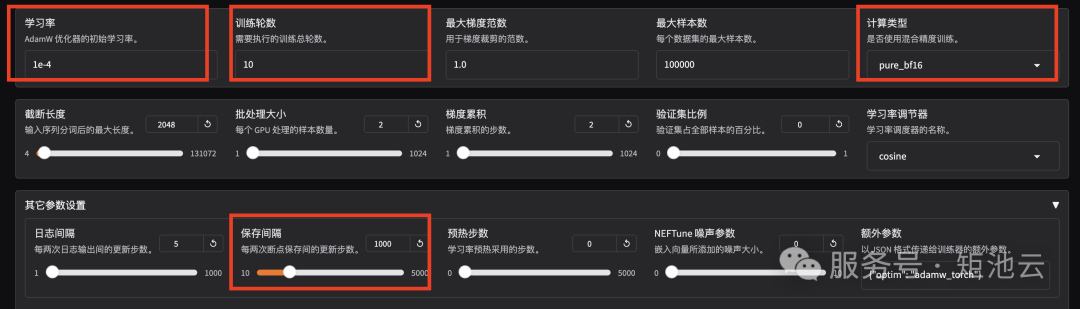
2.3 启动微调
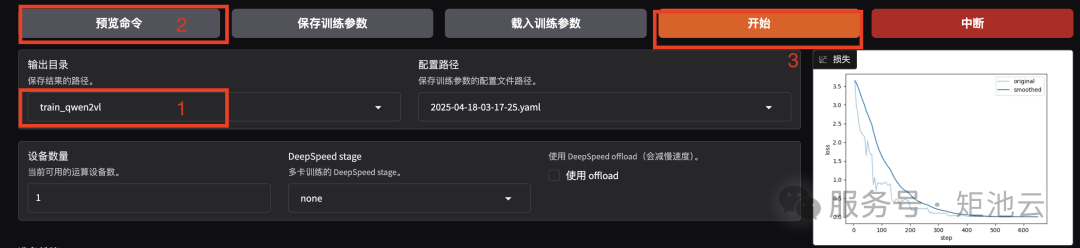
- 将输出目录修改为
train_qwen2vl,训练后的模型权重将会保存在此目录中。 - 点击「预览命令」可展示所有已配置的参数,如果想通过代码运行微调,可以复制这段命令,在命令行运行。
- 点击「开始」启动模型微调。
- 启动微调后需要等待一段时间,待模型下载完毕后可在界面观察到训练进度和损失曲线。模型微调大约需要 14 分钟,显示“训练完毕”代表微调成功。
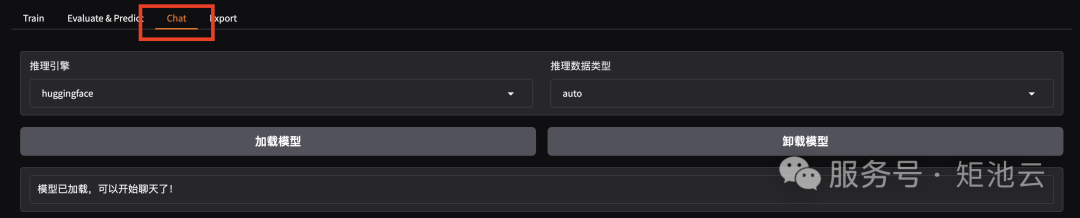
2.4 模型对话
将检查点路径改为 train_qwen2vl

选择「Chat」栏,点击「加载模型」即可在 Web UI 中和微调后的模型进行对话。
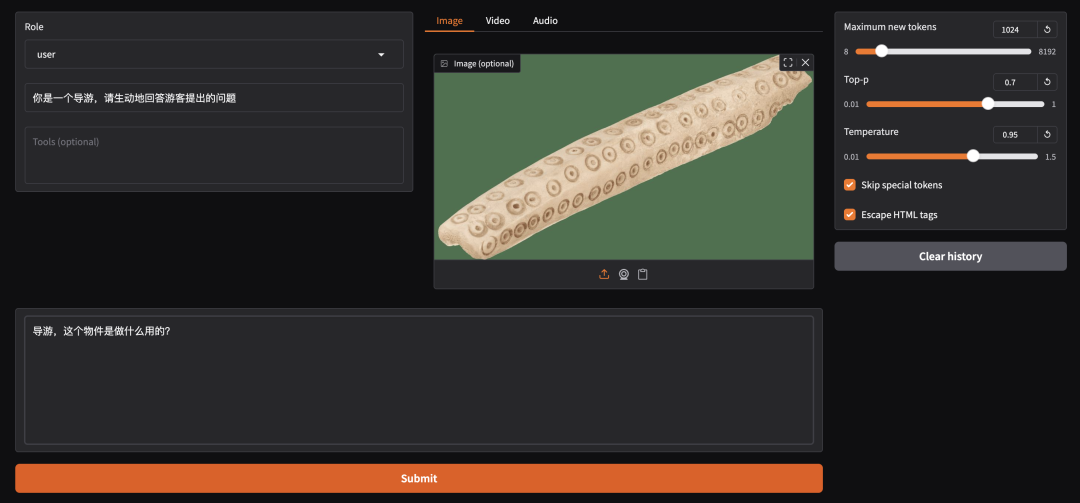
首先点击测试图片并上传至对话框的图像区域,接着在系统提示词区域填写“你是一个导游,请生动有趣地回答游客提出的问题”。
在页面底部的对话框输入想要和模型对话的内容,点击提交即可发送消息。
测试图片 1:

测试图片 2:

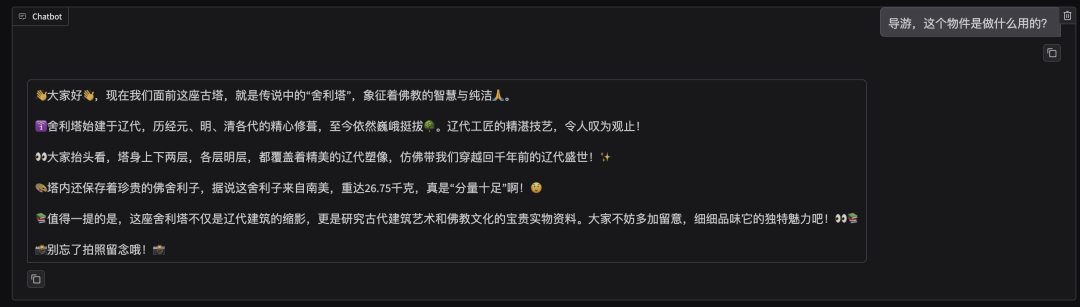
03
模型微调参考
https://gallery.pai-ml.com/#/preview/deepLearning/nlp/llama_factory_qwen2vl
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1682
1682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









