






近期尝试了三种流行的微调框架,其中最推荐的是 unsloth,因为快!另外两种框架 LLaMA Factory 和 trl 是在夜里跑的,显卡风扇响了一宿。第二天看日志,它们都跑了三个多小时才跑完。但是同样的任务,unsloth 只需要五分钟,快得有点离谱。当然,这么比不是完全公平的,因为它们的量化方法、LoRA 参数是不同的。但是 unsloth 快这一点依然是无可质疑的。如果在 GPU 服务器上认真微调,那么用 LLaMA Factory 没毛病;但如果只是在笔记本上随便玩玩,unsloth 的优势就太大了。
GitHub 项目地址:见阅读原文
⭐ 本文的内容包括:
- 大模型微调的三种范式:无监督微调、监督微调、强化学习微调
- 介绍用于监督微调的数据格式,以及如何加载数据集
- 如何下载 Qwen 模型,代码见 download_qwen.py
- 使用三种框架微调大模型:LLaMA Factory, trl, unsloth
一、引言
大语言模型有很强的通用能力,但在特定领域,它的表现不如领域小模型。为了让大模型适应特定任务,我们对大模型进行微调,使大模型在保持通用性的同时,兼具领域模型的专业知识、对话风格和输出格式等特质。
微调大模型有三种范式:
-
无监督微调:在海量数据上进行二次预训练
-
- PT 增量预训练
-
监督微调 (SFT):构造领域数据集,增强模型的指令遵循能力,并注入领域知识
-
- 指令微调
-
强化学习微调:通过 reward 引导模型优化
-
- RLHF 基于人类反馈的强化学习
- DPO 偏好优化方法
- ORPO 比偏好优化
- GRPO 群体相对策略优化
本文聚焦 监督微调 (Supervised Fine-Tuning)。监督微调是一种简单但有效的微调方式,能够快速融合业务数据、适应业务场景,因此它的性价比极高!
1. SFT 的简单介绍
监督微调的优化目标是 最小化模型生成回答与目标回答之间的差异,通常使用交叉熵损失。为避免破坏预训练阶段获得的知识,SFT 阶段通常使用 较低的学习率,并且只更新部分参数层,其他参数保持不变。与预训练阶段所需的海量数据相比,SFT 只需 较小的数据量(数千到数十万样本),即可完成微调。
2. SFT 的使用场景
为了让大家感受一下 SFT 能做什么,下面列举一些使用场景:
| 任务 | 场景举例 | 类型 |
|---|---|---|
| 文案生成 | 输入标签:红色#女士#卫衣,输出文案:女士专属红色卫衣,解锁秋冬时尚密码 | 任务对齐 |
| 情感分类 | 输入用户评论:蓝牙连接不稳定,输出情感标签:负面 | 任务对齐 |
| 合同审核 | 输入合同文本,输出潜在法律风险,并引述法条和案例 | 知识迁移 |
3. SFT 的数据集格式
SFT 通过人类精心设计的高质量数据集进行微调。
微调使用的数据格式是灵活的。但是过于灵活的数据格式,可能导致加载数据的不便。SFT 经过几年时间,也逐渐发展出一些主流的数据格式。其中,alpaca 就是一种专为指令微调设计的数据格式。通常,每条 alpaca 数据由 instruction, input, output 三个字段组成。
1)问答数据集
{
"instruction": "帕金森叠加综合征的辅助治疗有些什么?",
"input": "",
"output": "综合治疗;康复训练;生活护理指导;低频重复经颅磁刺激治疗"
}
上面是一条 alpaca 格式的问答数据。对于问答数据,input 字段可以留空。问题放在 instruction 字段;回答放在 output 字段。
2)指令微调数据集
{
"instruction": "请对下面这篇文章进行分类,分类标签从“教育”、“健康”、“游戏”、“其他”四个标签中选择。仅回答标签,不要回答除标签以外的任何内容。",
"input": "怪物猎人崛起实在是太好玩了!",
"output": "游戏"
}
上面是一条 alpaca 格式的指令微调数据。指令微调数据的三个字段都有值。instruction 字段写我们希望模型做什么;input 字段写这次请求模型的输入,output 字段写这次请求我们希望模型输出什么。
SFT 还有其他数据格式,比如
ShareGPT,ChatML等,参考 datasets-guide
4. 本文的任务
本文只有一个微调任务,但是通过三种框架实现。
一个任务:
使用 医疗问答数据集 medical 对 Qwen 模型 做 SFT 监督微调。相关资源列表如下:
- medical 数据集:shibing624/medical
Qwen2.5-0.5B-Instruct模型:Qwen/Qwen2.5-0.5B-InstructQwen2.5-7B-Instruct模型:Qwen/Qwen2.5-7B-Instruct
三种框架:
- LLaMA Factory: 提供简洁的 UI 界面,支持零代码微调大模型
- trl: 有 HuggingFace 生态支持,且工具链完备。不仅支持监督微调,对强化学习微调的支持也很好
- unsloth: 擅长加速训练和量化技术,能显著减少显存使用量、加快训练速度
本文旨在跑通流程,因此使用 0.5B 模型。这既能减少显存占用,也能更快完成任务。如果你有 RTX 5090 或者 GPU 服务器,可以考虑使用 3B, 7B 等更大规模的模型。如果你计划用较多的样本进行训练,可以考虑使用非 Instruct 模型,关于这点建议参考文档 Instruct or Base Model?
二、LLaMA-Factory 微调大模型
首先,我们来安装 LLaMA-Factory。LLaMA Factory 是一个比较容易上手的微调框架,可以通过 WebUI 来零代码微调大模型。
1. 环境准备
1.1 安装 LLaMA Factory
1)安装 CUDA
运行以下命令检查驱动是否安装:
nvidia-smi
PS:假定你已经安装好驱动,驱动的安装方法这里略过。
安装 CUDA Toolkit:
# 安装 build-essential 和 gcc-multilib
sudo apt-get update
sudo apt-get install build-essential
sudo apt-get install gcc-multilib
# 设置 CUDA 仓库
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
# 更新并安装 CUDA
sudo apt-get update
sudo apt-get install cuda
2)安装 LLaMA-Factory
运行以下命令,安装 LLaMA-Factory:
# 创建一个文件夹放 repository
mkdir envs && cd envs
# 下载 LLaMA-Factory 代码仓库
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
# 安装 LLaMA-Factory 及其依赖
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
检查安装:
# 查看版本
llamafactory-cli version
# 查看训练相关的参数帮助
llamafactory-cli train -h
检查 pytorch 环境:
import torch
torch.cuda.current_device()
torch.cuda.get_device_name(0)
torch.__version__
3)安装 bitsandbytes
如果想启用量化 LoRA(QLoRA),需要安装 bitsandbytes。
在 Linux 上安装 bitsandbytes:
pip install bitsandbytes
如果想在 Windows 上启用 QLoRA,请根据 CUDA 版本选择合适的 bitsandbytes 发行版。
执行以下命令,查看 CUDA 版本:
nvcc --version
我的 CUDA 版本是 12.6
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2024 NVIDIA Corporation
Built on Thu_Sep_12_02:55:00_Pacific_Daylight_Time_2024
Cuda compilation tools, release 12.6, V12.6.77
Build cuda_12.6.r12.6/compiler.34841621_0
选择安装较新的版本 0.41.1:
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.1-py3-none-win_amd64.whl
1.2 下载 Qwen 模型
前几个项目用的都是 Qwen 模型,秉持着推理代码可以复用的偷懒精神,这次还用 Qwen。我有 8G 显存,当前最大可接受的参数量是 7B,阿里经过指令微调的 Qwen2.5-7B-Instruct 模型是我最好的选择,后续开 QLoRA 可将显存消耗压制在合适范围内。
如果显存不足,可以选择 1.5B 或 3B 模型:
- Qwen/Qwen2.5-1.5B-Instruct
- Qwen/Qwen2.5-3B-Instruct
1)安装 ModelScope
pip install modelscope
pip install modelscope-agent
2)下载 Qwen2.5-7B-Instruct 模型
中国大陆建议使用 ModelScope 下载模型:
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-7B-Instruct', cache_dir='./')
print(f"model_dir: {model_dir}")
以上代码同本仓库 download_qwen.py 脚本。
可在根目录打开命令行,执行
cd model && python download_qwen.py下载 Qwen 模型。
1.3 模型推理测试
模型下载好之后,测试一下模型能否正常推理。
1)使用 transformers 库推理
import os
import torch
import transformers
MODEL_PATH = "./model/Qwen/Qwen2.5-7B-Instruct"
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f'device: {device}')
device: cuda
# 模型的绝对路径
abs_model_path = os.path.abspath(MODEL_PATH)
pipeline = transformers.pipeline(
"text-generation",
model=abs_model_path,
model_kwargs={
"torch_dtype": torch.bfloat16
},
device_map=device, # auto cuda
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=pipeline.tokenizer.eos_token_id,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
Arrr, I be yer trusty pirate chatbot, ready to sail the cyber seas wit ye and share tales of treasure and treachery! What be yer name, matey?
2)使用 ChatBot 推理
LLaMA Factory 提供了一个基于 gradio 开发的 ChatBot 推理页面。
运行以下命令启动 ChatBot:
model_path="./model/Qwen/Qwen2.5-7B-Instruct"
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \
--model_name_or_path $model_path\
--template qwen
PS: 如需了解 template 的枚举值,可查看对话模板文件:template.py
模型加载完毕后,浏览器打开 http://localhost:7861/ 即进入推理页。

2. 数据准备
模型微调后用于何种任务,决定了应该使用什么数据集。业界常见的任务包括:NL2SQL,商品描述生成、广告文案生成等。但是以上任务班味太重,不适合我们 side project 的调性。经过一番挑三拣四,决定用医疗对话数据集来优化 Qwen 模型在问诊场景的效果。
2.1 下载医疗对话数据集
数据集 shibing624/medical 是医疗大模型 shibing624/MedicalGPT 的训练数据集,
- 从 Huggingface 下载:shibing624/medical
- 从 Modelscope 下载:medical_zh
无需下载全部数据文件,只需要下载以下 3 个和中文 SFT 有关的数据文件即可。下载后放在本项目的 /data 目录:
train_zh_0.jsontest_zh_0.jsonvalid_zh_0.json
2.2 检查数据格式
使用以下命令获取 train_zh_0.json 文件的前三行:
cd data
head -3 train_zh_0.json
样例数据如下:
{"instruction": "血热的临床表现是什么?", "input": "", "output": "初发或复发病不久。皮疹发展迅速,呈点滴状、钱币状或混合状。常见丘疹、斑丘疹、大小不等的斑片,潮红、鲜红或深红色。散布于体表各处或几处,以躯干、四肢多见,亦可先从头面开始,逐渐发展至全身。新皮疹不断出现,表面覆有银白色鳞屑,干燥易脱落,剥刮后有点状出血。可有同形反应;伴瘙痒、心烦口渴。大便秘结、小便短黄,舌质红赤,苔薄黄或根部黄厚,脉弦滑或滑数。血热炽盛病机,主要表现在如下四个面:一、热象:血热多属阳盛则热之实性、热性病机和病证、并表现出热象。二、血行加速:血得热则行,可使血流加速,且使脉道扩张,络脉充血,故可见面红目赤,舌色深红(即舌绛)等症。三、动血:在血行加速与脉道扩张的基础上,血分有热,可灼伤脉络,引起出血,称为“热迫血妄行”,或称动血。四、扰乱心神:血热炽盛则扰动心神,心主血脉而藏神,血脉与心相通,故血热则使心神不安,而见心烦,或躁扰发狂等症。"}
{"instruction": "帕金森叠加综合征的辅助治疗有些什么?", "input": "", "output": "综合治疗;康复训练;生活护理指导;低频重复经颅磁刺激治疗"}
{"instruction": "卵巢癌肉瘤的影像学检查有些什么?", "input": "", "output": "超声漏诊;声像图;MR检查;肿物超声;术前超声;CT检查"}
非常棒,数据已经是 alpaca 格式,满足 LLaMA Factory 的数据格式要求,无需进行数据格式转换。
2.3 添加描述文件
使用 wc -l train_zh_0.json 查看文件行数,发现训练集有 194 万多行,太多了。为了快速跑完第一次微调任务,从训练集中抽取前 1000 条样本:
head -1000 train_zh_0.json > train_zh_1000.json
新建数据集描述文件 data/dataset_info.json,参考 格式要求 填写:
{
"train_zh": {
"file_name": "train_zh_0.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
},
"train_zh_1000": {
"file_name": "train_zh_1000.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
},
"test_zh": {
"file_name": "test_zh_0.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
},
"valid_zh": {
"file_name": "valid_zh_0.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
}
}
3. 微调大模型
以上,我们已经准备了微调框架、模型文件、微调数据集,下面开始微调模型。
打开命令行,来到项目根目录,执行以下命令启动 WebUI 页面:
llamafactory-cli webui
# 如需指定显卡 id 和 WebUI 端口
# CUDA_VISIBLE_DEVICES=0 GRADIO_SERVER_PORT=7860 llamafactory-cli webui
3.1 SFT 监督微调
配置好模型路径、微调方法、数据集等参数。由于我的显存限制,开启了 4-bit 量化,会损失一些训练精度。
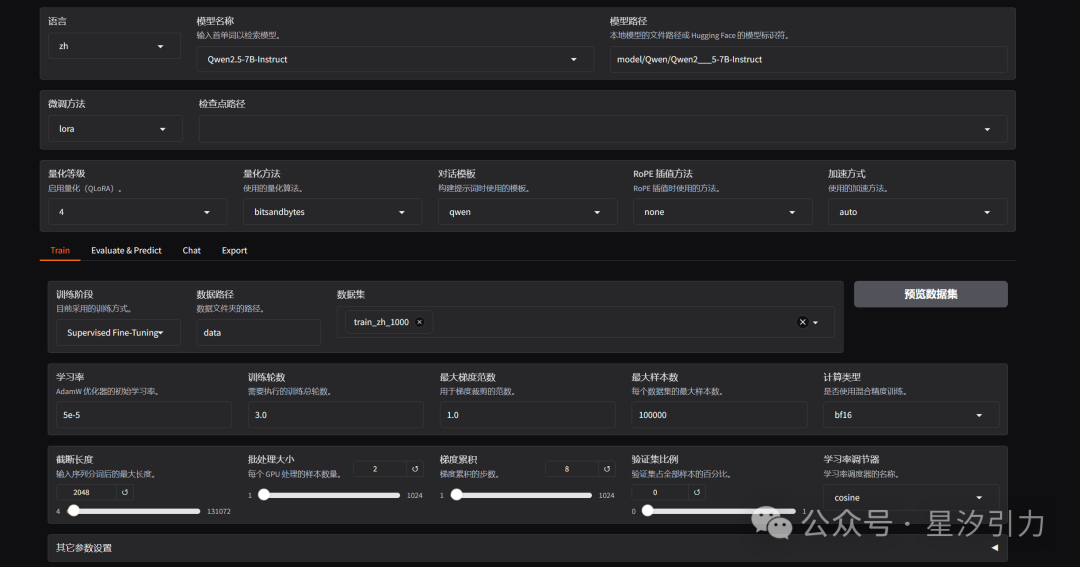
我的训练参数如下,供参考:
| 参数名 | 参数值 |
|---|---|
| 模型名称 | Qwen2.5-7B-Instruct |
| 模型路径 | model/Qwen/Qwen2___5-7B-Instruct |
| 微调方法 | lora |
| 量化等级 | 4 |
| 量化方法 | bitsandbytes |
| 训练阶段 | Supervised Fine-Tuning |
| 数据路径 | data |
| 数据集 | train_zh_1000 |
使用 预览命令 功能,生成当前训练参数下的训练脚本:
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path model/Qwen/Qwen2___5-7B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template qwen \
--flash_attn auto \
--dataset_dir data \
--dataset train_zh_1000 \
--cutoff_len 2048 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--report_to none \
--output_dir saves/Qwen2.5-7B-Instruct/lora/train_2025-04-11-15-29-12 \
--bf16 True \
--plot_loss True \
--trust_remote_code True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--optim adamw_torch \
--quantization_bit 4 \
--quantization_method bitsandbytes \
--double_quantization True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all
训练参数配置好后,点击“开始”进行训练。由于我们只选择了 1000 条样本进行训练,训练很快就能结束。
训练中,loss 逐渐下降:

8G 显存接近跑满:

PS: 为了防止训练因 Windows 的电源计划或睡眠设置中断,可以启用 PowerToys 的 唤醒功能。它支持一键维持电脑的唤醒状态。
3.2 加载训练好的 LoRA 文件
训练完毕后, 点击“检查点路径”,即可在下拉栏中找到该模型历史上使用 WebUI 训练的 LoRA 模型。点选我们上一次训练的检查点,后续再训练或者执行 chat 的时候,会将此 LoRA 一起加载。
3.3 导出微调后的模型
WebUI 支持将训练后的 LoRA 和原始大模型进行融合,输出一个完整的模型文件。
导出操作也很简单。首先切换到 Export 分页,然后配置好导出路径和检查点路径,点击“开始导出”,少时就导出完成了。

导出后的模型目录包含以下文件:
.
├── Modelfile
├── added_tokens.json
├── config.json
├── generation_config.json
├── merges.txt
├── model-00001-of-00004.safetensors
├── model-00002-of-00004.safetensors
├── model-00003-of-00004.safetensors
├── model-00004-of-00004.safetensors
├── model.safetensors.index.json
├── special_tokens_map.json
├── tokenizer.json
├── tokenizer_config.json
└── vocab.json
4. vLLM 作为推理后端
4.1 启动后端推理服务
使用 LLaMA Factory 作为推理后端,需要安装 vLLM 环境。安装过程可参考我的上一篇博客 《本地部署大模型:Ollama 和 vLLM》
# 打开安装好 vLLM 的虚拟环境
conda activate vllm_env
# 补充安装 LLaMA Factory
cd ./envs/LLaMA-Factory/
pip install -e ".[torch,metrics]"
安装好环境后,运行下面这个脚本启动推理服务:
#!/bin/bash
# USAGE: bash server.sh
source $(conda info --base)/etc/profile.d/conda.sh
conda activate vllm_env
# 我的电脑只支持运行 0.5B 模型
# 如果你也是,请先用 ./model/download_qwen.py 下载模型
model_path="./model/Qwen/Qwen2___5-0___5B-Instruct"
CUDA_VISIBLE_DEVICES=0 API_PORT=8621 llamafactory-cli api \
--model_name_or_path $model_path \
--template qwen \
--infer_backend vllm \
--vllm_gpu_util 0.99 \
--vllm_maxlen 512 \
--vllm_enforce_eager
4.2 运行客户端获取结果
上一篇博客写好的 Qwen 客户端代码 qwen_vllm_bash_client.py,这里直接拿来用:
# -*- coding: utf-8 -*-
from openai import OpenAI
openai_api_base = "http://localhost:8621/v1"
def chat_completion(prompt, model=''):# llama factory 不需要写模型名,空着就行
client = OpenAI(
base_url=openai_api_base,
api_key='EMPTY_KEY'# 也不需要写 api key,非空/非空字符串就行
)
chat_response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt},
],
temperature=0.8,
top_p=0.9,
max_tokens=512,
extra_body={
"repetition_penalty": 1.05,
},
)
return chat_response
response = chat_completion(prompt="抑郁症有哪些症状")
content = response.choices[0].message.content
print(content)
三、trl 微调
trl 的功能强大,支持 SFT, PPO, DPO, GRPO 等微调方法。并且有良好的生态支持,比如,trl 可以配合 peft 的 LoraConfig 模块定义 LoRA 参数;配合 unsloth 的 FastLanguageModel 模型加载模型。
与上一节的 LLaMA Factory 相比,trl 可以更精细地定义训练中的行为。比如,如何加载数据集、如何构建损失函数、允许哪些参数层参与训练等等。适合需要深度控制训练过程的场景。
# !uv pip install --upgrade transformers
# !uv pip install bitsandbytes
import torch
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer, DataCollatorForCompletionOnlyLM
from peft import LoraConfig
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
DATASET_PATH = './data/train_zh_1000.json'
MODEL_PATH = './model/Qwen/Qwen2.5-7B-Instruct/'
1. 加载数据集
上一节,我们将医疗数据集 shibing624/medical 保存到 data 目录,并采样生成了 train_zh_1000.json 文件。
本节,我们用 datasets 的 load_dataset 方法加载 train_zh_1000.json 文件。关于 load_dataset 的数据处理逻辑,详见:https://huggingface.co/docs/datasets/loading
# 从 HuggingFace 仓库加载数据集
# dataset = load_dataset("trl-lib/Capybara", split="train")
# 从本地加载数据集
dataset = load_dataset("json", data_files=DATASET_PATH)['train']
# 打印数据集的基本信息
print(f'基本信息:\n{dataset}')
# 查看数据集的行数
print(f'数据集的行数:\n{dataset.num_rows}')
# 查看数据集的形状
print(f'数据集的形状:\n{dataset.shape}')
2. 微调 Qwen 模型
对模型使用 4-bit 量化,并用半精度浮点数加载模型。
# 量化配置
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_compute_dtype=torch.bfloat16
)
# 加载模型
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
device_map="auto",
torch_dtype=torch.bfloat16,
quantization_config=bnb_config
)
我们加载的数据集是 alpaca 格式的。下面使用 formatting_prompts_func 函数,将数据转换成如下格式的文本:
### Question:
{your_question}
### Answer:
{your_answer}
def formatting_prompts_func(example):
output_texts = []
for i in range(len(example['instruction'])):
text = f"### Question: {example['instruction'][i]}\n ### Answer: {example['output'][i]}"
output_texts.append(text)
return output_texts
本次微调采用 Train on completions only 方法(仅对模型生成的 ### Answer: 之后的部分计算损失)。什么意思呢?如果没有额外配置,我们将计算整个句子的损失,既计算 Question 的损失,也计算 Answer 的损失。这显然是不合理的。既然不用推理 Question,就不应该计算 Question 的损失。若将 Question 的损失加入训练,浪费算力不说,模型的优化目标也会产生偏差,导致训练效果变差。
为了达到仅计算 Answer 部分的损失的效果,下面用 DataCollatorForCompletionOnlyLM 定位样本数据 Answer 部分的位置。
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
response_template = " ### Answer:"
collator = DataCollatorForCompletionOnlyLM(response_template, tokenizer=tokenizer)
我的五星级神机显存高达 8G,因此选择了较小的秩和缩放系数。如果你的 GPU 比较厉害,可以把秩和缩放系数设置得大一点,这有利于提高微调精度。比如可以设置成:
r=16,
lora_alpha=32,
target_modules 参数用于指定 LoRA 微调生效的模块,比较推荐微调以下模块:
- 注意力相关:“q_proj”, “k_proj”, “v_proj”, “o_proj”
- GLU 相关:“gate_proj”, “up_proj”, “down_proj”
亦可参考官方文档的
peft_config配置:training-adapters
# LoRA 配置
peft_config = LoraConfig(
r=8, # 秩
lora_alpha=16, # 缩放系数
lora_dropout=0.05, # dropout 比例
target_modules=[
"q_proj", "k_proj", "v_proj", "o_proj"
], # 指定需要微调的模块
task_type="CAUSAL_LM"
)
SFTConfig 的配置也压低了单卡批量数和训练轮次,因为我们旨在跑通,并非正经训练。
如果你想了解更多 SFTConfig 的配置详情,请参考文档:trl.SFTConfig
# SFT 训练参数
training_args = SFTConfig(
output_dir="./Qwen2.5-0.5B-SFT",
per_device_train_batch_size=1, # 单卡批量数
num_train_epochs=1, # 训练轮次。这里仅仅为了跑通,因此设为 1
fp16=True, # 启用半精度训练
optim="adamw_torch_fused", # 使用内存优化的优化器
max_seq_length=512, # 序列的最大长度
logging_steps=50, # 日志打印间隔,默认 500
)
trainer = SFTTrainer(
model,
train_dataset=dataset,
args=training_args,
peft_config=peft_config,
formatting_func=formatting_prompts_func,
data_collator=collator
)
trainer.train()
# save model
trainer.save_model()
3. 加载微调后的模型
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = 'cuda'
model = AutoModelForCausalLM.from_pretrained(
"./Qwen2.5-0.5B-SFT",
torch_dtype=torch.float16,
device_map=device
)
tokenizer = AutoTokenizer.from_pretrained("./Qwen2.5-0.5B-SFT")
def use_template(text):
return f'### Question: {text}\n ### Answer:'
query = use_template(text='癔症有哪些表现')
inputs = tokenizer(query, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=50)
tokenizer.decode(outputs[0])
参考:
- trl SFT 文档:Supervised Fine-tuning Trainer
- trl 示例:sft.py
- peft 文档:peft
- 知乎:使用HuggingFace TRL微调Qwen1.5-7B模型(SFT)
四、unsloth 微调
unsloth 是目前最适合在消费级显卡上使用的微调框架,它的显存消耗少且速度极快。最感人的是它的文档也是最全的,回答了初学者的常见疑惑和一些很有价值的问题 --> ⭐ Beginner? Start here!
import torch
from unsloth import FastLanguageModel
from datasets import load_dataset
from trl import SFTTrainer
from transformers import TrainingArguments, TextStreamer, AutoTokenizer, BitsAndBytesConfig
from unsloth import is_bfloat16_supported
from peft import AutoPeftModelForCausalLM
DATASET_PATH = './data/train_zh_1000.json'
MODEL_PATH = './model/Qwen/Qwen2.5-0.5B-instruct'
OUTPUT_PATH = './model/lora_model'
1. 加载模型
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = MODEL_PATH,
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)
model = FastLanguageModel.get_peft_model(
model,
r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
2. 加载数据
与上一节相同,我们要加载 Alpaca 数据集,然后使用模板,将数据做成特定格式的纯文本。
官方Notebook Qwen2.5_(7B)-Alpaca.ipynb 提供的模板:
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
由于我们数据的 Input 字段为空,可以略去。我们使用的格式如下:
alpaca_prompt = """### Question:
{}
### Response:
{}"""
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
instructions = examples["instruction"]
outputs = examples["output"]
texts = []
for instruction, output in zip(instructions, outputs):
# Must add EOS_TOKEN, otherwise your generation will go on forever!
text = alpaca_prompt.format(instruction, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
# 从 HuggingFace 仓库加载数据集
# dataset = load_dataset("yahma/alpaca-cleaned", split = "train")
# 从本地加载数据集
dataset = load_dataset("json", data_files=DATASET_PATH, split = "train")
# 打印数据集的基本信息
print(f'基本信息:\n{dataset}')
# 将模板应用于数据
dataset = dataset.map(formatting_prompts_func, batched = True,)
dataset[0]
3. 微调模型
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
# num_train_epochs = 1, # Set this for 1 full training run.
max_steps = 60,
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
report_to = "none", # Use this for WandB etc
),
)
trainer_stats = trainer.train()
4. 模型推理
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[
alpaca_prompt.format(
"血热的临床症状是什么?", # instruction
"", # input - leave this blank for generation!
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens = 64, use_cache = True)
tokenizer.batch_decode(outputs)
# 实时推理
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
5. 保存模型
# 保存模型
model.save_pretrained(OUTPUT_PATH) # Local saving
tokenizer.save_pretrained(OUTPUT_PATH)
6. 保存模型后重新加载
1)使用 unsloth 加载模型
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = OUTPUT_PATH, # YOUR MODEL YOU USED FOR TRAINING
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
_ = FastLanguageModel.for_inference(model) # Enable native 2x faster inference
alpaca_prompt = """### Question:
{}
### Response:
{}"""
inputs = tokenizer(
[
alpaca_prompt.format(
"血热的临床症状是什么?", # instruction
"", # input - leave this blank for generation!
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
2)使用 transformers 加载模型
# I highly do NOT suggest - use Unsloth if possible
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16, # 计算时使用的数据类型
bnb_4bit_quant_type="nf4", # 量化类型,nf4或fp4
bnb_4bit_use_double_quant=True # 是否使用双重量化
)
model = AutoPeftModelForCausalLM.from_pretrained(
OUTPUT_PATH, # YOUR MODEL YOU USED FOR TRAINING
quantization_config=quantization_config,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(OUTPUT_PATH)
alpaca_prompt = """### Question:
{}
### Response:
{}"""
prompt = alpaca_prompt.format("血热的临床症状是什么?", "")
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=1024,
temperature=0.7,
top_p=0.95,
do_sample=True,
pad_token_id=tokenizer.pad_token_id
)
# outputs
decoded_output = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded_output)
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 7226
7226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









