



“ 端到端模型,是一个直接由输入获取输出的过程 ”
最近有一个很火的关于人工智能模型的词——端到端模型。
那么什么是端到端模型?为什么会提出端到端模型,以及它解决了哪些问题?
今天我们就来一起了解一下这个端到端模型。
端到端模型
还记得计算机组成原理里面,关于冯诺伊曼计算机结构中,组成计算机的几个模块吗?
运算器 控制器 存储器 输入设备和输出设备,由这五大模块组成了现有的计算机系统。
而对我们使用者来说,这五大模块中我们接触最多的就是输入设备与输出设备,也就是鼠标键盘显示器。
而运算器,控制器和存储器是由计算机系统自己处理的,我们不需要知道它们的内部运行原理,也不需要知道它们是怎么协调的。
同样端到端也是如此,从表象来看我们只需要关心其输入与输出,不需要知道它的内部结构,也就是说,端到端模型的表象是一个黑盒。
我们知道,大模型的表现是无法解释的,它更多的是一种现象,叫做智能涌现,现在很多研究机构都在解决大模型的可解释性,也就是大模型为什么能做到这样的效果,中间经历了哪些处理。
但如果要实现一个端到端的大模型,应该怎么实现呢?任何新技术的出现都是为了解决存在的问题,那端到端模型解决了什么问题?
其实用一句话概括端到端,就是让大模型直接理解问题,然后给出答案或决策。
比如拿语音模型举例,很多人以为的语音模型就是直接理解语音,但事实上语音模型并不是直接理解语音;而是由多个模块组成的一个语音模型。
语音在语音模型中的处理过程,需要经过语音转文字,然后把文字输入给大模型,大模型处理完毕返回文字,再有转化系统把文字转换为语音返回给用户。
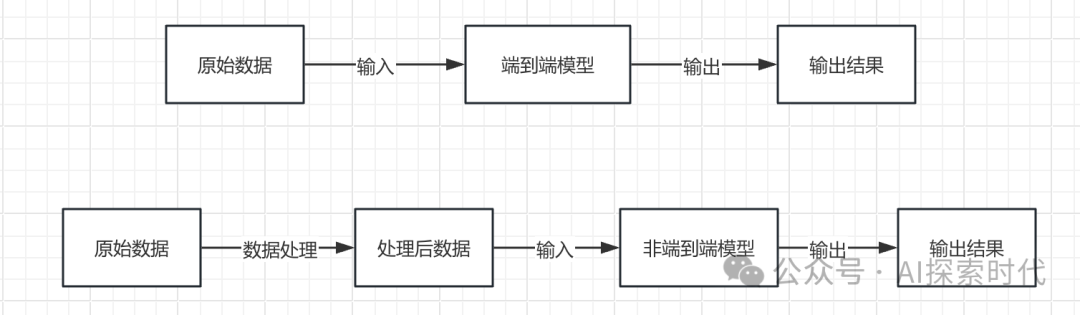
这就是现在大模型所存在的问题,中间需要经过多个模块的协同处理才能得到想要的结果。可能有人会问为什么不让大模型直接理解语音,还要经过中间的转化?
原因就是这样的实现方式技术难度低,容易实现。
而端到端模型的目的就是省略中间语音转文字,文字转语音的过程;为什么要这么做?
这么做的目的并不是为了炫耀技术,而是有些场景需要强大的实时性,无法接受如此长链条的处理响应时间。
比如说自动驾驶,现今的自动驾驶采用的就是多模块协作的方式,如路况采集,自动化分析,做出决策,执行决策等。这样的自动驾驶系统就需要大量的时间做出响应。
而如果采用端到端系统,那么端到端系统就可以直接采集路况数据,然后做出决策,省略中间各种乱七八糟的处理流程,大大提升了系统灵敏度。
从技术到角度来说,端到端模型实现难度更大,系统更复杂,而且可解释性更差,而且更像一个黑盒。
可能说到这里,有些人任务端到端模型能做到的事,普通大模型也可以做到,而且技术难度更低,成本也更低。
但端到端模型出现的原因并不是为了解决普通的问题,比如回答系统;哪怕你普通大模型性能低一点,回答慢一点也可以接受。
但在一些领域,如智能驾驶,高端制造,军事竞争等方面,延迟要在毫秒,甚至是微秒的程度;这时普通大模型就无法完成任务了。
端到端模型的主要目的就是为了让大模型直接接受输入,减少中间环节的处理成本,提升效率。
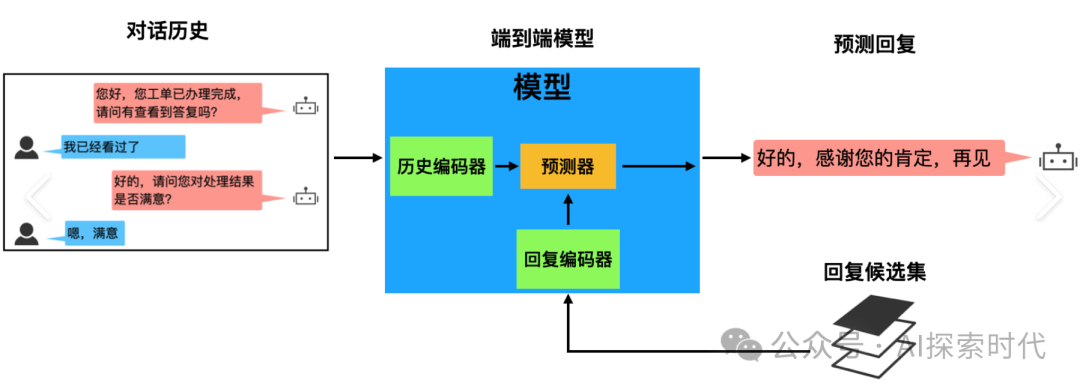
程序员应该比较容易理解端到端,普通大模型就类似于现在的高级语音,如java,python等;它们的功能强大,但执行效率低,原因就是中间有一个解释器。
而端到端模型就类似于C语言,直接转换为计算机能够处理的格式,省略了中间解释的环节。
虽然高级编程语言的作用越发强大,但永远也没有那个语言能完全取代C语言和汇编语言。
当然,C语言和汇编语言虽然效率高,但迁移性比较低,不同的平台需要不同的指令集和开发库。端到端模型也是如此,对训练数据质量的要求更高,适应性也更差。
因此,网上也有人说,所谓的端到端就是直接由输入得到输出,大模型可以直接理解输入数据,而不需要这样那样的转化过程。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 753
753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









