



本文详细介绍了RAG系统的五维度评估体系,包括召回率与准确率(BLEU、ROUGE等指标)、可信度(答案与文档匹配度)、响应速度(平均延迟和P95/P99)、可扩展性(不同数据规模下的性能)和用户体验(满意度与可读性)。通过这些量化指标,系统评估RAG系统是否"能上生产",不仅保证回答正确,还确保有依据、响应快、可扩展且用户体验良好。这套评估体系不仅能指导系统优化,也是大厂面试中的专业回答,帮助求职者展示RAG产品的工程思维。
大家好,我是吴师兄。
在很多人眼里,RAG 项目能“跑通”就算完事了, 但在真正的大厂或金融企业里,事情远没这么简单。
面试官会继续追问一句:
“那你们是怎么评估 RAG 系统效果的?”
如果这时候你还在讲“能答对问题”“效果还可以”,那就太业余了。 真正的工程评估,要有体系、有指标、有量化。
今天我们就来聊聊:如何制定一个完整的 RAG 系统评估方案,尤其针对金融保险类问答场景。
一、为什么评估体系很关键
RAG 项目的核心,是让模型在检索和生成之间保持平衡。 但“好不好用”不是拍脑袋决定的。 要让系统进入生产落地,你必须回答五个问题:
- 它答得准不准?
- 它靠不靠谱?
- 它快不快?
- 它能不能扩?
- 用户用着爽不爽?
这五个维度,分别对应:召回率 / 准确率、可信度、响应速度、可扩展性、用户体验。
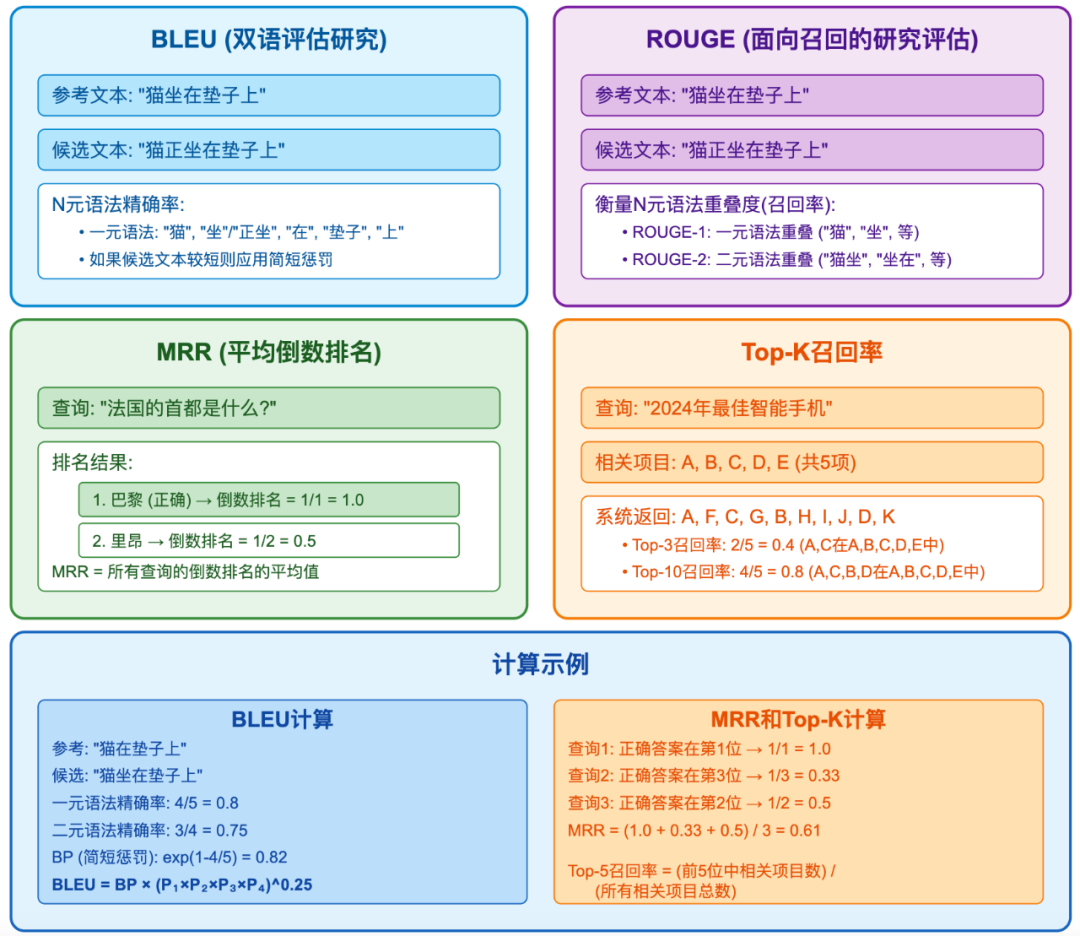
二、召回率与准确率:先确定“能不能答对”
这是最基础也是最重要的评估。
金融保险问答系统的关键目标是模型必须答对,不能“编”。
通常我们从两个层面评估:
- 答案准确率:看模型输出是否接近标准答案;
- 检索召回率:看系统是否能找到包含正确答案的文档。
这时会用到自然语言处理中的几大经典指标:
- BLEU:衡量 n 元语法匹配程度;
- ROUGE:衡量召回覆盖率;
- MRR(Mean Reciprocal Rank):看正确答案排在第几个;
- Top-k Recall:正确文档是否出现在前 k 个结果中。
举个例子(代码略简化):
from nltk.translate.bleu_score import sentence_bleu, SmoothingFunction
from rouge import Rouge
ref = "您的汽车保险可赔偿医疗费用、车辆维修费,以及第三方损害赔偿。"
gen = "您的保单通常涵盖车祸后的医疗费用、车辆损失,以及对第三方的赔偿。"
chencherry = SmoothingFunction()
bleu = sentence_bleu([list(ref)], list(gen), smoothing_function=chencherry.method1)
rouge = Rouge().get_scores(gen, ref)
print(f"BLEU: {bleu:.3f}, ROUGE-1 F1: {rouge[0]['rouge-1']['f']:.3f}")
如果 BLEU 超过 0.6、ROUGE 在 0.7 以上,就说明回答与参考答案相似度较高。 再配合检索结果的 MRR、Top-3 召回率,就能判断整个链路的正确性。
三、可信度:让答案“有出处、有依据”
第二个维度,是看答案是否“有根有据”。 尤其在金融保险领域,生成的内容必须可追溯。
这里有两个关键指标:
- 答案与支持文档的匹配度
- 文档覆盖率
简单来说: 答案里的关键信息,能不能在检索文档中找到。
generated = "您的保单通常涵盖车祸后的医疗费用、车辆损失,以及对第三方的赔偿。"
docs = [
"根据保险条款,医疗费用和车辆损失在车祸理赔中可以获得赔偿。",
"如果您对第三方造成损害,保险也会提供相应的赔付。"
]
tokens = lambda x: [c for c in x if c.strip()]
a, d = set(tokens(generated)), set(tokens("".join(docs)))
coverage = len(a & d) / len(a)
print(f"支持文档覆盖率: {coverage:.2f}")
如果覆盖率能达到 0.7 以上,说明大部分回答来自于检索文档,可信度较高。 在更高阶的系统中,还会引入向量相似度计算语义重叠, 或者直接检查答案是否引用了具体文档片段。
四、响应速度:系统快不快,取决于延迟和稳定性
金融场景的用户最怕的不是回答错,而是回答慢。 因此必须评估系统的响应性能。
常用指标:
- 平均响应时间(Average Latency)
- P95 / P99 延迟(长尾性能)
通过统计多次查询响应时间,可以看出系统稳定性。
import random
times = [random.uniform(0.1, 0.3) for _ in range(100)]
avg = sum(times)/len(times)
p95 = sorted(times)[int(0.95*len(times))-1]
p99 = sorted(times)[int(0.99*len(times))-1]
print(f"平均: {avg:.3f}s, P95: {p95:.3f}s, P99: {p99:.3f}s")
例如输出:
平均: 0.200s, P95: 0.280s, P99: 0.290s
说明 95% 的请求在 0.28 秒内完成,性能表现稳定。 如果 P99 明显高于平均值,就要检查瓶颈在哪: 是检索慢?生成模型卡?还是网络延迟?
五、可扩展性:撑得住用户量才叫系统
RAG 的另一个考验是扩展能力。 文档量翻十倍、并发翻十倍,系统还能不能稳定?
我们通常测试:
- 不同数据规模下的响应耗时变化;
- 系统吞吐量(QPS)。
比如:
import time
sizes = [1000, 10000, 100000]
for s in sizes:
data = list(range(s))
q = 100
start = time.time()
for _ in range(q):
_ = (s+1) in data
total = time.time() - start
print(f"数据量: {s}, 平均耗时: {total/q*1000:.3f}ms, 吞吐量: {q/total:.1f}/s")
随着规模增长,响应耗时上升、吞吐量下降, 就能看出索引结构是否高效。 真实环境下,通常会通过向量索引或分布式缓存来维持线性增长。
六、用户体验:系统好不好用,用户说了算
最后一个维度,是真正影响口碑的:用户体验。
这里主要关注两点:
- 用户满意度(人工打分或反馈比例)
- 答案可读性(文本清晰度与可理解性)
ratings = [5,4,5,3,4,4,5]
avg = sum(ratings)/len(ratings)
print(f"用户满意度平均: {avg:.2f}/5")
输出:
用户满意度平均: 4.29/5
说明总体体验较好。 而对于可读性,可以计算 Flesch Reading Ease(针对英文), 中文可改用句长、术语比例等指标。
分数越高,代表语言越清晰易懂。 在金融保险类问答中,模型回答应避免堆砌术语或条文。
七、评估的最终目标:让模型“可靠地聪明”
这五个维度看似独立,其实是一个闭环。
- 召回率 / 准确率:保证“说对话”;
- 可信度:保证“有依据”;
- 响应速度:保证“够快”;
- 可扩展性:保证“能撑”;
- 用户体验:保证“能留人”。
这些指标配合起来,才能真正衡量一个 RAG 系统是否“能上生产”。 就像一辆车,不仅要跑得快,还得刹得住、坐得稳、开得久。
八、面试官想听到的回答
当面试官问:“你们是怎么评估 RAG 系统的?” 可以这样说:
“我们制定了一个五维度的评估体系,从准确性、可信度、速度、扩展性和用户体验全面衡量系统表现。
准确性通过 BLEU、ROUGE、MRR、Top-k召回率衡量;
可信度通过答案-文档匹配度和覆盖率评估;
性能用平均延迟和P95/P99指标监控;
可扩展性通过不同数据规模的吞吐量测试验证;
用户体验则结合人工满意度评分与可读性分析。
通过这些维度,我们可以系统发现瓶颈、指导优化,实现RAG系统在生产环境的稳定落地。”
这类回答不仅显得专业,而且能让面试官觉得 你不是在“做RAG项目”, 你在做RAG产品。
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习_,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和MoPaaS魔泊云联合梳理打造了系统大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!

【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与MoPaaS魔泊云的鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









