



文章详解了AI智能体的双层技术架构:基础层包含核心工作流、工作流引擎、RAG增强检索、模型微调和函数调用五大技术,为Agent提供自主运行能力;协作层包含多Agent协作、MCP协议和A2A协议三大技术,实现智能体间的分工、通信与动态发现。这些技术共同构建了从单一任务到复杂系统智能化的完整解决方案,是开发者构建大模型应用必备的核心知识体系。
基础层:筑牢Agent自主运行的技术基石
基础层是AI智能体的“能力底座”,决定了其能否独立完成任务规划、信息处理与行动执行。这一层的技术设计,直接影响Agent的自主性、准确性与适应性。
1. 核心工作流:定义Agent的“思考-行动”闭环
AI智能体的自主能力,源于一套严谨的核心工作流。它就像Agent的“操作系统”,规范了从接收用户需求到输出任务结果的全流程,通常由四大核心模块协同构成:
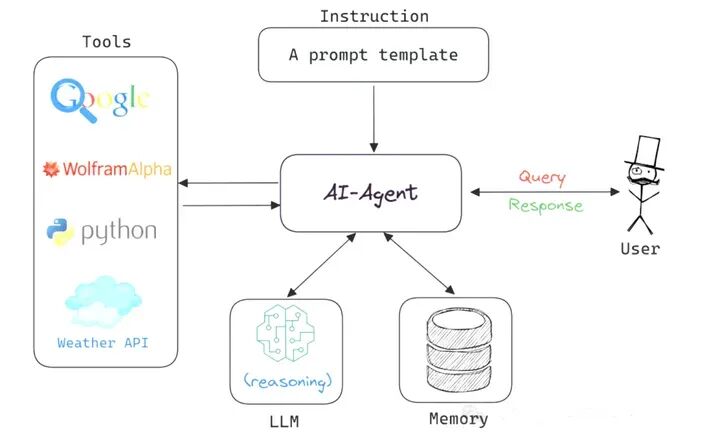
- Prompt指令层:作为Agent的“任务导航图”,不仅包含用户的核心需求,还需明确Agent的角色定位(如“专业财务分析师”)、行为边界(如“禁止生成不实数据”)、可调用工具列表(如“Excel数据处理工具”)。一份精准的Prompt能大幅降低Agent的决策偏差,例如为“市场调研Agent”设计Prompt时,需明确调研范围(“2024年中国新能源汽车市场”)、数据维度(“销量、用户画像、政策影响”),才能引导其生成符合预期的输出。
- Switch逻辑路由:相当于Agent的“决策大脑”,在任务执行的每一步,都会综合分析三类信息——用户的最新输入、历史交互记录、工具调用的返回结果,进而判断下一步行动:是直接基于现有信息回答,还是需要调用工具补充数据,或是向用户确认模糊需求(如“您提到的‘华东地区’是否包含上海市?”)。
- 上下文累积器:可理解为Agent的“动态记忆库”,会实时存储任务推进中的关键信息,包括Agent的思考过程(“已调用行业数据库,未找到2024Q2数据,需补充检索”)、工具调用的参数与结果(“调用天气API,返回北京今日气温25℃”)、用户的补充说明。这份完整的上下文记录,是Agent实现多步推理的关键,例如在“撰写旅行攻略”任务中,Agent需通过上下文记住用户“偏好自然景观”“预算5000元”等需求,避免后续推荐偏离方向。
- For循环驱动引擎:是Agent的“动力核心”,通过循环执行“分析上下文→逻辑路由决策→执行行动(回答/调用工具)→更新上下文”的流程,推动任务持续推进,直至满足终止条件(如“完成报告撰写”“用户明确表示无需继续”)。例如在“数据可视化”任务中,引擎会先驱动Agent调用数据获取工具,再根据返回数据判断是否需要调用绘图工具,最后生成可视化结果,形成完整闭环。
2. 工作流引擎:拆解复杂任务的“调度中枢”
当任务涉及多环节、多角色(如“生成一份完整的产品上市方案”),单一Agent难以覆盖所有需求,此时工作流引擎便成为关键。它通过可视化的任务编排与智能调度,将宏观复杂任务拆解为有序、可执行的子任务,并分配给对应能力的Agent。
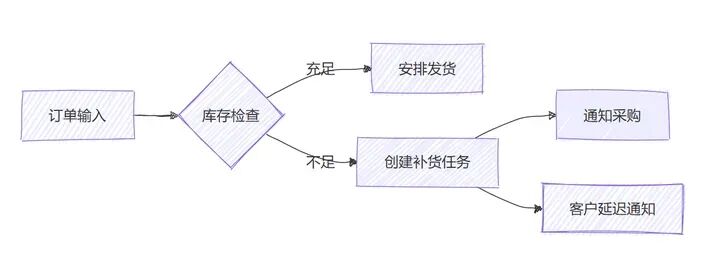
工作流引擎通常以有向无环图(DAG) 为核心模型,图中的每个节点代表一个子任务,节点间的连线定义了任务的执行顺序(如“先完成市场调研,再进行竞品分析,最后制定定价策略”)。以“生成年度销售分析报告”为例,引擎的调度逻辑如下:
- 调度“数据采集Agent”:从企业ERP系统、销售管理软件中抓取全年销售数据(如各区域销量、客单价、复购率);
- 数据校验:若采集数据存在缺失,自动触发“数据补全Agent”补充信息;
- 调度“数据分析Agent”:对清洗后的数-据进行多维度分析(如同比/环比增长、热门产品排行);
- 调度“报告撰写Agent”:基于分析结果生成结构化报告,并调用“可视化Agent”插入图表(柱状图、折线图);
- 最终整合:将报告初稿与数据附件打包,反馈给用户。
这种模块化的调度方式,不仅提升了任务执行效率,还便于后期维护——若需优化“数据分析”环节,只需替换对应的Agent,无需重构整个工作流。
3. RAG增强检索:解决LLM“知识滞后”与“幻觉”的关键
大型语言模型(LLM)虽具备强大的生成能力,但存在两大核心缺陷:一是知识存在“截止日期”(如2023年训练的模型无法获取2024年的新数据),二是可能生成与事实不符的“幻觉内容”(如编造不存在的学术论文)。RAG(Retrieval-Augmented Generation,检索增强生成)技术通过将LLM与外部知识库联动,有效弥补了这些不足。
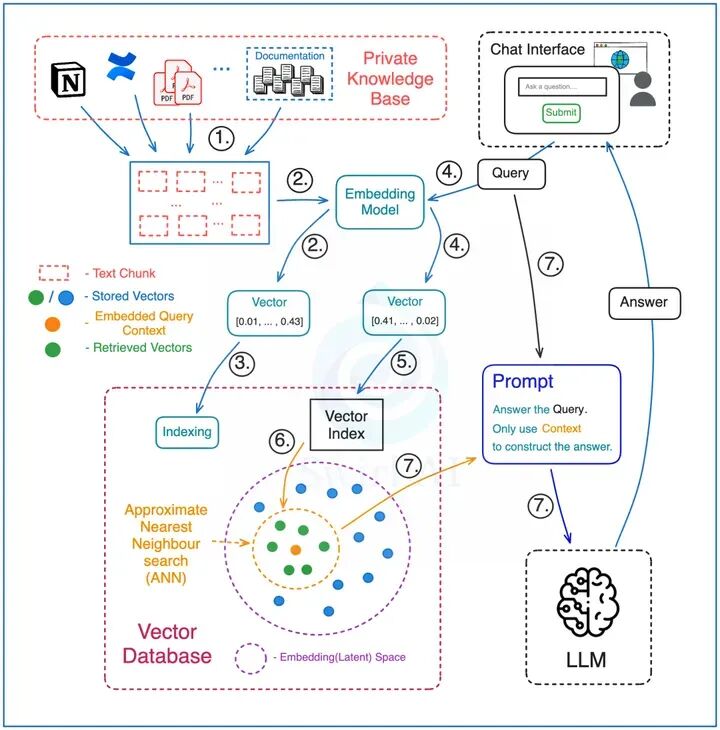
RAG的工作流程分为“预处理”与“检索生成”两大阶段:
预处理阶段:构建可检索的知识库
- 文档切片:将原始知识文档(如PDF报告、学术论文、企业手册)按照逻辑段落拆分为500-1000字的“知识块(Chunks)”,避免因文本过长导致检索精度下降;
- 向量编码:通过嵌入模型(Embedding Model) 将每个知识块转换为高维数值向量——这些向量会保留文本的语义信息,例如“人工智能”与“AI”的向量会高度相似;
- 向量存储:将编码后的向量与对应的知识块元数据(如文档来源、页码)一同存入向量数据库(如Milvus、Pinecone),为后续快速检索奠定基础。
检索生成阶段:基于实时检索生成精准答案
- 问题编码:当Agent接收到用户问题(如“2024年中国人工智能市场规模是多少?”),先通过相同的嵌入模型将问题转换为向量;
- 相似性检索:向量数据库根据问题向量,快速计算其与库中所有知识块向量的相似度,召回Top 5-10个最相关的知识块(如“2024中国AI市场白皮书”中的相关数据);
- 精准生成:将召回的知识块作为“事实依据”,与用户问题一同填入Prompt模板,提交给LLM,引导其基于真实数据生成答案,避免“幻觉”。
# 预处理阶段:知识库构建核心代码示例
# 1. 文档切片(使用langchain库)
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_text(knowledge_base_text) # knowledge_base_text为原始文档内容
# 2. 向量编码(使用开源嵌入模型sentence-transformers)
from sentence_transformers import SentenceTransformer
embed_model = SentenceTransformer('all-MiniLM-L6-v2')
embeddings = embed_model.encode(chunks, convert_to_tensor=True)
# 3. 向量存储(使用Milvus)
from pymilvus import Collection, FieldSchema, CollectionSchema, DataType
# 定义向量字段(维度需与嵌入模型输出一致,all-MiniLM-L6-v2输出384维)
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=384),
FieldSchema(name="content", dtype=DataType.VARCHAR, max_length=1000)
]
schema = CollectionSchema(fields=fields, description="AI知识库")
collection = Collection(name="ai_knowledge_base", schema=schema)
# 插入数据
insert_data = [embeddings.tolist(), chunks] # 注意顺序与字段对应
collection.insert(insert_data)
collection.create_index(field_name="embedding", index_params={"metric_type": "L2"}) # 构建索引提升检索速度
# 检索生成阶段:基于用户问题生成答案
user_query = "2024年中国人工智能市场规模是多少?"
# 1. 问题编码
query_embed = embed_model.encode(user_query, convert_to_tensor=True).tolist()
# 2. 相似性检索
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
results = collection.search(
data=[query_embed],
anns_field="embedding",
param=search_params,
limit=5, # 召回Top5相关知识块
output_fields=["content"]
)
# 3. 提取检索结果
retrieved_content = [hit.entity.get("content") for hit in results[0]]
# 4. 调用LLM生成答案(以OpenAI GPT-3.5为例)
from openai import OpenAI
client = OpenAI(api_key="your_api_key")
prompt = f"基于以下事实信息,回答用户问题:{user_query}\n事实信息:{retrieved_content}"
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}]
)
print(response.choices[0].message.content)
RAG技术在企业级应用中尤为重要,例如金融领域的“智能投研Agent”可通过RAG实时检索最新政策、行业报告;医疗领域的“问诊辅助Agent”能基于最新临床指南生成建议。目前已有不少开源工具简化了RAG的搭建流程,例如通过开源版Coze搭建私有化知识库问答智能体,企业可快速接入内部文档,实现专属领域的精准问答。
4. 模型微调(Fine-tuning):让LLM适配特定领域需求
通用LLM(如GPT-4、Llama 3)虽能处理日常任务,但在专业领域(如法律、医疗、工业制造)中,往往因不熟悉行业术语、业务逻辑而生成不符合需求的内容。模型微调通过对LLM进行“针对性训练”,使其掌握特定领域的知识与规则,成为“领域专家”。
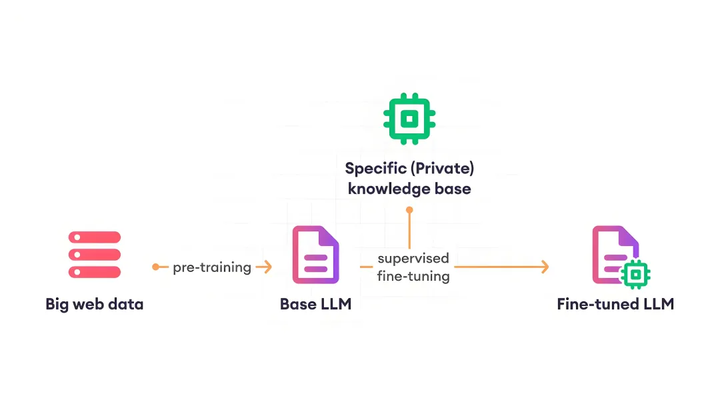
目前主流的微调方式分为两类,各有适用场景:
- 全参数微调(Full Fine-tuning):对LLM的所有参数(通常数十亿至千亿级)进行更新,相当于“重塑模型的认知体系”。这种方式能最大程度地将领域知识融入模型,例如对通用LLM进行全参数微调时,输入大量医疗病例、临床指南,可使其具备专业的医学问答能力。但全参数微调的缺点显著:需要海量标注数据(通常数十万条以上)、极高的计算资源(需多台GPU服务器,训练周期长达数周),成本高昂,更适合对模型精度要求极高的科研场景或大型企业。
- PEFT高效微调(Parameter-Efficient Fine-tuning):核心思路是“冻结LLM的大部分基础参数,仅训练少量新增的‘适配器(Adapter)’参数”。例如LoRA(Low-Rank Adaptation)技术,会在LLM的关键层(如注意力层)插入小型矩阵,仅训练这些矩阵的参数,参数总量仅为原模型的0.1%-1%。PEFT微调的优势明显:数据需求少(数千至数万条标注数据即可)、计算成本低(单台GPU即可完成,训练周期仅需数小时至数天),且微调后的模型可快速与原模型合并或单独加载,灵活性高。目前PEFT已成为商业场景的主流选择,例如电商企业可通过PEFT微调,让通用LLM快速掌握“商品推荐话术”“售后问题处理逻辑”,无需承担全参数微调的高昂成本。
5. 函数调用:连接虚拟能力与现实世界的“桥梁”
LLM的核心能力是生成文本,但要让AI智能体完成实际任务(如查询天气、预订机票、控制智能家居),必须通过“函数调用”实现——它允许Agent调用外部API、本地代码或硬件接口,将虚拟的思考转化为现实世界的行动。

函数调用的标准流程可分为五步:
- 需求判断:Agent接收用户需求后,先分析是否需要外部工具支持。例如用户提问“明天上海会下雨吗?”,Agent判断自身无实时天气数据,需调用天气API;若用户提问“1+1等于几?”,则无需调用工具,直接回答。
- 生成调用指令:LLM根据需求,生成结构化的函数调用指令(通常为JSON格式),明确指定“函数名称”“参数”“参数格式”。例如调用天气API时,需包含“城市名称”“查询日期”“温度单位”等关键参数,避免因参数缺失导致调用失败。
- 执行函数调用:应用程序解析LLM生成的JSON指令,验证参数合法性(如“城市名称是否存在”“日期是否为未来日期”),然后向目标接口发起请求(如调用第三方天气API),或执行本地代码(如读取Excel文件)。
- 接收返回结果:函数执行完成后,将结果以结构化格式(如JSON、表格)返回给Agent。例如天气API返回“上海明日天气:多云,气温18-25℃,无降水”。
- 结果处理与响应:Agent分析返回结果,判断是否需要进一步行动(如“是否需要根据天气推荐出行装备”),或直接将结果整理为自然语言,反馈给用户。
// 函数调用指令示例(LLM生成的JSON)
{
"function": "get_real_time_weather", // 函数名称:获取实时天气
"params": {
"location": "上海市", // 参数1:城市名称(必填)
"date": "2024-06-10", // 参数2:查询日期(必填,格式YYYY-MM-DD)
"unit": "celsius", // 参数3:温度单位(可选,默认celsius,可选fahrenheit)
"language": "zh-CN" // 参数4:返回语言(可选,默认zh-CN)
},
"timeout": 5 // 可选参数:调用超时时间(单位:秒)
}
// 函数执行返回结果示例(API返回的JSON)
{
"status": "success", // 调用状态:success/failure
"data": {
"location": "上海市",
"date": "2024-06-10",
"weather": "多云",
"temperature": {
"min": 18,
"max": 25,
"unit": "celsius"
},
"precipitation": "0%", // 降水概率
"wind": "东北风3级"
},
"message": "" // 错误信息(调用成功时为空)
}
在实际应用中,函数调用需注意“参数校验”与“错误处理”——例如用户输入“明天外星会下雨吗?”,Agent需先校验“城市名称”是否合法,避免无效调用;若API因网络问题返回错误,Agent需告知用户“当前无法获取天气数据,请稍后重试”,提升用户体验。
协作层:构建多Agent协同的“智能团队”
当任务复杂度超过单一Agent的能力边界(如“完成一款APP的从需求分析到上线部署”),就需要多个Agent组成“团队”,通过协作实现目标。协作层技术的核心,是解决“Agent间如何沟通、如何分工、如何协同”的问题。
6. 多Agent协作(Agentic AI):模拟人类团队的“分工协作模式”
Agentic AI的理念是“让AI智能体像人类团队一样工作”——每个Agent拥有明确的角色、专业技能与职责范围,通过共享信息、协同行动,完成复杂任务。这种模式的关键在于“角色定义”与“协作机制”。
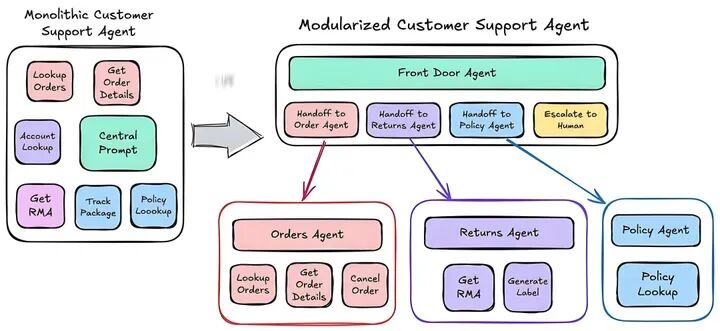
以“自动化软件开发”这一典型场景为例,多Agent协作的架构与分工如下:
- 需求分析师Agent:负责接收用户需求(如“开发一款校园二手交易APP”),通过提问澄清细节(如“是否需要实名认证?支付方式支持哪些?”),最终输出结构化的《需求规格说明书》,明确功能模块(如“商品发布、搜索、下单、聊天”)、非功能需求(如“APP响应时间<2秒”)。
- 项目经理Agent:基于《需求规格说明书》,拆解任务清单(如“UI设计、后端接口开发、前端页面开发、测试”),制定项目时间表(如“UI设计3天完成,后端开发7天完成”),并为每个任务分配对应的Agent。
- UI设计师Agent:根据需求文档,生成APP的界面设计图(如首页、商品详情页、个人中心),输出Figma格式的设计文件,并传递给前端开发Agent。
- 后端开发Agent:基于需求文档设计数据库结构(如“用户表、商品表、订单表”),开发API接口(如“用户注册接口、商品查询接口、订单提交接口”),并编写接口文档。
- 前端开发Agent:根据UI设计图与后端API文档,开发APP的前端页面,实现页面跳转、数据渲染、用户交互等功能(如“点击商品卡片进入详情页”“提交订单时调用后端接口”),完成后将前端代码提交至代码仓库。
- 测试工程师Agent:从代码仓库拉取前后端代码,搭建测试环境,执行多维度测试——包括功能测试(如“验证商品能否正常发布”)、兼容性测试(如“在安卓/ios系统下是否正常显示”)、性能测试(如“同时100人访问时APP是否卡顿”),生成《测试报告》,标注bug(如“下单时未校验库存,导致超卖”)并反馈给开发Agent。
- 后端/前端开发Agent:根据《测试报告》修复bug(如“后端增加库存校验逻辑”“前端优化页面加载速度”),修复后重新提交代码,由测试工程师Agent二次验证。
- 部署工程师Agent:当所有测试通过后,将APP代码部署至生产环境(如安卓应用市场、ios App Store),并配置服务器、数据库等基础设施,确保APP可正常访问。
在协作过程中,需通过“共享知识库”与“实时通信机制”保障信息同步——例如所有Agent可访问同一个云端文档库,实时查看《需求规格说明书》《测试报告》的更新;当后端开发Agent修改了API接口时,会自动向前端开发Agent发送通知,避免因信息滞后导致开发偏差。这种分工明确、信息互通的协作模式,能大幅提升复杂任务的执行效率,且可根据任务需求灵活增减Agent(如“若需要多语言版本,可新增‘翻译Agent’负责界面文字翻译”)。
7. MCP协议(Model Context Protocol):打破多Agent通信壁垒的“通用语言”
在实际应用中,多Agent系统往往由不同团队、不同技术栈开发——例如一个Agent基于OpenAI GPT-4构建,另一个基于Meta Llama 3构建,还有一个基于开源的Qwen模型构建。这些Agent使用的模型、数据格式、工具接口各不相同,直接通信会面临“语言不通”的问题。MCP协议(Model Context Protocol)的核心作用,就是定义一套跨模型、跨平台的通用通信标准,让不同来源的Agent能够顺畅交互。
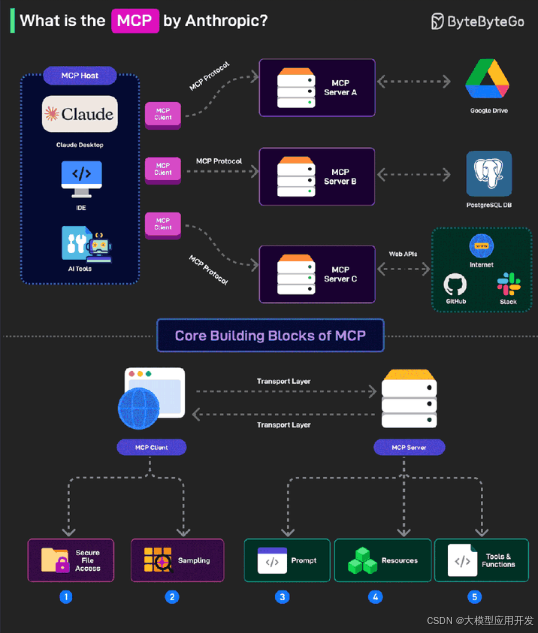
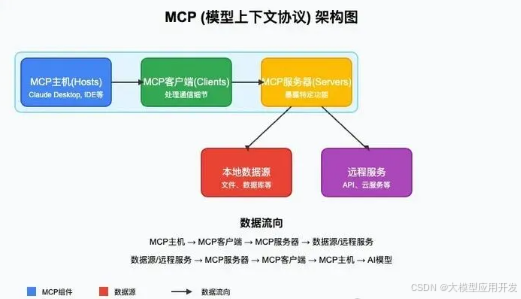
MCP协议主要规范了三个核心维度的通信内容,确保Agent间信息传递的一致性与完整性:
- 上下文传递规范:定义了Agent间传递“任务上下文”的标准格式,包括“任务ID”(用于标识同一任务的不同协作环节)、“历史交互记录”(如“之前已完成的子任务、已交换的信息”)、“当前任务状态”(如“待执行、执行中、已完成”)。例如,当需求分析师Agent将《需求规格说明书》传递给项目经理Agent时,需按照MCP格式封装信息:
{"task_id":"dev_campus_app_20240610",// 任务唯一标识"sender":"requirement_analyst_agent_v1.0",// 发送方Agent标识"receiver":"project_manager_agent_v2.1",// 接收方Agent标识"context_type":"requirement_document",// 上下文类型"content":{"document_name":"校园二手交易APP需求规格说明书","version":"v1.0","update_time":"2024-06-10 15:30:00","content_url":"https://cloud-doc.example.com/dev_campus_app/req_v1.0.pdf",// 文档存储地址"key_summary":["支持实名认证","包含商品发布/搜索/下单功能","响应时间<2秒"]// 核心信息摘要},"timestamp":"2024-06-10 15:35:22"// 传递时间戳} - 工具接口规范:统一了Agent调用外部工具(或其他Agent提供的服务)的接口格式,包括“工具名称”“参数定义”“返回结果格式”。例如,若测试工程师Agent需要调用“性能测试工具”,无论该工具是由哪个团队开发,都需遵循MCP定义的接口格式发起请求,确保工具能正确解析参数:
{"tool_name":"performance_test_tool",// 工具名称"tool_version":"v3.2",// 工具版本"params":{"test_url":"https://campus-app.example.com/api/goods",// 测试接口URL"concurrent_users":100,// 并发用户数(参数类型:整数)"test_duration":60,// 测试时长(单位:秒,参数类型:整数)"metrics":["response_time","error_rate"]// 需监控的指标},"callback_url":"https://test-agent.example.com/callback"// 测试结果回调地址} - 状态同步规范:定义了Agent如何向协作伙伴同步自身任务进度与状态(如“执行中、已完成、异常中断”),避免因状态不透明导致协作混乱。例如,后端开发Agent在完成“订单接口开发”后,会向项目经理Agent与前端开发Agent发送状态同步消息:
{"task_id":"dev_campus_app_20240610_task3",// 子任务ID"agent_id":"backend_dev_agent_v1.5",// 发送方Agent标识"status":"completed",// 状态:completed/processing/failed"progress":100,// 进度(百分比)"completion_time":"2024-06-15 11:20:30",// 完成时间"output":{"api_doc_url":"https://backend-doc.example.com/order-api",// 输出物:接口文档地址"test_url":"https://test-backend.example.com/api/order"// 测试环境接口URL},"message":""// 附加信息(如状态为failed时,说明失败原因)}
MCP协议的价值在于“降低多Agent协作的门槛”——无论Agent背后使用何种模型、何种技术栈,只要遵循同一套MCP标准,就能实现“即插即用”的协作。例如,企业可将外部第三方的“支付Agent”(遵循MCP协议)直接接入内部的“电商APP开发多Agent系统”,无需额外开发适配接口,大幅提升系统的扩展性。
8. A2A协议(Agent-to-Agent):实现多Agent“动态发现与调用”的“服务网络”
如果说MCP协议解决了“Agent间如何规范通信”的问题,那么A2A协议(Agent-to-Agent)则聚焦于“Agent如何找到能协作的伙伴”——它通过标准化的“Agent身份描述”与“服务发现机制”,让Agent能够在复杂的生态中,快速找到具备所需能力的其他Agent,并发起调用。
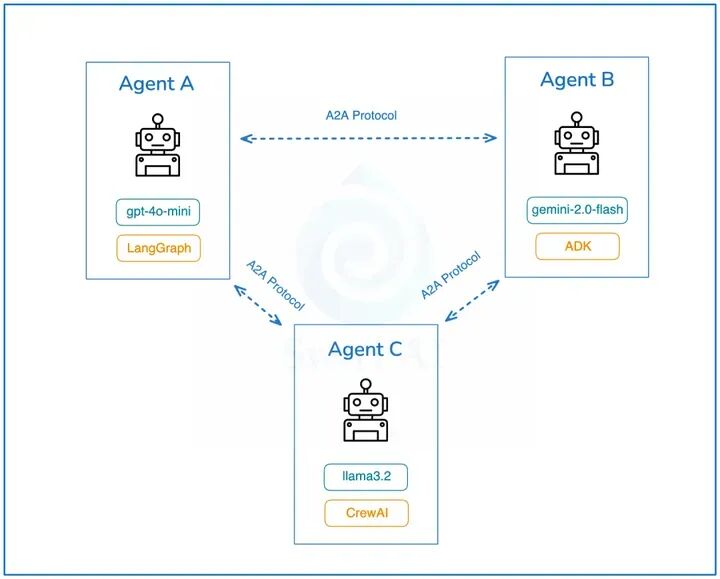
A2A协议的核心组件是“Agent Card(智能体名片)”与“服务注册中心”:
-
Agent Card:标准化的“能力说明书”
每个遵循A2A协议的Agent,都会生成一张结构化的“Agent Card”,清晰描述自身的核心信息,相当于给Agent打造了一张“数字名片”。其核心内容包括:- 基础信息:Agent的唯一标识(Agent ID,如“weather_agent_shanghai_001”)、名称(如“上海实时天气查询Agent”)、开发者(如“某气象科技公司”)、版本号(如“v2.0”)、服务状态(如“在线/离线”);
- 能力范围:明确该Agent能提供的服务(如“查询中国各城市未来7天天气、生成天气预警通知、导出天气数据报表”)、服务限制(如“每天最多提供1000次免费查询,超过需付费”)、输入输出格式(如“输入:城市名称+日期;输出:JSON格式的天气数据”);
- 调用方式:包括调用地址(如API URL:“https://weather-agent.example.com/call”)、认证方式(如“API Key认证”)、通信协议(需兼容MCP协议,确保信息格式一致)。
一个简化的Agent Card示例如下:
{"agent_id":"weather_agent_shanghai_001","agent_name":"上海实时天气查询Agent","developer":"Shanghai Meteorological Technology Co., Ltd.","version":"v2.0","status":"online","capabilities":[{"service_name":"7_day_weather_query","description":"查询中国任意城市未来7天的天气数据(温度、降水、风力)","limits":"免费调用1000次/天,超出部分0.01元/次","input_schema":{"location":{"type":"string","required":true,"description":"城市名称,如‘上海市’"},"language":{"type":"string","required":false,"default":"zh-CN","options":["zh-CN","en-US"]}},"output_schema":{"location":"string","forecast_days":[{"date":"string","weather":"string","temp_min":"number","temp_max":"number","wind":"string"}]}}],"invocation_info":{"call_url":"https://weather-agent.example.com/api/v2/query","auth_type":"api_key","protocol":"MCP_v1.1"}} -
服务注册中心:Agent的“黄页目录”
所有遵循A2A协议的Agent,都会将自己的“Agent Card”注册到一个或多个“服务注册中心”——这相当于一个公开的“Agent黄页”,记录了所有在线Agent的能力与调用方式。当一个Agent需要某种服务时,只需向服务注册中心发起“能力查询”请求,即可快速找到匹配的Agent。以“电商APP的订单Agent需要查询用户所在城市的天气,判断是否需要延迟发货”为例,A2A协议的调用流程如下:
- 发起查询:订单Agent向服务注册中心发送请求,说明所需服务(“查询北京市2024-06-20的天气,判断是否有暴雨”);
- 匹配Agent:服务注册中心根据请求,检索所有注册的Agent Card,筛选出具备“城市天气查询能力”且“服务状态在线”的Agent(如上述“上海实时天气查询Agent”);
- 返回结果:服务注册中心将匹配到的Agent Card(包含调用地址、认证方式)返回给订单Agent;
- 发起调用:订单Agent根据Agent Card中的信息,遵循MCP协议向天气查询Agent发起调用,传入“北京市”“2024-06-20”等参数;
- 接收反馈:天气查询Agent返回“北京市2024-06-20有暴雨”的结果,订单Agent基于此决定“延迟发货,并向用户发送通知”。
A2A协议的核心价值在于“动态性”与“开放性”——它允许Agent在不预先知晓其他Agent存在的情况下,通过服务注册中心快速找到协作伙伴,实现“按需调用”。例如,当一个新的“物流跟踪Agent”(遵循A2A协议)注册到服务中心后,所有需要“物流信息查询”的Agent(如电商APP的订单Agent、外卖APP的配送Agent)都能自动发现并调用它,无需人工配置,大幅提升了多Agent生态的灵活性与扩展性。
总结
AI智能体的开发并非单一技术的应用,而是“基础层能力构建”与“协作层生态协同”的有机结合。基础层的5大技术(核心工作流、工作流引擎、RAG增强检索、模型微调、函数调用),为单个Agent打造了“能思考、能行动、能适配”的核心能力,是智能体运行的“技术基石”;协作层的3大技术(多Agent协作、MCP协议、A2A协议),则打破了单个Agent的能力边界,通过“分工、通信、发现”机制,构建了可无限扩展的“智能体团队生态”,让复杂任务的高效完成成为可能。
随着AI技术的快速演进,智能体的应用场景将从“单一任务自动化”(如智能客服、天气查询)向“复杂系统智能化”(如全自动软件开发、智慧城市管理)拓展。对于开发者而言,理解并掌握这8大核心技术,不仅能快速搭建符合需求的AI智能体,更能在未来的“智能体时代”抢占技术先机——无论是企业级的私有化智能体部署,还是面向公众的智能体服务开发,这些技术都将成为不可或缺的核心竞争力。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习_,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和MoPaaS魔泊云联合梳理打造了系统大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!

【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与MoPaaS魔泊云的鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









