



前言
RAG教程满天飞。随便搜一下,“手把手教你搭建RAG”、“10分钟跑通RAG”、“RAG最佳实践”……看起来很简单对吧?
但真正上手就会发现:教程里的demo跑得飞起,换成自己的文档就拉胯。
为什么?
因为大多数教程在教你怎么跑通,而不是怎么做好。它们会告诉你用什么向量库、怎么调Top-k、怎么写Prompt——但这些都是"能跑起来"的60分线,不是"效果好"的90分线。
我研究了一周RAG,发现真正决定效果的是两道坎:
- • 第一道坎:解析层——看得见的坎,你的文档有没有被正确解析
- • 第二道坎:检索层——看不见的坎,检索策略的调优没有标准答案
解析层是门槛,做不好是0分;检索层是天花板,从60到90全靠这里。
这篇文章不是另一个"跑通RAG"的教程,而是我对这两道坎的理解,以及架构选型、框架对比、企业落地的判断。
有偏差欢迎拍砖。
一、第一道坎:解析层
大多数教程跳过这个环节,直接教你怎么切块、怎么检索。但如果文档解析就是错的,后面全白搭。
1.1 RAG七阶段Pipeline
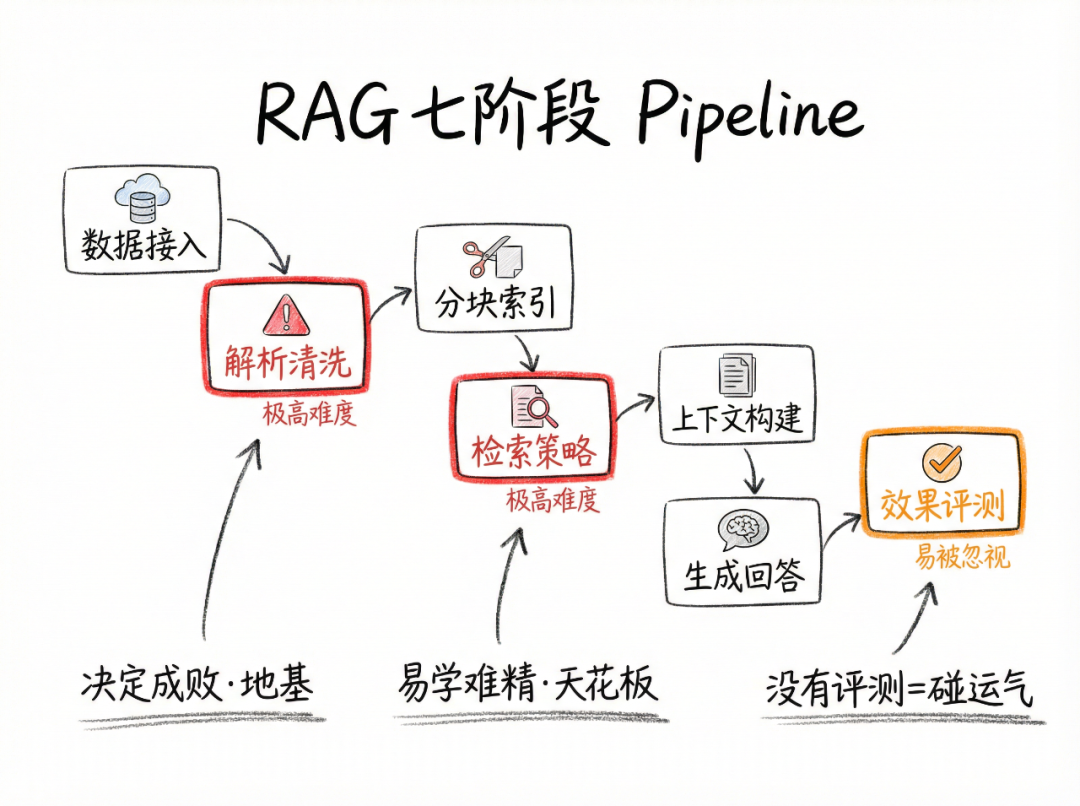
RAG系统可拆解为七个阶段:
| 阶段 | 核心任务 | 标准化程度 | 启动门槛 | 落地上限 | 核心痛点 |
|---|---|---|---|---|---|
| 1. 数据接入 | 连接数据源 | 中 | 中 | 中 | 工程繁琐。OA三巨头虽有API但取内容难;老旧私有系统(OA/ERP)基本靠定制或人工导出 |
| 2. 解析清洗 | 非标转结构化 | 极低 | 中 | 极高 | 决定成败。复杂PDF、表格、公式尚无完美解析方案,数据洗不干净,后续算法再强也是徒劳 |
| 3. 分块索引 | 语义切片 | 中 | 低 | 中 | 语义断裂。简单按字数切分会导致上下文丢失;引入语义切分成本较高 |
| 4. 检索策略 | 召回+重排序 | 高 | 低 | 极高 | 易学难精。跑通流程仅需几行代码,但要解决"查得准"(多跳推理/精确匹配)极度依赖调优 |
| 5. 上下文构建 | 提示词组装 | 中 | 低 | 中 | 窗口博弈。长文本下的"迷失中间"问题,随着长窗口模型普及,难度略有下降 |
| 6. 生成回答 | LLM生成 | 极高 | 极低 | 低 | 同质化严重。调用通用大模型API即可,除特定行业微调外,各家能力差异不大 |
| 7. 效果评测 | 体系化验收 | 低 | 低 | 高 | 重建设轻验收。缺乏体系化的基准测试集,导致优化方向不明,迭代全凭体感 |
从这张表能看出什么?
两个"极高"落地上限的环节:解析清洗和检索策略。这就是我说的两道坎。
另外注意效果评测:启动门槛低,但落地上限高(认真做起来不简单)。大多数团队选择跳过,结果就是优化全凭体感,改了也不知道对不对。
1.2 为什么「解析」最难标准化?
数据现实:大量企业数据仍以PDF、扫描件、富文本为主,结构混乱。
行业差异:不同领域有不同的复杂文档——
| 行业 | 典型复杂文档 |
|---|---|
| 金融 | 财报、合同条款、嵌套表格 |
| 医疗 | 检验报告、多语言混排 |
| 技术 | 规格书、流程图、公式 |
技术栈复杂:解析不是单一技术,而是多层叠加——OCR → 版面分析 → 表格结构识别 → 领域规则 → 质量
评测。还要处理页眉页脚、脚注、跨页表格、嵌套列表、编号错乱……
结论:这不是按字数机械切分就能解决的问题。
1.3 商业化逻辑:为什么都在解析环节收费
三个字:难、脏、贵。
| 特征 | 说明 |
|---|---|
| 难 | 技术栈复杂,需OCR+版面+表格+多模态多管线协同 |
| 脏 | 需要大量标注数据、领域经验规则、后处理逻辑 |
| 贵 | 训练/微调多模态模型,构建数据处理流水线成本高 |
看看头部玩家怎么收费的:
LlamaIndex推出的LlamaCloud,核心卖点就是LlamaParse——一个文档解析服务。定价模式很直接:按页收费,每页几美分。复杂文档(嵌套表格、扫描件、多语言)价格更高。
为什么客户愿意买单?因为价值主张极其清晰:
- • “你的PDF解析成一坨屎,我帮你解析成结构化数据”
- • “跨页表格、嵌套表格、扫描件,我都能处理”
- • “你自己搞需要养一个团队,用我的服务按页付费”
相比之下,“我们检索更聪明”、"我们重排序多加了一层"这种卖点,客户根本没感知。你说准确率提升5%,客户问:怎么证明?
而且检索层的技术大多是开源标准方案——向量库有Milvus、Qdrant、pgvector,重排序有开源模型,混合检索也不是秘密。你能做的,别人也能做。没有技术壁垒,就很难收费。
这就是为什么解析层容易商业化,检索层不容易。
1.4 对下游的影响:Garbage In, Garbage Out
解析质量对RAG效果的影响是质变级别的:
- • 表格解析错误 → 检索召回错误信息 → 生成答案胡说八道
- • 跨页内容断裂 → 上下文不完整 → 回答片面或矛盾
- • 格式丢失 → 层级关系消失 → 无法做结构化检索
一句话:解析是RAG的「地基」,地基歪了,上面盖什么都白搭。
解析层是RAG的第一道坎——看得见的坎。
文档解析错了,一眼能看出来;解析对了,至少能拿60分。这道坎的特点是:难,但有解。砸钱砸人,总能搞定。
另外别忘了评测。大多数RAG项目死在"不知道哪里出了问题",根本原因是没有评测体系。后面会专门讲这个。
60分到90分,靠的是下一道坎。
二、第二道坎:检索层
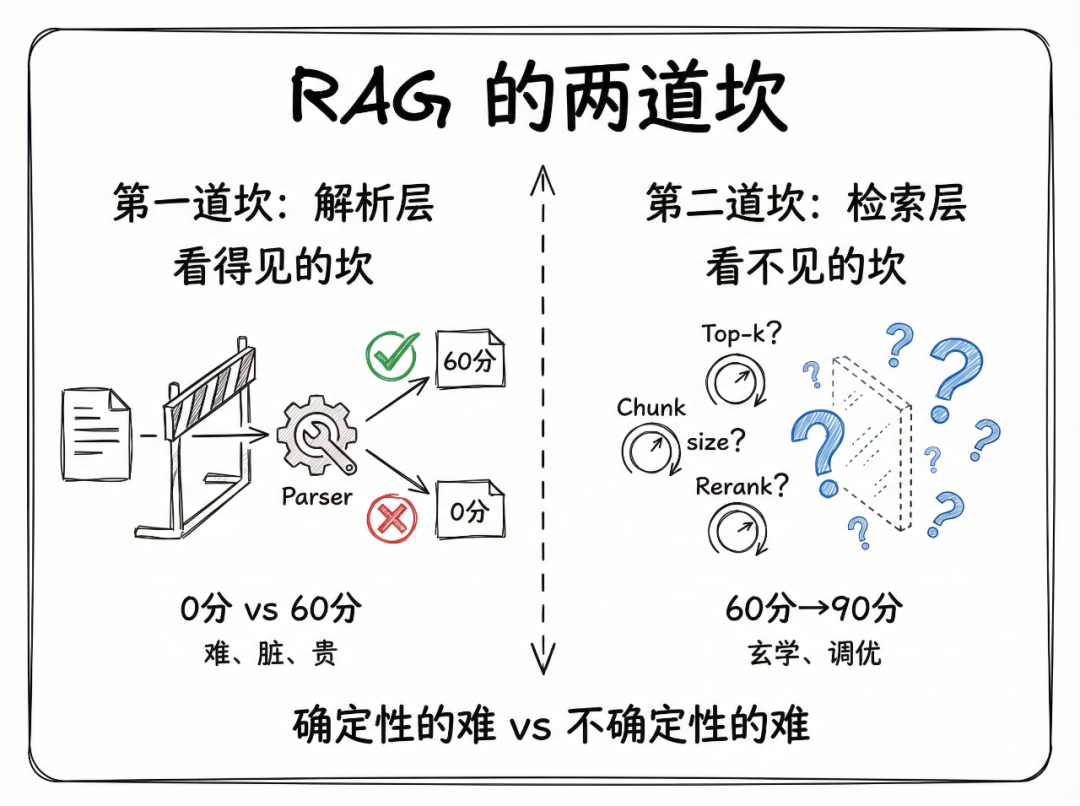
2.1 为什么检索层更难?
解析层是工程问题,检索层是调优问题。
| 维度 | 解析层 | 检索层 |
|---|---|---|
| 难度类型 | 确定性的难 | 不确定性的难 |
| 特点 | 脏、累、但有解 | 玄学、组合爆炸、没有标准答案 |
| 评测 | 容易(对不对一眼看出来) | 困难(什么叫"检索好"?) |
| 投入产出 | 砸钱能解决 | 砸钱不一定有用 |
检索层的痛苦在于:
- • Top-k设多少? 设3可能漏信息,设10可能引入噪音
- • Chunk size怎么定? 256还是512还是1024?没有标准答案
- • 要不要Rerank? 加了延迟上升,不加准确率差
- • 混合检索权重怎么配? BM25和向量各占多少?
每个参数都能调,但调了也不知道对不对。80%的case好调,剩下20%的边界case能把人逼疯。
举个真实的例子:
用户问"Q3销售额是多少",你的RAG返回了Q2的数据。为什么?
可能是:
- • 向量相似度上,"Q3销售额"和"Q2销售额"几乎一样
- • 恰好Q2那段内容更长、信息更密集,得分更高
- • 或者根本就是解析问题——Q3的表格解析错了
你怎么判断是哪个环节出了问题?只能一层一层排查。而且修了这个case,可能又搞坏了另一个case。
这就是第二道坎:看不见的坎。你以为RAG跑通了,但效果就是上不去,又说不清问题在哪。
2.2 检索层的核心优化方向
好消息是,虽然没有银弹,但有一些成熟的优化方向。
2.3 Naive RAG:能用但局限明显
架构:文档 → 切块 → 向量化 → 向量库 → Top-k检索 → LLM生成
适用场景:简单问答、小规模文档(<100篇)、原型验证
优势:实现简单,开源方案成熟,成本低
致命局限:
| 问题 | 说明 |
|---|---|
| 检索准确率低 | 语义漂移,"Q3财报"可能匹配到Q2、Q4 |
| 上下文碎片化 | 切块太小信息不足,太大检索不准 |
| 无法处理复杂查询 | 多跳推理(需要串联多个信息点才能回答)、对比分析搞不定 |
| 对文档结构无感知 | 层级关系、表格结构全丢失 |
2.4 Advanced RAG:三阶段优化
核心思路:在Naive RAG的基础上,针对检索前、检索中、检索后三个阶段做优化。
这里只列最常用的技术,实际上每个阶段都有大量变体和组合,论文层出不穷。不用全学,挑适合你场景的用。
检索前优化
| 技术 | 原理 | 解决的问题 |
|---|---|---|
| 查询改写 | LLM改写用户问题,使其更适合检索 | 用户表达不清晰 |
| 查询扩展 | 扩展同义词、相关词 | 召回不全 |
| 查询拆解 | 把复杂问题拆成子问题,分别检索 | 复杂问题难以一次命中 |
| HyDE | 先让LLM生成假设性答案,用答案去检索 | 问题和文档的语义空间不匹配 |
其他还有:查询路由(根据问题类型选不同检索器)、意图识别、查询分类等。
检索中优化
| 技术 | 原理 | 适用场景 |
|---|---|---|
| 层级检索 | 先检索文档摘要,再检索具体段落 | 多文档(100+) |
| 句子窗口 | 用单句做检索,返回时扩展上下文 | 需要精确匹配+上下文 |
| 混合检索 | BM25(关键词)+ 向量(语义)并行 | 需要精确匹配+语义理解 |
| 父子chunk | 检索用小chunk,返回用大chunk(父chunk) | 精确召回+完整上下文 |
其他还有:多路召回、向量模型微调、动态chunk策略等。
检索后优化
| 技术 | 原理 | 效果 |
|---|---|---|
| 重排序 | 用更精细的模型对检索结果重新打分 | 显著提升准确率 |
| 压缩 | 压缩检索到的上下文,去除冗余 | 减少token消耗 |
| 过滤 | 基于规则/模型过滤低质量结果 | 减少噪音 |
其他还有:结果融合、多样性优化、上下文重组等。
关键认知:这些技术不是越多越好。每加一层都有成本(延迟、复杂度、维护负担)。先把基础的做好(混合检索+重排序),再根据具体问题加对应的优化。
2.5 Modular RAG:从固定流程到可编排模块
核心思路:不再是固定的「检索→生成」流程,而是把RAG拆成可插拔模块,自由编排。
关键特征:
- • 模块独立,可单独替换/升级
- • 流程可编排(支持条件分支、循环)
- • 支持并行执行
适用场景:多类型查询需要不同处理流程、需要灵活实验不同组合、生产环境需要模块级监控
优势:灵活性高、便于A/B测试和迭代、模块级可观测性
劣势:架构复杂度上升、需要更多工程投入、调试难度增加
2.6 Graph RAG:知识图谱增强
核心思路:用知识图谱补充向量检索的盲区——实体关系和多跳推理。
向量检索的盲点
举个例子:在一个企业知识库里搜「谁负责Project Titan?」
| 方式 | 过程 | 结果 |
|---|---|---|
| 向量检索 | 语义匹配 → 返回相关段落 | 可能返回项目介绍、项目进度,但就是没有负责人 |
| 知识图谱 | 查询 (人)-[负责]->(Project Titan) | 直接返回:张三 |
为什么向量检索找不到?因为"张三负责Project Titan"这句话可能根本不存在于任何文档中。它是散落在各处的:组织架构图里有张三是PM,项目文档里有Project Titan的描述,但没有一句话把两者直接关联起来。
知识图谱的三大优势
| 优势 | 示例 |
|---|---|
| 多跳推理 | 「谁是Project Titan负责人的上级?」→ 张三 → 张三的汇报线 → 李总,一次查询搞定 |
| 实体消歧 | 公司有两个「李明」,根据部门、项目上下文匹配正确的那个 |
| 时间推理 | 「去年这个时候谁负责这个项目?」→ 带时间属性的关系 |
什么时候该用Graph RAG?
适用场景:
- • 需要多跳推理(串联多个信息点才能回答)
- • 实体关系密集的领域(企业组织架构、供应链网络、学术论文引用网络、金融股权关系)
不适合:
- • 非结构化长文本(小说、博客)
- • 没有明确实体的抽象概念讨论
- • 纯技术文档(API文档、代码注释)
劣势:构建成本高(需要实体抽取、关系抽取)、维护成本高(知识图谱要持续更新)、实体抽取质量直接影响效果
2.7 Agentic RAG:智能体化检索
核心思路:让智能体自主决策检索策略,而非固定流程。
与传统RAG的本质区别
| 维度 | 传统RAG | Agentic RAG |
|---|---|---|
| 决策者 | 开发者预设规则 | 智能体自主决策 |
| 检索次数 | 固定(通常1次) | 动态(按需多次) |
| 策略选择 | 固定流程 | 根据问题动态选择 |
| 错误处理 | 无 | 自我评估、重试、换策略 |
一个典型例子:Claude Code
Anthropic的Claude Code就是Agentic RAG的典型应用。当你让它帮你改代码时,它会:
-
- 先判断需要看哪些文件(自主决策)
-
- 读取相关代码(检索)
-
- 发现信息不够,再去看其他文件(多轮检索)
-
- 改完之后自己跑测试,发现报错再修(自我纠错)
整个过程不是预设的固定流程,而是根据任务动态调整。这就是Agentic的本质:自主决策+多轮迭代+自我纠错。
Agentic RAG的四种模式
| 模式 | 原理 | 适用场景 |
|---|---|---|
| 路由模式 | 根据问题类型路由到不同检索器 | 多类型查询 |
| 推理-行动循环 | 思考→行动→观察,多步检索 | 复杂问题 |
| 多文档智能体 | 每个文档一个智能体,协调器统筹 | 跨文档对比 |
| 自我纠错 | 检索后自我评估,必要时重新检索 | 高准确性要求 |
优势:真正的自主决策、适应复杂多变场景、可处理传统RAG搞不定的问题
劣势:成本高(多次LLM调用)、延迟大、可控性降低、调试困难、容易陷入死循环
2.8 专项增强
Long-context RAG(长上下文RAG)
核心思路:利用长上下文LLM(100K+ tokens),改变检索粒度。
传统RAG用小chunk(512 tokens),导致检索次数多、上下文碎片化。Long-context RAG反其道而行:用大chunk(4K-8K tokens),减少检索次数,保持文档结构完整。
| 维度 | 传统RAG | 长上下文RAG |
|---|---|---|
| 切块大小 | 512 tokens | 4K-8K tokens |
| 检索数量 | 多个碎片 | 少量完整段落 |
| 上下文 | 拼接后送LLM | 保持文档结构 |
LongRAG论文(2024)的核心发现:把chunk从100词扩大到4K词,在多个数据集上效果显著提升。原因是:小chunk虽然检索精确,但丢失了上下文;大chunk保留了段落完整性,LLM更容易理解。
适用场景:长文档理解(研究论文、法律合同)、需要保持全局结构、章节间有强关联
前提:你得有一个支持长上下文的LLM,而且要承受更高的token成本。
Multi-modal RAG(多模态RAG)
核心思路:处理图文混合文档,保留视觉信息。
传统方案:PDF → OCR → 文本 → 向量化,图表信息丢失
新方案(如ColPali):PDF → 视觉语言模型直接生成页面向量,保留视觉信息
适用场景:文档含大量图表、流程图,技术手册、研究报告,投资材料、设计文档
LightRAG
核心思路:Graph RAG的轻量替代,用更少资源实现图增强。
| 维度 | Microsoft GraphRAG | LightRAG |
|---|---|---|
| Token消耗 | 高(数千/查询) | 低(百级/查询) |
| API调用 | 多次 | 1次 |
| 增量更新 | 需要重建 | 支持 |
优势:资源消耗大幅降低、支持增量更新、部署简单
2.9 架构选型:我的判断
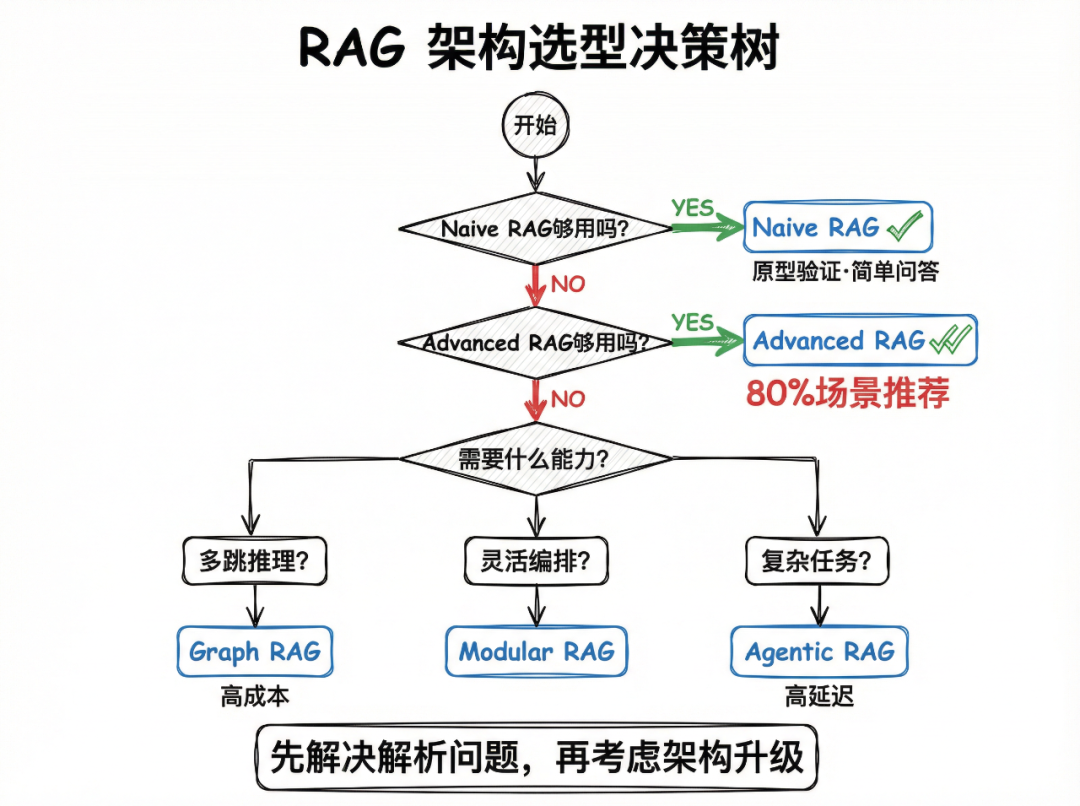
先说结论:80%的场景用Advanced RAG就够了。
很多人一上来就想上Graph RAG、Agentic RAG,觉得越复杂越厉害。但复杂度是有代价的——成本高、延迟大、调试难。
| 架构 | 适用场景 | 复杂度 | 成本 |
|---|---|---|---|
| Naive RAG | 原型验证、简单问答 | 低 | 低 |
| Advanced RAG | 通用搜索、高精度要求 | 中 | 中 |
| Modular RAG | 多类型查询、灵活编排 | 中高 | 中 |
| Graph RAG | 金融/法律/医药、多跳推理 | 高 | 高 |
| Agentic RAG | 编程、复杂多步骤 | 高 | 高 |
| Long-context RAG | 长文档、全局结构 | 中 | 中高 |
| Multi-modal RAG | 图文混合文档 | 中高 | 高 |
| LightRAG | 图增强但预算有限 | 中 | 中 |
我的选型建议
-
- 先问自己:Naive RAG真的不够用吗?很多时候问题出在解析,不在架构
-
- 默认选Advanced RAG(混合检索+重排序),这是性价比最高的方案
-
- Graph RAG听起来很美,但构建和维护成本很高,除非你的场景真的需要多跳推理
-
- Agentic RAG适合复杂任务,但延迟和成本都会飙升,想清楚再上
组合使用建议
实际项目中,往往需要组合多种架构:
| 组合 | 适用场景 |
|---|---|
| Advanced + Long-context | 长文档 + 高精度 |
| Modular + Agentic | 复杂查询 + 灵活编排 |
| Graph + Advanced | 实体关系 + 传统检索互补 |
| Multi-modal + Advanced | 图文文档 + 文本检索 |
2.10 别迷信RAG:什么时候不该用
RAG不是万能药。以下场景要么不适合,要么有更好的选择:
| 场景 | 为什么RAG不合适 | 更好的选择 |
|---|---|---|
| 需要特定语气/风格/人设 | RAG检索的是知识,不是风格。你想让AI说话像鲁迅,检索鲁迅的文章没用 | 微调、few-shot prompt |
| 数据量小且更新频繁 | 维护索引的成本比收益大 | 直接塞进上下文窗口 |
| 创意生成类任务 | RAG会让输出趋向于已有内容,限制创造力 | 纯生成,不检索 |
| 实时性要求极高(<100ms) | 检索+重排序有延迟 | 缓存、预计算 |
| 答案需要综合上百篇文档 | Top-k覆盖不全,拼接也超出上下文 | 预先生成摘要/报告,或用Map-Reduce |
一个简单的判断标准:
问自己两个问题:
-
- 我需要的是知识/事实,还是风格/能力?→ 前者用RAG,后者用微调
-
- 我的数据能放进上下文窗口吗?→ 能且更新频繁,直接塞进去比RAG简单
别为了用RAG而用RAG。
三、主流框架对比与选型
本文聚焦RAG专用框架,通用智能体编排框架(如LangChain)不在讨论范围。
3.1 LlamaIndex
定位:围绕文档和检索的RAG开发框架
核心价值:
- • 抽象出了RAG共性组件(文档加载器、索引、查询引擎),让开发者不用从零搭建
- • 以数据为中心的架构思路
- • 多种索引类型(树形、列表、向量、关键词、知识图谱等)
- • 内置完善的评测模块(忠实度、相关性、正确性等)
- • 紧跟前沿,社区活跃
优点:
-
- RAG技术栈视角完整,不只是「向量库+Top-k」
-
- 评测模块成熟
-
- 云生态绑定紧(GCP/AWS都有官方集成)
-
- 对开发者友好,可自然嵌入现有服务
缺点:
-
- 没有开箱即用的RAG平台
-
- 文档功能宽泛,有学习曲线
-
- 文档解析能力是「够用级」,不是「强迫症级」
生产级RAG的核心设计思路
LlamaIndex官方文档总结了几个关键设计原则:
一、分离检索粒度和合成粒度
核心洞见:检索阶段适合细粒度(句子级),合成阶段需要宽上下文(段落级)。
为什么?文档直接按大块向量化会导致相关句子被埋在中间,从而漏检;先检索"句子级"命中,再关联其周边窗口用于合成,既精确又充分。
二、大规模文档的结构化检索
当文档数量上百上千时,单纯"Top-k语义相似度"会漂移。解决方案:
- • 元数据过滤 + 自动检索:为文档打标签,推理时由LLM自动选择过滤条件
- • 文档层次(摘要→原始块)+ 递归检索:先以摘要做文档级语义查找,锁定候选文档,再深入块级检索
三、根据任务动态调整检索策略
不同任务需要不同策略:
- • 事实问答:高相似度精确命中,少而准
- • 长文摘要:扩大覆盖面,聚合多块
- • 比较/对照:分别检索多来源并对齐
四、领域化向量优化
通用向量模型不一定理解行业语义。对专业术语密集的场景(规范/招标/财报),需要对向量模型做领域数据上的优化/微调。
3.2 RAGFlow
定位:开源RAG引擎,强调「复杂文档解析 + 可视化RAG/智能体工作流」
核心优势
| 维度 | 能力 |
|---|---|
| 深度文档理解 | 表格、布局、图片、扫描件解析,保持结构 |
| 智能切块 | 基于版面的切块,不是无脑按字数切 |
| 可视化干预 | 界面中能看到切块结果和引用,方便业务同学介入 |
| GraphRAG内置 | 知识图谱构建作为预处理步骤,界面里可直接开启 |
| 智能体工作流 | 拖拽式多步流程、多智能体协作 |
与LlamaIndex对比
| 维度 | LlamaIndex | RAGFlow |
|---|---|---|
| 定位 | 数据/RAG/智能体框架,给工程师用的SDK | 深度文档理解+RAG引擎+可视化平台 |
| 使用方式 | 代码驱动(Python/TS) | 部署服务+Web控制台+API |
| 文档解析 | 常规加载器/分割器,支持自定义 | 强调深度文档理解 |
| Graph/GraphRAG | 有支持,但偏代码层实验 | 内置知识图谱构建,界面里可直接开启 |
| 评测 | 内置评测器 | 本身偏执行引擎,评测多依赖外部平台 |
选型建议
- • 想深度折腾RAG评测、检索策略、代码层定制 → LlamaIndex
- • 要复杂PDF/表格/扫描件 + 可视化配置 + 给业务方看的界面 → RAGFlow
3.3 我的选型结论
说实话,框架选型没那么重要。
LlamaIndex和RAGFlow各有侧重,但核心能力差不多。真正影响效果的是:你对业务场景的理解、文档解析的质量、评测体系的完善程度。
如果非要给建议:
- • 默认选LlamaIndex,灵活、社区活跃、可逐步扩展,复杂文档解析可接入LlamaParse
- • 如果你的文档很复杂(PDF/合同/表格),且需要给非技术同事用 → RAGFlow
- • 如果是大型企业,需要跨系统权限管理 → Glean这类企业级产品
别在框架选型上纠结太久。先跑起来,遇到问题再换也不迟。
四、企业级搜索:Glean的设计逻辑
Glean定位为企业内部的"工作AI助理",核心是跨系统的语义搜索+问答。研究它的价值不在于推荐这个产品,而是理解企业级RAG要额外解决什么问题——这些设计思路同样适用于自建系统。
4.1 企业搜索 vs 个人搜索:本质区别
企业搜索和个人搜索的核心差异不在于"有没有"某个能力,而在于复杂度量级:
| 维度 | 个人搜索 | 企业搜索 |
|---|---|---|
| 用户 | 单用户 | 多用户、多角色、多部门 |
| 数据源 | 少量、同质 | 100+异构系统(云盘/聊天工具/知识库/项目管理…) |
| 权限 | 简单或无 | 复杂访问控制、跨系统继承、实时同步 |
| 个性化 | 单用户历史偏好 | 多维度:角色×部门×协作网络×项目上下文 |
| 时效性 | 通用时间衰减 | 场景化(政策必须最新 vs 文档稳定 vs 历史记录不衰减) |
| 术语 | 通用语言 | 大量内部术语、缩写、项目代号 |
核心洞察:
- • 个人搜索:单用户 × 少数据源 × 简单个性化
- • 企业搜索:多用户 × 多数据源 × 多维度个性化 × 权限治理
混合检索(BM25+向量)已是行业标配,不是企业搜索的差异化能力。Glean的核心价值在于处理权限、多维度个性化、场景化时效性、术语理解、数据治理这些企业特有的复杂度。
4.2 统一权限模型
核心问题:企业有100+数据源,每个系统权限模型不同,如何统一?
Glean的解决方案:
| 能力 | 实现方式 |
|---|---|
| 跨系统权限继承 | 从各源系统实时同步访问控制列表,构建统一身份图 |
| 检索时权限过滤 | 权限信息与文档元数据一起索引,检索时直接过滤 |
| 统一权限模型 | 搜索、助手、智能体共用同一套权限 |
关键实现细节:
- • 不是检索后再查权限(太慢),而是权限预先索引
- • 通过实时同步机制同步权限变更
- • 支持权限继承(文件夹权限自动继承到子文件)
4.3 时效性加权
核心问题:旧文档被引用多、内容丰富,向量得分往往更高,但用户要的是最新的。
场景化调整:不是所有查询都需要最新的
- • 搜「公司政策」→ 时效性权重高
- • 搜「技术文档」→ 时效性权重中
- • 搜「历史记录」→ 时效性权重低
这个思路对任何RAG系统都适用:时效性不是一个全局参数,而是要根据查询意图动态调整。
4.4 个性化排序
核心问题:同一个问题,销售和工程师需要的结果不同。
Glean的个性化信号:
| 信号 | 作用 |
|---|---|
| 部门亲和性 | 优先返回用户所在部门的文档 |
| 协作者相关性 | 优先返回常合作同事创建的文档 |
| 历史偏好 | 基于用户过去的点击/阅读行为 |
| 点击数据 | 全公司的点击行为反哺排序 |
实际效果:
- • 销售搜「Q3报告」→ 优先返回销售数据
- • 工程搜「Q3报告」→ 优先返回技术指标
4.5 双层知识图谱
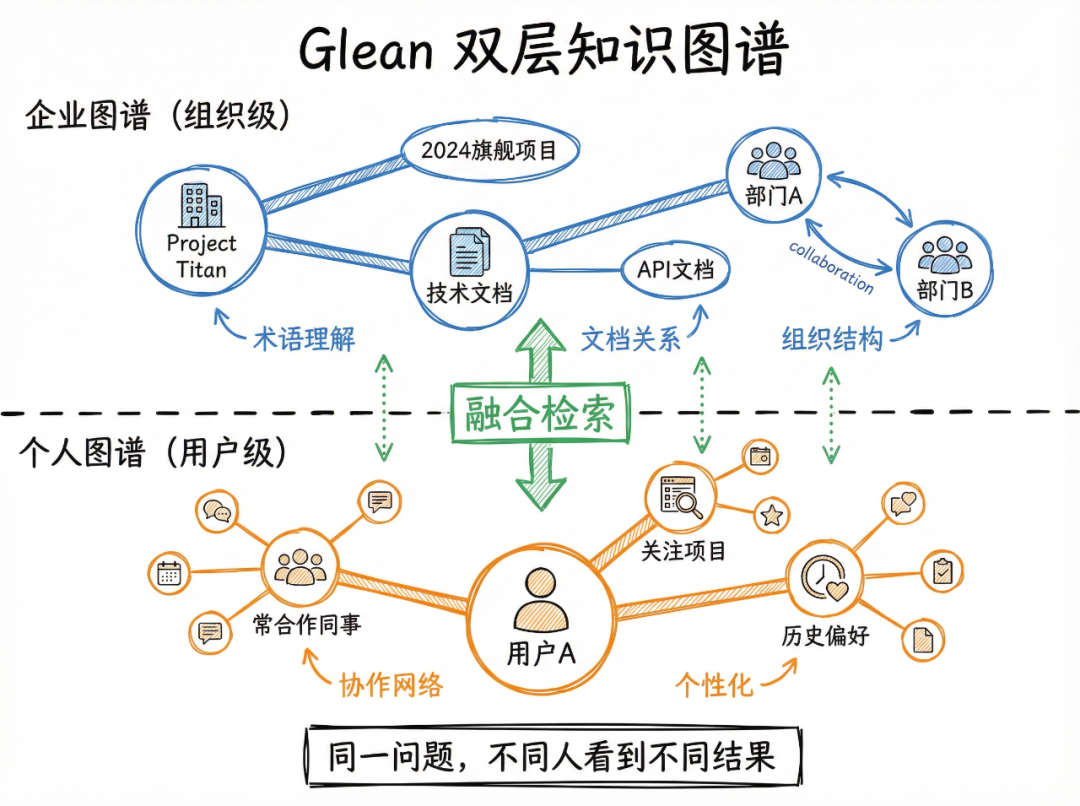
Glean构建两层图谱:企业图谱(组织级)+ 个人图谱(用户级)
企业图谱
| 维度 | 作用 |
|---|---|
| 语义系统 | 理解组织内部术语(Project Titan = 2024旗舰项目) |
| 文档链接 | 文档间的引用/关联关系 |
| 人员网络 | 组织内人员协作关系网络 |
| 概念理解 | 领域概念的同义词、上下位关系 |
个人图谱
| 维度 | 作用 |
|---|---|
| 协作网络 | 用户常合作的同事 |
| 关注领域 | 用户常访问的文档类型/主题 |
| 工作上下文 | 用户当前参与的项目/任务 |
双层图谱的价值:
- • 企业图谱解决「术语理解」和「实体消歧」
- • 个人图谱解决「个性化排序」
- • 两者结合实现:同一个问题,不同人看到与自己最相关的结果
研究Glean不是为了推荐它(大多数团队也用不起),而是想搞清楚:从个人RAG到企业RAG,中间差了什么?
答案是:权限、个性化、时效性、术语理解。
这些问题在个人项目里感知不到,但在企业场景里是刚需。如果你在做ToB的RAG产品,这些是绕不过去的。
五、落地建议
5.1 先建评测体系,再谈优化
这是我最想强调的一点:没有评测体系的RAG优化是在碰运气。
很多人的做法是:上线 → 用户反馈不好 → 调参数 → 再上线 → 还是不好 → 继续调……
问题是:你怎么知道调对了?用户说"不好",是检索不准?还是回答不对?还是根本没理解问题?
比跑指标更重要的是:自己看case,做错误分析。
作为AI产品经理,你至少得亲自看过100个case才能建立体感。不是看指标报告,是一个一个看:用户问了什么、检索到了什么、回答了什么、哪里出了问题。
看多了你会发现错误是有规律的:
- • 某类问题总是检索不到 → 可能是切块策略问题
- • 检索到了但回答错 → 可能是上下文太长LLM没注意到
- • 某个文档反复出问题 → 可能是解析有问题
错误分析比优化更重要。知道错在哪,优化方向才清晰。
评测工具方面,LlamaIndex内置了评测模块,包含诸如:忠实度(Faithfulness)、相关性(Relevancy)、正确性(Correctness)、语义相似度(Semantic Similarity)等指标。
开源工具还有Ragas(专注RAG评测)、DeepEval(更全面的LLM评测框架)、Arize Phoenix(观测平台)等。但工具只是辅助,核心还是你对case的理解。
评测这块内容很多,我准备单独写一篇展开。
5.2 分阶段路线图
第一阶段:MVP(2-4周)
目标:跑通基础RAG,验证可行性
技术栈:
- • 向量检索:LlamaIndex VectorStoreIndex
- • 关键词检索:BM25
- • 时效性过滤:文件日期
- • 简单合并排序
交付物:能用的问答原型
第二阶段:优化(4-8周)
目标:提升准确率,加入高级能力
新增:
- • 实体识别(评分标准、技术要求)
- • 简单图谱(文档-评分项-案例)
- • 点击反馈学习
- • 基于用户历史的个性化
关键动作:建立评测体系,数据驱动迭代
第三阶段:进阶(可选)
目标:达到生产级水平
新增:
- • 完整知识图谱(项目-标段-评分规则-中标方案)
- • 多跳推理(类似项目的中标策略)
- • 自动更新图谱
前提:有足够的数据和工程资源
5.3 技术栈推荐
| 层级 | 推荐方案 | 备选 |
|---|---|---|
| 检索框架 | LlamaIndex | - |
| 向量库 | Milvus / Qdrant | pgvector |
| 文档解析 | LlamaParse | MinerU |
| 图谱(可选) | Neo4j | - |
| 评测 | LlamaIndex内置 | Ragas |
LLM选型不列了。原则很简单:先用最强的模型(GPT/Claude/Gemini)把效果调到位,再考虑换便宜模型降成本。别一开始就用小模型省钱,效果差了你都不知道是模型问题还是RAG问题。
5.4 常见坑
| 坑 | 说明 | 避坑方法 |
|---|---|---|
| 一上来就建知识图谱 | 过度设计,投入产出不划算 | MVP先验证基础RAG |
| 只用向量数据库 | 精度不够,无法精确匹配 | 混合检索(BM25+向量) |
| 自己造轮子 | 浪费时间重复发明 | 用LlamaIndex |
| 不做评测就上线 | 不知道效果好不好 | 先建评测体系 |
| 忽视解析质量 | 垃圾进,垃圾出 | 先看解析,再调检索 |
5.5 几句大实话
-
- 解析是地基——效果不好先查解析,别急着换架构
-
- 没有银弹——不同文档用不同工具,别指望一招鲜吃遍天
-
- 先跑起来再说——从简单方案开始做起,完美主义是RAG项目最大的敌人
-
- 评测比优化重要——没有评测体系,你根本不知道改对了没
写在最后
写完这篇,我最大的感受是:RAG没有银弹。
市面上太多文章在推销某个框架、某个架构、某个神奇的技术,好像用了就能解决所有问题。但现实是,RAG的效果取决于一系列琐碎的决策:文档怎么解析、怎么切块、用什么向量模型、检索策略怎么配、重排序要不要加……每个环节都可能出问题。
如果非要总结几个最重要的认知:
-
- 解析是门槛——做不好是0分,做好了是60分及格线
-
- 检索是天花板——从60到90全靠这里,但调优是玄学
-
- 评测是指南针——没有评测体系,优化就是碰运气
还有很多我没想清楚的问题,比如:
- • 评测体系怎么建才能真正反映业务效果,而不是自嗨?
- • 多模态RAG在实际场景中的ROI到底怎么样?
- • Agentic RAG的可控性问题怎么解决?
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









