



‘’
AI系统好不好用的核心,从来不是你写了什么提示词,而是AI知道了什么。
RAG、微调、数据工程…
AI圈新词一直很多,更新又快,搞得很多人懵懵懂懂,一头雾水。
最近很火的词,上下文工程是什么?
怎么利用上下文技术的把AI应用的用户体验做到更好? 今天一文带你了解上下文技术的全貌。
2、LLM的基本原理
首先我们需要理解一下LLMs,或者AI的本质。
简单来说,LLMs其实就是一个概率模型。它通过分析海量文本,学习词与词、句与句之间的统计关系,从而在给定上下文的情况下,预测下一个最可能出现的词。比如当我输入“我今天想吃”的时候,LLMs就可以根据概率计算出来,后面可能是“苹果”、”蛋糕“之类的词语,而不太可能是”自行车“。
LLMs概率模型准不准呢?主要来自于他所学习的数据集。比如我用某度贴吧的语料库,训练出来的很可能是一堆暴躁老哥,但如果我用论文数据集,训练出来的就可能是一堆相对严格的科学家。

AI圈子里就有句老话,叫 garbage in ,garbage out 。LLM模型的本质可以理解成一个函数:
输入信息 → LLMs → 输出信息
你输入的数据质量不行,AI就很难给你理想的输出作为结果。
想要Ai应用好用,我们就得保证输入数据的质量。
3、上下文是如何影响大模型的
回到开篇的观点:
“AI好不好用的核心,其实从来不是你写了什么提示词,而是AI知道了什么。"
这个知道了什么,本质上就是Context,上下文。
为什么呢?首先我们要理解人类和AI的差异。当我们和人类聊天的时候,我说:
有点馋了,明天我们去吃饭火锅吧。
人类只记住了两个词:明天,火锅。
机器记住的则是一串长长的token,再对Token的每一个词的权重进行标记,最终存到内存里面。
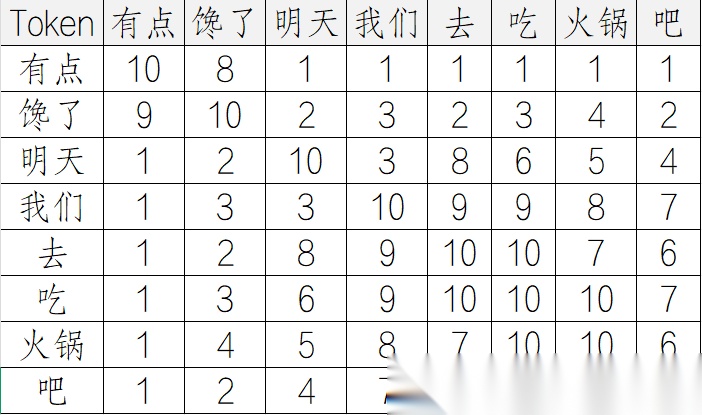
机器是如何理解这句话的 - Attention Map
人类是基于语义和常识进行抽象理解,而机器则是通过 Token 间的注意力权重计算来建立关联,这种差异决定了上下文对 AI 理解的关键作用。
我们做项目时候用到的各种工具、技术,无论是提示词、RAG、微调等,其实都是为了解决这样一个核心的问题:让AI明确的知道你想做到的是什么。这包括了用户在文中表达的明确的意图,也包括更广泛、更隐形的知识,比如背景、目的、意图、没说出口的潜台词等。
以AI会议助理场景为例:
‘’
AI 助手收到一封邮件:
“明天有没有时间同步一下工作进度?”
传统的Agent客服会回复:
‘’
“收到。我明天有时间,请问您希望具体几点?”
一个中规中矩的回复,回复没什么信息量,稳定但平庸。
”Agent的本质是由丰富的上下文内容驱动的函数。用户输入信息的主要意义是“为大模型完成目标所需的信息做准备”。“
那么升级下思路,我们可以怎么做?
在调用大模型之前,系统可以自动查询上下文、调用以下信息:
- 你的日历信息(显示你全天已满)
- 你与对方过去的邮件往来(判断应使用轻松随意的语气)
- 联系人列表(识别出此人是关键合作伙伴)
- 可用工具(如
send_invite或send_email)
有了这些信息后,Agent就能生成自然、精准且主动的回复:
‘’
“王总!我明天全天排满了,一直开到下班。周四上午我有空,您看行吗? 我已经发了个会议邀请,看看时间是否合适。”
请注意!我们并没有对模型进行任何微调,也没有改变提示词的其他部分!
所以如今的Agent到底好不好用,不是因为更高级的模型或更巧妙的算法,仅仅因为为特定任务提供恰到好处的上下文。
这就是为什么Context Engineering如此重要。
4、回顾提示词工程
那我们怎么在我们的AI工程中使用提示词技术与上下文技术呢?
先回顾一下提示词工程,这个大家都很熟悉:
- 角色赋予
告诉模型“你是谁”。例如:
‘’
“你是一位资深 Python 开发者,正在审查代码中的安全漏洞。”
这个角色设定会产生完全不同于普通请求的结果。模型会自动采用该角色的专业知识、术语体系和关注重点。
- 少样本示例(One-Shot Example)
即身教胜于言传。提供 2~3 个输入/输出样例,帮助模型理解你期望的格式、风格或结构。
比如,如果你想要特定字段名的 JSON 输出,那就直接展示字段。
- 思维链
在强化学习训练出推理模型之前,这是一种非常流行的技巧。
通过添加:
‘’
“让我们一步一步思考。” 或 “请解释你的推理过程。”
迫使模型展示中间步骤,避免跳步得出错误结论。这对复杂逻辑任务尤其有效。
- 约束
明确划定边界。例如:
‘’
“请将回复限制在100字以内。” “只能使用上述信息作答。”
这类约束能防止模型跑题或编造内容。
5、上下文工程
如果把提示词工程比喻成是描述问题,那上下文工程就是给Agent 搭建舞台:上下文工程为智能体打造一个完整的上下文运行环境。
25年6月末,《The New Skill in AI is Not Prompting, It’s Context Engineering》文章对上下文做出定义:
简单来说:
‘’
上下文工程是一门设计和构建动态系统的学科,旨在以正确的格式、在正确的时间,向大语言模型提供完成任务所需的所有信息与工具。
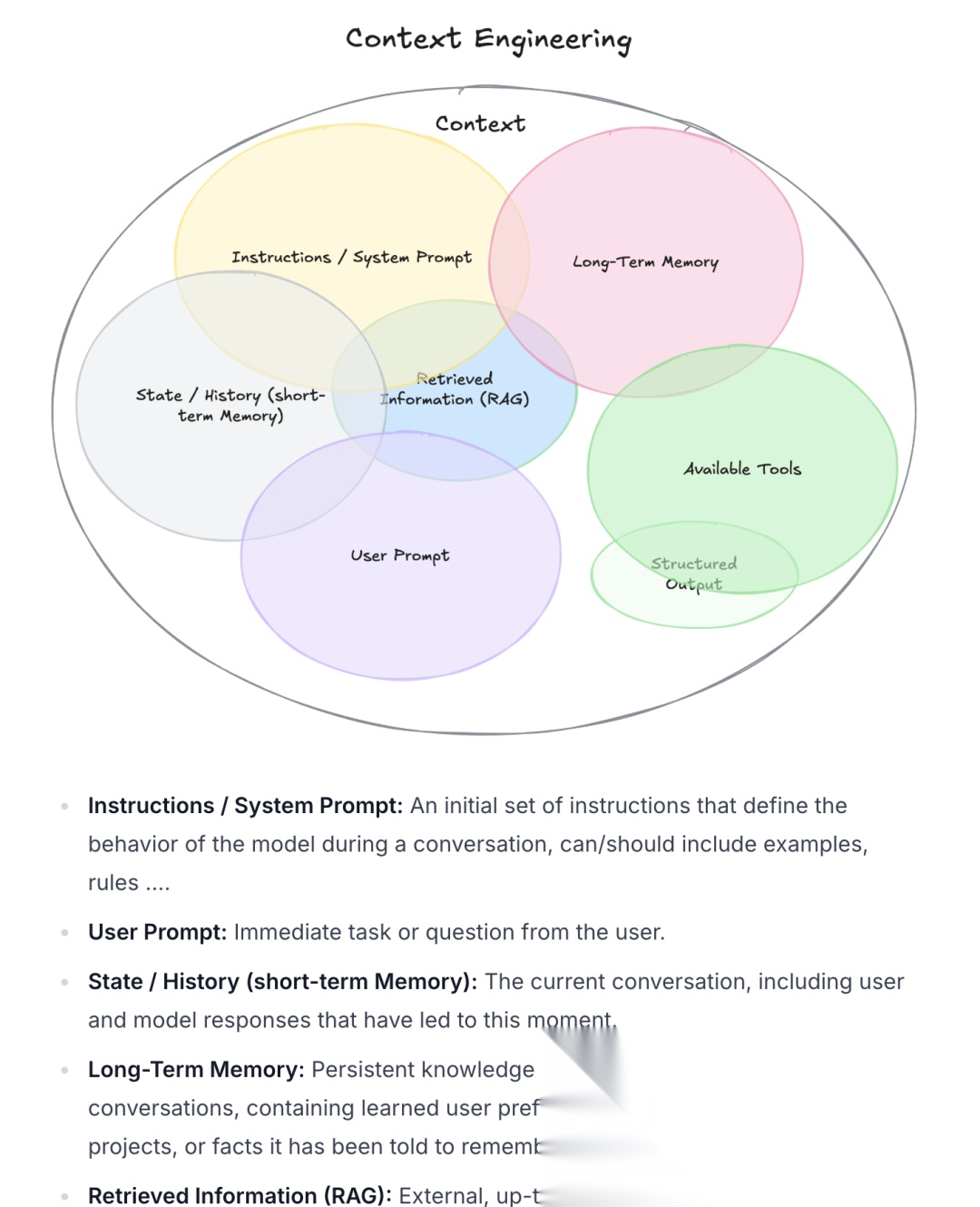
Context有7个关键指标:
说明/系统提示、用户提示、短期记忆(状态/历史)、长期记忆、检索信息 (RAG)、工具调用、结构化输出。
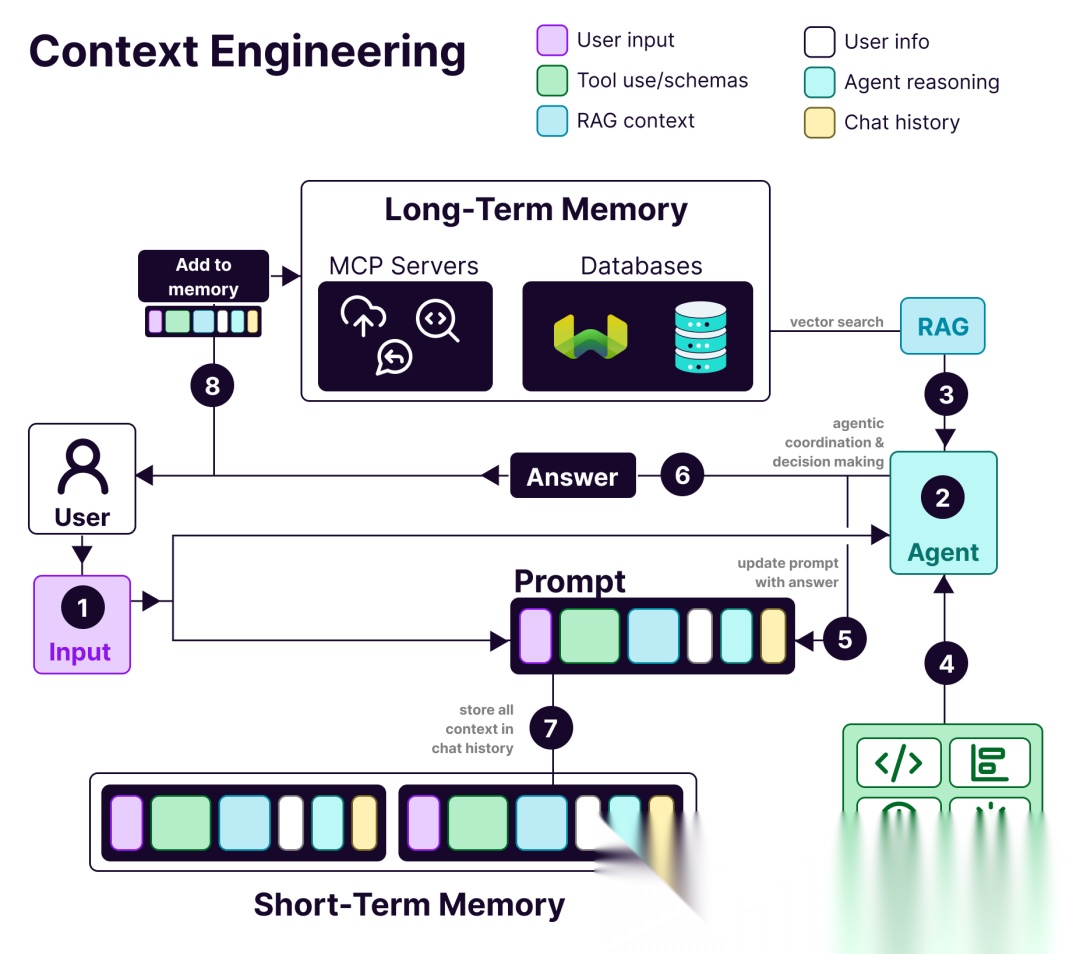
具体来说,其包括以下几个核心组件:
1. 记忆管理
智能体需要记住过去的信息,分为两种:
- 短期记忆:如对话摘要,用于在有限的上下文窗口内保留关键历史。
- 长期记忆:通常借助向量数据库实现,存储用户偏好、过往行程、行为模式等。
2. 状态管理
在一个多步骤任务中,我们需要知道:
“当前进行到哪一步了?”
比如,当 Agent 正在为我安排整个行程时,我想了解:
- 飞机订好了吗?
- 到达时间是多少?以便安排接机。
- 酒店是否已确认?
状态管理确保智能体不会在任务中途“失忆”或重复操作。
3. RAG
这个大家都熟,RAG就是动态知识的来源。RAG 使用混合搜索技术(语义 + 关键词匹配),根据当前上下文精准提取信息。
RAG相当于一个外挂数据库,协助系统精确检索数据,并且可以降低Token的消耗。
4. Tools
LLM 无法对真实世界进行操作。比如:查数据库、调 API、运行代码。
而工具(Tools)恰好可以解决这些问题。
例如:
- 查询 SQL 数据库
- 获取实时房价数据
- 自动部署云服务器
其中包括MCP、Function Calling 等技术。
上下文工程在Tools的调用中,需要:
‘’
设计清晰的工具接口描述,指导 LLM 正确选择和使用工具。
工具描述应包括:
- 功能说明
- 触发条件
- 使用限制
5. 动态提示词
别忘了——提示词工程也是上下文工程的一部分!
你可以从一个基础 prompt 出发,比如:
‘’
“分析安全日志中的异常行为。”
然后在运行时,动态注入以下上下文信息:
- 最近的告警事件
- 已知的误报列表
- 用户权限变更记录
这些变量来自:
- 状态管理
- 记忆系统
- RAG 检索结果
最终形成的 prompt 可能是:
- 80% 来自动态上下文
- 20% 来自静态指令
这才是真正智能化的提示构造方式。

6、结语
要让AI系统真的好用,我们必须从写出一个好Prompt的阶段,转向系统级的上下文工程设计。
套用 IBM Martin Keen 的话:
‘’
Prompt engineering … it gives you better questions.
Context engineering — that gives you better systems
个人简单总结Context Engineering,就一句话:
在正确的时间,以正确的格式,提供正确的信息和工具。
这其实是一个非常系统性、非常综合的要求,需要产品负责人深入的理解企业的的业务场景,明确用户所期望的输出,明确工程的SOP,了解每个环节AI和系统的边界,并结构化地组织所有必要信息。只有这样,大语言模型才能真正的“完成任务”。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









