




LlamaIndex是一个专为构建大模型RAG应用开发的数据框架。
基于这个框架,我们可以加载文档和网页,优化对其中非结构化数据的处理,使用文本转换高级提取管道,从而构建企业级知识库;然后,采用BM25检索和向量检索实现混合检索方法,获取准确有用的信息,发送给大模型生成回答,并实现类ChatGPT的流式输出。
以上,是《大模型RAG实战》系列文章已经涵盖的主题。
现在,我们要构建一个生产级的大模型RAG应用,不但要掌握这些高级技术,还要对应用的架构有所了解。
本文以ThinkRAG项目为实例,基于LlamaIndex框架,介绍大模型应用的架构设计。
先上图。
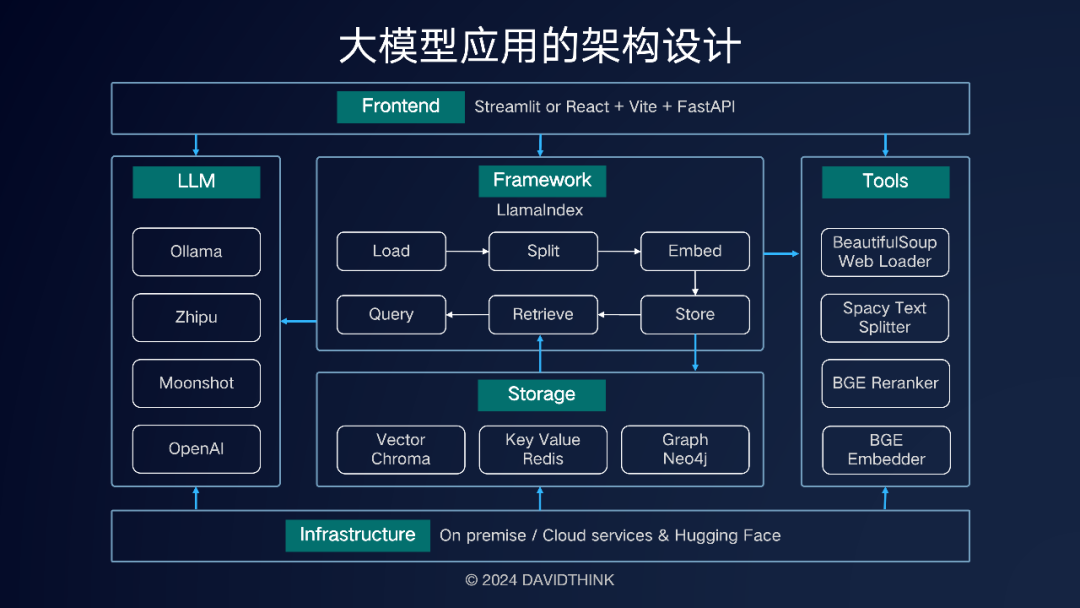
在这张架构图中,我把大模型应用涉及的组件分为6类,分别是:
- 框架(Framework)
- 大语言模型(LLM)
- 存储(Storage)
- 工具(Tools)
- 基础设施(Infrastructure)
- 前端(Frontend)
下面,介绍每一类组件包含的内容。
1. 框架(Framework)
采用Langchain或LlamaIndex这样的框架,让构建大模型应用变得简单.以至于用10行代码,就可以实现一个可演示的系统。
这个系统能支持从加载(Load)、文本分割(Split)、嵌入(Embed)、保存到向量数据库(Store)、检索(Retriever),实现查询(Query)和对话(Chat)的整个过程。
同时,系统还对接和调用各种大语言模型(LLM)与工具(Tools),适配各种数据存储(Storage)。
此外,LlamaIndex框架还支持一些高级功能,如工作流(Workflow)、智能体(Agent)、评估(Evaluation)和微调(Fine-Tuning),以及多模态(Multi-Modal),功能非常全面和强大。
不过,采用框架,对于复杂场景下的企业级应用不一定是最佳选择。过度的抽象,会导致缺乏灵活性并带来性能的损失。
因此,当应用系统开发的初期,我们可以基于框架加速开发和部署,把开发重心放在更关键的功能特性上。
未来,我们可基于框架进行深度定制,或抛弃框架直接优化相关功能。
2. 大语言模型(LLM)
在应用中使用大模型,通常有两种方式。
一种方式是通过Ollama等工具,将模型下载到本地部署运行,例如GLM、Llama、Gemma等模型。
但是运行这些本地模型,需要算力支持。尽管glm4:9b这样尺寸的模型,可以在个人电脑上运行,但是性能和效果都欠佳。如有算力资源,建议在AI服务器上下载和使用百亿级参数的模型。
另一种方式是调用大模型厂商的线上API服务,如OpenAI或国内的智谱(Zhipu)、月之暗面(Moonshot)、深度求索(DeepSeek)提供的大模型服务。
这种方式的优点是性能好、响应快。但是,大量使用消耗token会导致成本较高。而且,如果系统处于隔离的内网环境,也无法使用外部服务。
3. 存储(Storage)
一个完整的应用系统需要存储各种数据,包括对话记录、向量数据、文本数据、配置信息等等。系统需要对接各种类型的数据库。
其中最关键的是向量数据库,用来存储嵌入后向量数据、处理后的文本(Document & Text Node)数据和索引(Index)数据。
如果在个人电脑上使用ThinkRAG,那么嵌入式的向量数据库如Chroma和LanceDB,是比较好的选择。若要在服务器上部署,则可以选择Milvus、Elasticseach等作为向量数据库。
在ThinkRAG中,我们不但使用了Chroma作为向量数据库,也使用了Redis作为单独的文档存储(Doc Store)和索引存储(Index Store),以便于管理知识库。
这里,我们也可以使用MongoDB替代Redis。这两者,在LlamaIndex中都可以适用于键值(Key Value)数据库的场合。
由于已经安装了Redis,我们在ThinkRAG中,还继续使用Redis作为文本提取高级管道的缓存(Ingestion Cache),存储对话记录(Chat Store)。
最后,系统还有各种配置信息的存储。此类数据量不大,我们采用LlamaIndex提供的简单键值存储(SimpleKVStore),并通过一个本地文件(config_store.json)持久化。
这样,如果在笔记本电脑上部署并以生产模式运行ThinkRAG,我们只需要额外安装一个Redis服务。
更为简单的是,如果以开发模式运行,那么所有数据都以文件的形式在本地存储,不需要额外安装任何数据库。
4. 工具(Tools)
一个生产级系统,需要引入多个工具。在架构图中我列举了一些,比如:文本分割的工具,ThinkRAG用的是对中文更合适的Spacy Text Splitter。
再者,对网页信息的抓取,ThinkRAG基于BeautifulSoup实现。我们也可以使用Jina提供的Reader服务,可以抓取和处理网页信息,并输出为Markdown格式,缺点是响应有点慢。
更为关键的工具,是嵌入模型和重排模型,推荐使用北京智源人工智能研究院(BAAI)开发的BGE系列模型,实用效果很好。你也可以选用HuggingFace上的其他模型。
这些模型都可以从HuggingFace下载和使用,ThinkRAG内置了相应的国内镜像网址。
此外,该类别下还有更多的工具,目前ThinkRAG还没有涉及,尤其是与智能体和外部服务调用相关的工具。
5. 基础设施(Infrastructure)
基础设施包含的内容,取决于你的部署和运行环境。
如果在笔记本电脑上运行ThinkRAG应用,那么对CPU和内存会有要求。未来,AI PC普及之后,将对系统提供更好的支撑。
如果使用到外部的模型,你需要能够访问和下载这些模型,例如前面提到的HuggingFace。你也可以使用托管在云端的数据库服务,包括Milvus、Redis、MongoDB、Elasticsearch等等。
进一步,当使用的模型需要进行微调训练,那么还需要提供相应的算力资源、PyTorch等深度学习框架与运行环境。
6. 前端(Frontend)
构建大数据或AI应用的前端工具,有Streamlit、Chainlit、Gradio等。
ThinkRAG选用的是Streamlit。它基于Python,提供了很多简单易用的数据可视化工具,也有一定的可扩展性。
这使得我们不需要前端开发经验,就可以快速构建和演示一个AI应用,也让我们可以把时间精力聚焦于AI本身。
基于Streamlit实现的ThinkRAG前端页面展示如下:
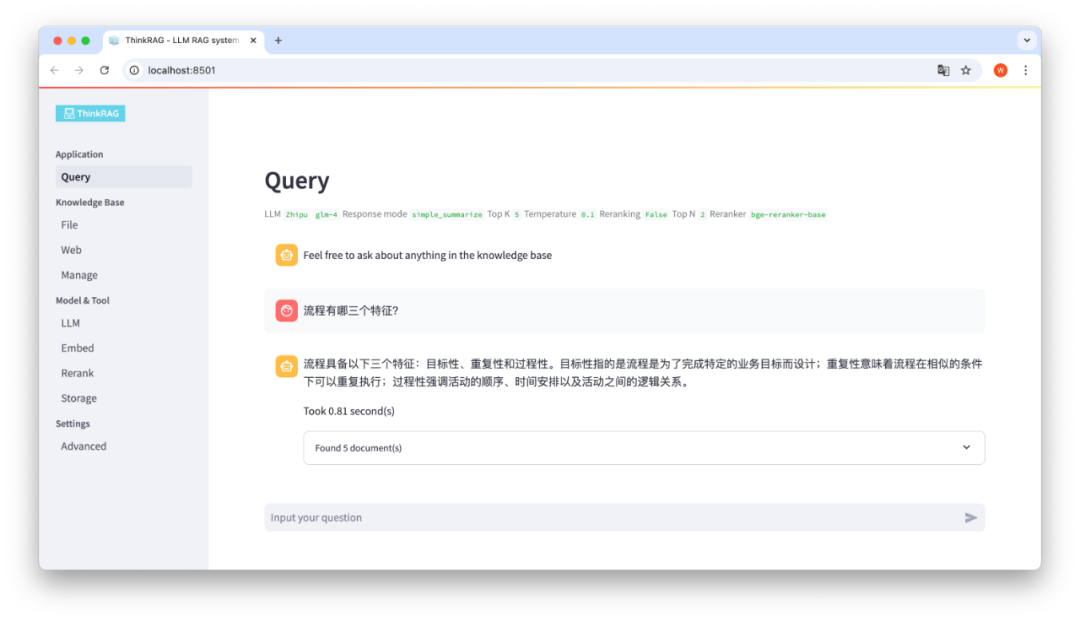
不过,如果要打造一个更美观、更好用、令用户喜爱的产品,Streamlit是远远不能满足需求的。
这时,我们可以基于React前端框架,重构前端应用,并通过FastAPI封装后端服务,形成前后端分离的架构。同时,我们还要对后端服务进行优化,以支持多用户、并发、大数据量的场景。
再进一步,我们可以基于Electron,将应用打包成可下载安装的应用软件,而非启动后端服务后在浏览器中打开。这里可以参考开源项目AnythingLLM的技术栈。
结语
最后要说明的是,ThinkRAG的定位,是可在笔记本电脑上运行的本地知识库大模型RAG应用。
因此,在上文所述的架构中,ThinkRAG对于各种组件和技术的运用有所取舍。
如果要提供企业级服务、处理海量的数据,那么可以同样按照这个架构,选用合适的组件,对前后端进行重构与优化,将能满足需求。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】【开源项目代码和文档扫取获得】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









