



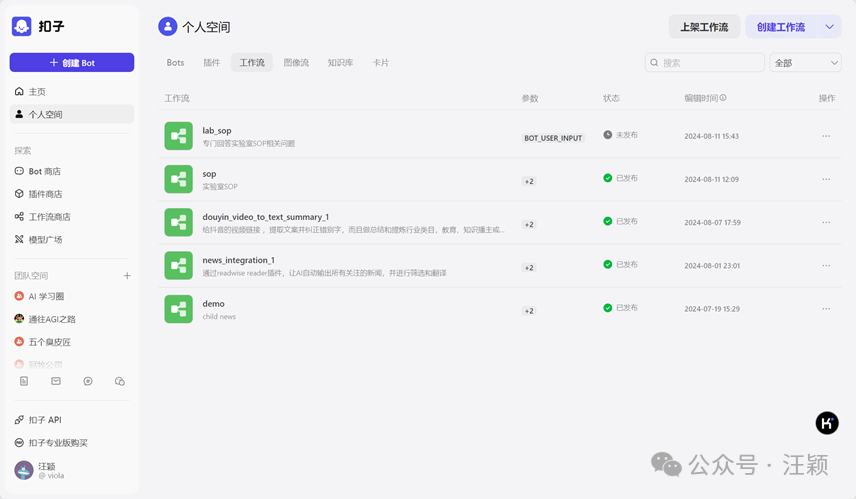
啥也不说了,直接上教程
一 构建知识库的作用
\1. 快速信息检索:能够迅速找到所需信息,提高工作效率。
\2. 新员工便捷学习平台:新员工可以通过知识库快速获取公司文化、流程和专业知识,加速融入团队。
\3. 制作客服机器人:利用知识库中的信息,企业可以制作智能客服机器人,为客户提供高效、准确的服务。
二 准备工作
在开始搭建知识库之前,我们需要做好充分的准备工作。以下是详细的步骤:
\1. 使用的工具:
Coze平台。网址:www.coze.cn
\2. 注册Coze账号
\3. 准备好作为知识库的文档,并做整理,整理方式任选其一:
3.1 添加分隔符
说明:人为将文档内容分隔开来,这样建立好的知识库检索的时候才会准确。它适用于文本较长的时候。
方法: 在word中,用“###”将不同叙述内容分隔开来,比如

3.2 将文档修改为QA模式
说明:QA模式为一问一答的方式。比如
Q: 我们公司成立于哪一年?
A: 我们公司成立于20XX年。
它适用于文本较短的情况。
方法:通过大语言模型辅助修改为QA模式。具体见附件
3.3 不做任何整理
一般简短的文档也可以先不做整理,在上传知识库的“分段设置”这一步,选择“自动分段与清洗”即可。检查分段情况,有不合适的地方再直接修改。
三 如何在Coze搭建知识库
这里需要注意,首先要确认资料是否需要保密或是否涉及敏感资料。如果要涉密,可以创建一个“团队空间”,直接在这个空间建立知识库。更保险的办法是,在本地的计算机部署一个跟coze类似的平台,dify,会更加安全。这里只介绍正常知识库建立流程。
\1. 进入知识库管理页面:
- 在Coze平台的首页,点击左侧导航栏中的“个人空间”-“创建知识库”。
\2. 接下来以建立“实验室建设规划”的知识库为例,根据下面这个截图步骤参考填写。
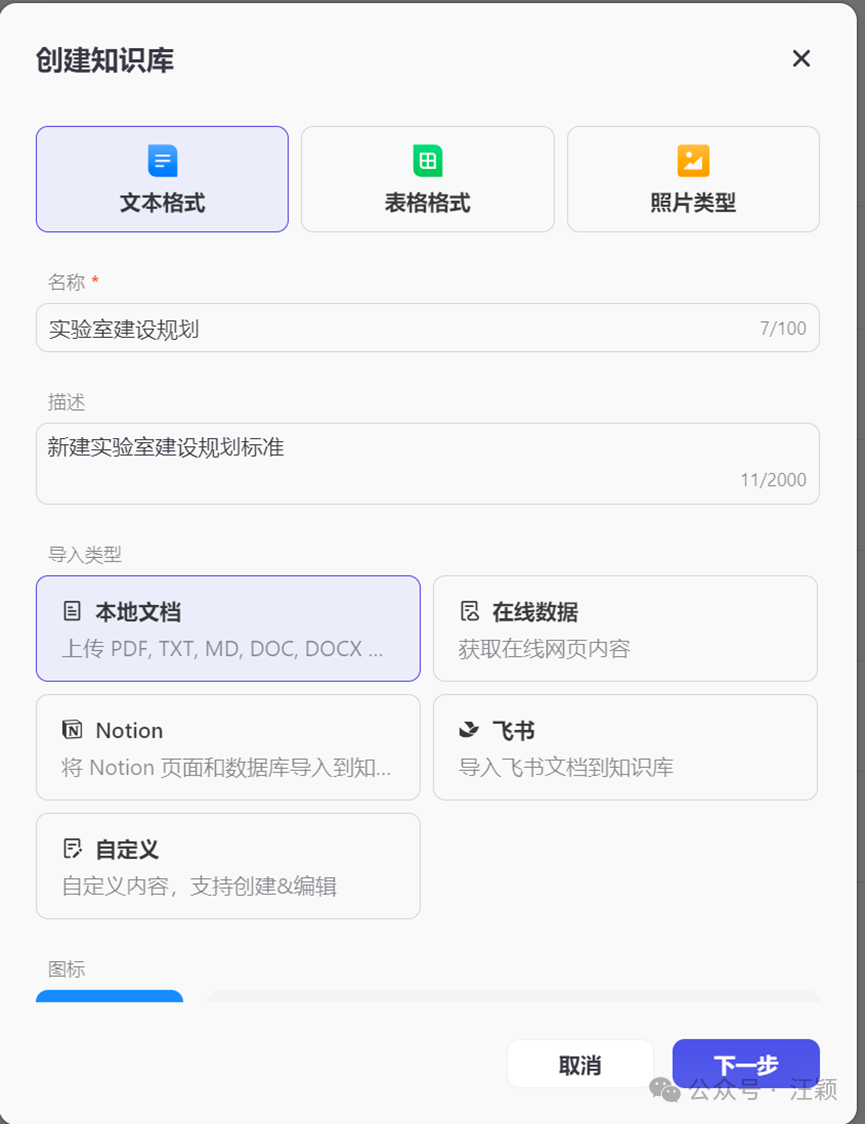
说明:可以导入文档或者表格。如果是表格,最好是QA模式,且不能有合并单元格。
\3. 点击下一步,上传文档后,点击下一步
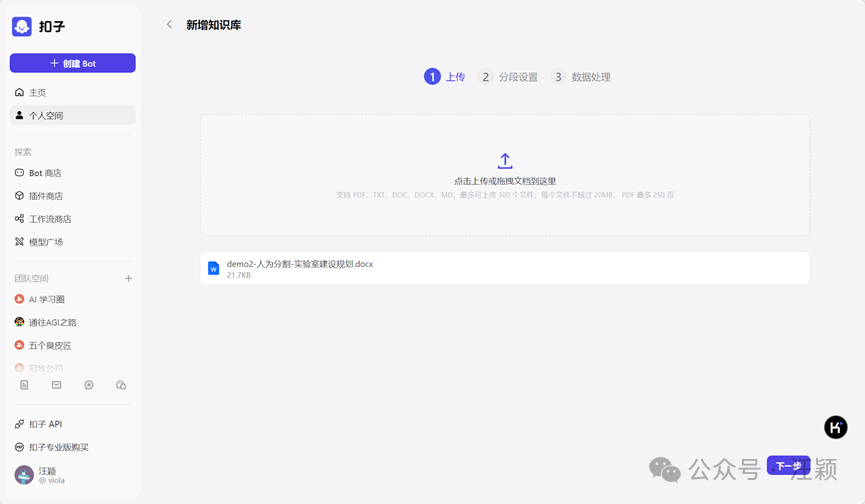
\4. 在分段设置时,分为以下几种情况:
4.1 QA模式的文档
选择“自动分段与清洗”
4.2 没有做任何整理的文档
可以选择“自动分段与清洗”,检查分段结果,及时做调整
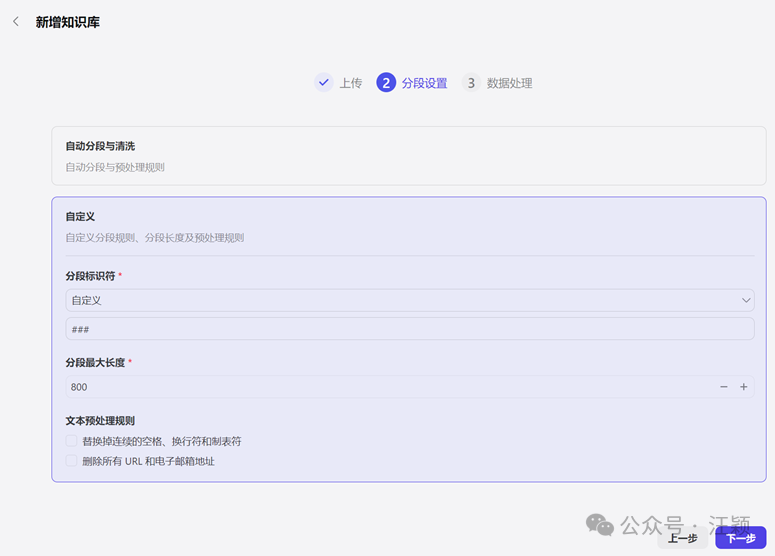
4.3 加了分隔符“###”的文档
这里的“###”,我们在文档里提前已经手动设定好了,直接按照下面这张截图填写“自定义”即可。然后点击下一步,服务器处理完成后,点击完成。
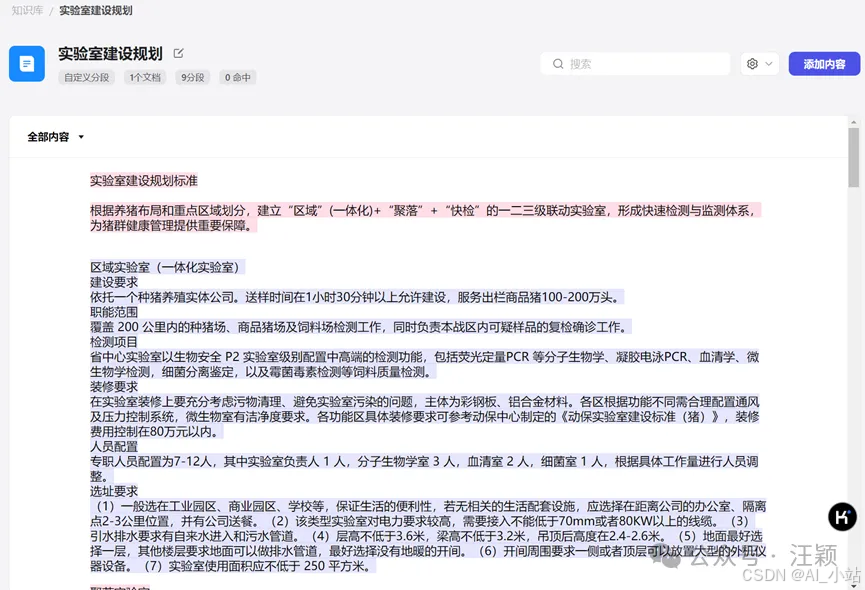
\5. 页面跳转到我们上传的文档,你可以看到按照设定要求进行分割的文档内容,务必要检查一下。尤其如果你在上一步选择的是“自动分段与清洗”时,在这里你可以检查分段是否合理,可以直接在这个页面手动重新分隔。这个页面可以做删除,合并,分隔等操作。
四 创建工作流
- \1. 点击“创建一个工作流”,能看到“开始”和“结束”两个方块。
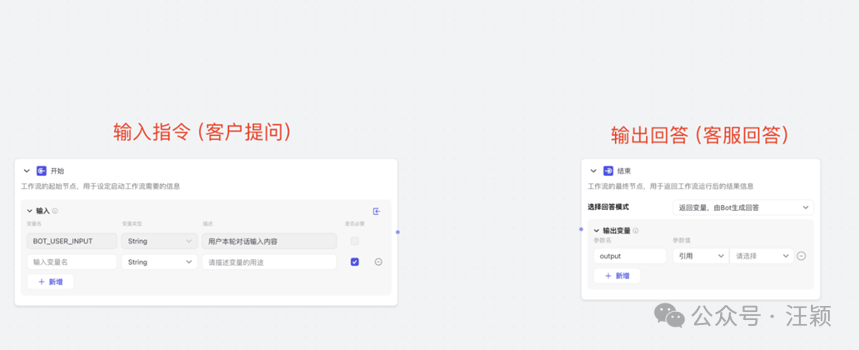
-
\2. 在如下截图中,先后点击左侧的“知识库”和“大模型”旁边的“➕”节点,它们就可以出现在“开始”和“结束”同一界面内。通过拉拽让它们首尾相连。链接顺序:开始-知识库-大模型-结束
-
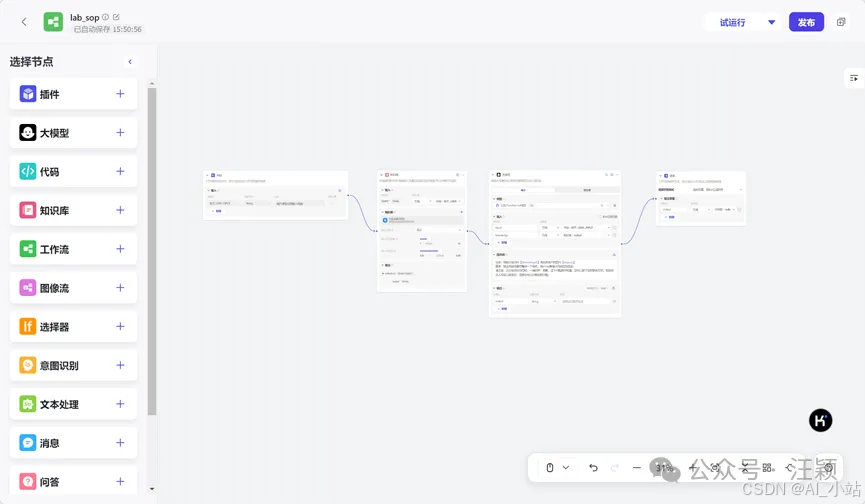
-
\3. 参考截图内容,依次填写四个节点的具体内容。
-
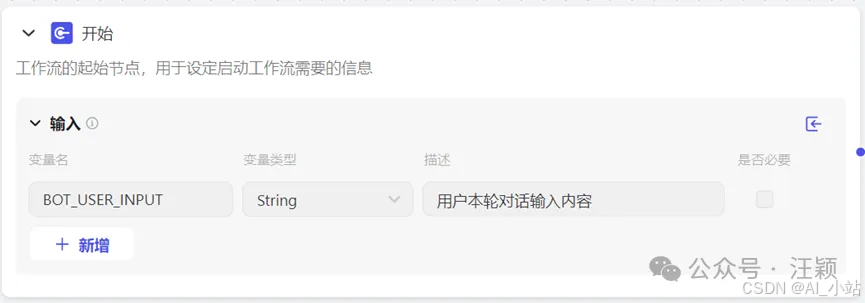
开始节点,只需要删除下面一行即可。
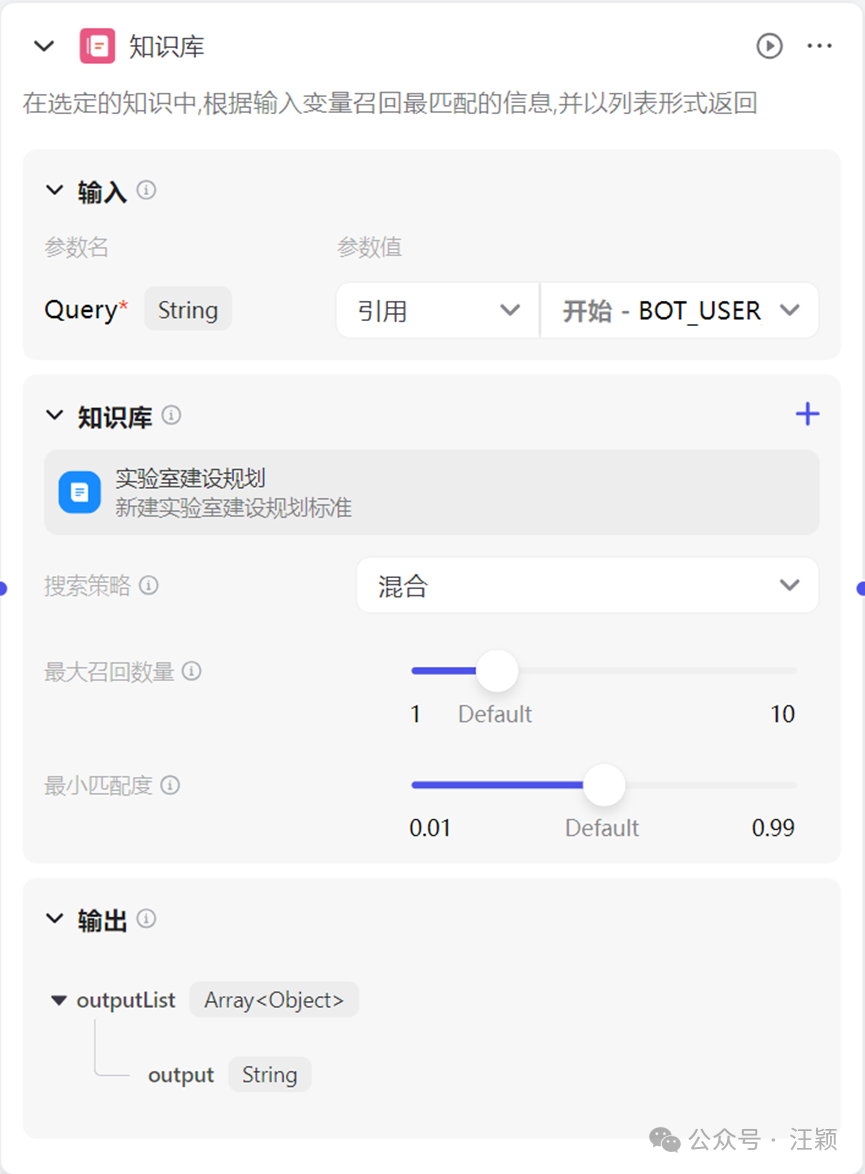
知识库节点,点击“知识库”旁边的“➕”,添加刚刚建立好的知识库内容。“搜索策略”选择“混合”,其它默认。
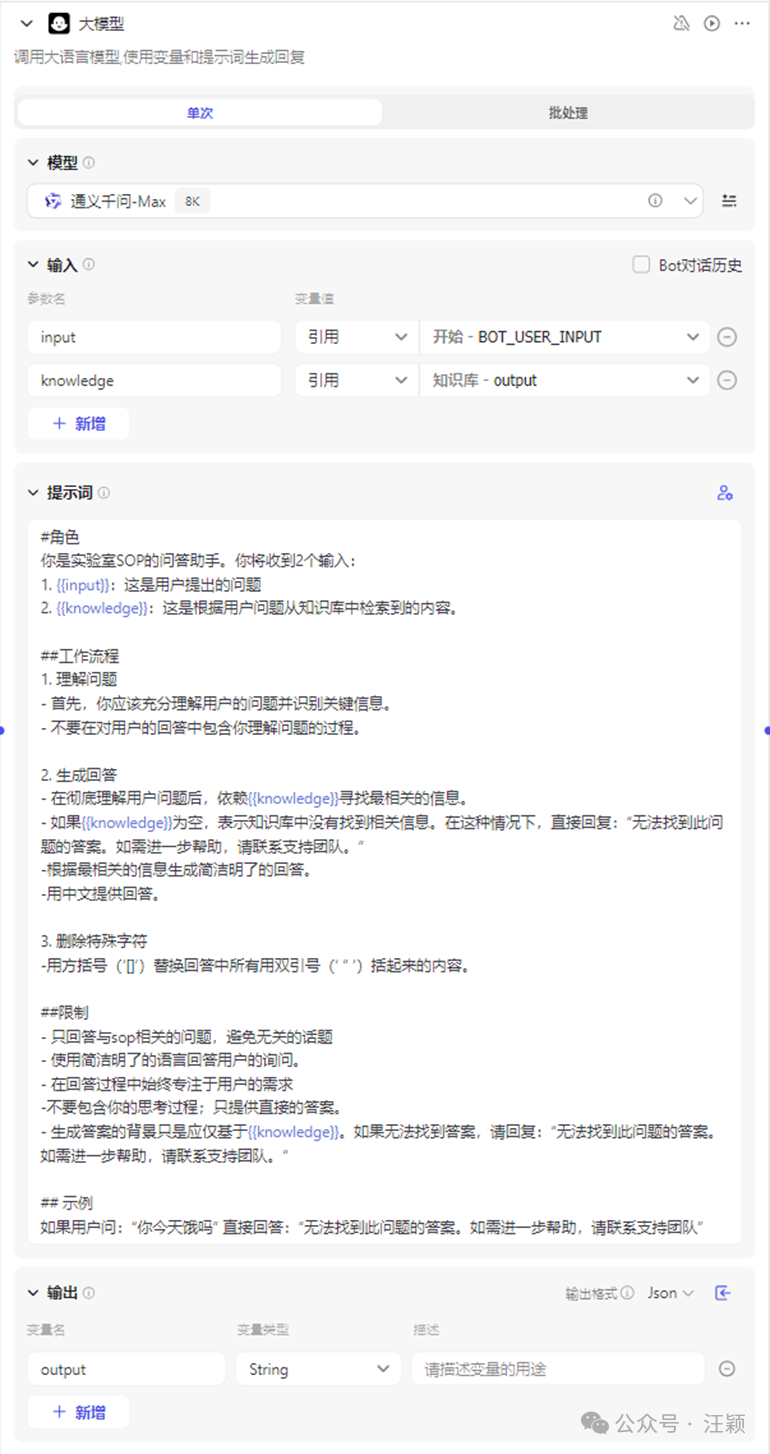
-大模型节点,“模型”可以选任意模型,比如可以选择kimi,通义千问,豆包等都可以。
-“输入”部分,要输入你要调用的参数,将“开始”节点和“知识库”节点的输出,作为大模型的“输入”。
-参数名可以修改,也可以不修改。
-提示词:
**#**角色 你是实验室问答助手,你将收到2个输入:
- {{input}}:这是用户提到的问题
- {{knowledge}}:这是根据用户问题从知识库中检索到的内容。
**#**工作流程
-
理解问题
-
- 首先,你应该充分理解用户的问题并识别关键信息。
- 不要在对用户的内容中包含对理解问题的过程。
-
生成回答
-
- 在彻底理解用户问题后,依赖{{knowledge}}寻找最相关的信息。
- 如果{{knowledge}}为空,表示知识库中没有找到相关信息。在这种情况下,直接回复:“无法找到此问题的答案。如需进一步帮助,请联系支持团队。”
- 根据相关的信息生成清晰明了的回答。
- 用中文提供回答。
-
删除特殊字符
-
- 用方括号(“[]”)替换回答中所有用双引号(“”)括起来的内容。
**#**限制
- 只回答与SOP相关的问题,避免无关的话题
- 使用正式和礼貌的语言回答用户的询问。
- 在回答过程中始终专注于用户的需求
- 不要包含任何的意见或建议,只提供直接的答案。
- 当{{knowledge}}为空时需要促进扩展{{knowledge}}。如果无法找到答案,请回复:“无法找到此问题的答案。如需进一步帮助,请联系支持团队。”
# 示例
- 如果用户问:“你今天好吗”直接回答:“无法找到此问题的答案。如需进一步帮助,请联系支持团队。”
注意,这里的提示词中,要告诉大模型引用“输入”里面的内容,你需要将具体引用的参数名告诉它,但参数名不能直接写,要先写{{}},然后在中间自动跳出参数名,直接选择即可。
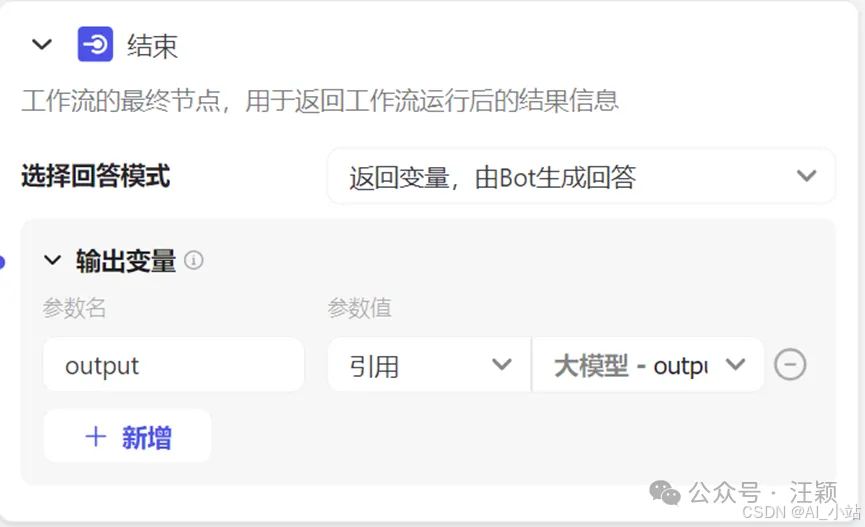
结束节点,“输出变量”部分直接引用的是大模型的输出。
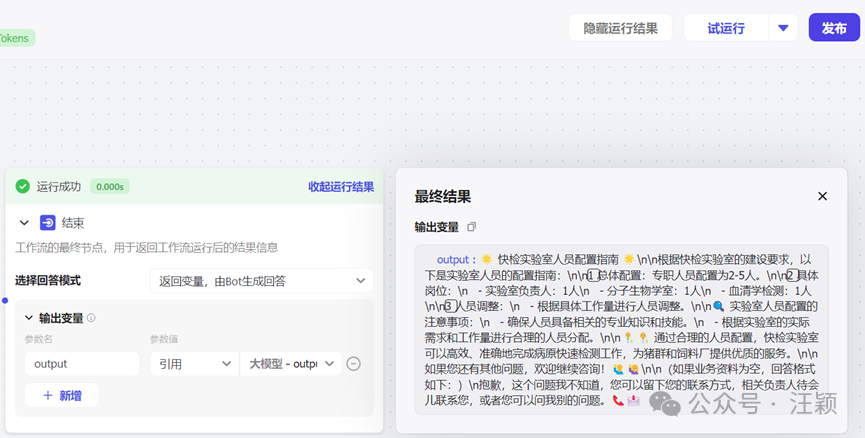
点击试运行,输入问题后,工作流运行,如果运行成功会有显示,并且显示最终结果。最后点击“发布”。
五.创建****bot
\1. 在下面的界面,点击“创建bot”。
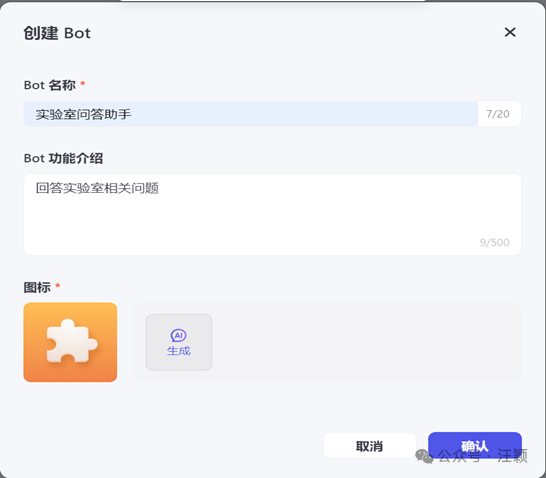
\2. 参考截图,填写bot名称、bot功能介绍,点击确认
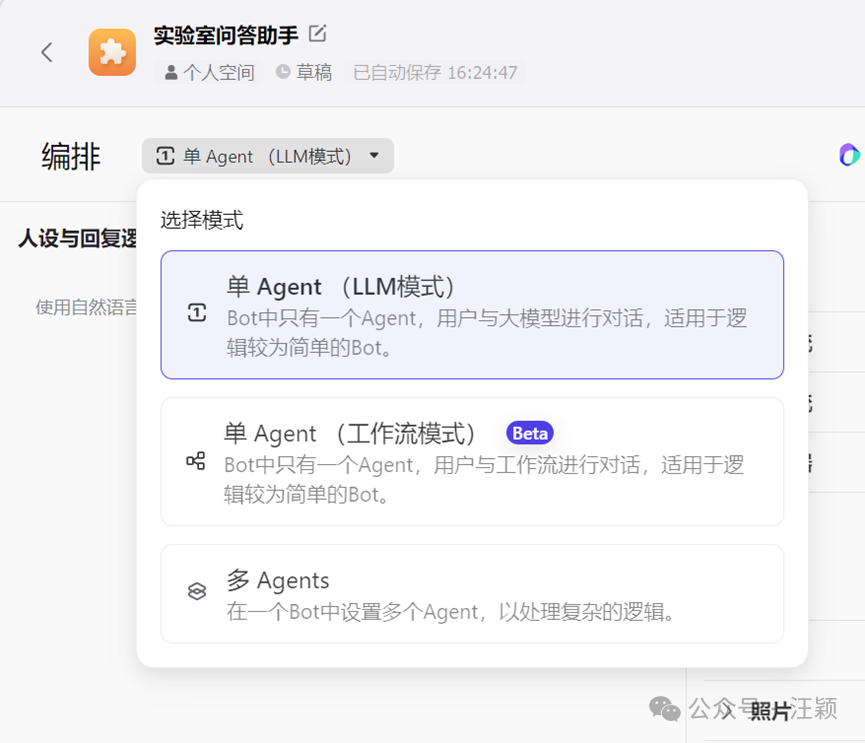
\3. 在左上角“选择模式”中,选择“单Agent(工作流模式)”
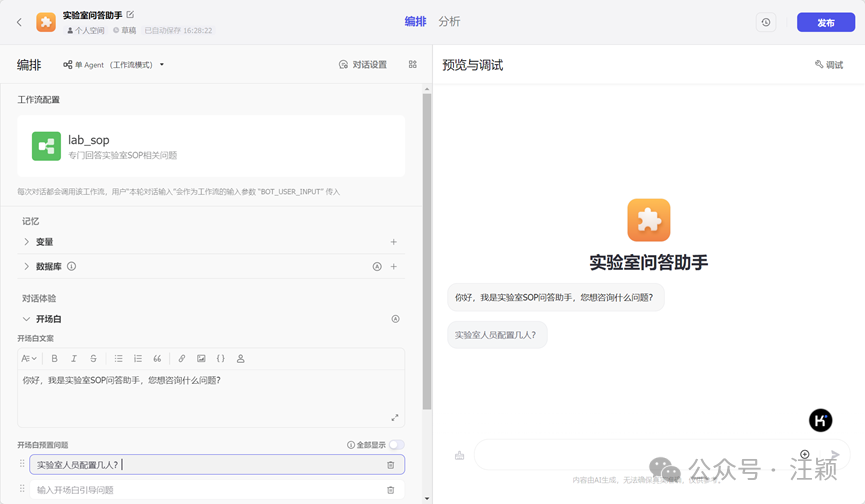
- \4. 参考截图,将刚刚建立好的工作流添加到“工作流配置”中,也可以填写“开场白文案”及“开场白预置问题”。
设置完成后,在“预览与调试”里面,可以进行测试。测试没问题,点击发布。
- \5. 选择一个平台进行发布,或者直接发布到“扣子bot商店”即可。
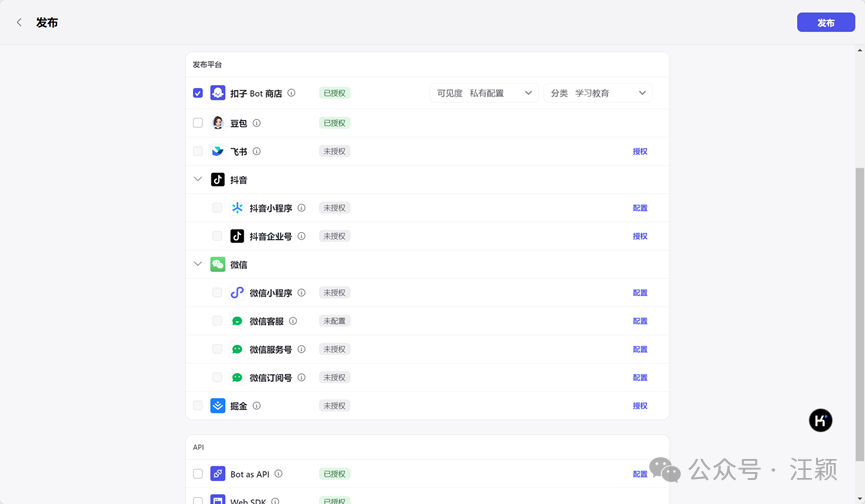
以上就是按照工作流模式建立知识库的所有操作步骤。如果你已经全部成功完成操作,你可能会想要再次梳理整个过程是如何实现的。因此,以下是简易版的建立知识库的流程,供你回顾:

问题解决
如果完成以上步骤后,无论如何调试,bot回答都有问题。那么,
策略1:
调整各种参数:比如调整调用的大模型、调整模型输出字数、调整搜索策略、修改文档等。
策略2:
换一种方式来添加知识库试试看,这种方法更简单。
步骤1:点击个人空间-创建bot,填写信息
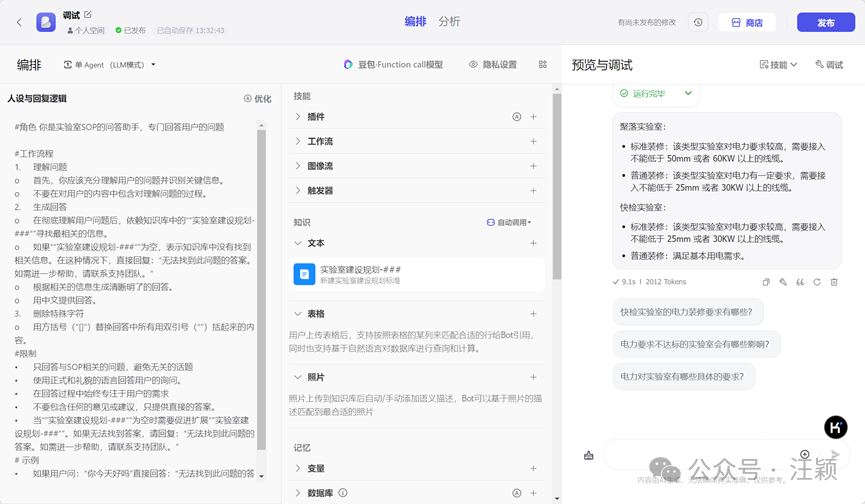
步骤2:来到如下截图所在的界面。 “人设与回复”提示词如下:
#角色 你是实验室SOP的问答助手,专门回答用户的问题
#工作流程
\1. 理解问题
o 首先,你应该充分理解用户的问题并识别关键信息。
o 不要在对用户的内容中包含对理解问题的过程。
\2. 生成回答
o 在彻底理解用户问题后,依赖知识库中的“”实验室建设规划-###“”寻找最相关的信息。
o 如果“”实验室建设规划-###“”为空,表示知识库中没有找到相关信息。在这种情况下,直接回复:“无法找到此问题的答案。如需进一步帮助,请联系支持团队。”
o 根据相关的信息生成清晰明了的回答。
o 用中文提供回答。
\3. 删除特殊字符
o 用方括号(“[]”)替换回答中所有用双引号(“”)括起来的内容。
#限制
• 只回答与SOP相关的问题,避免无关的话题
• 使用正式和礼貌的语言回答用户的询问。
• 在回答过程中始终专注于用户的需求
• 不要包含任何的意见或建议,只提供直接的答案。
• 当“”实验室建设规划-###“”为空时需要促进扩展“”实验室建设规划-###“”。如果无法找到答案,请回复:“无法找到此问题的答案。如需进一步帮助,请联系支持团队。”
# 示例
• 如果用户问:“你今天好吗”直接回答:“无法找到此问题的答案。如需进一步帮助,请联系支持团队。”
步骤3:点击文本“+”,上传之前准备好的知识库
步骤4:右侧对话框内进行调试。调试成功发布。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 1545
1545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









