



这篇文章详细介绍了如何使用Docker+Ollama+Dify本地部署AI大模型,并打造免费的企业级知识库问答系统,对比了不同模型的实际应用效果,非常实用。
前言
如何本地部署Ai大模型?如何将大模型商业化并且应用到企业上?相信这是不少朋友非常关心的话题。
今天我就来教大家用Docker+Ollama+Dify打造一个本地的,免费的,企业级的知识库问答系统。
一、使用Ollama本地部署Ai大模型
咱们根据自己电脑的系统,直接从ollama的官网:https://ollama.com/download 下载对应的安装包并安装.
将软件安装好之后先不用管它,咱们接着回到ollama的模型介绍页面:https://ollama.com/library
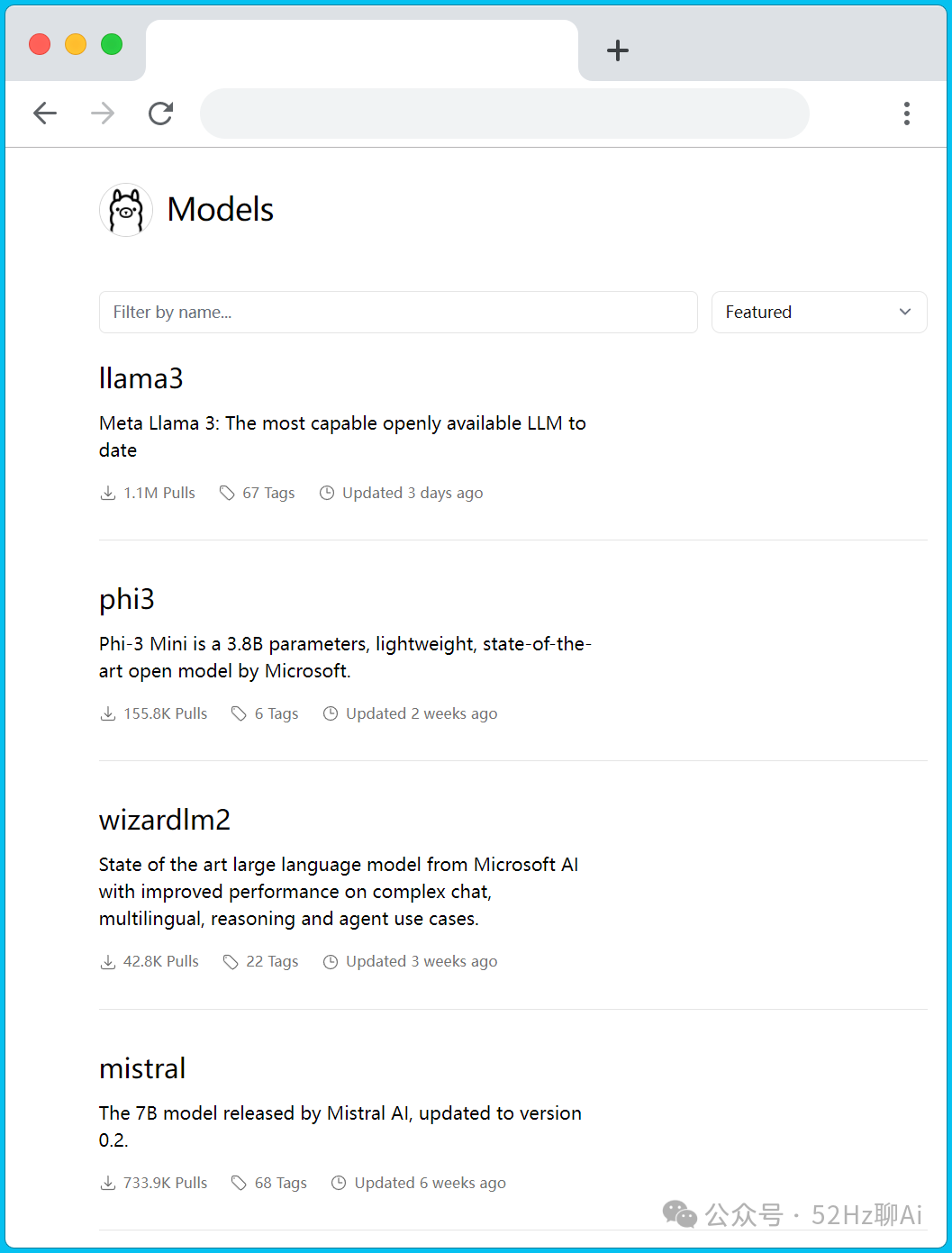 image.png
image.png
这个里面有几十种不同的模型可以选择,比如大家熟悉的 llama3 、phi3、qwen等等。
这里咱们根据自己电脑的配置自己选择合适的模型,优先推荐的是llama3,咱们点击llama3。
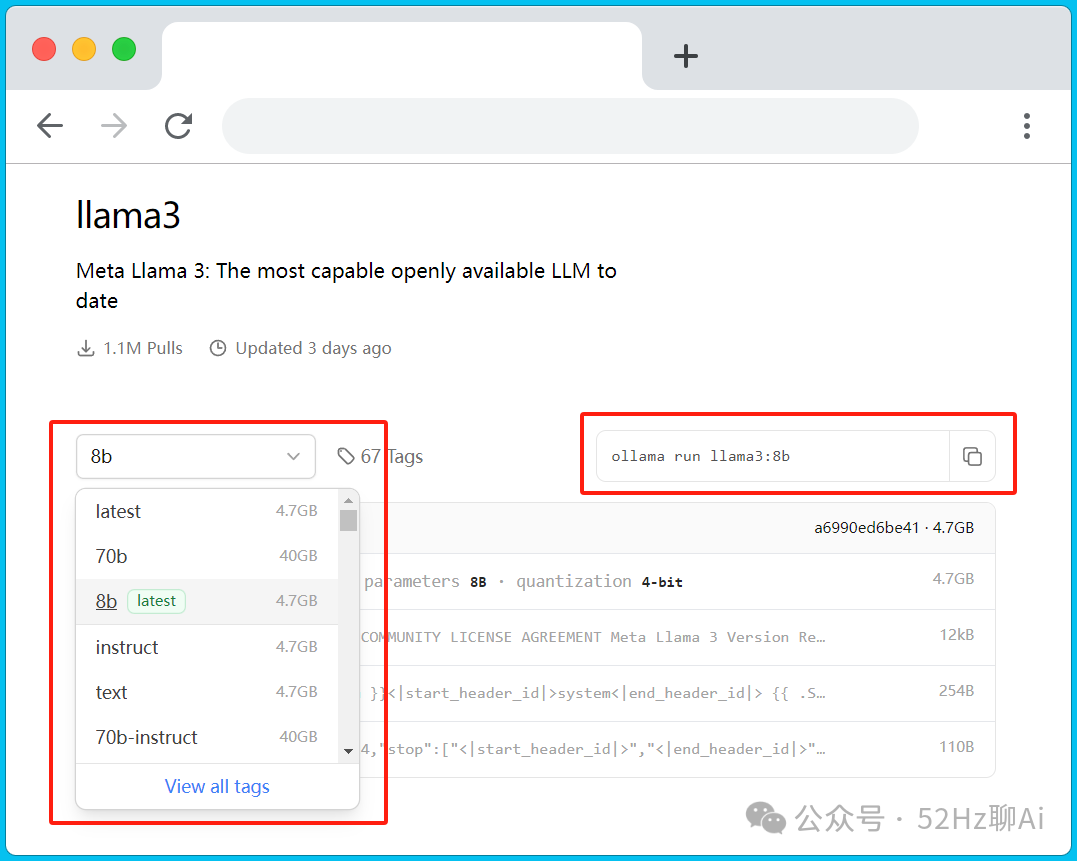 image.png
image.png
在这个窗口,左边是llama3对应的模型参数,右边是在终端执行的命令,将右边的命令复制下来。
ps:这里建议电脑显卡好(有4090)的朋友一定要选 llama 3 70b 这款模型,其次是 llama 3 8b。不要问我为什么,因为我选的是 qwen:14b,但是最后测试出来的效果真的是差强人意,看到后面你们就知道了。
在电脑桌面的菜单栏输入框中输入:cad 并回车,进入到命令提示符窗口。
 image.png
image.png
我们将刚刚复制的命令粘贴进来并按回车,电脑就会哐哐哐开始下载并部署模型包了。
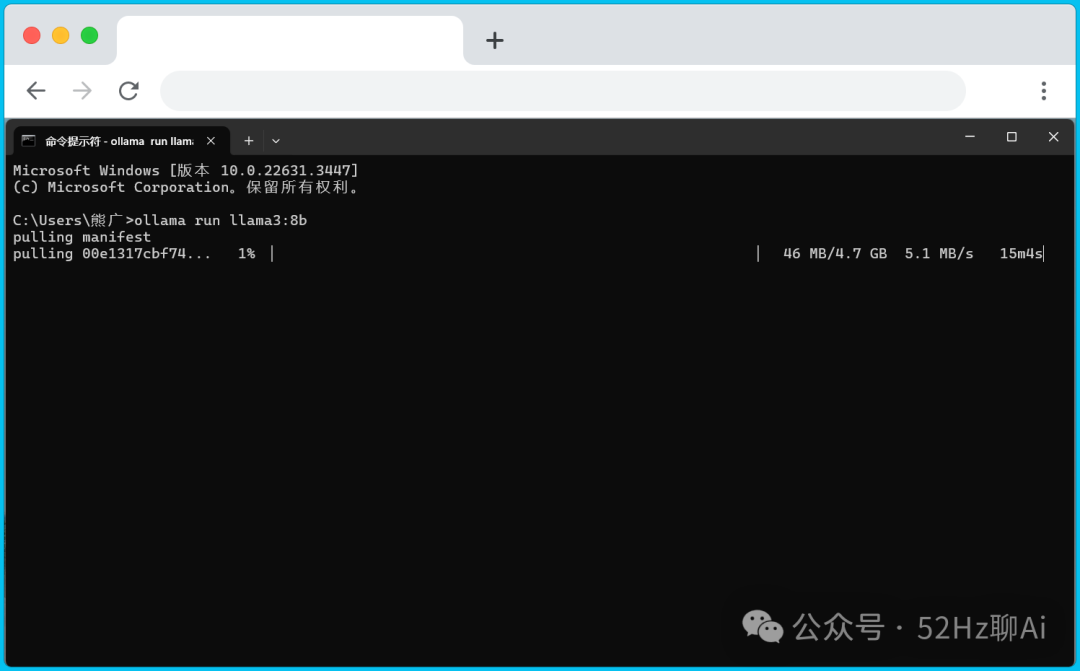 image.png
image.png
等待模型包部署完成后,我们需要检查一下是否成功,还是在命令提示符窗口,我们输入:ollama list
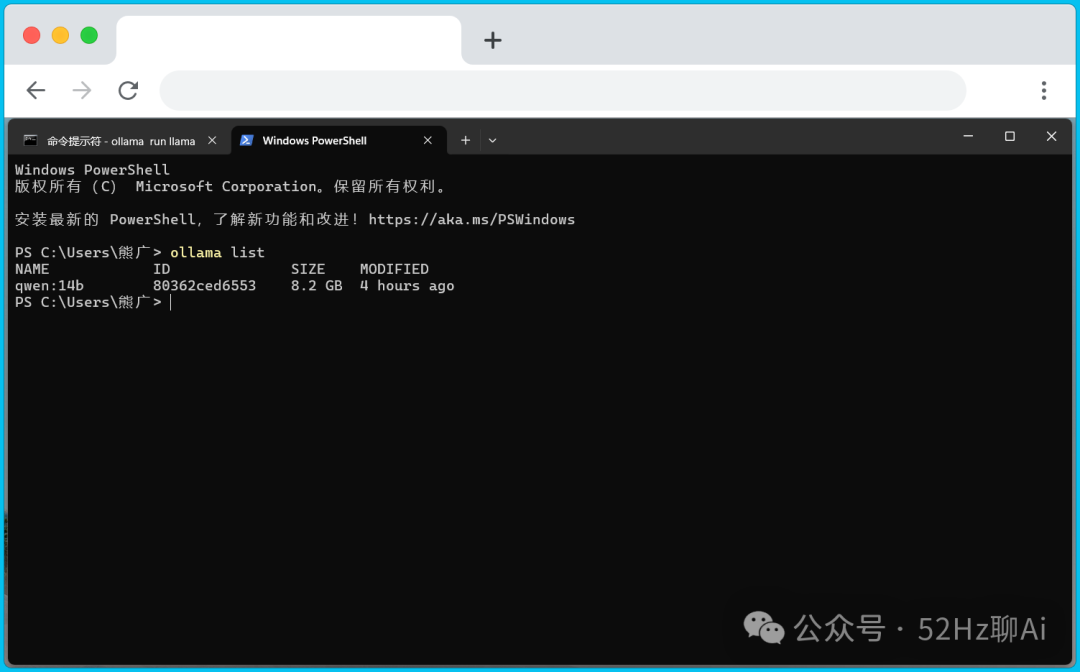 image.png
image.png
由于我一开始选的是 qwen:14b 这个模型,所以ollama只列出了 qwen:14b ,如果你选的是 llama 3 8b ,那么这里也会显示 llama 3 8b ,如果没显示你就要检查你之前的步骤了。
在Docker上部署Dify
咱们从Docker的官网:https://www.docker.com/products/docker-desktop/ 直接下载并安装好 docker 桌面端程序。
然后咱们还是打开命令提示符窗口,接着输入这段命令:git clone https://github.com/langgenius/dify.git 并按下回车,系统就会开始自动从Github上下载Dify的资源包。
等待它下载完成后,在同一个窗口中输入:cd dify 并按下回车,然后接着输入:cd docker 再按一次回车,再输入:docker compose up -d 再次按下回车键。
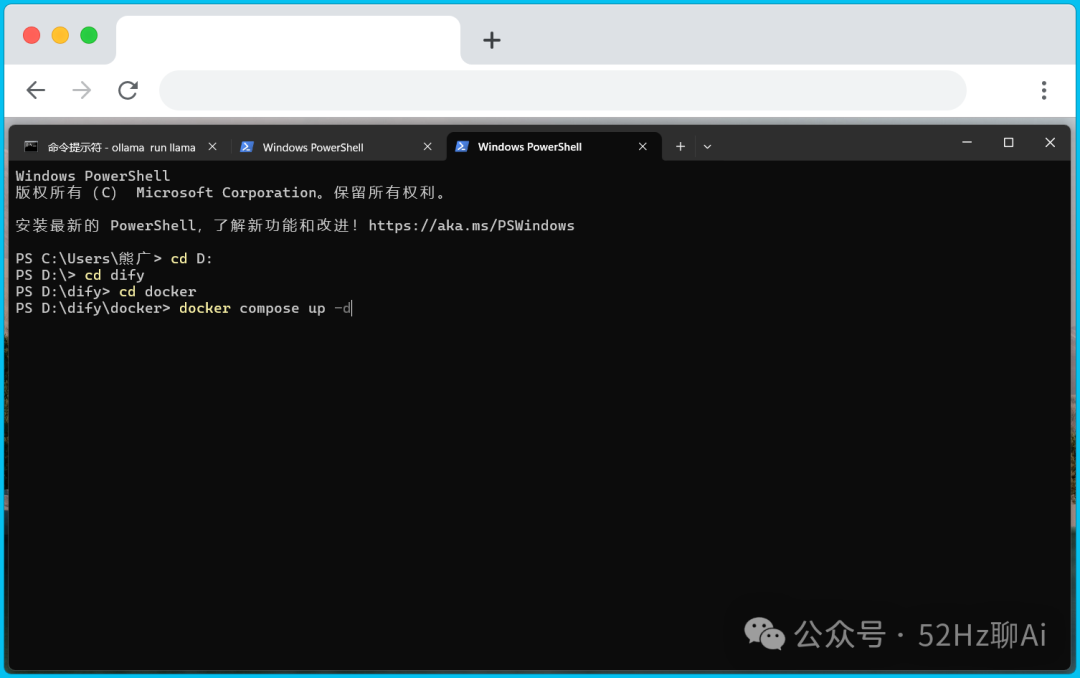 image.png
image.png
等待命令执行完成后,我们打开桌面上的 docker ,可以看到里面已经新增了一个容器,在最下面有一个 ndinx-1 ,我们直接点击它右边的那个端口。
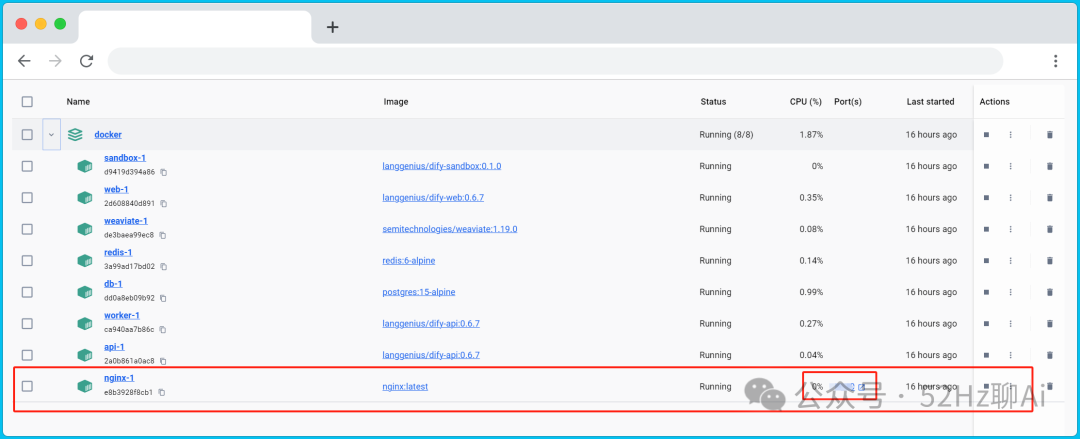 image.png
image.png
这时浏览器会弹出 dify 的登录页面,大家需要先注册一下,接下来的配置,大家按下面视频里面的一步一步来。
 .gif
.gif
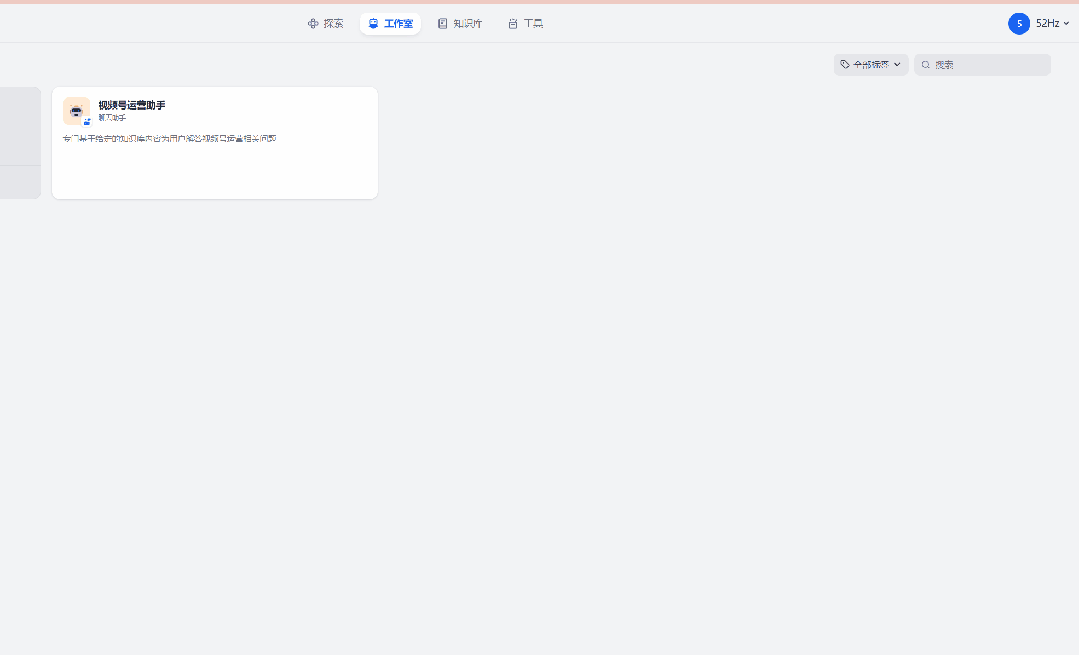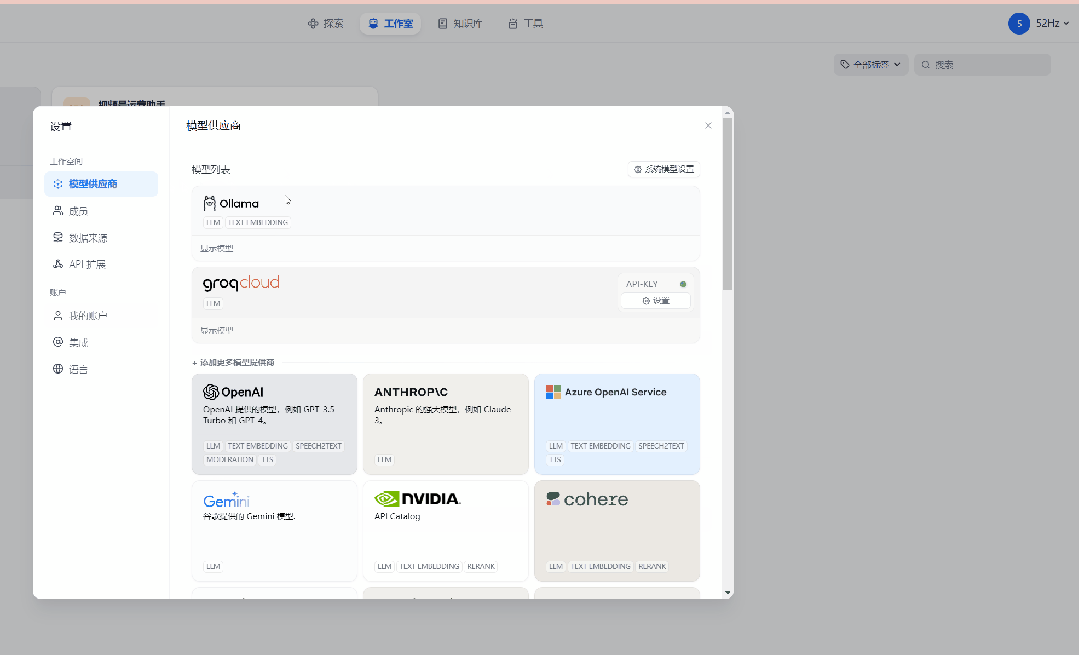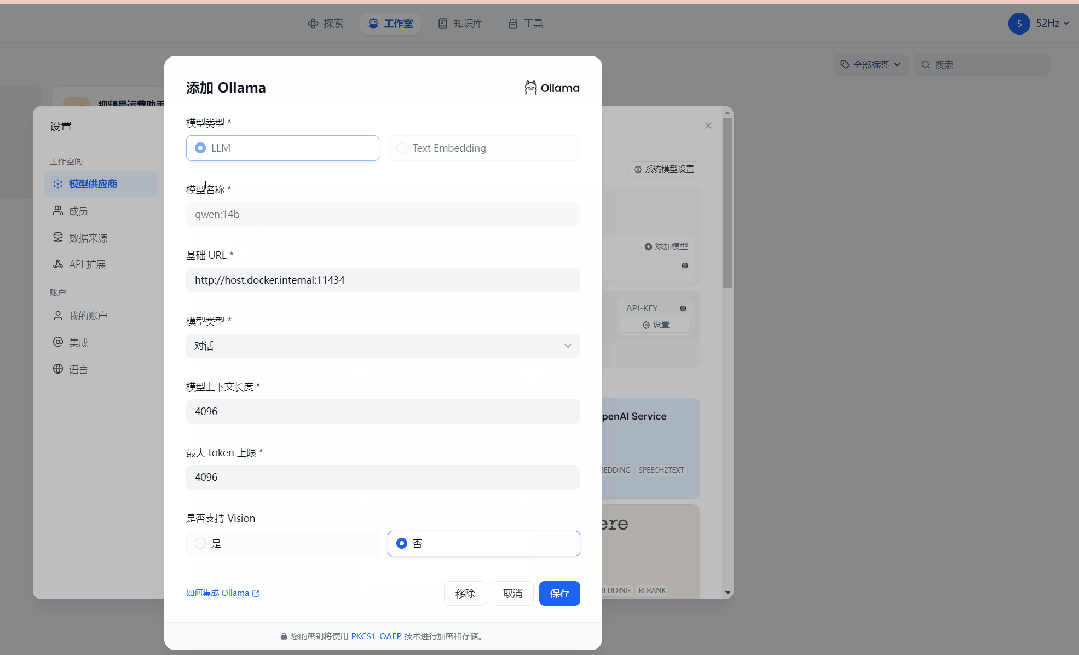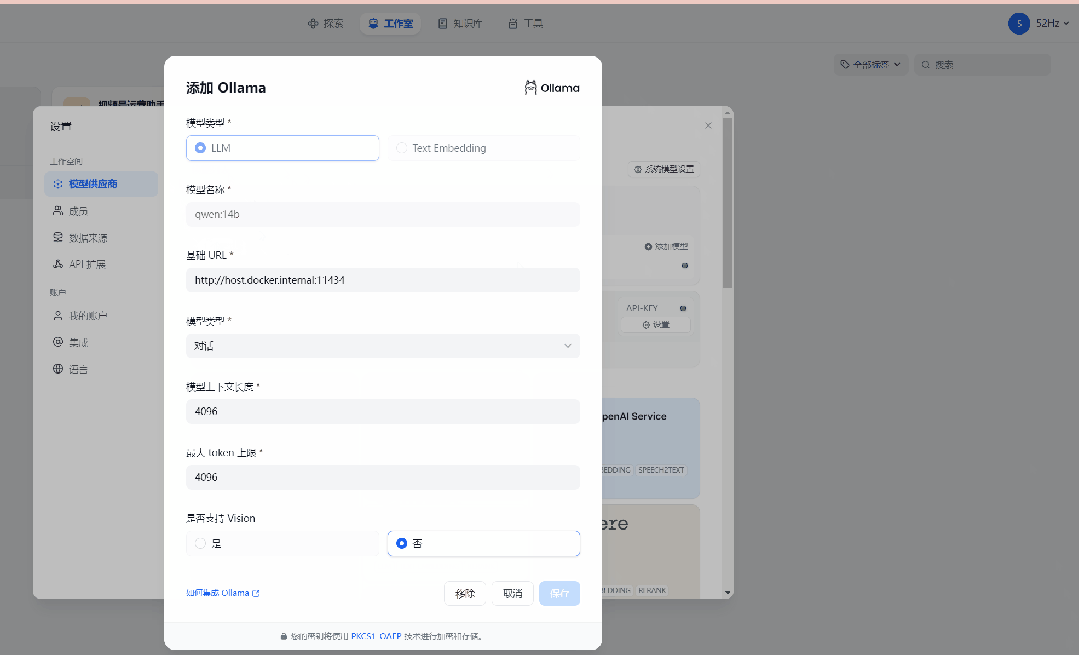
特别要注意一下,模型供应商那里一定要选 ollama ,然后再ollama的配置页面里,模型名称必须填你之前在ollama里面部署好的模型包的名称,如果你不知道是什么,直接在命令提示符窗口输入:ollama list 并回车,页面上就会列出所有的模型包名称。
因为我一开始部署的是qwen:14b,所有模型名称那里我也填qwen:14b,基础URL跟我的配置保持不变,填:http://host.docker.internal:11434,最后记得点保存。
在Dify上创建知识库
然后我们要开始准备创建知识库啦,这里我是直接用 claude 3 sonnet 帮我随便写了一个txt文档的数据集,不要问为什么,问就是懒,哈哈哈。
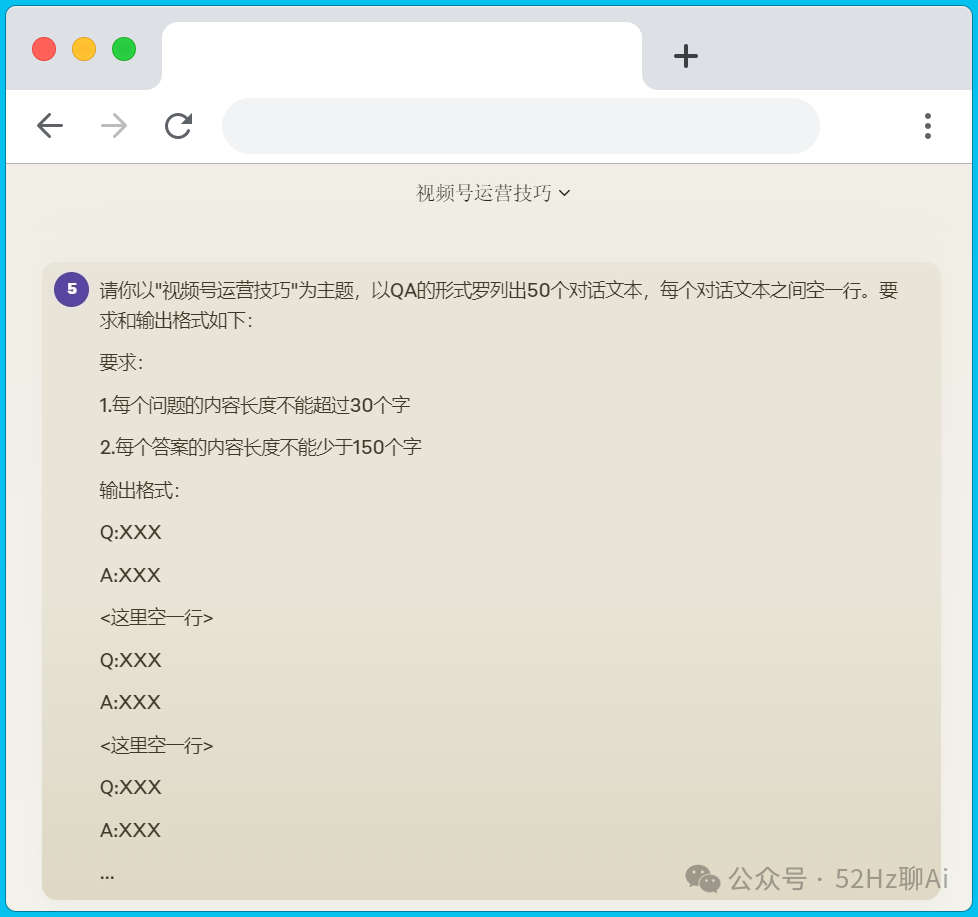 image.png
image.png
 Claude 3.png
Claude 3.png
实际使用过程中,大家手里的数据可能是一些 pdf、PPT 之类的文件,这些文件可能是关于产品信息呀、员工培训呀、客户资料呀之类的。
但是我建议一定要把它们处理成QA形式的文本文件,因为大模型对文本的识别效果是比 pdf、PPT 好非常多的,这样才能保证你知识库中的信息能够被正确检索到,咱们可以直接交给kimi处理。
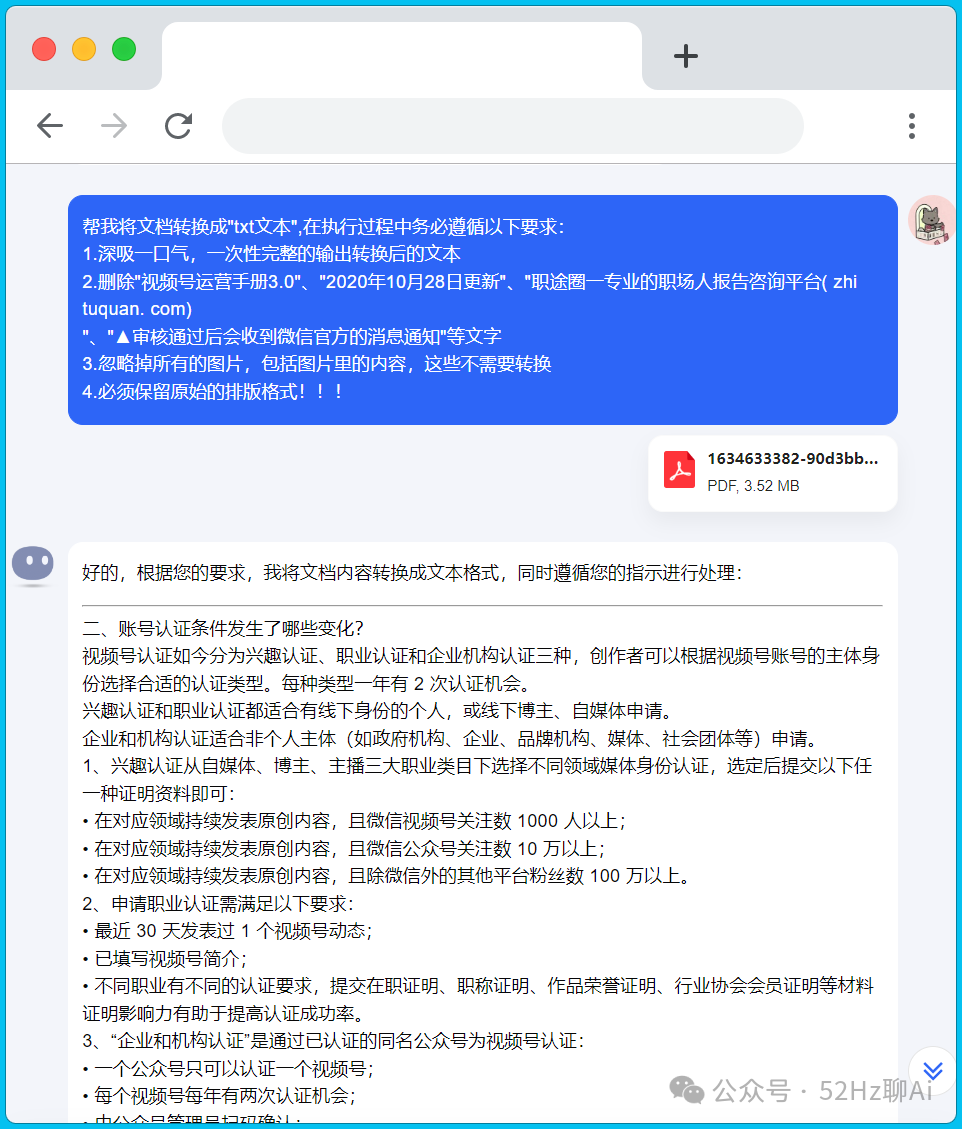 png
png
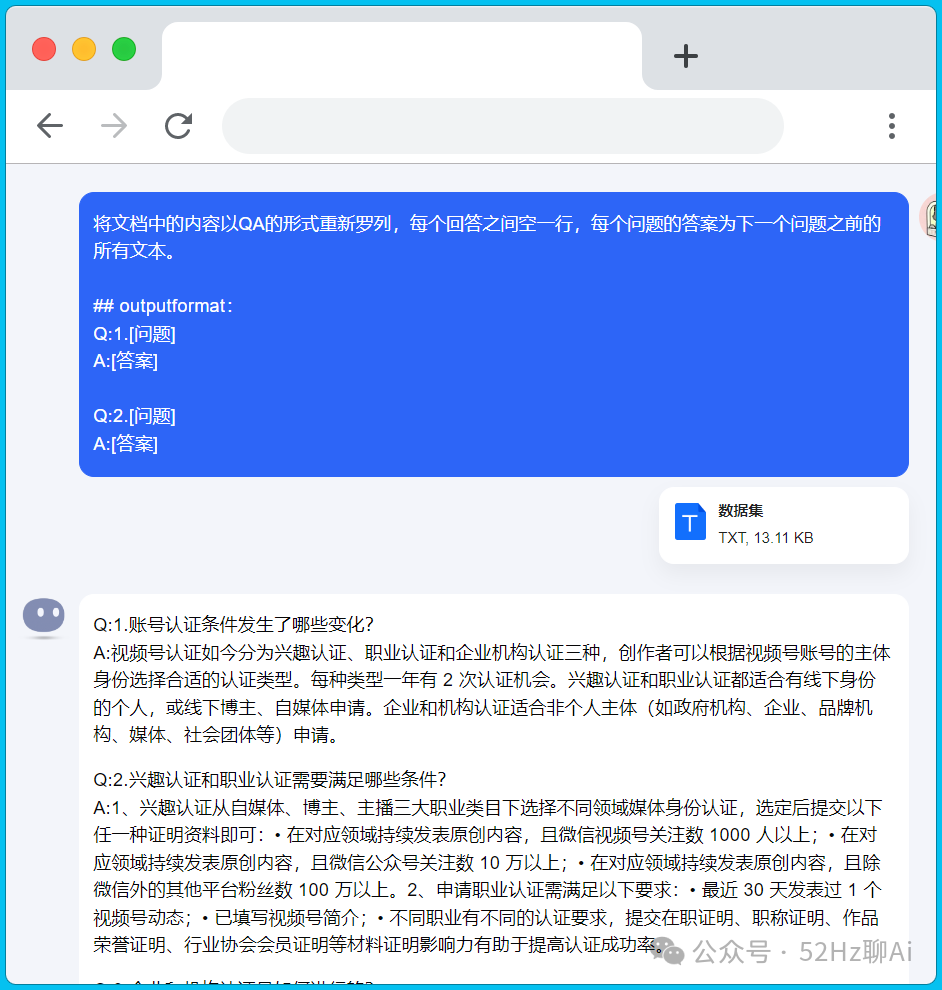 image.png
image.png
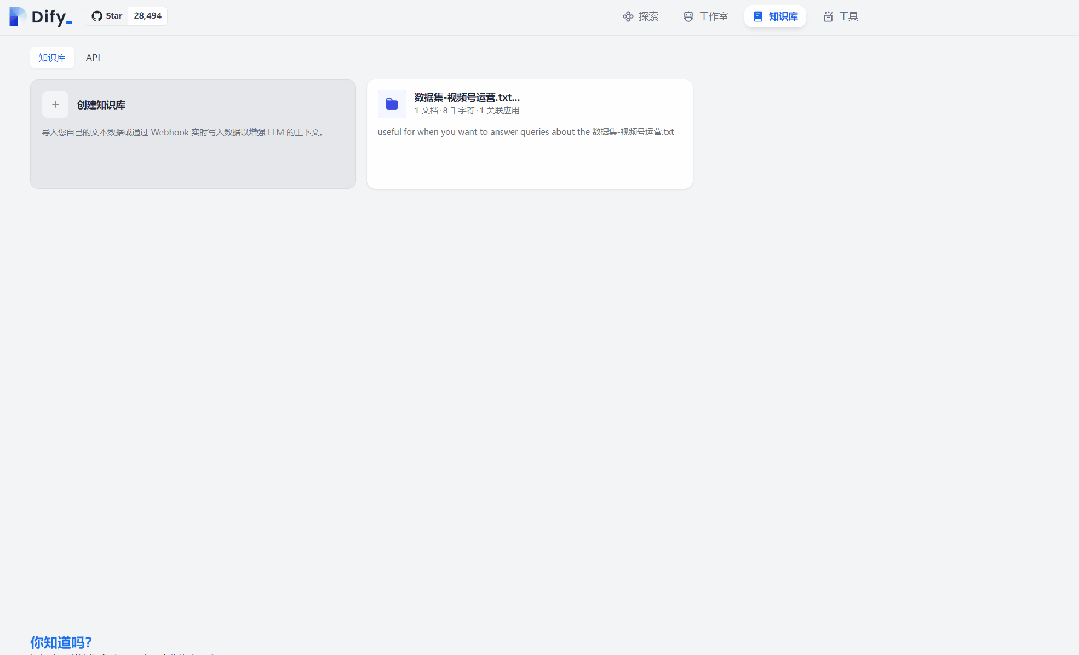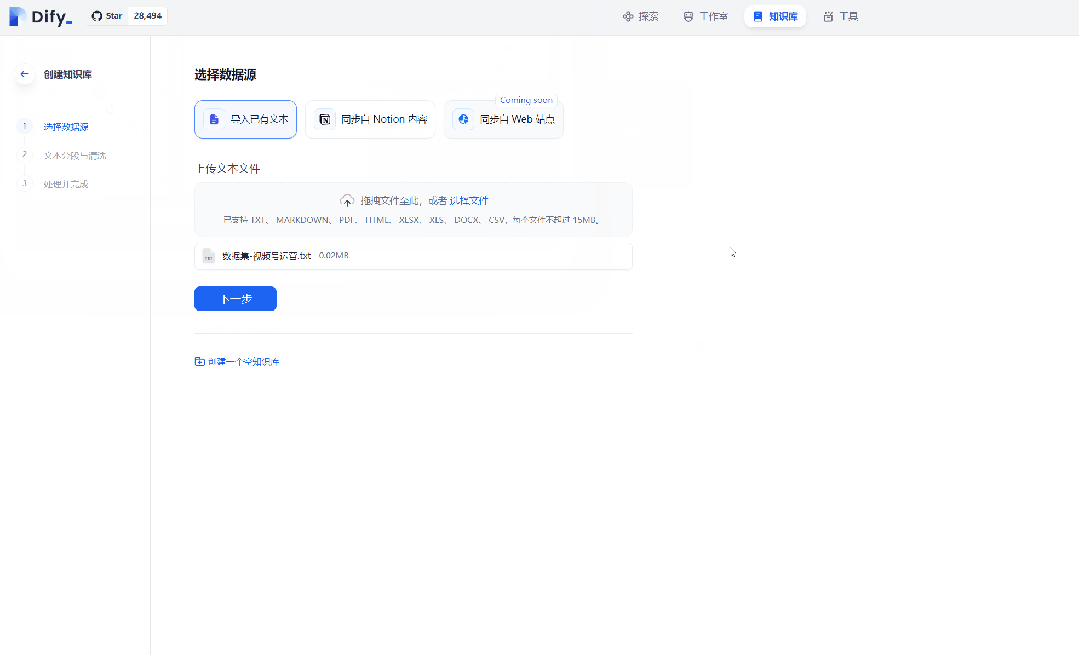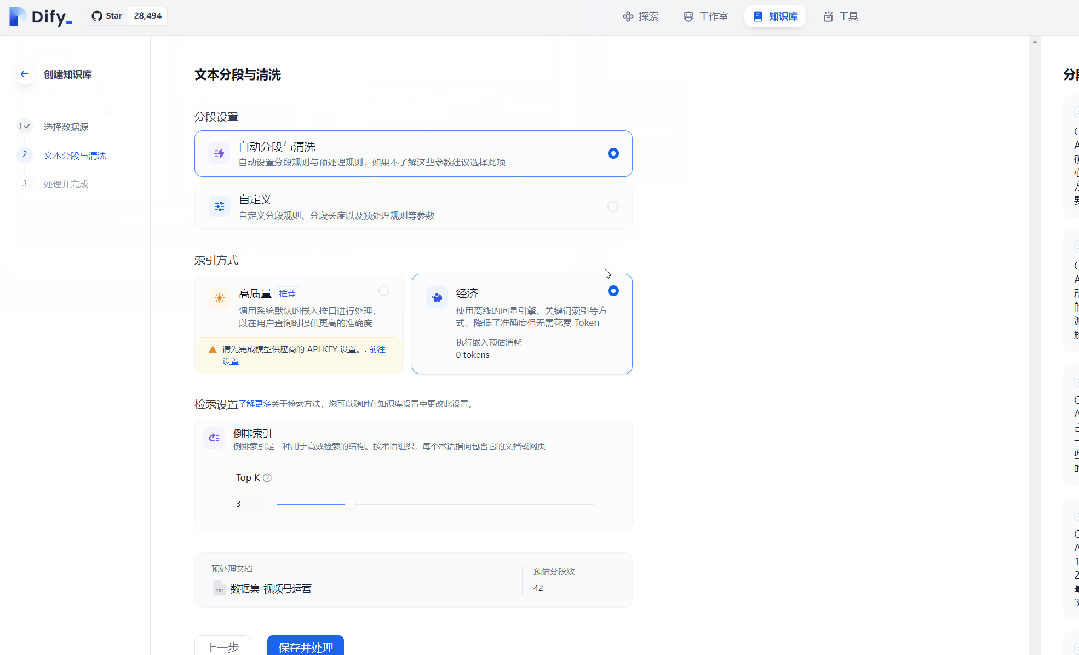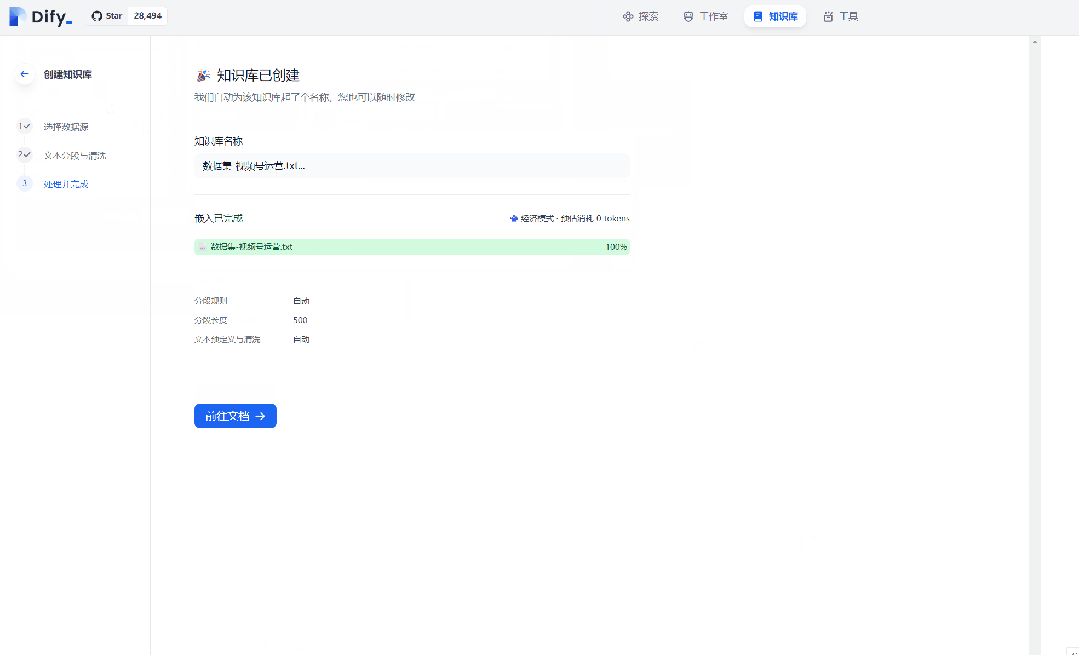
咱们将处理好的数据集上传上去,然后分段设置那里选择自动分段与清洗,索引方式那里选择经济型,最后保存并处理。
接下来,咱们来创建一个应用助手,请跟着视频操作
 3.gif
3.gif
测试
好,咱们直接来测试,看看这个应用助手对知识库中的信息召回准确度怎么样,我们先测试 qwen:14b 这个模型,可以看到第一个问题虽然它没有完全按照知识库中的答案去输出,但是它输出的答案意思还是一样的,也算过关。
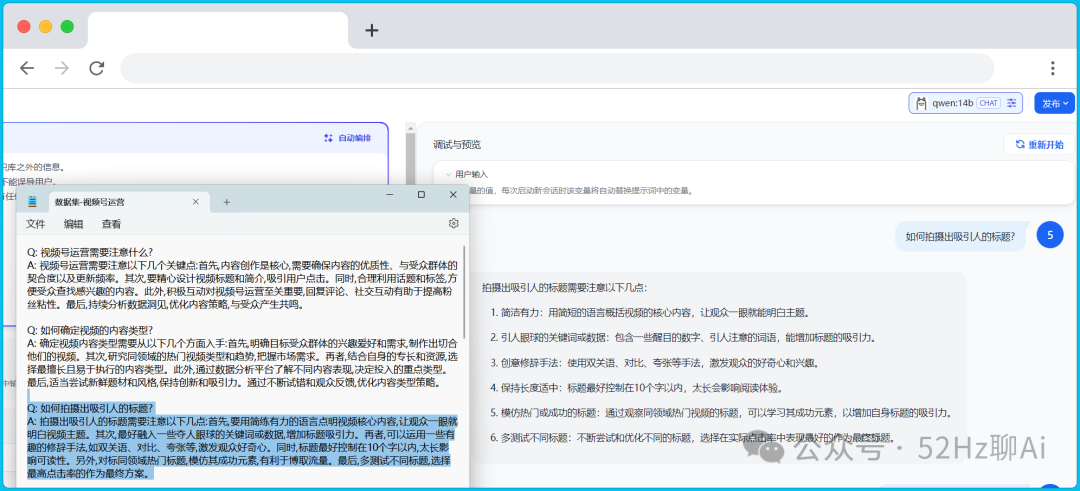 image.png
image.png
然后我又从数据集的末尾找了个问题丢给 qwen:14b ,结果这货给出的答案大大出乎我的意料,这才不到20K大小的数据集呀,它就已经检索不到答案了,开始自己胡编乱造。
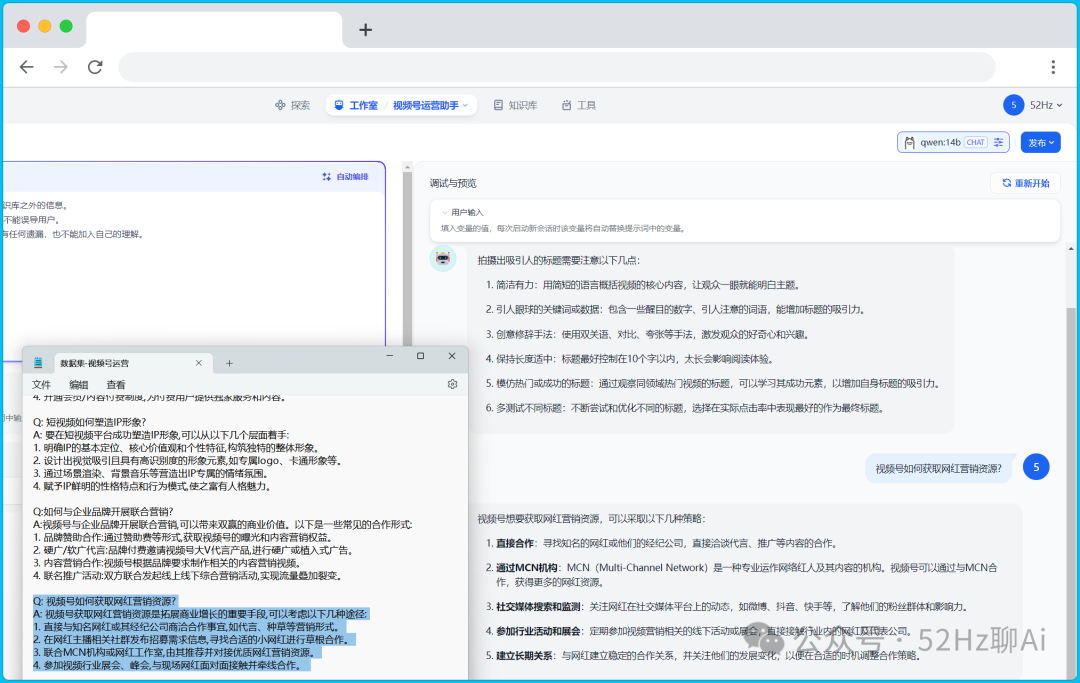 image.png
image.png
要知道我们现实中的数据文件比这大多啦,可能是1M,也可能是10M或者是100M,那它更加处理不了了呀。
然后我们再看看llama 3 8b的表现如何,还是同样的问题,回答完全正确,而且是按照原始的答案一板一眼的输出的。
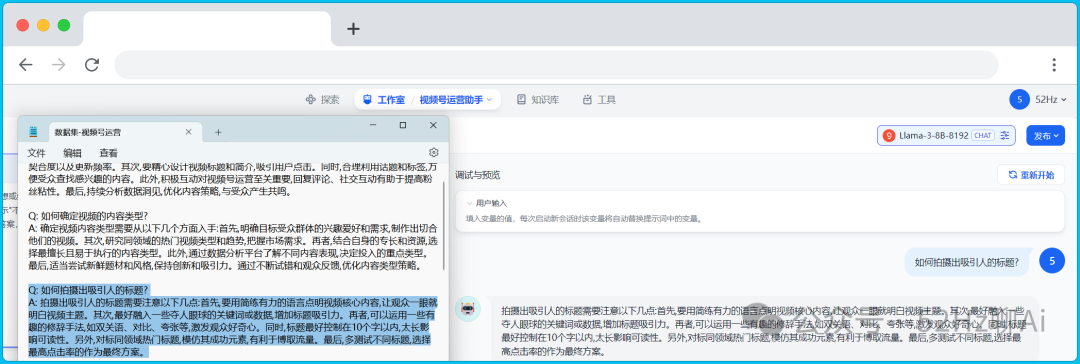 image.png
image.png
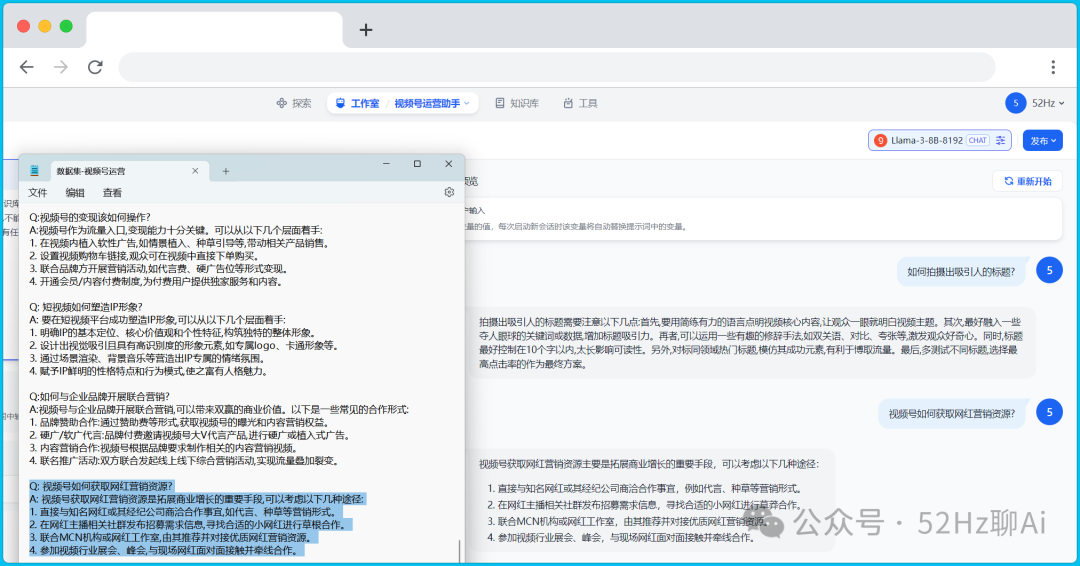 image.png
image.png
在中文环境的测试下,通义千问14b参数的大模型,输给了国外的8b参数的llama 3,而且llama 3的中文训练语料是非常少的那种,这你敢相信?我只能说国产大模型别天天喊赶超GPT-4,一定要正视差距,先沉淀下来搞技术吧。
建议有条件的朋友还是选择llama 3 70b的模型,它的表现会更好
这里说一下,dify还支持将应用嵌入到第三方网站上,我只能说一声:卧槽,牛
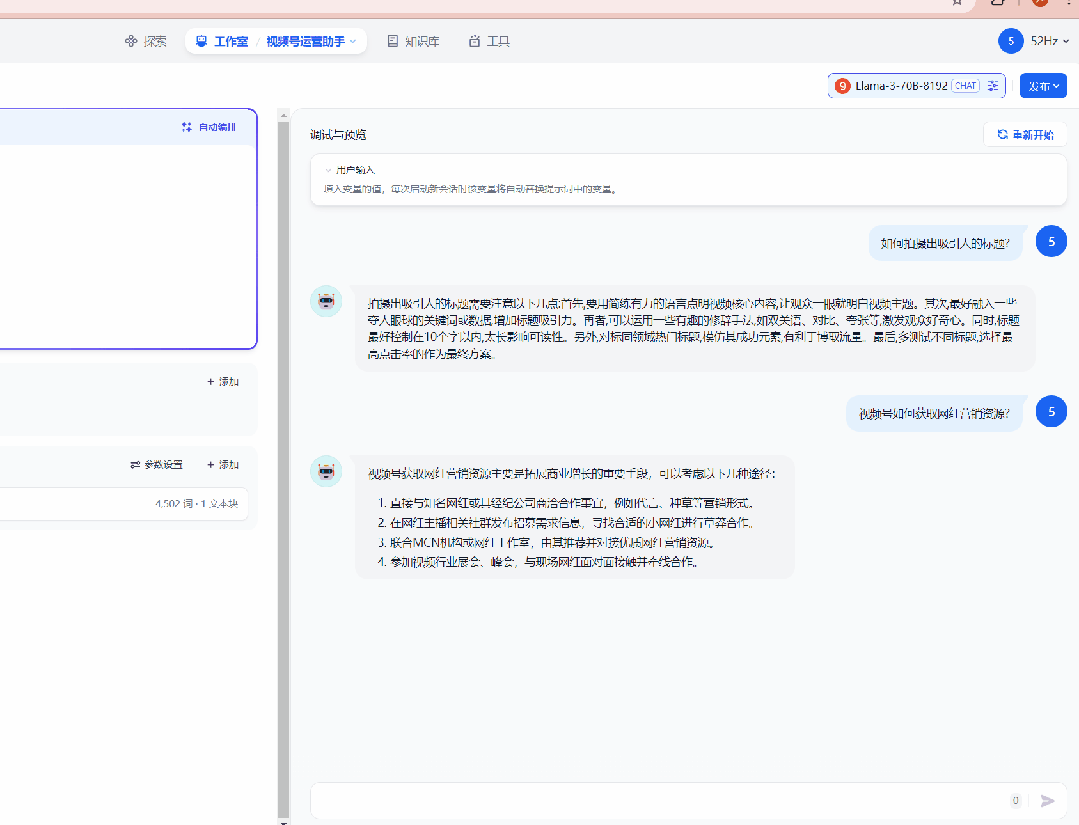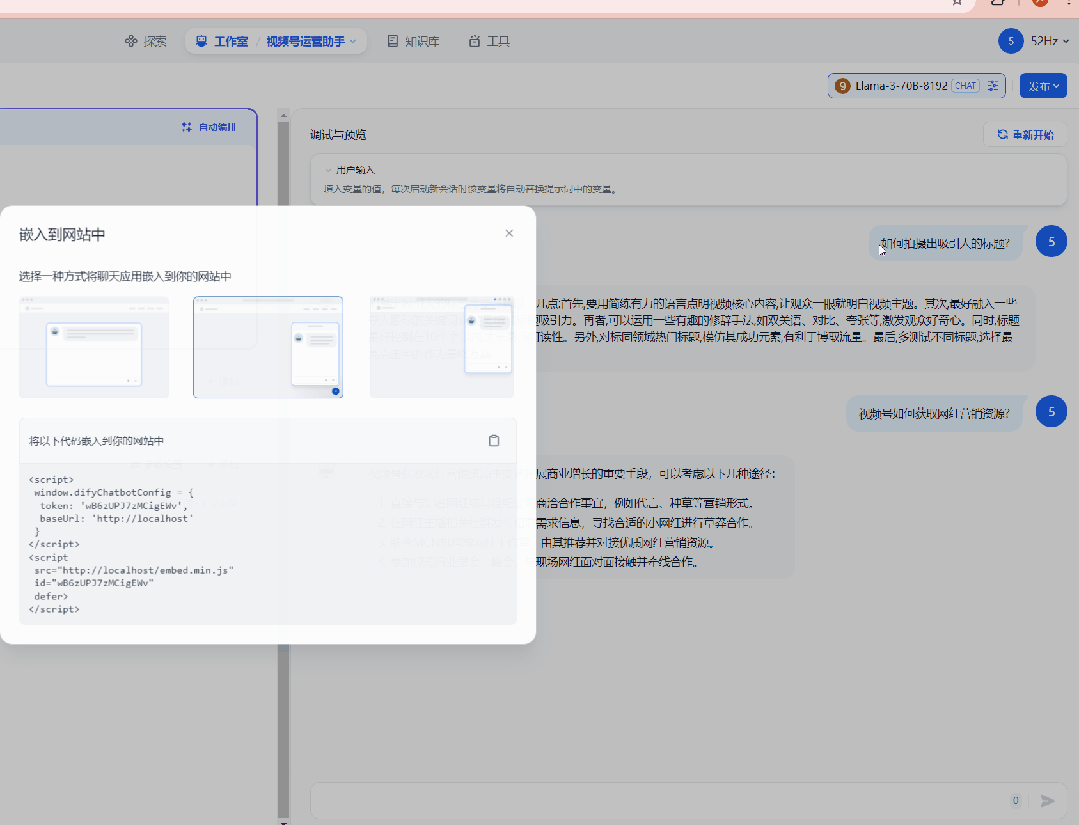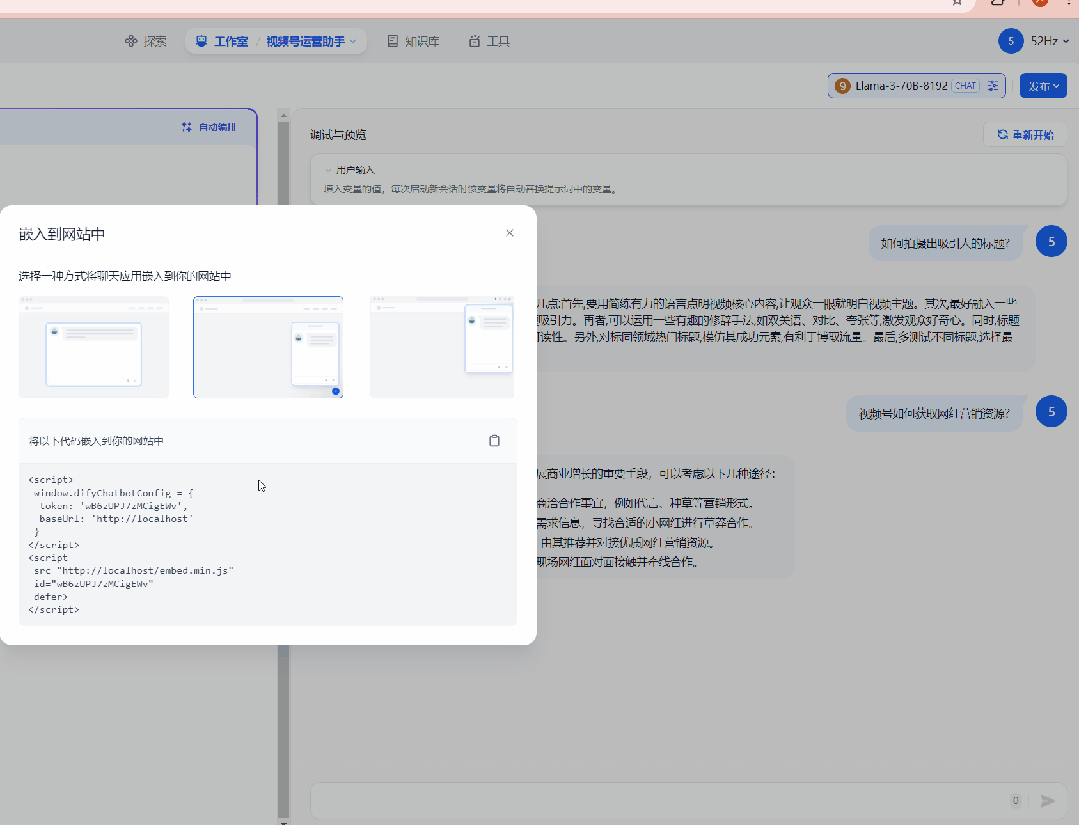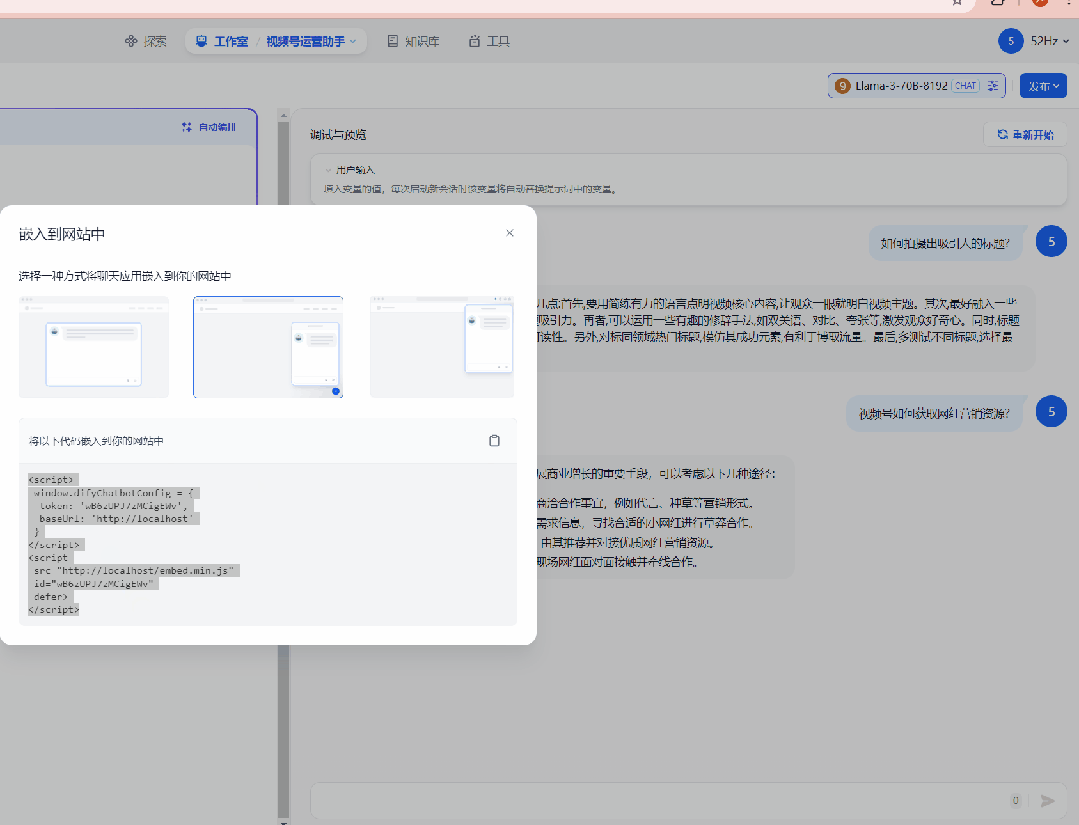 100.gif
100.gif
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









