



今天,我们将把重点转向 OpenAI。本文将提供一份规范的指南,帮助开发者利用 OpenAI API 对大型语言模型 (LLM) 进行精细化微调,以满足特定领域或应用场景的需求。通过微调,开发者可以基于预训练模型的强大泛化能力,针对特定数据集进行定制化训练,从而显著提升模型在目标任务上的性能表现。
\01. 环境准备与依赖安装
在开始微调流程之前,我们需确保开发环境已正确配置,并安装以下必要的 Python 库:
datasets: 用于高效地加载、处理和管理数据集,尤其适用于机器学习工作流。openai: 用于与 OpenAI API 进行交互,执行文件上传、微调任务创建和管理等操作。
pip install datasets openai
\02. 数据集加载与预处理
本指南以 Hugging Face Hub 上公开的 "lamini/lamini_docs" 数据集为例进行演示。开发者可根据实际情况替换为自定义数据集。
from datasets import load_dataset
# 从Hugging Face加载数据集
dataset = load_dataset("lamini/lamini_docs")
\03. 数据集结构分析
为了确保后续步骤的顺利进行,建议开发者在加载数据集后,对其结构和内容进行初步分析,以便进行必要的数据预处理和格式转换。
print(dataset)
输出结果示例:
DatasetDict({
train: Dataset({
features: ['question', 'answer', 'input_ids', 'attention_mask', 'labels'],
num_rows: 1260
})
test: Dataset({
features: ['question', 'answer', 'input_ids', 'attention_mask', 'labels'],
num_rows: 140
})
})
04. 数据格式转换与准备
数据集被分为训练集和测试集,我们将只使用训练数据。现在来提取训练数据:
import pandas as pd
train_dataset = dataset['train']
train_df = pd.DataFrame(train_dataset)
questions_answers = train_df[['question', 'answer']]
在此步骤中,我们将仅从数据框中提取问题和答案,因为它们是主要的微调目标。
OpenAI 要求数据采用特定的 JSONL 格式进行微调。每行必须是一个表示单个训练示例的 JSON 对象。以下是格式化数据的方法:
with open('finetune_data_chat_format.jsonl', 'w') as jsonl_file:
for index, example in questions_answers.iterrows():
formatted_data = {
"messages": [
{"role": "system", "content": "You're a helpful assistant"},
{"role": "user", "content": example['question']},
{"role": "assistant", "content": example['answer']}
]
}
jsonl_file.write(json.dumps(formatted_data) + '\\n')
更多关于数据格式的详细信息,请参阅 OpenAI 官方文档(见文末)。
\05. 数据集上传至 OpenAI 平台
完成数据格式转换后,需要将 JSONL 文件上传至 OpenAI 平台。
from openai import OpenAI
from pathlib import Path
client = OpenAI(api_key="your_api_key")
response = client.files.create(
file=Path('finetune_data_chat_format.jsonl'),
purpose='fine-tune'
)
安全提示: 请妥善保管 API 密钥,避免泄露。
06. 创建并启动微调任务
使用上传文件的 ID 创建微调任务。
fine_tune_response = client.fine_tuning.jobs.create(
training_file=response.id, # 使用上传文件的ID
model="gpt-3.5-turbo" # 指定要微调的模型
)
print("微调作业已启动,ID为:", fine_tune_response.id)
这将在所选模型上开始微调过程。作业 ID 用于跟踪微调作业的进度。
注意: 训练完成后,你将收到一封包含模型名称的电子邮件,用于在测试部分使用该模型名称。
07. 创建并启动微调任务微调任务进度监控
使用以下代码查询微调任务的状态和进度。
client.fine_tuning.jobs.retrieve("your_fine_tune_job_id")
将 “your_fine_tune_job_id” 替换为作业创建步骤返回的 ID。此命令提供有关作业状态和性能的详细信息。
08. 微调模型测试与评估
微调完成后,使用新的模型名称进行测试和评估。
completion = client.chat.completions.create(
model="your_fine_tuned_model_name",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Your message here"}
],
max_tokens=50
)
print(completion.choices[0].message.content)
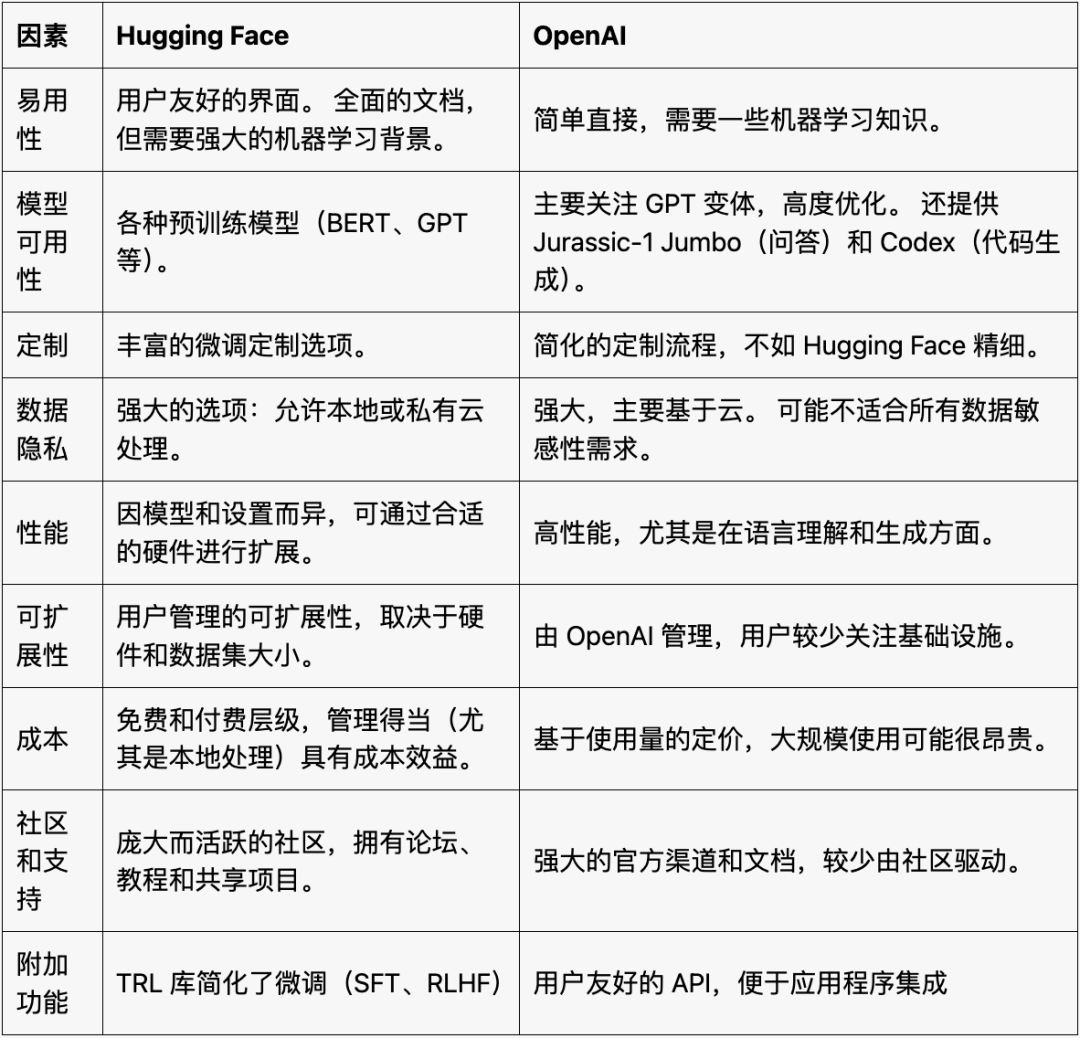
Hugging Face 与 OpenAI 微调方案对比
结语
OpenAI API 提供了一种强大且简化的 LLM 微调方法,使开发者能够根据特定需求定制语言模型。本文概述了微调的关键步骤,并探讨如何利用向量数据库优化微调效果。
微调模型通常涉及为输入数据生成嵌入(向量表示)。将这些嵌入存储在向量数据库中,可以显著提升检索效率和相似性搜索性能,尤其在文档分类、语义搜索等应用场景中。MyScale 是一款专为 AI 应用设计的 SQL 向量数据库,其快速检索和相似性搜索能力使其成为 LLM 微调的理想伴侣。 开发者可以通过熟悉的 SQL 语法轻松与其交互,简化了集成流程。
通过以上内容和建议,开发者可以有效地利用 OpenAI API 微调 LLM,并构建满足特定需求的定制化语言模型。结合向量数据库等技术,更可以进一步提升模型性能和应用效率。
OpenAI 数据格式文档:https://platform.openai.com/docs/guides/fine-tunin**g/example-format
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。


















 1231
1231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









