



前言
为了能够实现向量数据库的构建与应用,我们首先需要知道几个小的背景和流程:
- 之所以我们要有向量数据库,其主要的原因就是大语言模型的上下文是有局限的,对于一些很长的文章来说很难完整的读完。但是假如读不完的话很可能又会遗漏一些重要的信息。因此我们可以借助向量数据库把整个文章保存起来,然后根据向量的近似程度来找到最相关的片段提供给大语言模型让其进行回复,这样就既兼顾了阅读全文,又兼顾了文章太长的问题。

- 那这个向量数据库里的向量是怎么产生的呢?其实就是先把文章进行拆分成一块块,然后放入到一个Embedding模型里。Embedding模型将文本转化为向量,这些向量捕捉了文本的语义信息。不同的文本通过Embedding转换后,如果它们的内容相似,它们对应的向量也会非常相近。
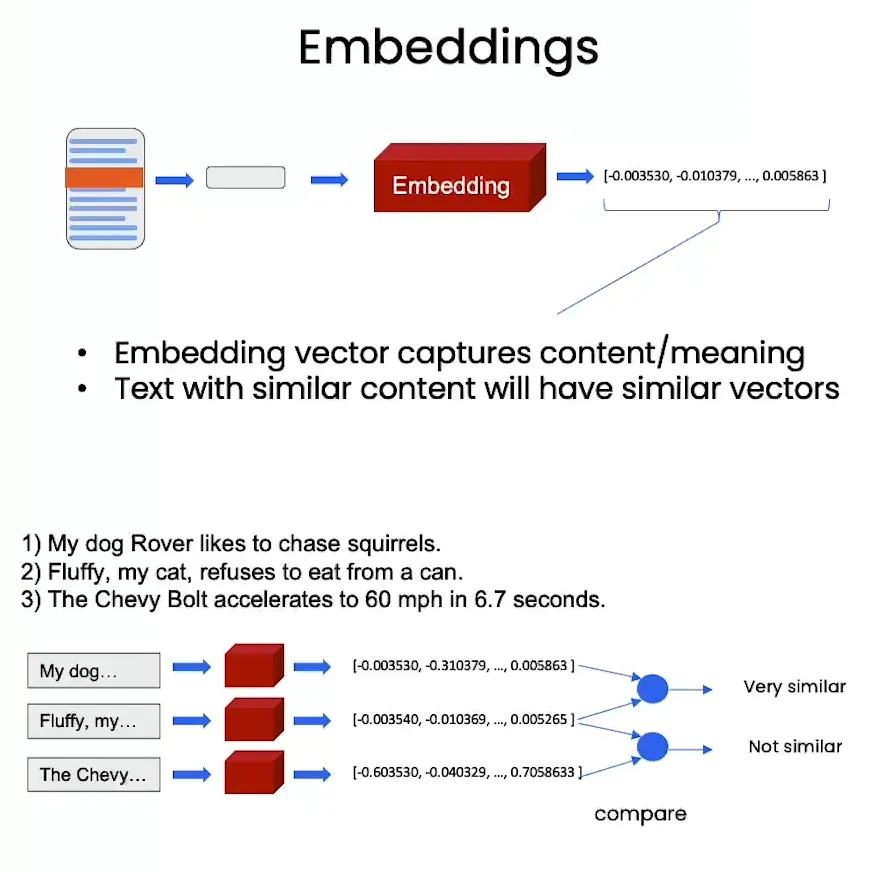
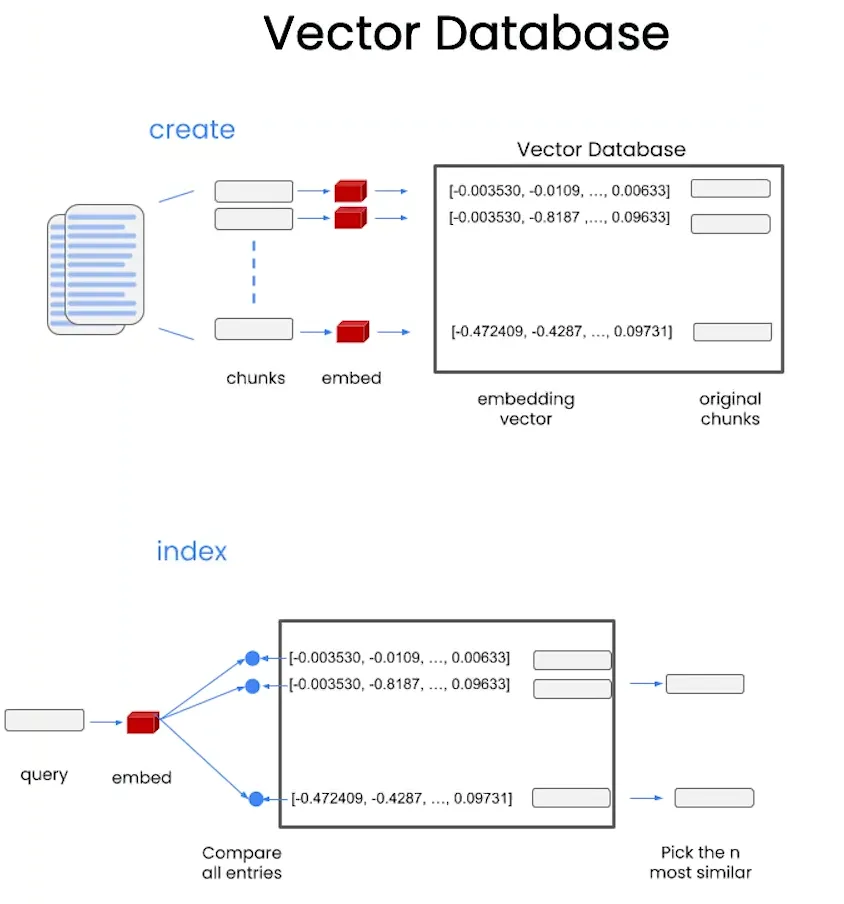
- 在把每一块的文本内容转为向量后,这些向量会被存储到向量数据库中,每个向量都与原始的文档片段关联在一起。这样,当有新的查询(query)输入时,查询也会被转化为一个向量,并与数据库中的向量进行比对。在比对过程中,系统会计算查询向量与所有存储向量的相似度,选出最相似的n个向量。这些相似的向量对应的文档块就是最相关的答案,通过这种方式可以快速返回与查询内容相关的文本片段。
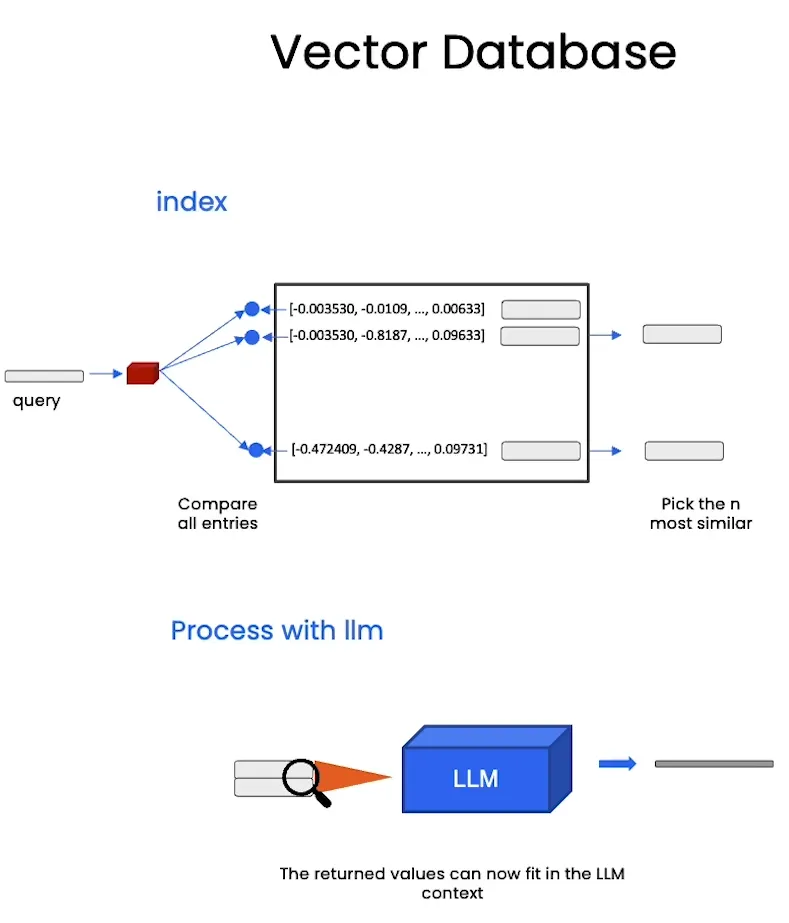
- 最后在找到这些最相关的片段后,这些片段并不会直接返回到用户的界面,而是被传递到大语言模型中。由于每个文档片段已经被转化为向量,大语言模型可以通过这些相关片段来理解查询的上下文,进而生成回答或做出处理。通过这种方式,LLM能够有效地利用检索到的相关信息,从而更好地回答用户的查询。
前期准备
根据上面的信息我们其实已经对RAG系统有一个简单的了解了,那么下面我们就可以来更深入的看看如何利用一份简单的商品文档来利用VectorstoreIndexCreator进行构建属于我们自己的数据库问答系统。
| 商品名称 | 描述 | 尺寸与规格 | 特点 |
|---|---|---|---|
| 女士 Campside 牛津鞋 | 这款超舒适的全鞋款牛津鞋,采用超软帆布材质,厚实的内垫和高质量的制作工艺,从穿上它的第一刻起就能体验到它的舒适感。 | 重量:每双约1磅1盎司;材料:软帆布,EVA内垫,抗菌除臭技术。 | 适合日常穿着,舒适透气;经典设计,适合搭配各种服装。 |
| 可回收 Waterhog 狗垫,菱形编织款 | 这款超耐用的回收材料 Waterhog 狗垫,专为保护地板免受溅水与污垢而设计,采用美国制造的优质材料。 | 尺寸:小号(18"x28"),中号(22.5"x34.5")。 | 抗污抗水,适合各种环境;由94%回收材料制成,环保且耐用。 |
| 婴儿女孩 Coastal Chill 游泳衣(两件式) | 这款亮色的两件式游泳衣适合幼儿,搭配有趣的印花和褶边设计,四向弹性、氯水抗性面料保持衣物形状并避免起球。 | UPF 50+,提供最高级别的防晒保护,阻挡98%的有害紫外线。 | 专为幼儿设计,提供舒适的穿着体验,确保安全合身,具有极佳的抗紫外线性能。 |
| EcoFlex 3L 防水裤 | 采用TEK O2技术的防水裤,保证在各种天气和活动下保持干爽,尤其适合滑雪和户外活动使用。 | 材料:100%尼龙;机器洗涤。 | 高透气性,适合四季穿着,设计有内部防水裤腿和全拉链设计,便于穿脱。 |
| 男女运动休闲鞋 | 这款多功能、舒适的运动鞋,适合各类户外活动和日常穿着,采用透气网面和防水翻毛皮,提供舒适和耐用的体验。 | 鞋垫采用EVA材料,鞋底使用TPU橡胶;适合各种活动。 | 防水透气,舒适设计,适合徒步、跑步等多种运动,特别适合户外使用。 |
大家可以创建一个名为“商品详情.csv”的文件,并将下面的内容放进去即可完成数据库的创建。
商品名称,描述,尺寸与规格,特点
女士 Campside 牛津鞋,这款超舒适的全鞋款牛津鞋,采用超软帆布材质,厚实的内垫和高质量的制作工艺,从穿上它的第一刻起就能体验到它的舒适感。,重量:每双约1磅1盎司;材料:软帆布,EVA内垫,抗菌除臭技术。,适合日常穿着,舒适透气;经典设计,适合搭配各种服装。
可回收 Waterhog 狗垫,菱形编织款,这款超耐用的回收材料 Waterhog 狗垫,专为保护地板免受溅水与污垢而设计,采用美国制造的优质材料。,"尺寸:小号(18""x28""),中号(22.5""x34.5"")。",抗污抗水,适合各种环境;由94%回收材料制成,环保且耐用。
婴儿女孩 Coastal Chill 游泳衣(两件式),这款亮色的两件式游泳衣适合幼儿,搭配有趣的印花和褶边设计,四向弹性、氯水抗性面料保持衣物形状并避免起球。,UPF 50+,提供最高级别的防晒保护,阻挡98%的有害紫外线。,专为幼儿设计,提供舒适的穿着体验,确保安全合身,具有极佳的抗紫外线性能。
EcoFlex 3L 防水裤,采用TEK O2技术的防水裤,保证在各种天气和活动下保持干爽,尤其适合滑雪和户外活动使用。,材料:100%尼龙;机器洗涤。,高透气性,适合四季穿着,设计有内部防水裤腿和全拉链设计,便于穿脱。
男女运动休闲鞋,这款多功能、舒适的运动鞋,适合各类户外活动和日常穿着,采用透气网面和防水翻毛皮,提供舒适和耐用的体验。,鞋垫采用EVA材料,鞋底使用TPU橡胶;适合各种活动。,防水透气,舒适设计,适合徒步、跑步等多种运动,特别适合户外使用。
下面就让我一步步的带领大家快速的进行构建。
借助 VectorstoreIndexCreator 直接进行查询
导入模型
首先第一步也是最关键的一步就是要把我们需要的大模型以及嵌入模型。这里我们还是选用的是ChatTongyi 这个大模型,并且使用同样是阿里云打造的DashScopeEmbeddings() 作为我们的向量模型。由于两者是同一个企业的,因此我们也只需要用同一个api_key即可。
import os
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_community.embeddings import DashScopeEmbeddings
# 设置 API 密钥(输入自己的api_key)
os.environ["DASHSCOPE_API_KEY"] = 'YOUR_API_KEY'
# 初始化通义千问模型
llm = ChatTongyi()
embeddings = DashScopeEmbeddings()
导入数据
下面我们就需要把文档作为背景数据库传入到langchain的loader之中。在 Langchain 中,loader 是一个非常重要的概念,主要用于 数据加载 和 数据预处理。它负责从不同的数据源(如文件、数据库、Web 页面等)加载数据并进行初步的处理,以便后续的文本处理、向量化、嵌入或其他任务。比如说我们现在传入的是一个CSV文件,因此用的也就是langchain中的CSVLoader,假如是其他类型的文件,比如PDF文件可能就会用到我们的PyMuPDFLoader。
from langchain_community.document_loaders import CSVLoader
# 确保文件的路径准确无误
file = 'D:\langchain\llm_development\商品详情.csv'
loader = CSVLoader(
file_path=file,
encoding='utf-8' # 备选方案:使用 latin-1 编码
)
构建向量数据库索引
再然后我们就需要使用 Langchain 的工具将数据加载器(loader)中加载的数据通过嵌入(embeddings)转化为向量,然后存储到一个内存中的向量存储(DocArrayInMemorySearch)中。
VectorstoreIndexCreator 是 Langchain 提供的一个类,专门用于创建一个向量数据库索引。它将数据加载器中提取的文本数据通过嵌入模型转化为向量,然后将这些向量存储到一个向量数据库中(也就是下面介绍的DocArrayInMemorySearch),以便后续进行高效的相似度搜索或查询。
DocArrayInMemorySearch 是 一个内存型向量存储。它通过 DocArray(一个支持高效向量化操作的数据结构)来管理和查询向量数据。因为它是一个内存中的存储,所以适合处理较小规模的索引数据。在数据量较大时,我们可能需要使用更具持久化能力的存储解决方案,如 FAISS 或 Pinecone 等。
from langchain.indexes import VectorstoreIndexCreator
from langchain_community.vectorstores import DocArrayInMemorySearch
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch,
embedding=embeddings
).from_loaders([loader])
基于向量数据库完成对话
然后我们就可以基于这里面有的数据完成对话了,比如说我就问一下这个里面有哪些商品。然后通过VectorstoreIndexCreator 创建好的index来将问题和我们创建的llm连接起来。
query ="请问这里有哪些商品?"
response = index.query(query,
llm = llm)
print(response)
最后我们就可以发现其真的读取了里面的数据内容完成了问答。
这里的商品包括:
1. 男女运动休闲鞋
2. EcoFlex 3L 防水裤
3. 女士 Campside 牛津鞋
4. 婴儿女孩 Coastal Chill 游泳衣(两件式)
当然其实这个只是一个案例,我们只有放入更多的数据才能展示出这个向量数据库的价值。原课程案例里有大量的数据,但是由于课程的局限我这里就只选择几条并翻译成中文内容。
我们可以看到终端显示出了这个报错,但是大家可以忽略这部分内容的,并不会影响我们的具体使用。
C:\Users\76391\anaconda3\envs\Langchain_Learning\lib\site-packages\pydantic\_migration.py:283: UserWarning: `pydantic.error_wrappers:ValidationError` has been moved to `pydantic:ValidationError`.
warnings.warn(f'`{import_path}` has been moved to `{new_location}`.')
完整代码如下所示:
import os
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_community.document_loaders import CSVLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain_community.vectorstores import DocArrayInMemorySearch
from langchain_community.embeddings import DashScopeEmbeddings
# 设置 API 密钥
os.environ["DASHSCOPE_API_KEY"] = 'YOUR_API_KEY'
# 初始化通义千问模型
llm = ChatTongyi()
embeddings = DashScopeEmbeddings()
file = 'D:\langchain\llm_development\商品详情.csv'
loader = CSVLoader(
file_path=file,
encoding='utf-8'# 备选方案:使用 latin-1 编码
)
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch,
embedding=embeddings
).from_loaders([loader])
query ="请问这里有哪些商品?"
response = index.query(query,
llm = llm)
print(response)
借助RetrievalQA链完成系统的快速构建
在上面代码的基础上,我们也可以通过RetrivalQA的方式完成系统的快速搭建。两者其实十分类似,只是在数据库搭建的过程可能会复杂一些。
文件及模型导入
首先第一步我们还是需要把大模型和向量数据库进行导入,并将文件也进行导入。
import os
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_community.document_loaders import CSVLoader
from langchain_community.embeddings import DashScopeEmbeddings
# 设置 API 密钥
os.environ["DASHSCOPE_API_KEY"] = 'YOUR_API_KEY'# 设置 DashScope API 密钥
# 初始化通义千问模型和嵌入模型
llm = ChatTongyi() # 初始化 ChatTongyi 模型
embeddings = DashScopeEmbeddings() # 初始化 DashScope 嵌入模型
# 加载商品数据
file = 'D:\langchain\llm_development\商品详情.csv'# 数据文件路径
loader = CSVLoader(
file_path=file, # 指定文件路径
encoding='utf-8'# 指定文件编码
)
生成向量数据库
在我们通过CSVLoader把文件载入进来,其实这个时候我们还不能直接使用这个文档。loader 是一个 加载器的实例,用于从某个数据源加载原始数据。它本身是一个工具,不会直接执行加载操作,而是通过调用其 load() 方法来实际加载数据。在load完以后,这个数据就可以进行正常的调用和查看了,比如说我们可以docs[0]来查看这里面第一条的数据。然后我们就可以把文档数据通过 embeddings 转换为向量,然后存储到一个 DocArrayInMemorySearch 类型的数据库db中。
# 加载数据
docs = loader.load() # 从文件加载数据,返回文档列表
# 将文档转换为向量并存入数据库
db = DocArrayInMemorySearch.from_documents(
docs, # 文档数据
embeddings # 使用嵌入模型将文档转为向量
)
比如说我们就可以通过相似度搜索的方式查看和问题最相关的内容是哪一部分。
query = "这里有哪些鞋子可以买呢?"
docs = db.similarity_search(query)
docs[0]
我们发现返回的内容就是和鞋子相关的内容。
page_content='商品名称: 男女运动休闲鞋
描述: 这款多功能、舒适的运动鞋,适合各类户外活动和日常穿着,采用透气网面和防水翻毛皮,提供舒适和耐用的体验。
尺寸与规格: 鞋垫采用EVA材料,鞋底使用TPU橡胶;适合各种活动。
特点: 防水透气,舒适设计,适合徒步、跑步等多种运动,特别适合户外使用。' metadata={'source': 'D:\\langchain\\llm_development\\商品详情.csv', 'row': 4}
检索器生成及RetrievalQA链构建
接下来我们将可以刚刚创建的向量数据库db转换为一个 retriever(检索器),使得可以基于查询向量在数据库中查找相似度高的文档。retriever 会将查询转换为向量,并与数据库中的向量进行比对,从而返回最相关的文档。
虽然看着db和retriever是一个东西,但是实际上retriever 封装了从数据库获取相关文档的复杂过程,可以直接返回查询相关的文档(或者文档片段)。它把查询过程变得更加简洁和高效。因此,通过 retriever,你可以直接与数据库进行交互,得到相关文档,之后将它们传递给大语言模型,完成类似问答、总结等任务。没有 retriever 的话,你就得手动处理如何从数据库中获取文档,这增加了复杂度。
# 将数据库转换为检索器
retriever = db.as_retriever()
最后我们就可以把llm和retriever串起来进行正常的对话啦!
# 创建一个 RetrievalQA 实例,通过 "stuff" 类型的链来处理查询。
qa_stuff = RetrievalQA.from_chain_type(
llm=llm, # 使用的语言模型(如 ChatGPT、通义千问等)
chain_type="stuff", # 链类型,"stuff" 指的是返回检索到的文档片段作为模型输入
retriever=retriever, # 使用的检索器,它将从数据库中获取相关的文档
verbose=True # 打开详细输出,便于调试
)
# 提出查询问题
query = "请问这里有哪些商品?"
# 使用创建好的 RetrievalQA 实例进行查询并获取响应
response = qa_stuff.invoke(query)
# 输出模型的响应结果
print(response)
这个时候所生成的结果如下所示:
> Entering new RetrievalQA chain...
> Finished chain.
{'query': '请问这里有哪些商品?', 'result': '这里的商品包括:\n\n1. 男女运动休闲鞋\n2. EcoFlex 3L 防水裤\n3. 女士 Campside 牛津鞋\n4. 婴儿女孩 Coastal Chill 游泳衣(两件式)'}
这样我们就完成一个RetrievalQA的搭设了,后续我们可以通过Gradio等前端界面进行正常的对话了!完整的代码如下所示:
import os
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_community.document_loaders import CSVLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain_community.vectorstores import DocArrayInMemorySearch
from langchain_community.embeddings import DashScopeEmbeddings
from langchain.chains import RetrievalQA
# 设置 API 密钥
os.environ["DASHSCOPE_API_KEY"] = 'YOUR_API_KEY'
# 初始化通义千问模型
llm = ChatTongyi()
embeddings = DashScopeEmbeddings()
file = 'D:\langchain\llm_development\商品详情.csv'
loader = CSVLoader(
file_path=file,
encoding='utf-8'# 备选方案:使用 latin-1 编码
)
# index = VectorstoreIndexCreator(
# vectorstore_cls=DocArrayInMemorySearch,
# embedding=embeddings
# ).from_loaders([loader])
# # query ="请问这里有哪些商品?"
# # response = index.query(query,
# # llm = llm)
# # print(response)
docs = loader.load()
db = DocArrayInMemorySearch.from_documents(
docs,
embeddings
)
# query = "这里有哪些鞋子可以买呢?"
# docs = db.similarity_search(query)
# print(docs[0])
retriever = db.as_retriever()
qa_stuff = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
verbose=True
)
query = "请问这里有哪些商品?"
response = qa_stuff.invoke(query)
print(response)
总结
在本节课中,我们通过使用 LangChain 快速构建了一个商品目录查询系统,并展示了如何利用 VectorstoreIndexCreator 和 RetrievalQA 来实现基于向量数据库的问答功能。相比之下,VectorstoreIndexCreator 更注重将文档数据加载后转化为向量并存储到内存数据库中,适合快速搭建小规模的查询系统;而 RetrievalQA 则通过结合检索器和语言模型,提供了更灵活的问答处理方式,能够基于实时检索结果生成更精准的回复。在下节课,我们将深入探讨如何评估模型输出的质量,了解不同模型的表现差异,并通过一些常见的评价指标来提升系统的有效性和可靠性。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









