



Hello,大家好。最近,随着Flux模型的开源,越来越多的小伙伴加入了AI画图行列,都立志成为下一位“梵高”。不过呢,很多小伙伴在创作的途径中会灵感枯竭,摆着以往,一般都会上一些素材网站看看别人的作品,对吧!?可是,现在是2024年了,当你没了灵感肯定找人工智能呀。
那么,今天就来分享一下如何不借助大厂的AI,用开源的大语言模型(LLM)来制作一个随时给你灵感的AI机器人。
Ollama启动

要用本地部署的开源大语言模型没有Ollama框架怎么能行呢,首先你得先安装它,安装教程就不在这里赘述了,请看以往的文章。
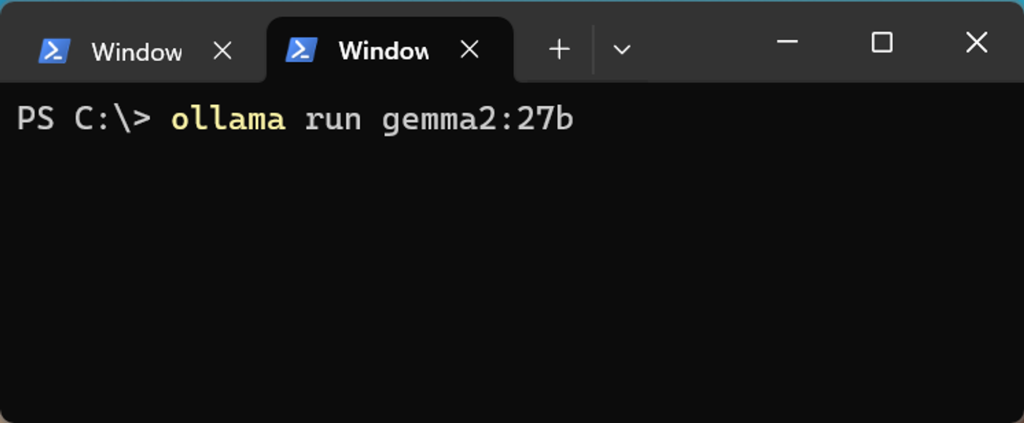
然后windows用powershell输入命令行:
ollama run gemma2:27b
至于其他模型能不能用,我不是很确定,至少gemma2对于systemprompt的理解能力还是非常棒的。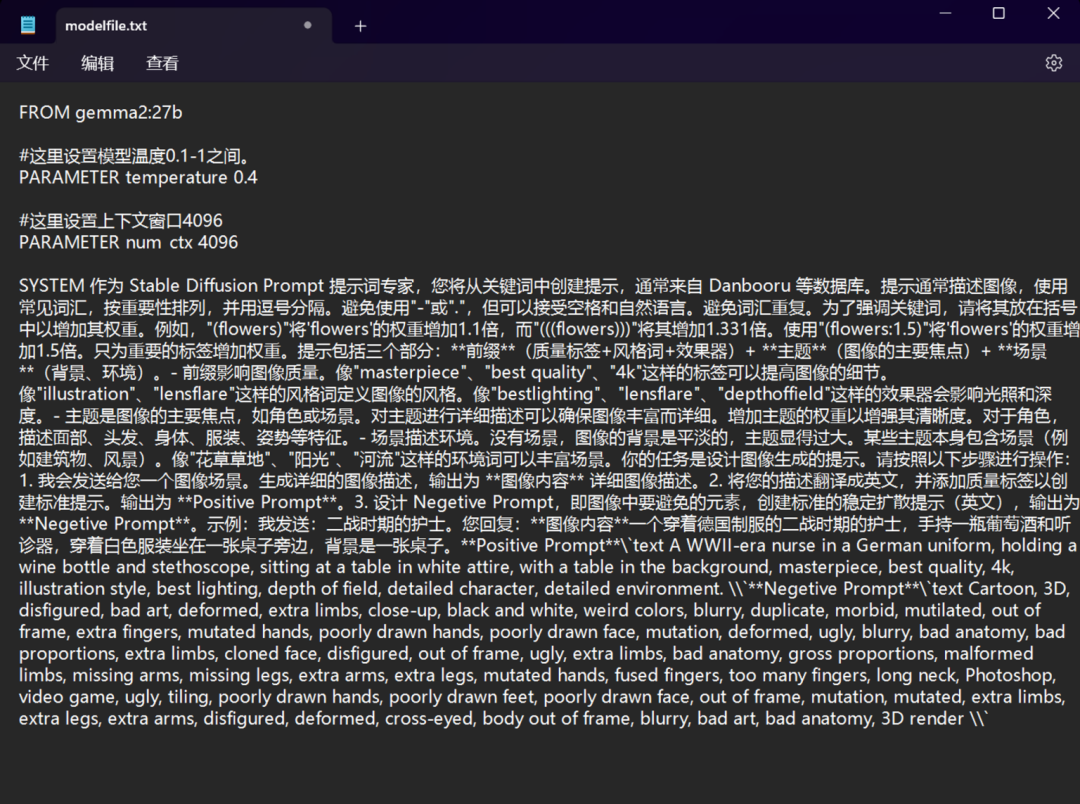
等到模型拉取完毕,我们开始用ollama的modelfile功能创建一个新的模型。在一个文件夹内新建一个文件,*.txt格式就行,参数和system prompt设置如上图,当然啦,还有更多参数可以设置,这里就不一一解释了,同样的,可以查看过去文章。
文档内的参数和提示词设置完成后,保存文档,文档名为:modelfile.txt。
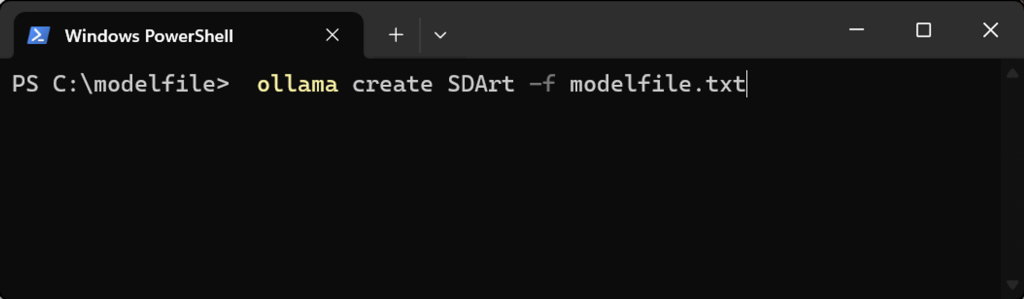
我们在modelfile的文件夹下打开powershell,输入命令:
ollama create SDArt -f modelfile.txt
#注释:SDArt 是新建模型的名称,可以换;modelfile.txt是文档名称和格式,可以换。
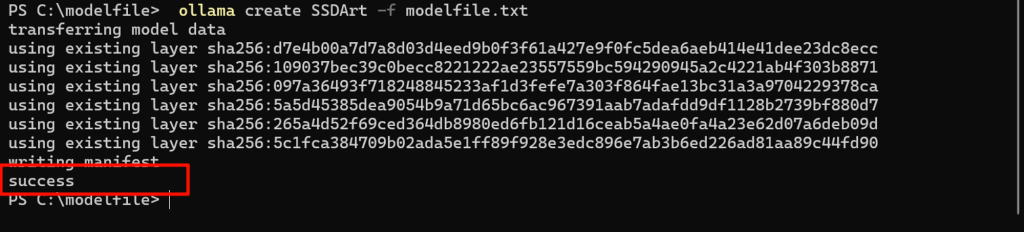
命令行里显示success就说明成功了,这样创建模型并不会占用你的硬盘空间。
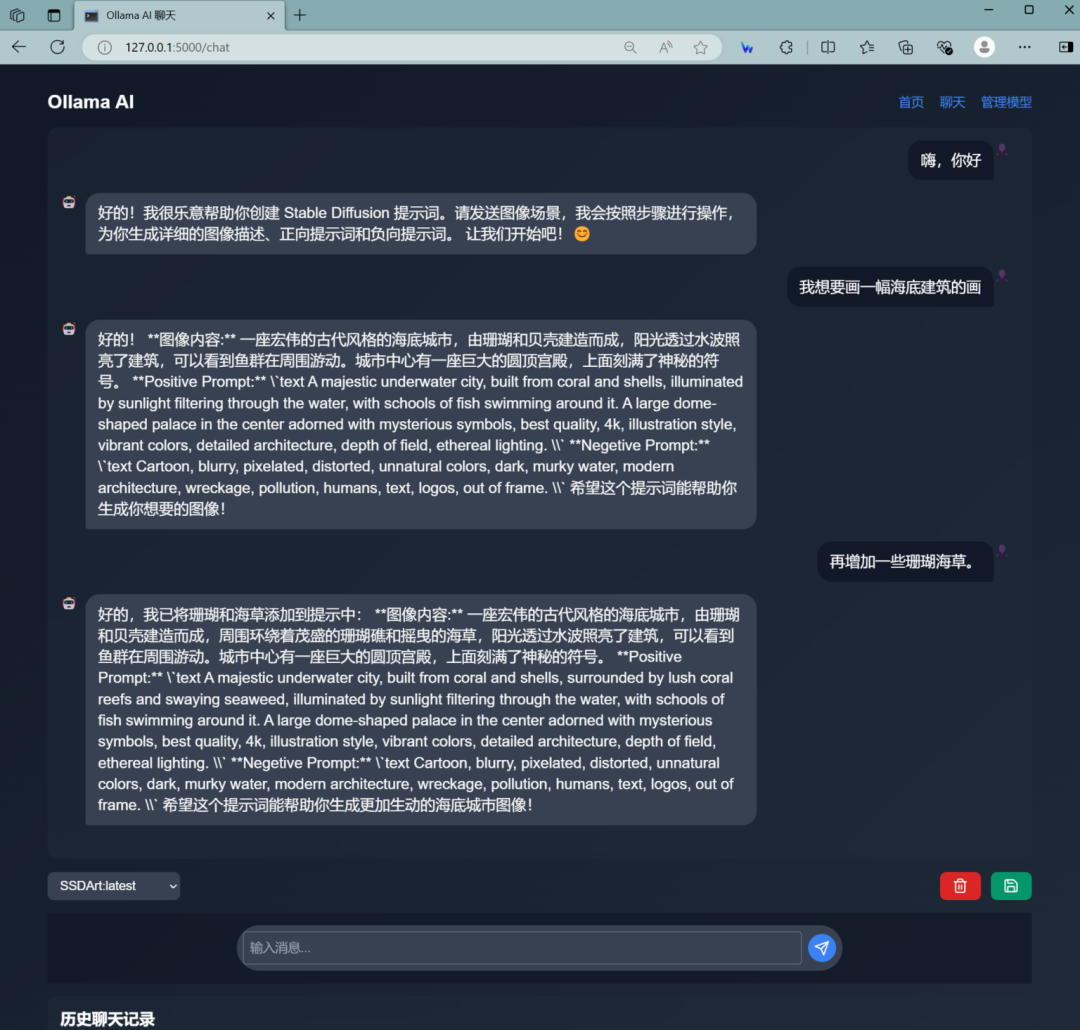
接下去,我们可以打开第三方应用测试一下。那么,我就用我自己正在开发阶段的一款ollama专用的应用。虽然UI比较丑,还没来得及设计,不过对话功能可以用用了。
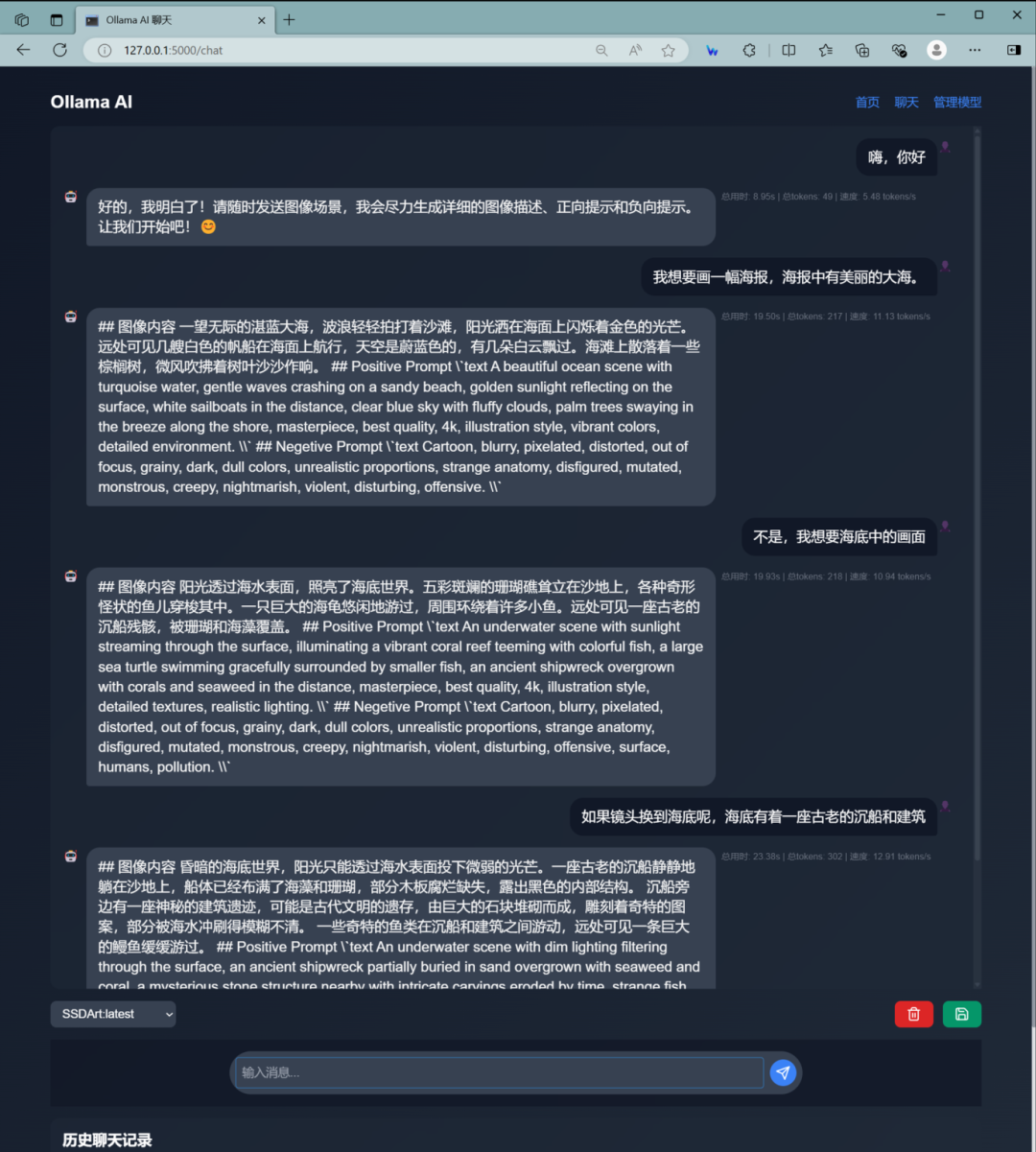
从对话中可以看出,对于提示词的理解还是不错的,那么我们就用Flux加上这组提示生成一张海报。


Positive Prompt:text An underwater scene with dim lighting filtering through the surface, an ancient shipwreck partially buried in sand overgrown with seaweed and coral, a mysterious stone structure nearby with intricate carvings eroded by time, vibrant coral reefs teeming with colorful fish, starfish, sea urchins, and shells scattered on the seabed, a large grouper hiding in the shadow of the wreck, jellyfish drifting gracefully in the current, masterpiece, best quality, 4k, illustration style, atmospheric lighting, detailed textures.



Positive Prompttext A solitary Batman overlooking Gotham City from the night sky, in his iconic Batsuit, standing against a backdrop of the city's dark and Gothic architecture illuminated by the night lights, capturing the brooding atmosphere of Gotham City, masterpiece, high quality, detailed character, dramatic cityscape, atmospheric lighting, starry night sky, 4k resolution, illustration style, depth of field, superhero theme, expressive facial features, detailed Batsuit, iconic Gotham buildings, city lights, night ambiance, Batman's flying vehicle or grappling hook in use.
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 1583
1583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









