




Transformer模型自2017年提出以来,通过自注意力机制彻底改变了序列建模领域。它通过并行计算每个位置的语义关联,打破了传统循环神经网络(RNN)的速度瓶颈,成为机器翻译、文本生成等任务的标杆。
然而,随着模型规模指数级增长,计算资源消耗与推理延迟问题日益凸显。这促使研究者探索更高效的架构,混合专家模型(MoE)应运而生。本文将从架构设计、工作原理、技术挑战三个维度,深入剖析Transformer与MoE的差异与演进逻辑。
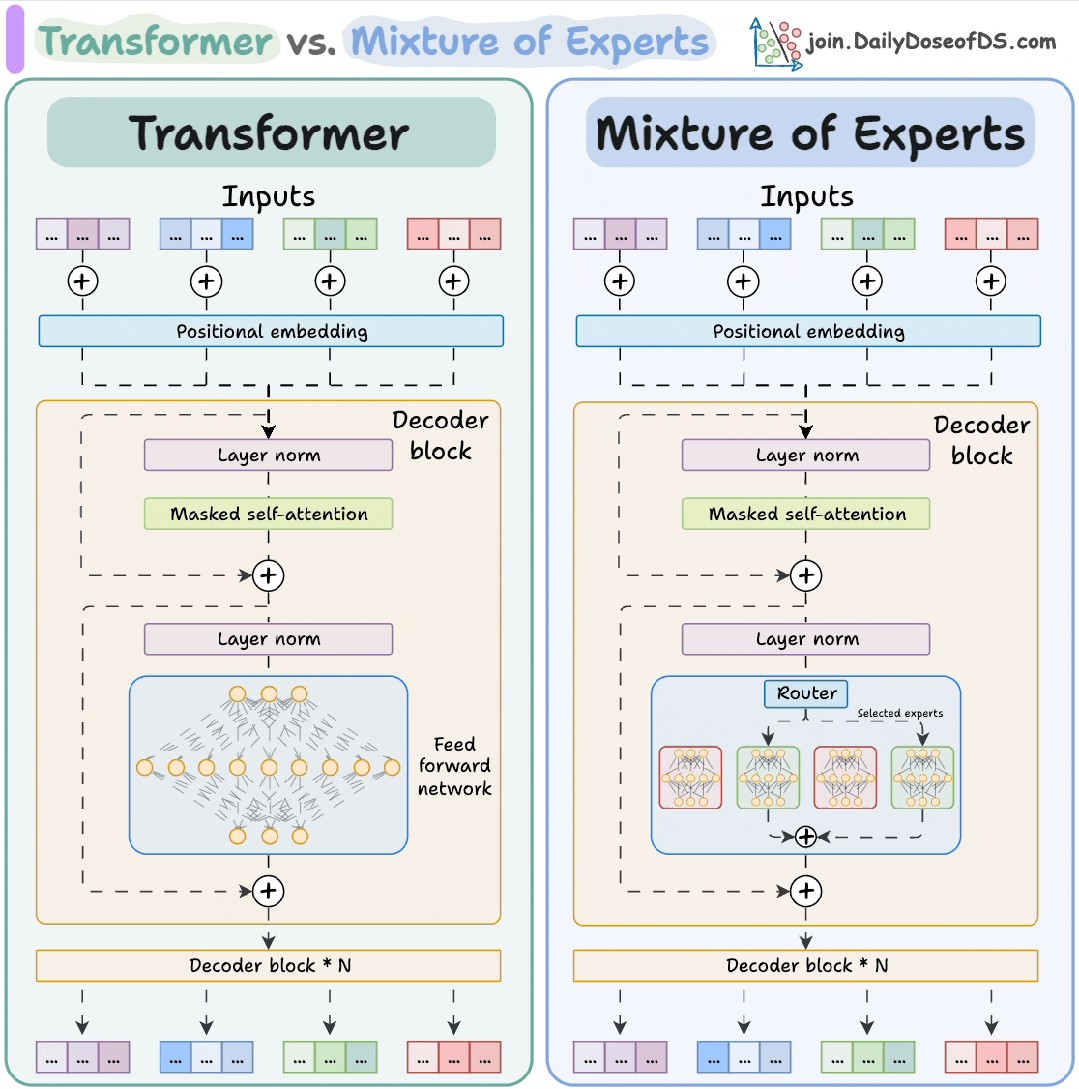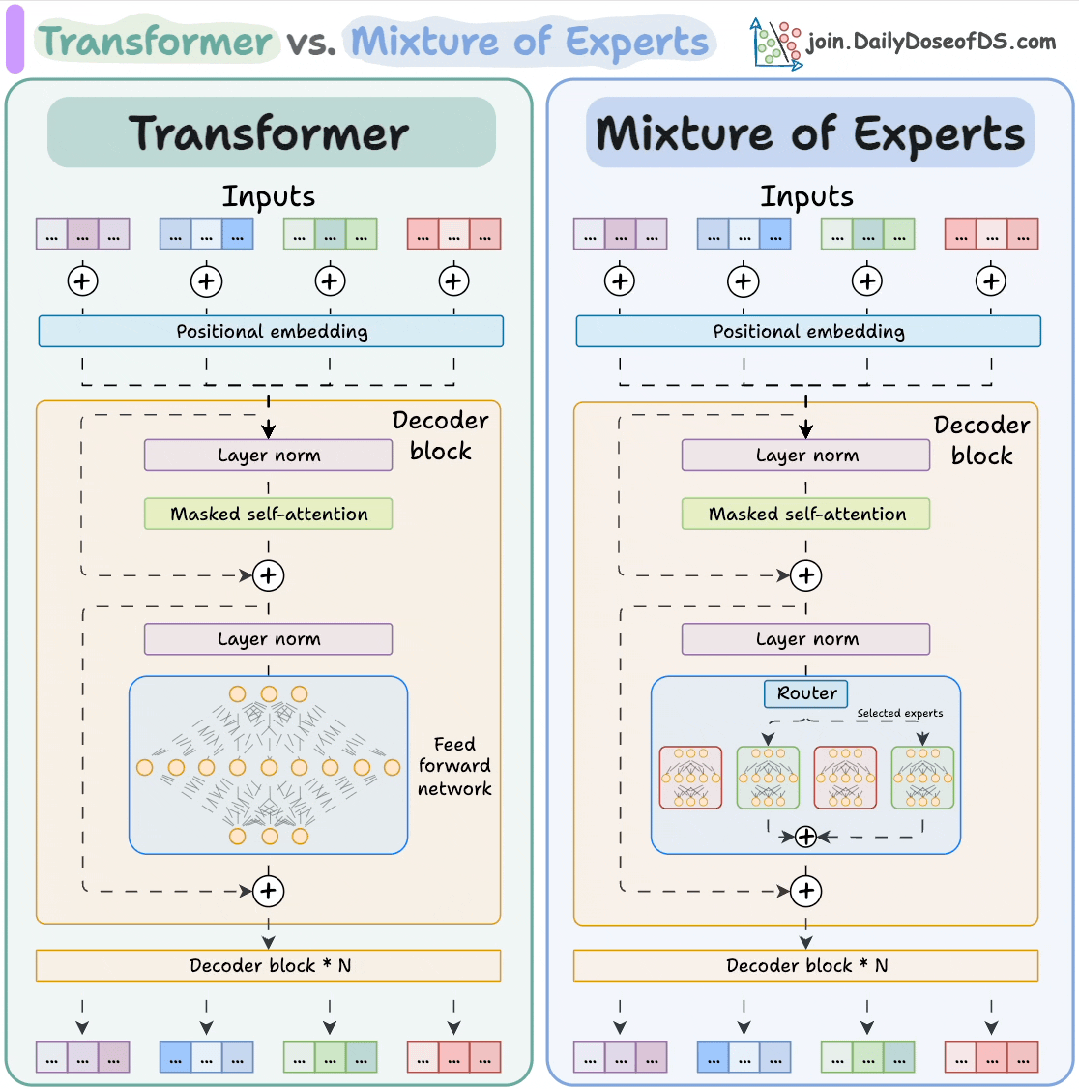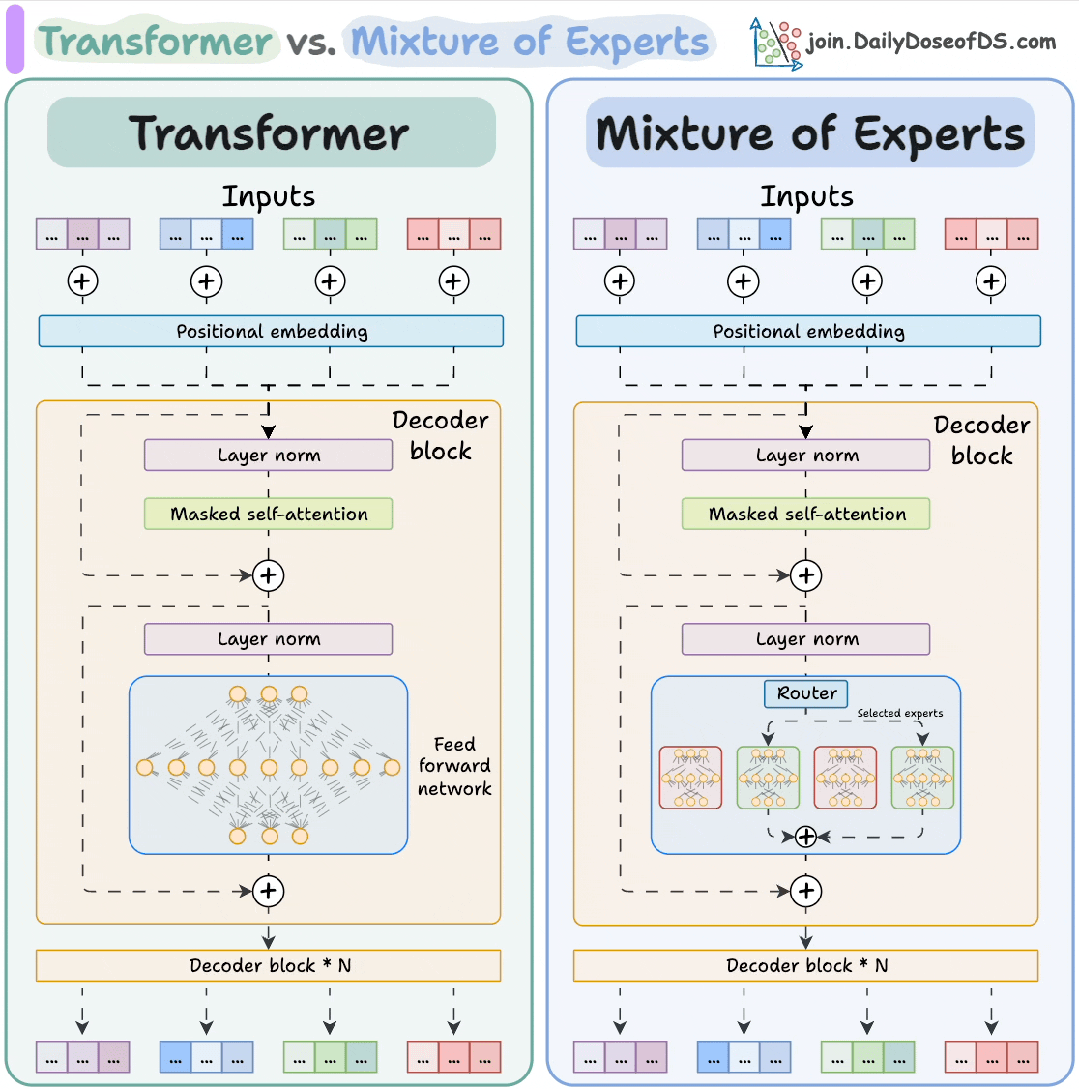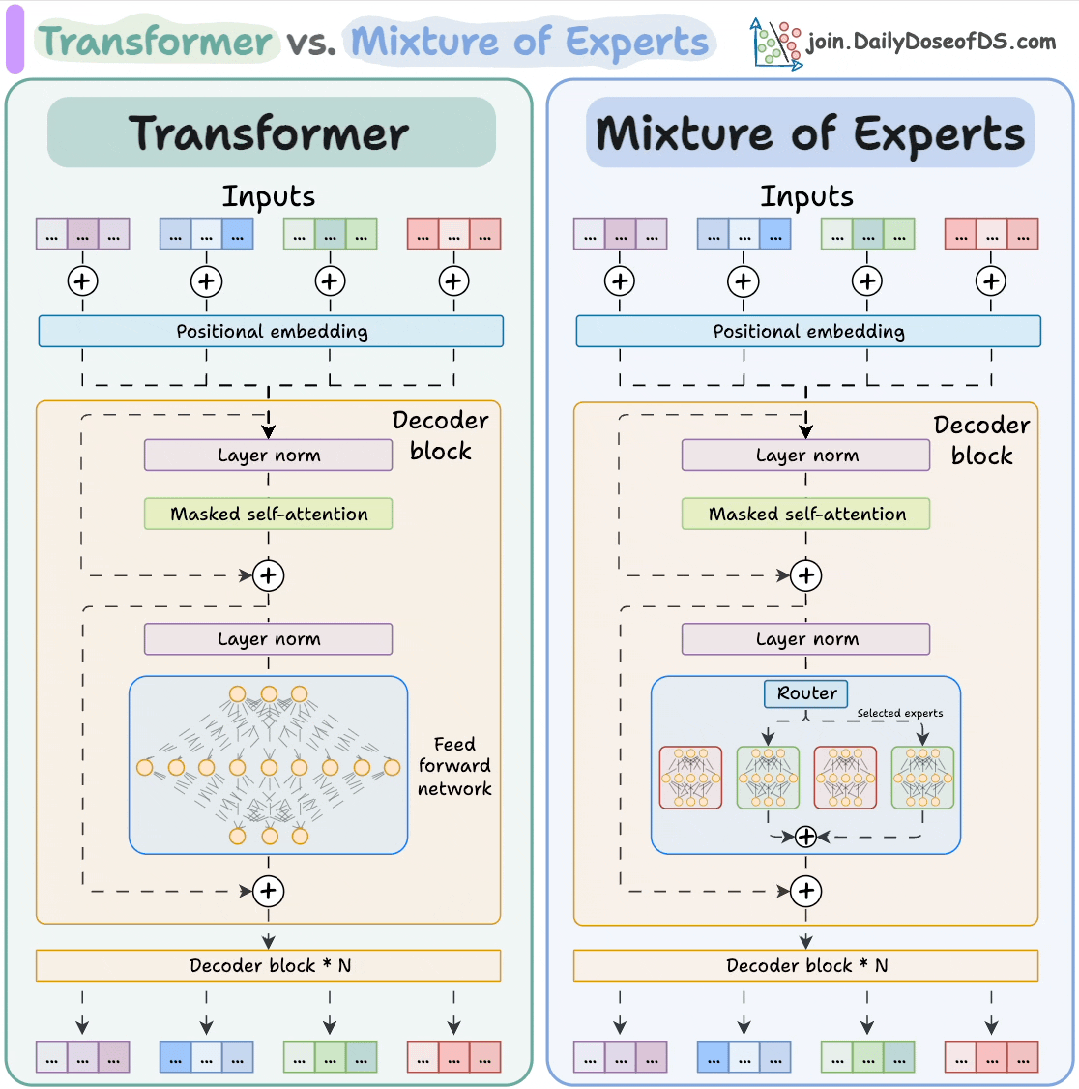
架构设计:从“全能选手”到"专家团队"
传统Transformer模型采用"编码器-解码器"堆叠结构,其核心计算单元是前馈神经网络(FFN)。每个FFN如同一个“全能选手”,无论输入何种任务都进行统一处理。这种设计在模型规模较小时表现高效,但随着模型规模膨胀,Transformer 逐渐暴露出两大短板:
- 计算成本随参数量呈指数级增长,训练和推理需要天价算力;
- 任务泛化与专业化能力失衡,出现 “什么都懂但什么都不精” 的 “万金油困境”。
MoE 的核心理念是 “分工协作”。它将 Transformer 的前馈网络替换为多个并行的 “专家” 网络,每个专家是更小的 FFN,专注于特定领域的特征提取,相当于组建了一支专业化的"智囊团"。例如处理"量子物理"问题时,物理专家主导;遇到"诗歌鉴赏"时则由文学专家牵头。
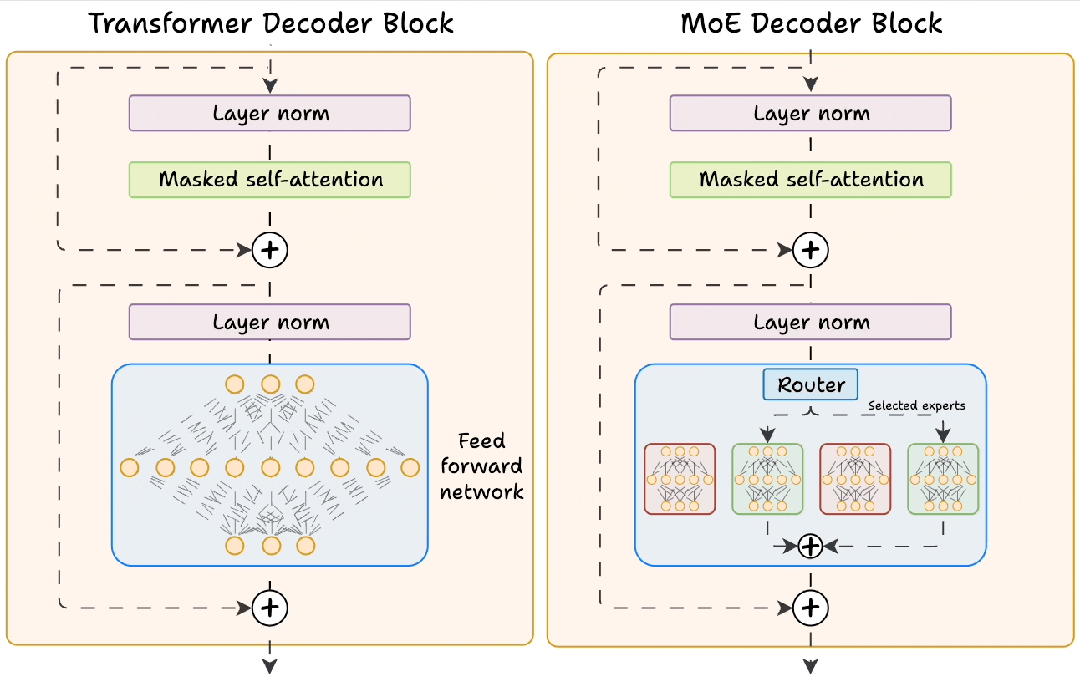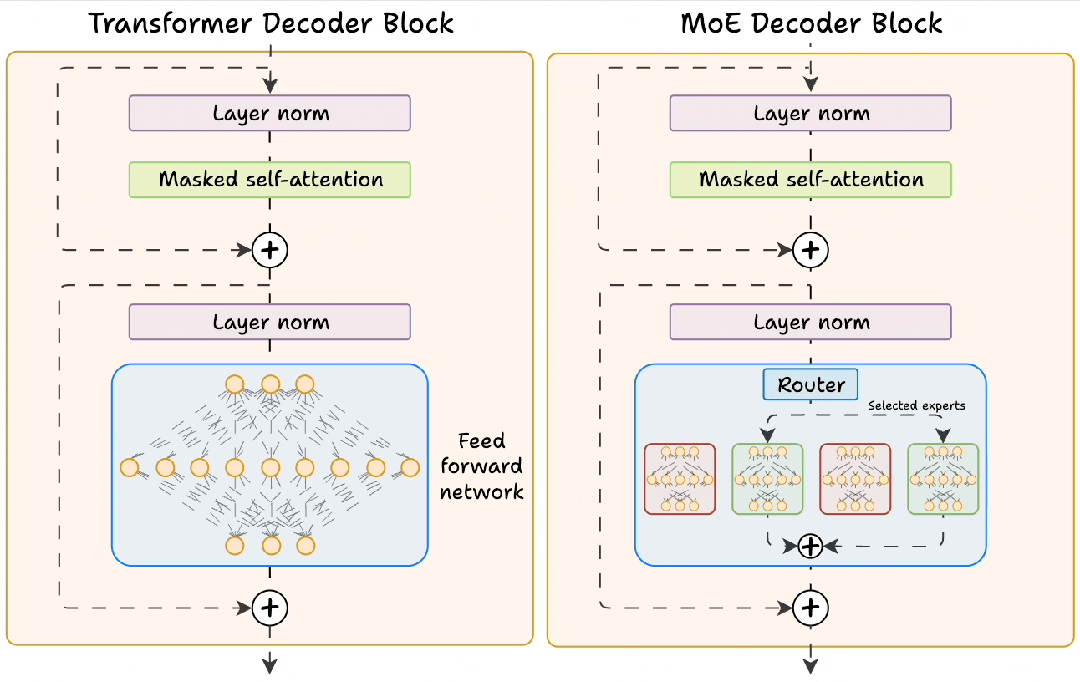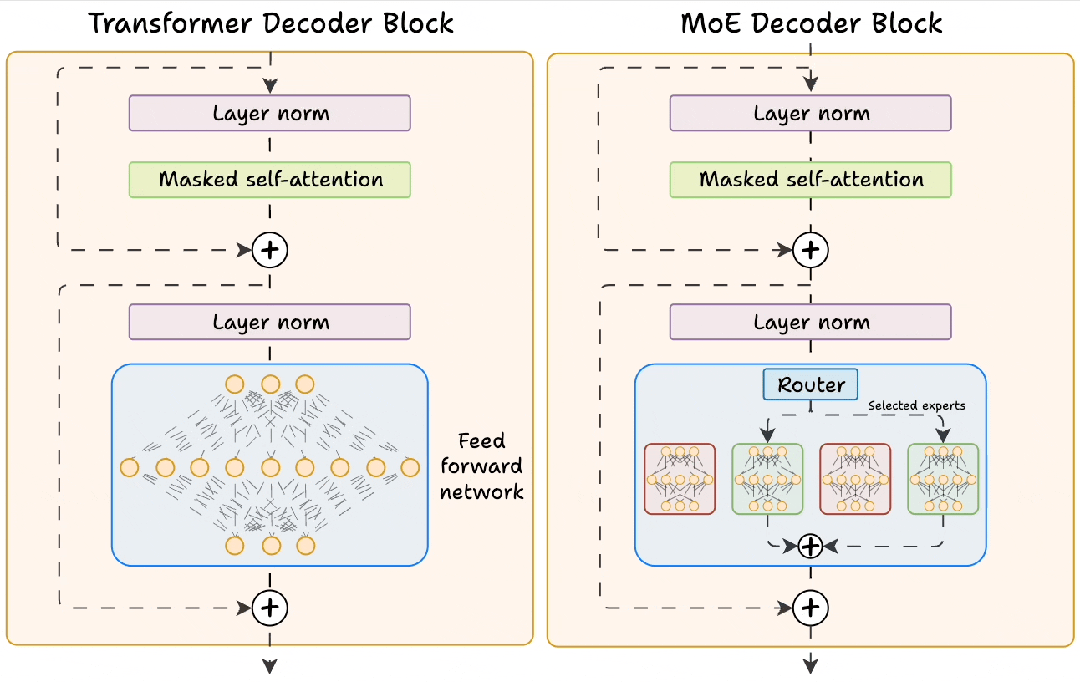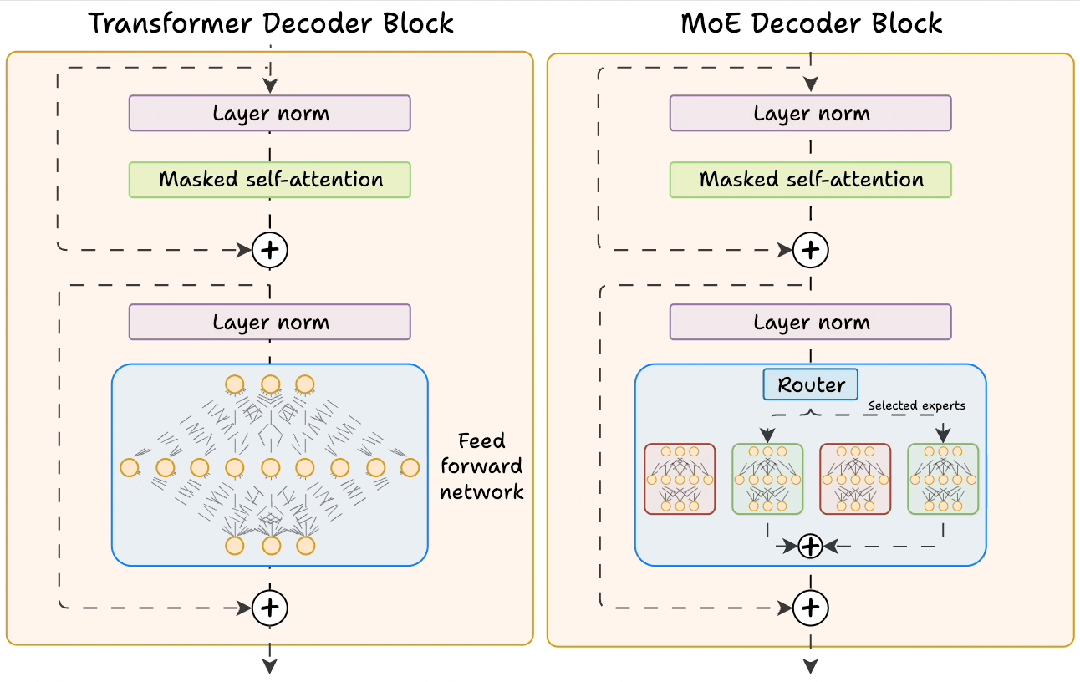
Transformer 和 MoE 解码器模块的区别
MoE 核心机制解析
动态路由:找最合适的 “专科医生”
当模型处理文本时,每个词(Token)就像带着不同 “病症” 的病人,而 MoE 的路由网络(Router)就像医院的 “导诊台”,负责把每个词分配给最擅长的 “专科专家”。
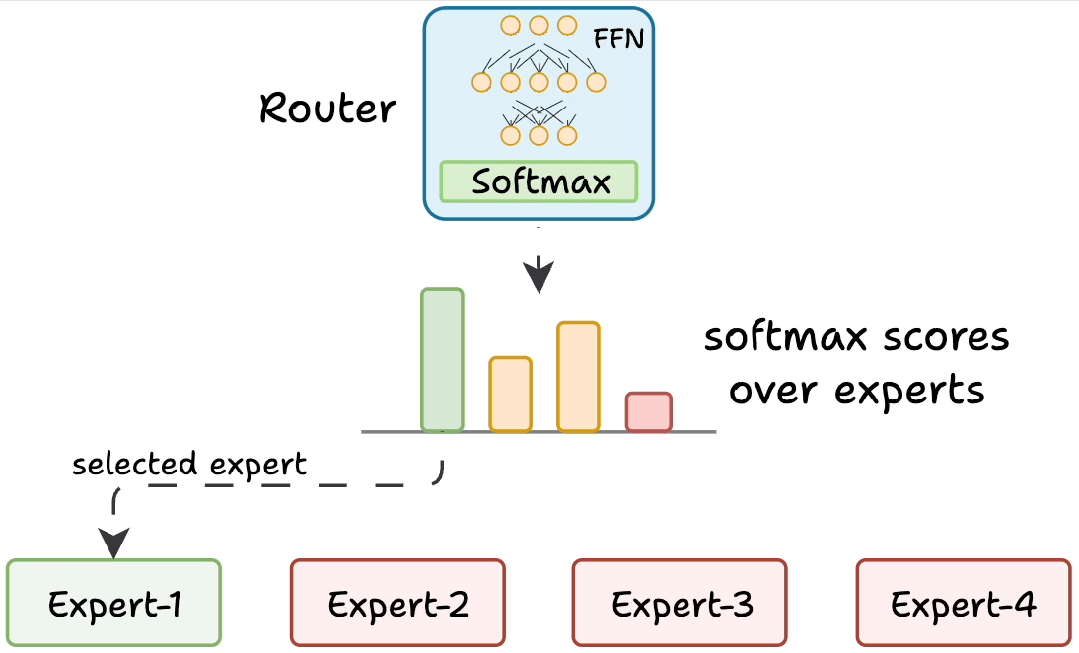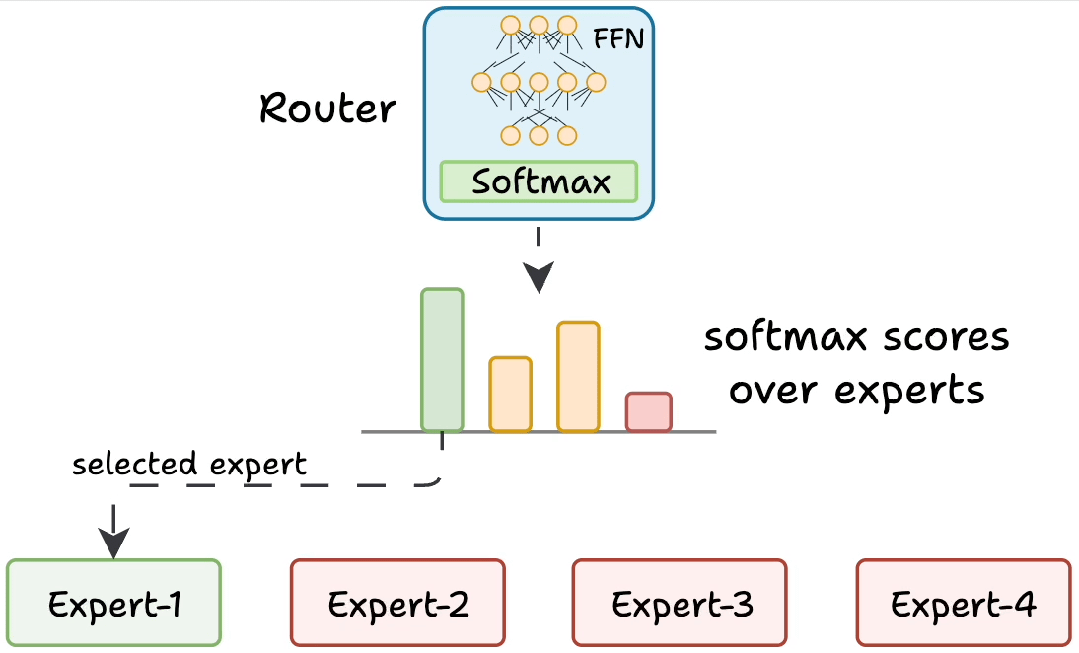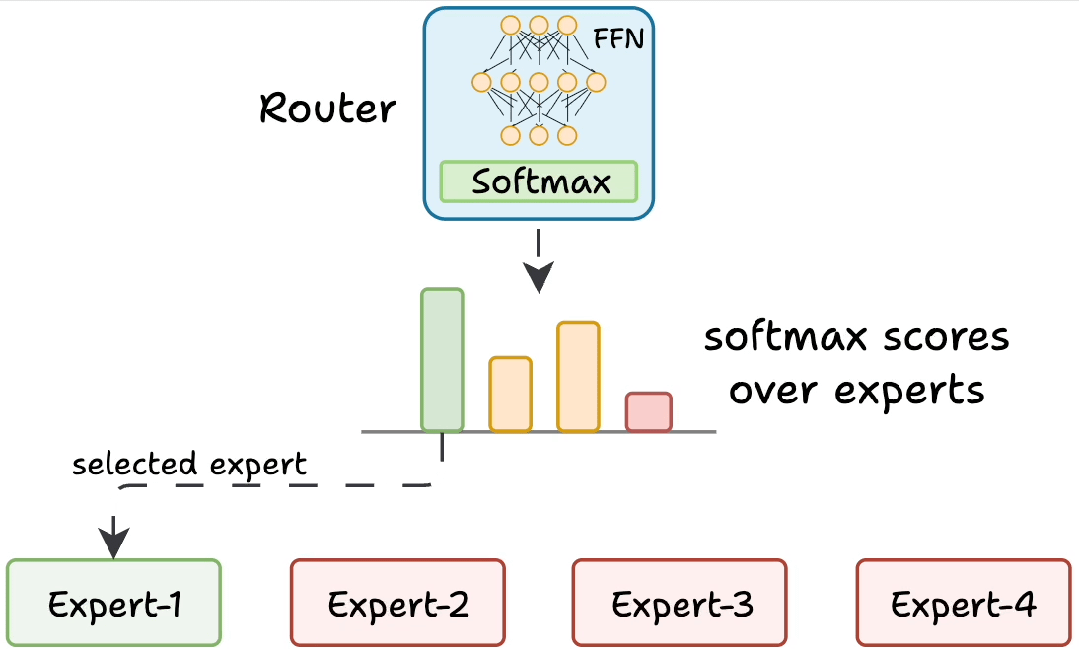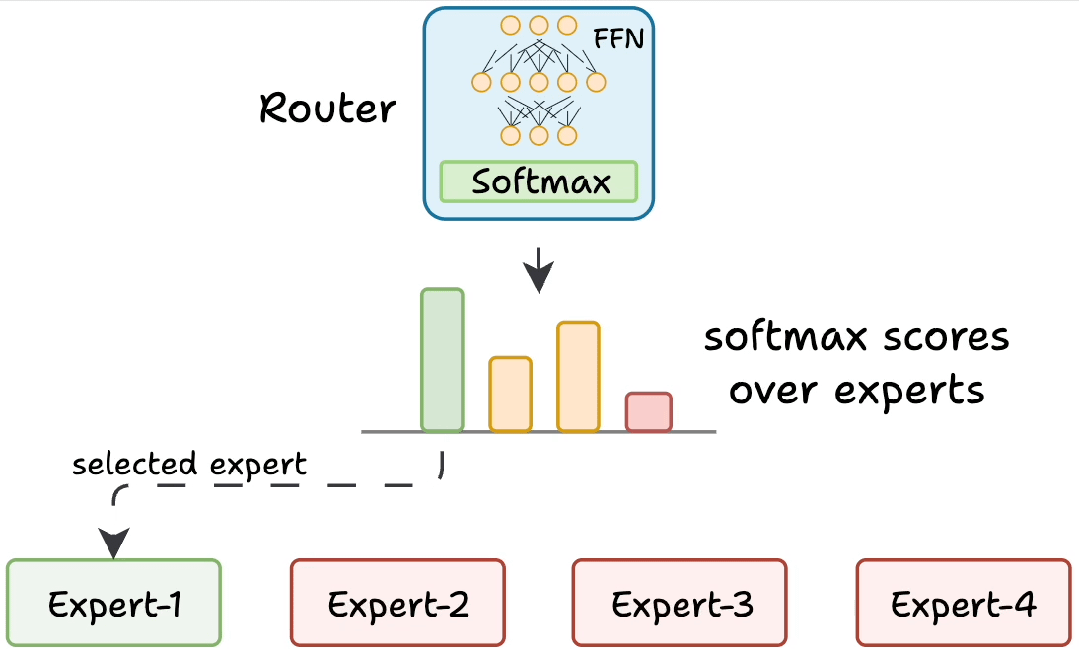
具体过程:
- 语义 “把脉”:路由网络先分析当前token的上下文,识别关键词、语法结构和上下文线索。例如,输入"苹果最新款手机发布"时,路由网络会捕捉到"手机""发布"等科技领域关键词,同时注意到"苹果"作为品牌的高频出现。
- 专家 “打分”:路由网络用类似考试打分的方式(softmax 函数),给每个专家打出 0-1 分的匹配度。比如擅长消费电子的专家A获得85分;专注水果分类的专家B获得10分;精通科技新闻的专家C获得90分。
- Top-K “挂号”:只选得分最高的 K 个专家(通常 K=2)参与计算。在这个案例中,专家A和C将组成"临时诊疗小组",而专家B则进入待命状态。
层间协同:多层 “专家团队” 接力解题
MoE 的解码器像一条 “专家流水线”,每层专家负责不同的 “解题步骤”,层层递进处理文本,举个🌰:
-
第一层:语法 “质检员”:专门检查句子结构是否正确。比如处理 “吃我苹果要洗” 时,第一层专家会先调整语序为 “我吃苹果要洗”。
-
第二层:语义 “翻译官”:理解词的真实含义。比如 “苹果” 在这一层会根据上下文确定是水果还是公司,避免歧义。
-
第三层:表达 “润色师”:让句子更自然流畅。比如把 “我洗苹果吃” 优化为 “我要把苹果洗干净再吃”。
-
第N层:xxxxxxxxx
最后,每层专家的处理结果会根据得分 “加权融合”,就像多个医生会诊后,按权威度给建议,得出最终方案。
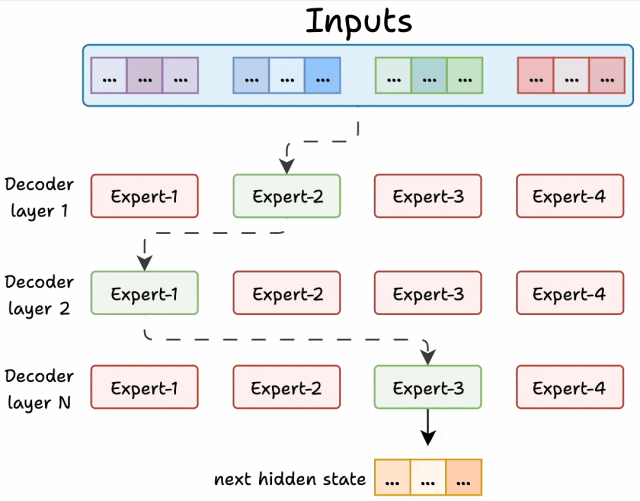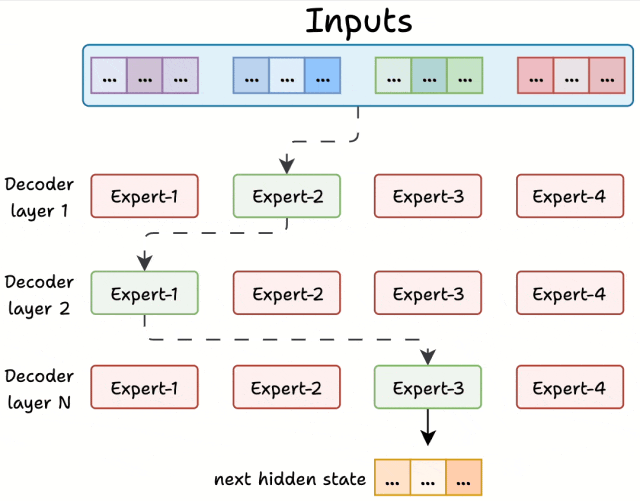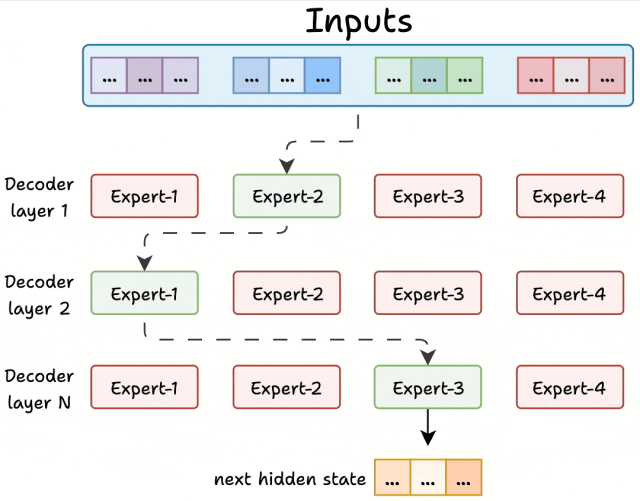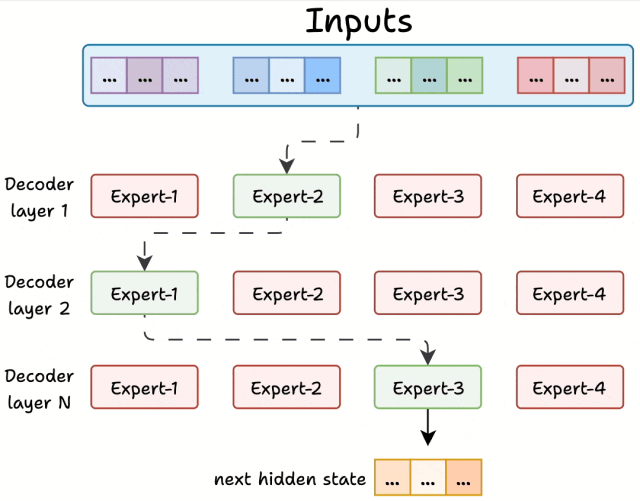
稀疏激活:用 “精兵简政” 让模型又快又省
虽然 MoE 总参数更多,但每次仅激活部分专家,推理速度比同规模 Transformer 快数倍。例如,DeepSeek 通过 MoE 架构将模型参数扩展至千亿级,同时降低 40% 能耗。
Transformer 就像 “全能老师”,每个词都要经过完整的计算流程。MoE 则是 “分科老师”,数学题找数学老师,语文题找语文老师,每次只让 2 个老师同时“工作”,其他老师 “休息”。比如 DeepSeek 的千亿参数 MoE 模型,实际计算量只相当于 120 亿参数的 Transformer,用更少的算力办更多的事,能耗自然省了 40%。
MoE 训练挑战与解决方案
MoE 的设计就像组建一支 “专家战队”,理论上每个专家各司其职能让模型又快又准。但实际训练时,就像老师带一群新学生,容易出现 “偏科” 和 “忙闲不均” 的问题,需要巧妙设计机制来解决。
挑战 1:专家训练不均衡(马太效应)
训练刚开始时,所有专家能力相似。路由网络分配任务时(比如处理 “苹果” 这个词),可能随机选中 “专家 2”。随着 “专家 2” 频繁处理类似任务,能力快速提升,路由网络下次打分时,它的得分会更高,形成 “选中→变强→再选中” 恶性循环,其他专家逐渐闲置。
假设模型有 8 个专家,训练 10 轮后,可能有 5 个专家从未被选中,剩下 3 个中还有 1 个处理了 70% 的任务。这会导致模型 “偏食”,只会处理某类问题,遇到新领域就抓瞎(比如让 “水果专家” 一直练,突然遇到 “苹果公司” 就不会处理了)。
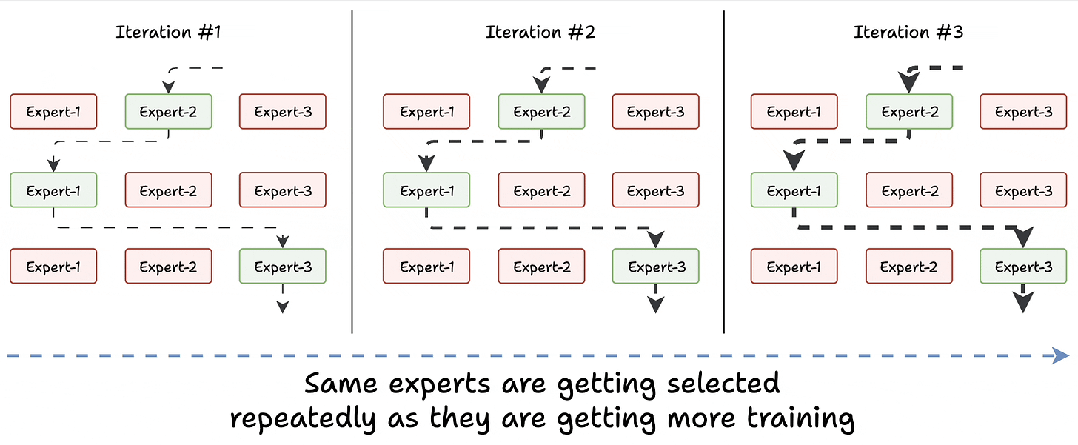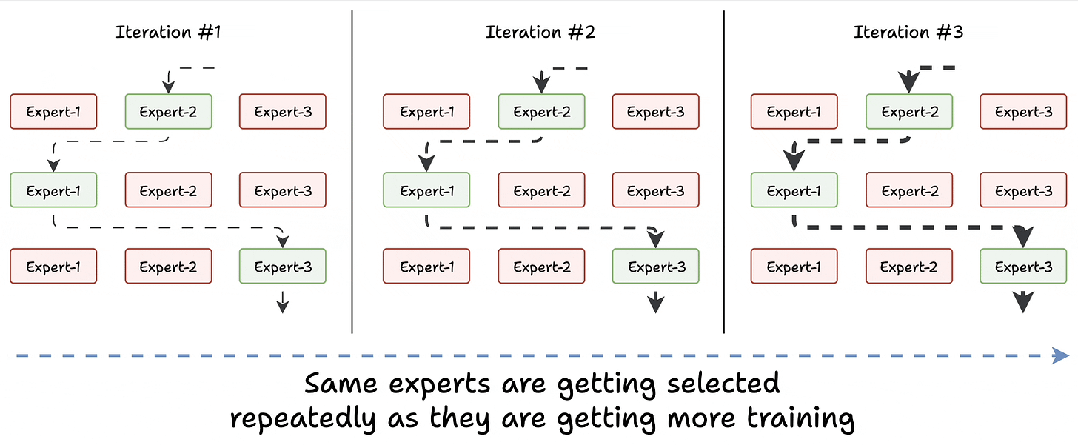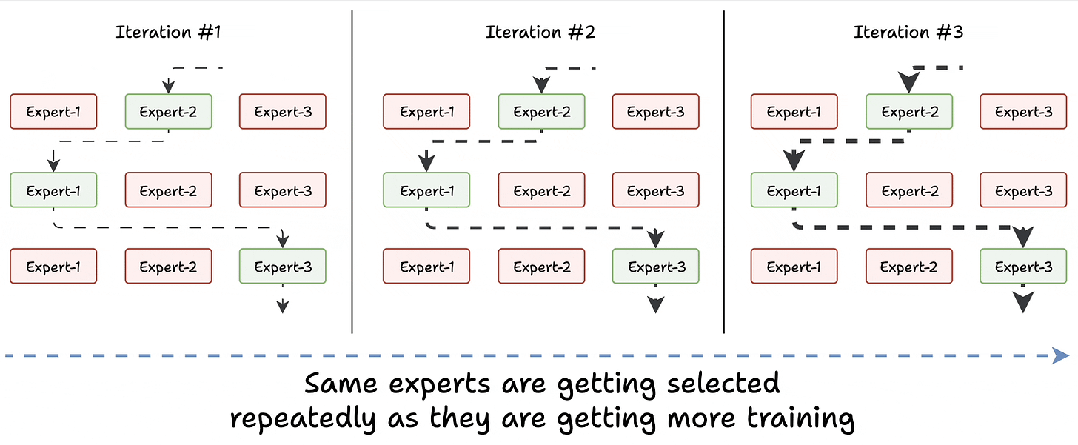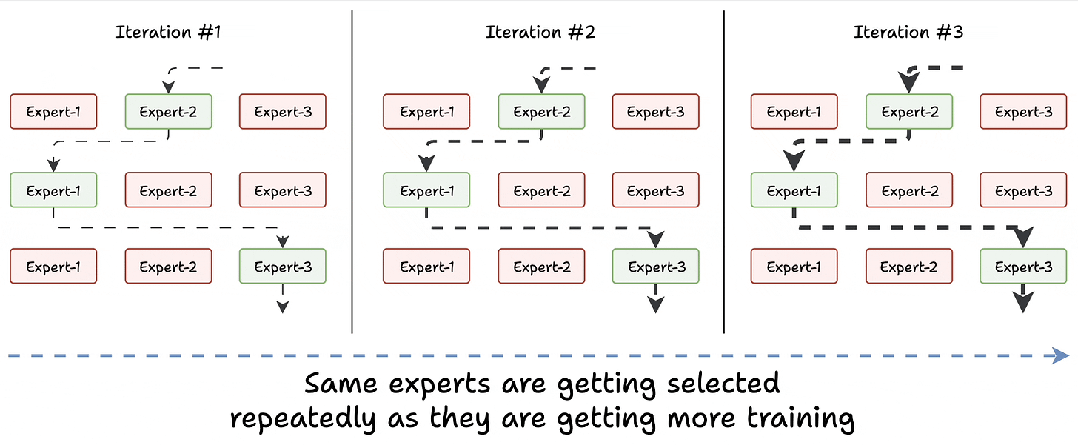
解决方案:打破垄断,强制 “轮流上岗”
- 噪声注入(给 “学霸” 的试卷加点 “干扰项”):路由器网络打分时(logits),故意给高分专家的分数加 “随机噪声”(比如学霸考了 95 分,随机减 5-10 分,其他人考了 80 分,随机加 3-5 分)。降低优势专家的得分,让其他专家有机会被选中。
- Top-K 屏蔽(只给前 K 名 “参赛资格”):不管有多少专家,只保留得分最高的 K 个(通常 K=2),其他专家的分数直接 “拉黑”(设为负无穷)。这样即使某个专家很强,也必须和第 2 名的专家 “共享任务”,防止垄断,确保训练机会分配更公平。
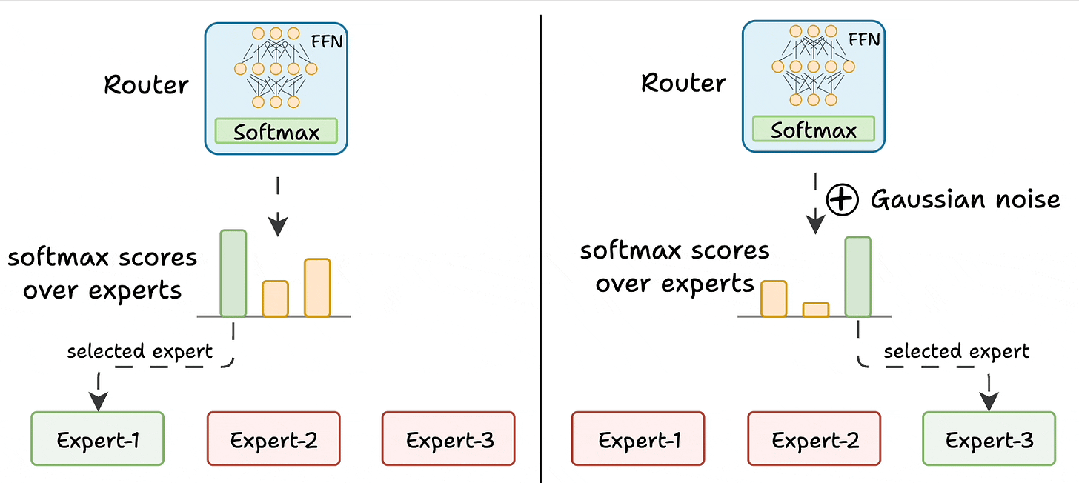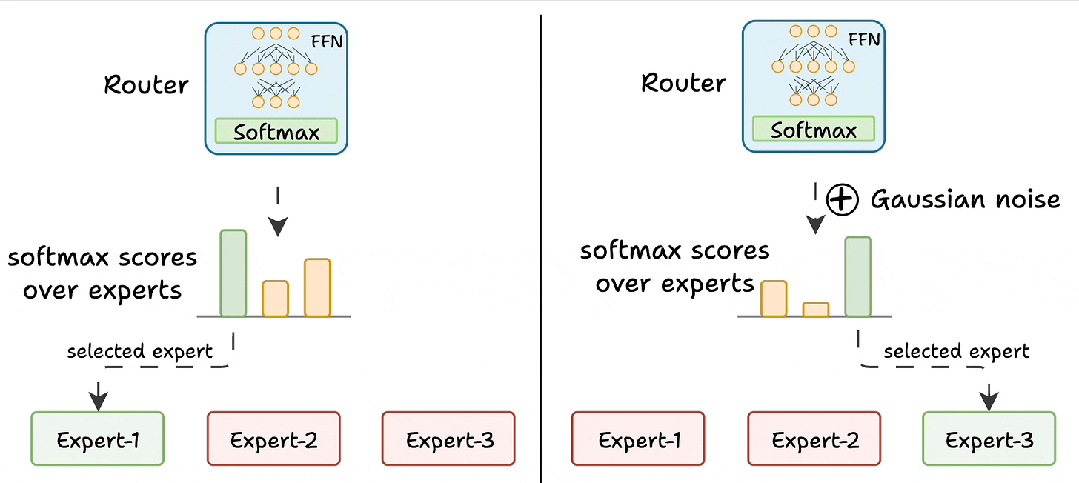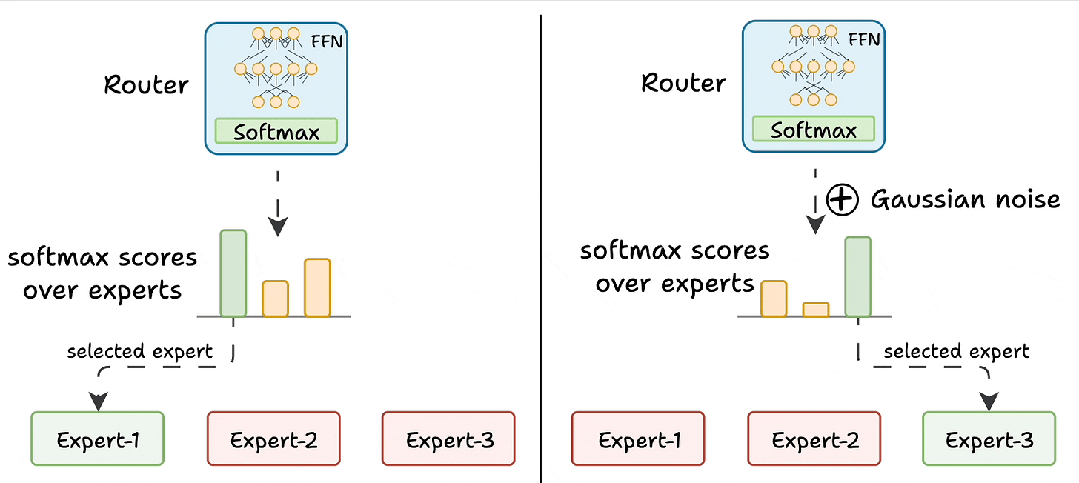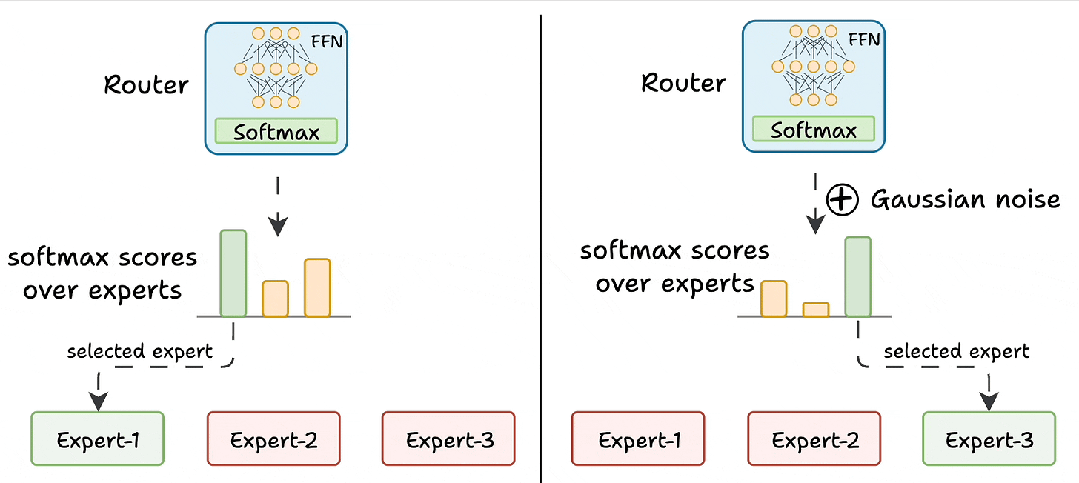
挑战 2:专家负载不均衡(忙闲不均)
即使解决了 “垄断” 问题,还可能出现 “能力强的专家被累死,能力弱的闲出病”。比如 “语法专家” 擅长处理复杂句子,所有长难句都被分配给它,导致它处理 70% 的 token,而 “情感专家” 只处理 30%。长期下来,“语法专家” 过度训练(可能过拟合),“情感专家” 训练不足(能力滞后)。
解决方案:双管齐下,强制平衡 “工作量”
- 容量限制(给每个专家设置 “任务配额”):给每个专家设定一个最大处理 token 数(比如每秒最多处理 1000 个)。当专家处理的 token 达到上限时,新任务会自动分配给下一个得分最高的专家。
- 辅助损失(用 “团队考核” 倒逼均衡):引入一个额外的 “负载均衡损失函数”,专门计算专家之间处理 token 数量的差异。假如某个专家比平均水平多处理 10%,就对模型 “扣分”(增加损失值),迫使路由网络调整分配策略,平衡训练负载。
这两大挑战的解决方案看似简单,却需要精细调校:
- 噪声注入强度太大容易让路由网络 “乱选”,太小无法打破垄断,就像老师给学霸的干扰要恰到好处,不能影响整体教学质量。
- 容量配额设定需要根据专家规模和任务复杂度动态调整,比如 8 个专家时配额设为总 token 的 20%,16 个专家时设为 10%,避免 “一刀切”。
通过这些机制,MoE 的训练过程从 “自由竞争” 变成 “有序协作”,这种平衡术正是 MoE 能在保持高效的同时,实现大规模参数扩展的关键,也让模型在面对千变万化的文本任务时,真正做到 “术业有专攻,团队有协作”。
结语
Transformer 与 MoE 的竞争,本质上是 “通用化” 与 “专业化” 的博弈。Transformer 以稳定性和成熟生态占据基础领域,而 MoE 通过稀疏激活和动态路由在效率与扩展性上展现出巨大潜力。从Transformer的"全能选手"到MoE的"专家联盟",架构的演进背后折射出的是AI领域对效率与性能平衡的不懈追求。
图片来源:ailydoseofds
参考链接:
https://www.dailydoseofds.com/p/transformer-vs-mixture-of-experts-in-llms/
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









