



本文带你从底层原理到实践操作,全面掌握AI智能体的构建之道。通过清晰的概念解析、实用的代码示例和丰富的实践技巧,无论你是AI新手还是有经验的开发者,都能学会如何设计、编排和安全运行一个真正的智能体。从理论到落地,一文助你开启AI智能体开发之旅,打造能解决问题的数字助手。
过去两年,“AI智能体(AI Agent)”这个词频频出现在各种会议和论文中。有人说它是“下一个操作系统”,有人说它将“重塑所有应用”。但在喧嚣背后,真正懂智能体逻辑的人却不多。
今天这篇文章,我们不讲空洞概念,而是带你从底层原理到落地实践,彻底弄清楚:
- 智能体到底是什么?
- 为什么现在是构建它的最好时机?
- 如何一步步设计、编排和安全运行一个Agent?
- 最后,我们还将用 LangGraph 框架写一个可直接运行的最小智能体示例。
一、什么是智能体(Agent)?
1. 核心定义
智能体(Agent)是一个能够代表用户,以高度独立性完成任务(Workflow) 的系统。它能理解用户目标,自主选择行动路径,并利用外部工具执行任务。
简单来说,它是“能帮你做事的AI”,而不仅仅是“能和你聊天的AI”。
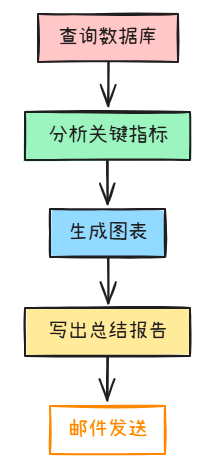
比如你告诉它“帮我分析最新销售数据,并生成周报”,它不会仅仅生成报告模板,而会:
1.查询数据库 → 2. 分析关键指标 → 3. 生成图表 → 4. 写出总结报告 → 5. 邮件发送。
这就是一个完整的 Agent工作流闭环。
2. 与传统LLM应用的区别
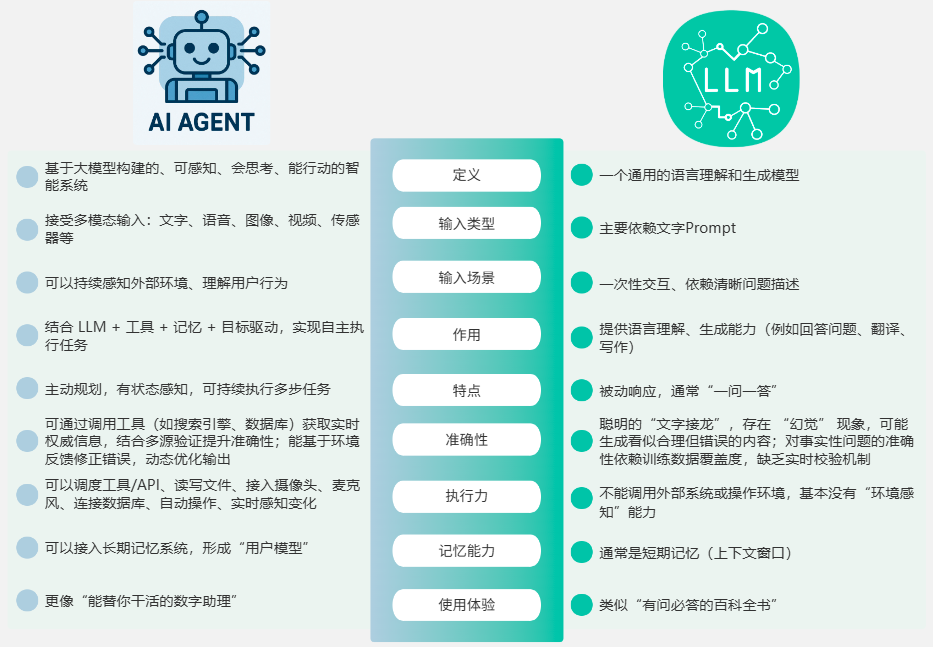
很多人把一个能回答问题的聊天机器人当成智能体,这其实是个误区。
智能体与普通LLM应用最大的区别在于:
| 项目 | 普通LLM应用 | 智能体(Agent) |
|---|---|---|
| 核心能力 | 生成文本回答 | 完成任务与执行工作流 |
| 决策方式 | 静态、被动响应 | 动态、主动决策 |
| 工具调用 | 通常无 | 可调用外部API、数据库、系统 |
| 状态管理 | 单轮 | 多轮、自主状态追踪 |
| 错误处理 | 无反馈 | 能主动识别并纠错 |
真正的Agent不仅会“说”,更会“做”。
3. 智能体的三大特征
(1)LLM驱动决策
智能体的“大脑”是LLM(如GPT、Claude、DeepSeek等),它会持续判断:
- 当前任务是否完成;
- 哪个工具最合适;
- 结果是否异常;
- 失败时是否应重试或终止。
(2)具备工具使用能力
它能访问数据库、API、文件系统、甚至调用其他Agent。
工具就像智能体的“手脚”,赋予它真正的行动力。
(3)运行在安全护栏之内
智能体在设计上必须有“边界”——确保不会调用危险API、不会泄露隐私数据,也不会乱执行高风险操作。
二、何时应该构建智能体?
一个非常实用的判断标准是:
如果问题可以用规则穷尽描述,就不要用Agent;如果问题充满模糊性和上下文判断,那就该考虑Agent。
典型场景举例:支付欺诈分析
传统规则引擎就像一份“条件清单”:
若金额>10,000 且 IP 异常 → 触发警报。
但智能体像一个经验丰富的调查员,它能结合交易时间、用户历史行为、语言描述等上下文因素做综合判断。即使数据没有明显异常,它也能感知出“可疑”的行为模式。
这种场景下,规则系统会“漏判”,而Agent能“察觉”。
三、智能体设计基础
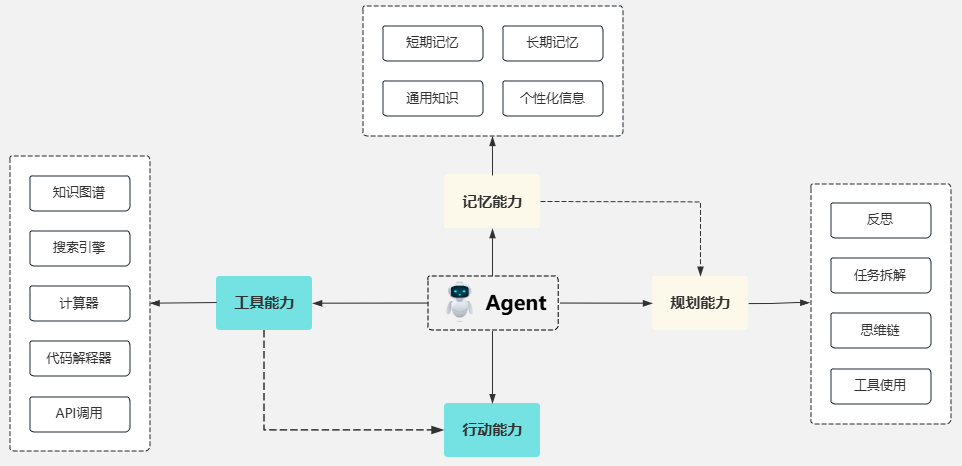
一个标准的Agent系统由三部分组成:
- 模型(Model):负责理解任务、推理与决策。
- 工具(Tools):让Agent能与外界交互(如数据库、API、文件系统)。
- 指令(Instructions):定义Agent该如何执行工作流。
我们先看一个结构化示例:
# 以LangGraph为例
from langgraph.graph import StateGraph, END
from langchain_community.llms import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
# 定义最小状态
class AgentState:
task: str
result: str | None
# 定义执行节点
def do_task(state: AgentState):
response = llm.invoke(f"帮我完成这个任务: {state.task}")
return AgentState(task=state.task, result=response.content)
# 构建智能体图
graph = StateGraph(AgentState)
graph.add_node("executor", do_task)
graph.set_entry_point("executor")
graph.add_edge("executor", END)
app = graph.compile()
# 测试运行
print(app.invoke(AgentState(task="生成一份销售周报")).result)
这就是一个最小可运行的智能体雏形:
你输入一个任务,它会自动调用大模型完成整个流程。
四、核心组件详解
1. 模型选择(Selecting your models)
智能体的核心是LLM,而不是盲目追求“最强模型”。
选择模型的关键在于平衡准确率、速度与成本:
- 原型阶段:先用顶级模型(如GPT-4、Claude 3)打样,验证逻辑;
- 优化阶段:用更小模型(如DeepSeek-R1、Qwen2.5)替代部分流程;
- 生产阶段:按任务类型动态调度不同模型。
实用建议:
- 对每类任务建立性能评估指标;
- 保证关键节点高质量;
- 用小模型优化边缘任务。
2. 定义工具(Defining Tools)
智能体真正的价值来自它能“动手”。
工具可分三类:
| 类型 | 作用 | 示例 |
|---|---|---|
| 数据工具 | 检索信息 | 数据库查询、PDF解析、网页搜索 |
| 行动工具 | 执行操作 | 发送邮件、更新CRM、生成报告 |
| 编排工具 | 控制流程 | 调用其他Agent,协同任务 |
最佳实践:
- 工具必须接口清晰、有文档、有测试;
- 输出格式要标准化;
- 工具可复用、可组合。
例如,我们定义一个工具来查询本地文件内容:
from langchain.tools import tool
@tool
def read_local_file(filename: str):
"""读取指定文件内容"""
with open(filename, 'r', encoding='utf-8') as f:
return f.read()
然后在智能体中调用:
content = read_local_file("sales_data.txt")
llm.invoke(f"请根据以下内容生成分析报告:\n{content}")
3. 配置指令(Configuring Instructions)
Prompt(提示词)是智能体的“行动指南”。
好的指令能让Agent变得“稳、准、懂边界”。
编写技巧:
- 从已有的业务文档或标准流程出发;
- 将复杂任务拆分为明确步骤;
- 明确定义每一步的输出;
- 考虑边缘场景与异常处理。
例如,生成财务报告的指令可以这样写:
instructions = """
你是一个财务分析智能体,目标是基于销售数据生成一份分析报告。
步骤:
1. 读取销售数据。
2. 提取关键指标(销售额、利润、成本)。
3. 识别趋势并分析原因。
4. 输出一份结构化报告(标题、摘要、图表建议、结论)。
"""
五、智能体的编排模式(Orchestration)
编排,就是智能体的“组织架构”。
1. 单智能体系统(Single-agent system)
最基础的形态:一个Agent、多个工具,在循环中执行任务。
优点:
- 简单;
- 易维护;
- 适合小规模自动化。
典型代码:
while not task_done:
next_action = llm.invoke(f"当前任务状态:{state},下一步应该执行什么?")
execute_tool(next_action)
2. 多智能体系统(Multi-agent system)
当任务过于复杂,就需要“团队作战”。
两种模式:
(1)管理者模式(Manager Pattern)
一个中央智能体(Manager)统筹多个子智能体。
比如:翻译Agent、分析Agent、报告Agent。
from langgraph.graph import StateGraph, END
def manager(state):
task_type = llm.invoke(f"请判断任务类型: {state.task}")
if "翻译" in task_type:
return AgentState(task="翻译", result=translator.invoke(state))
elif "分析" in task_type:
return AgentState(task="分析", result=analyzer.invoke(state))
else:
return AgentState(task=state.task, result="任务不匹配")
graph = StateGraph(AgentState)
graph.add_node("manager", manager)
graph.set_entry_point("manager")
graph.add_edge("manager", END)
(2)去中心化模式(Decentralized Pattern)
每个智能体都是独立节点,通过“移交(Handoff)”机制相互协作。
例如客服系统中,分流Agent判断问题类型后,将任务转交给售后或技术支持Agent。
六、护栏体系(Guardrails)
没有护栏的智能体,就像无人驾驶汽车没刹车。
护栏的作用是限制智能体的行为边界,确保安全、合规、稳定。
常见类型:
- 安全分类器:检测越狱、提示注入;
- PII过滤器:防止隐私泄露;
- 工具安全分级:限制高风险操作;
- 输出验证:确保生成内容合法;
- 人工干预触发器:在失败或高风险任务时让人类接管。
在LangGraph中,我们可以这样实现:
def pii_filter(output):
if "身份证" in output or "手机号" in output:
raise ValueError("检测到敏感信息,输出被拦截。")
return output
每次模型输出后执行该函数即可形成安全闭环。
七、总结
智能体的本质,不是聊天,而是行动。
它能在模糊场景中理解目标、做出判断、执行步骤、纠错反馈,最终帮人类完成工作。
构建智能体的正确路线图是:
- 打好三要素基础(模型、工具、指令);
- 选择适合的编排模式(单体或多体);
- 构建安全护栏;
- 小步迭代、持续验证。
未来每一个企业、每一个岗位,都会有属于自己的“数字助手”。
而理解今天的这些原理,就是你通向“AI工作流时代”的第一步。
随着大模型的持续爆火,各行各业都在开发搭建属于自己企业的私有化大模型,那么势必会需要大量大模型人才,同时也会带来大批量的岗位?“雷军曾说过:站在风口,猪都能飞起来”可以说现在大模型就是当下风口,是一个可以改变自身的机会,就看我们能不能抓住了。
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

以上的AI大模型学习资料,都已上传至优快云,需要的小伙伴可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1914
1914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









