




相信玩LLM的同学都已经听过Langchain这个框架了,LangChain-Chatchat (原Langchain-ChatGLM) :基于 ChatGLM 等大语言模型与 Langchain 等应用框架实现,开源、可离线部署的检索增强生成(RAG)大模型知识库项目。
通过langchain可以实现基于本地知识库的问答应用,langchain支持开源 LLM 与 Embedding 模型,可实现全部使用开源模型离线私有部署,对数据更加安全。也支持 OpenAI GPT API 的调用,可以作为网站或者APP的后端使用。如果自己电脑无法部署LLM模型也没关系,langchain也支持调用远程LLM,只要把相应LLM的key配置好即可。
实现原理
市面上绝大部分知识库都是 LangChain + LLM + embedding 这一套,实现原理如下,加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt 中 -> 提交给 LLM 生成回答。在这里,可以把LLM当成一个自然语言问答的引擎,能够针对知识库做定向的回答。如果用户的提问在知识库中找不到,就会调用LLM自身的回答。
在创建知识库文档的上传页面,可以看到LangChain几乎支持所有能承载内容的文件形式,包括图片。从office文档,到电子书,html网页,每个文档不大于200M即可。

安装流程
0.确认CUDA版本和显卡显存
如果本地部署LLM,我们要把CUDA升级到至少12.1的版本,同时显存越大越好,根据我的经验,至少16G,不然可能无法加载模型。
命令行下执行nvidia-smi,查看CUDA的版本
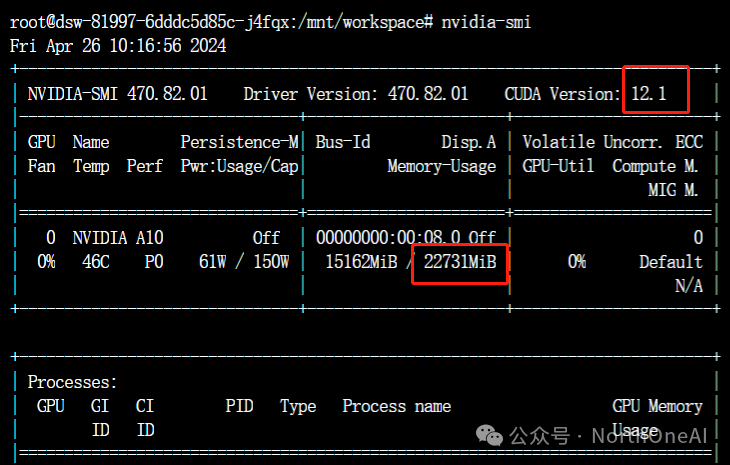
如果CUDA版本不够,升级CUDA,
登录英伟达官网,根据操作指引找到适合自己的驱动,更新CUDA,以下是我的乌班图22.04,A10显卡的更新包。大家找到自己的也是类似的。
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.0-1_all.deb
sudo dpkg -i cuda-keyring_1.0-1_all.deb
sudo apt-get update
sudo apt-get -y install cuda
CUDA升级完后在执行命令确认一下版本。
1.下载代码:
git clone https://kkgithub.com/chatchat-space/Langchain-Chatchat.git
git clone https://gitclone.com/github.com/chatchat-space/Langchain-Chatchat.git
当然也可以去github下载,但是因为访问问题,我这里直接放国内的镜像站,如果不想用git下载,文末有我上传网盘的地址可直接下载。
这2个镜像站推荐大家也收藏一下。
2.创建虚拟环境:

conda create --name myenv python=3.11.7
代码的readme里推荐用3.11.7,我们就装这个版本的虚拟环境。
3.激活虚拟环境,进入源代码根目录安装依赖
conda activate myenv
注意替换成自己的虚拟环境名字
然后cd到源代码的根目录,用pip安装依赖
先更新pip,这里都用阿里云的源
pip install -i https://mirrors.aliyun.com/pypi/simple --upgrade pip
下载依赖
pip install -i https://mirrors.aliyun.com/pypi/simple -r requirements.txt
pip install -i https://mirrors.aliyun.com/pypi/simple -r requirements_api.txt
pip install -i https://mirrors.aliyun.com/pypi/simple -r requirements_webui.txt
第一个比较费时间,后面2个会快一些,根据我的经验,如果下载速度100K/S左右,三个全部下载完大概需要1个多小时,第一个能占据80%的时间。
4.下载模型
这里我们本地部署,所以在进行第三步的同时,我们可以同时下载模型,这样更节省时间,需要2个模型,一个LLM模型,一个Embedding模型。
下载模型推荐魔塔:https://www.modelscope.cn/home
首先给git安装大文件下载支持
git lfs install
Embedding模型我们用text2vec-base-chinese,
下载地址:git-lfs clone https://www.modelscope.cn/Jerry0/text2vec-base-chinese.git
LLM模型我们选chatglm2-6b,当然也可以换别的。
下载地址:
git-lfs clone https://www.modelscope.cn/ZhipuAI/chatglm2-6b.git
这2个模型都下载好后,把它们放在一个目录里,目录地址没关系,不用和源代码放一个目录。
我是放在 /mnt/workspace/models/ 目录下的

5.复制配置文件
pip的依赖全部安装完后,可以执行这一步:
在源代码根目录下执行:
python copy_config_example.py
然后在根目录下会出现一个 config 目录,cd到这个目录里,稍微修改一下配置保存即可。
找到
MODEL_ROOT_PATH = “/mnt/workspace/models/”
这里配置一下模型根目录,我的就是 “/mnt/workspace/models/”
然后配置
EMBEDDING_MODEL = “text2vec-base-chinese”
再配置
LLM_MODELS = [“chatglm2-6b”, “zhipu-api”, “openai-api”]
最后配置MODEL_PATH,改成自己使用的,确保value和之前配置的path拼起来能找到模型即可。
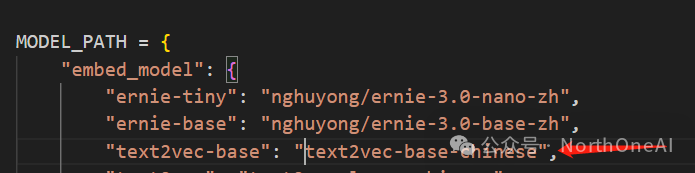
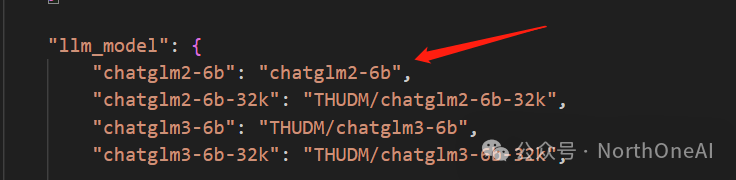
这样就配置好了。
6.启动
在源代码根目录执行
python startup.py --all-webui
注意这里是前台启动,远程访问要打开防火墙8501端口,出现下图就启动成功了,可以看到作为后台API服务器的地址,以及webui地址,我们在浏览器里用webui地址访问,本地就是localhost。
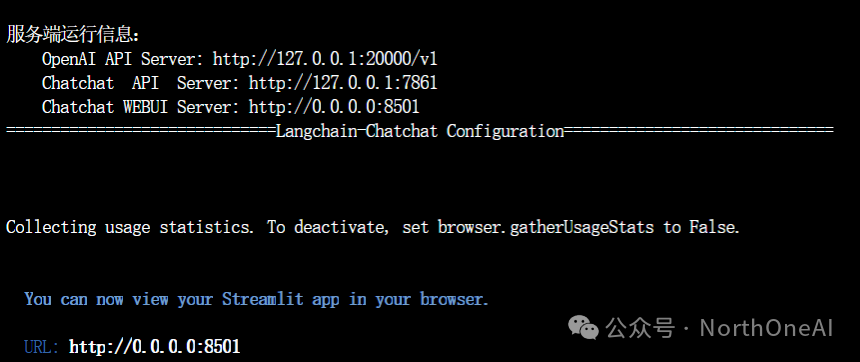
感受一下

左边可以选择LLM对话还是知识库对话,或者基于搜索引擎对话。
我们可以先创建知识库,点击知识库管理,
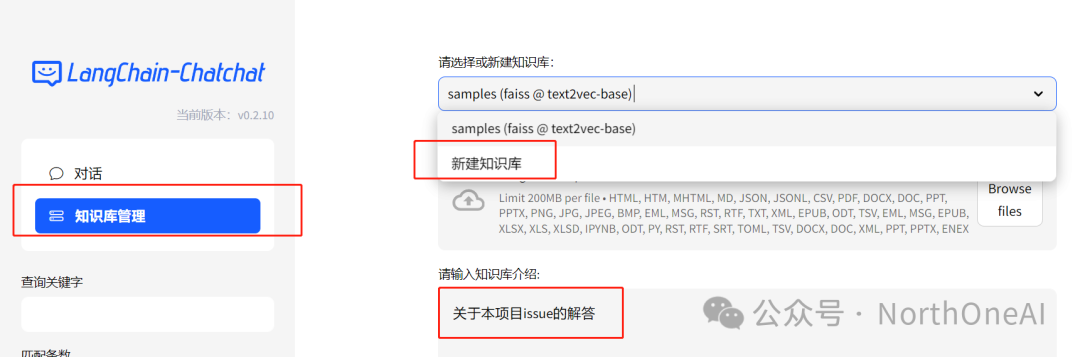
新建一个知识库,上传文档,
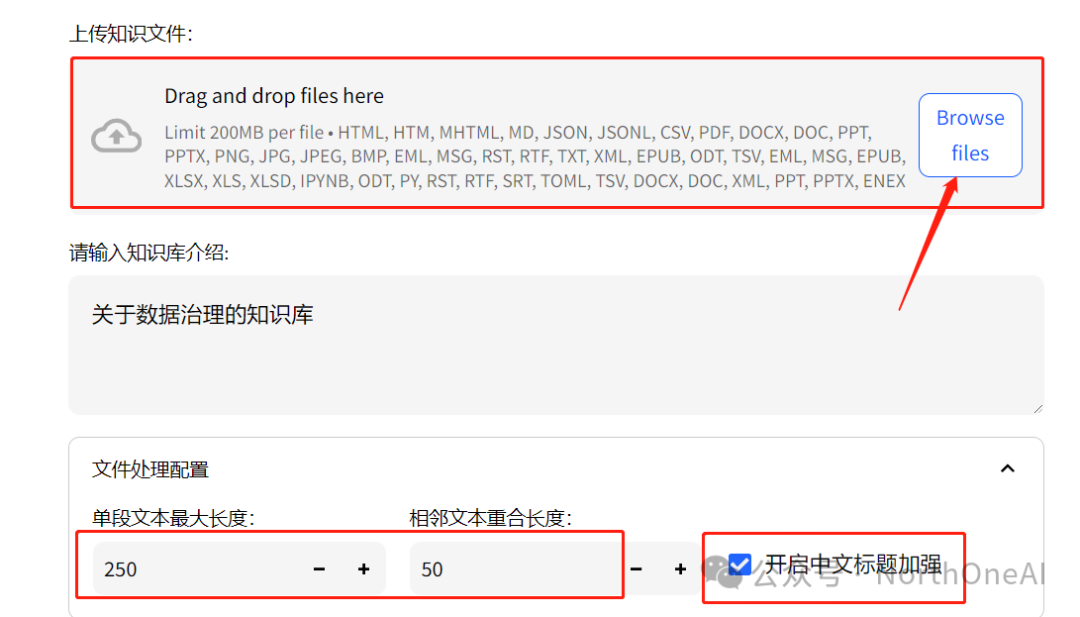
把开启中文标题加强勾上,然后在左边选择和知识库对话即可。其他一些功能大家就自己摸索吧。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。



















 1783
1783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









