




- 如何利用你的垂域数据补充LLM的能力
- 如何构建你的垂域向量知识库
- 搭建一套完整的RAG系统需要哪些模块
2. 什么是检索增强的生成模型(RAG)
LLM固有的局限性
- LLM的只是可能不是实时的
- LLM可能不知道你私有的领域/业务知识
检索增强生成
RAG可以通过检索的方法来增强生成模型的能力。
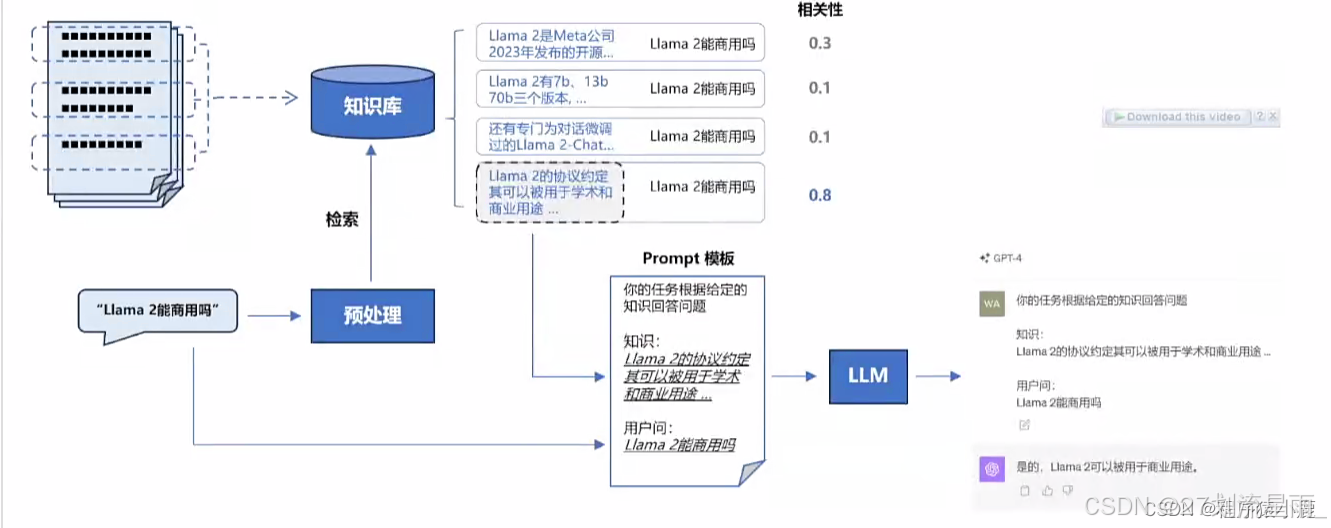
RAG的目标是通过知识库增强内容生成的质量,通常做法是将检索出来的文档作为提示词的上下文,一并提供给大模型让其生成更可靠的答案。更进一步地,RAG的整体链路还可以与提示词工程(Prompt Engineering)、模型微调(Fine Tuning)、知识图谱(Knowledge Graph)等技术结合,构成更广义的RAG问答链路。

3. RAG系统的基本搭建流程
搭建过程:
- 文档加载,并按一定条件
切割成片段 - 将切割的文本片段灌入
检索引擎 - 封装
检索接口 - 构建
调用流程:Query–> 检索 --> Prompt --> LLM --> 回复
文档的加载与切割
4. 向量检索
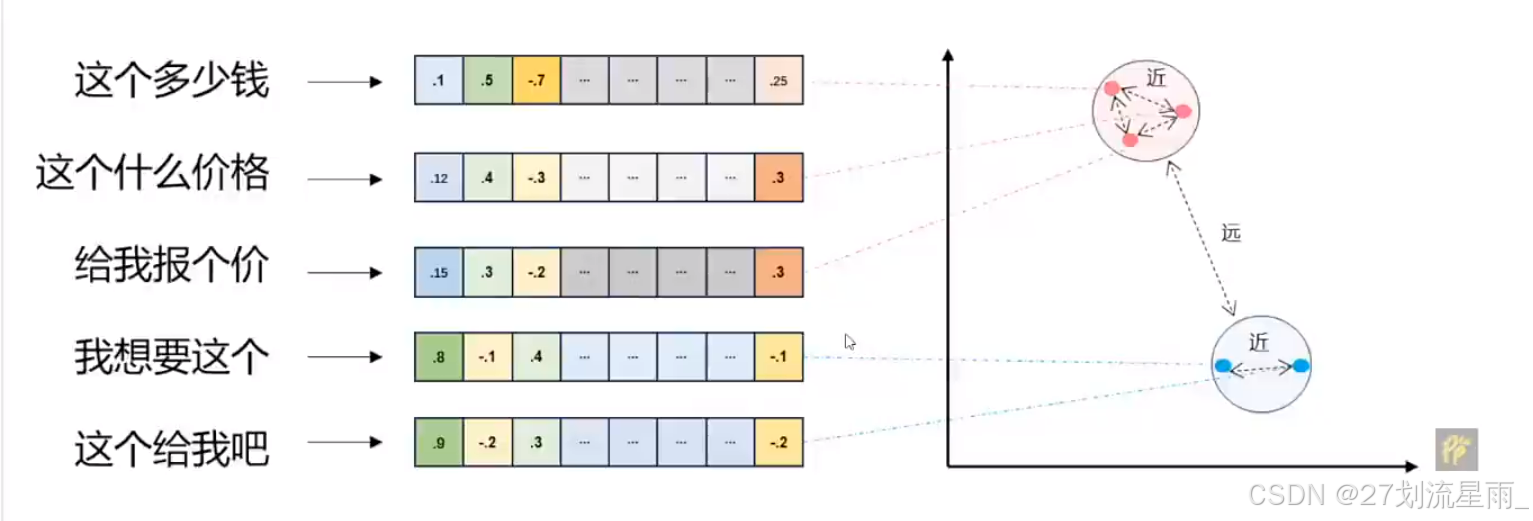
文本向量
- 将文本转换成一组浮点数:每个下标 iii ,对应一个维度
- 整个数组对应一个n维空间的一个点,即
文本向量 - 向量之间可以计算距离,距离远近对应
语义相似度的大小
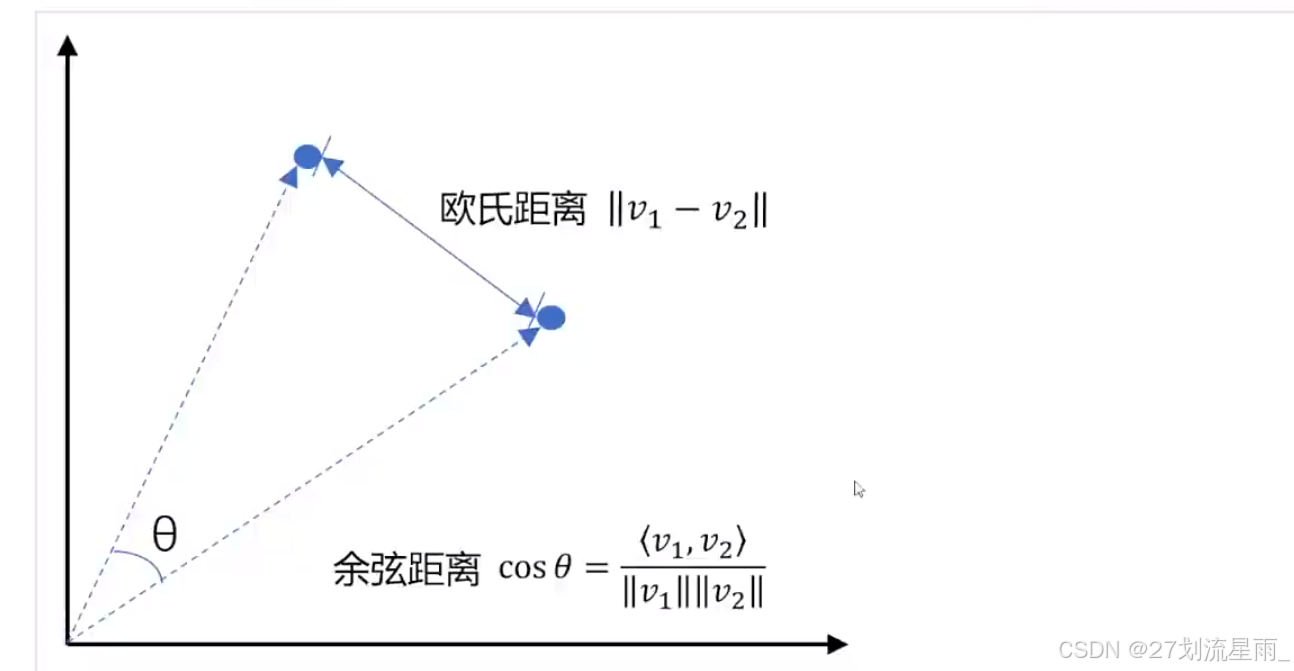
向量间的相似度计算
向量数据库
import numpy as np
from numpy import dot
from numpy.linalg import norm
# 余弦距离,越大越相似
def cosine_distance(x, y):
return dot(x, y) / (norm(x) * norm(y))
# 欧式距离,越小越相似
def euclidean_distance(x, y):
a = np.array(x) - np.array(y)
return norm(x)
import numpy as np
from numpy import dot
from numpy.linalg import norm
from sqlalchemy.orm.collections import collection
from pdfminer.high_level import extract_pages # 用于提取 PDF 文本
from pdfminer.layout import LTTextContainer # 1. 从 PDF 中提取文本 2. 提供了有关文本的布局和样式信息,包括字体大小、颜色、文本的起始和结束位置
# 余弦距离,越大越相似
def cosine_distance(x, y):
return dot(x, y) / (norm(x) * norm(y))
# 欧式距离,越小越相似
def euclidean_distance(x, y):
return norm(x - y)
def extract_t 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 513
513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









