




 本文详细解析了Java中Executor框架的运作原理,包括Executor、ExecutorService、ScheduledExecutorService等核心组件,以及线程池如ThreadPoolExecutor和ScheduledThreadPoolExecutor的配置细节。探讨了不同线程池类型如固定线程池、缓存线程池、单线程执行器和定时调度线程池的特点和应用场景。
本文详细解析了Java中Executor框架的运作原理,包括Executor、ExecutorService、ScheduledExecutorService等核心组件,以及线程池如ThreadPoolExecutor和ScheduledThreadPoolExecutor的配置细节。探讨了不同线程池类型如固定线程池、缓存线程池、单线程执行器和定时调度线程池的特点和应用场景。
Executor框架
Executor
基于生产——消费者模式,提交任务相当于生产者,执行任务的线程相当于消费者。如果要在程序中实现生产者——消费者,那么最简单的方式就是使用Executor。
线程池中的两个重要角色是工作队列(Work Queue)和工作线程(Worker Thread)。生产者向工作队列中添加任务,消费者(工作线程)从工作队列中获取任务并执行,任务执行完成后,返回线程到线程池。
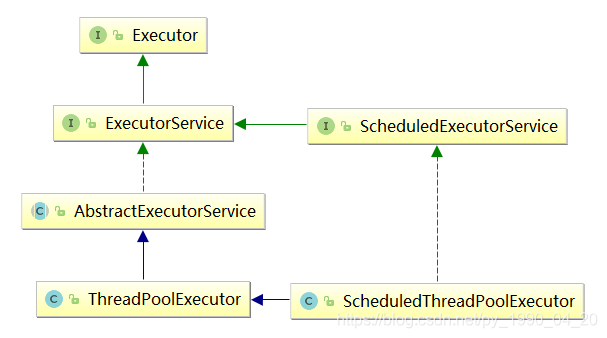
- Executor 最顶层的类,解耦Runnable的提交和执行
- ExecutorService 提供生命周期方法shutdown(),shutdownNow()…,和Callable任务提交
- ScheduledExecutorService 对ExecutorService扩展了定时调用
- AbstractExecutorService 一些基本实现,会发现submit()本质上还是调用的是execute()方法,有点像模板方法
- ThreadPoolExecutor 大量具体的实现,包括Executor#execute
- ScheduledThreadPoolExecutor 定时调度线程池的实现
Executors
Executors是Executor的工厂,分以下几类方法:
- 创建和返回ExecutorService
- 创建和返回ScheduledExecutorService
- 创建和返回不可修改配置的线程池,这种线程池一旦创建完成后,后续的其他代码是不能修改线程池参数的。
- 创建和返回ThreadFactory
- 创建和返回Callable,将Runnable适配为Callable
Executors提供了常用策略的线程池创建,当然如果你也可以直接使用ThreadPoolExecutor或ScheduledThreadPoolExecutor 创建你想要的线程池。
-
newFixedThreadPool
创建一个固定长度的线程池/* * @param nThreads the number of threads in the pool * @return the newly created thread pool * @throws IllegalArgumentException if {@code nThreads <= 0} */ public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }另一个对应的工程方法需要提供ThreadFactory,用于线程池创建线程
-
newCachedThreadPool
缓存线程池/* * @return the newly created thread pool */ public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }另一个对应的工程方法需要提供ThreadFactory,用于线程池创建线程
-
newSingleThreadExecutor
单线程的Executor/* * @return the newly created single-threaded Executor */ public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); }另一个对应的工程方法需要提供ThreadFactory,用于线程池创建线程
-
newScheduledThreadPool
定时调度的线程池public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) { return new ScheduledThreadPoolExecutor(corePoolSize); }另一个对应的工程方法需要提供ThreadFactory,用于线程池创建线程
-
newSingleThreadScheduledExecutor
单线程定时调度线程池
public static ScheduledExecutorService newSingleThreadScheduledExecutor() { return new DelegatedScheduledExecutorService (new ScheduledThreadPoolExecutor(1)); }另一个对应的工程方法需要提供ThreadFactory,用于线程池创建线程
归根结底还是配置ThreadPoolExecutor和ScheduledThreadPoolExecutor,所以上面不详细解释每个工厂方法的特性,只要明白了ThreadPoolExecutor和ScheduledThreadPoolExecutor 配置一切都会明白。
配置ThreadPoolExecutor
ThreadPoolExecutor通用构造函数
/**
* Creates a new {@code ThreadPoolExecutor} with the given initial
* parameters.
*
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
* @param keepAliveTime when the number of threads is greater than
* the core, this is the maximum time that excess idle threads
* will wait for new tasks before terminating.
* @param unit the time unit for the {@code keepAliveTime} argument
* @param workQueue the queue to use for holding tasks before they are
* executed. This queue will hold only the {@code Runnable}
* tasks submitted by the {@code execute} method.
* @param threadFactory the factory to use when the executor
* creates a new thread
* @param handler the handler to use when execution is blocked
* because the thread bounds and queue capacities are reached
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
...
}
-
线程的创建与销毁
corePoolSize没有任务执行时大的线程池的大小,并且只有工作队列workQueue满了才会创建超出这个数量的线程,但不会超过maximumPoolSize。在创建ThreadPoolExecutor初期,线程并不会立即启动,而是等待任务提交时才会启动,除非调用
prestartAllCoreThreads。maximumPoolSize表示可同时活动的线程数量上限。
当某个线程的空闲时间(没有任务运行)超过存活时间keepAliveTime,那么这个线程将被标记为可回收,并且线程池的当前大小超过了corePoolSize时,这个线程将被终止。
newFixedThreadPool的工厂方法的corePoolSize和maximumPoolSize一样大,keepAliveTime为0,所以线程池会一直保持设置的大小,不扩展也不回收。
newCachedThreadPool的工厂方法的corePoolSize为0和maximumPoolSize为Integer.MAX_VALUE,keepAliveTime为60s,是一个无界线程池,线程空闲会被回收。如果把
corePoolSize设置为0(像newCachedThreadPool),工作队列改为其他的非SynchronousQueue工作队列,例如大小为20LinkedBlockingQueue,那么只有等工作队列填满20任务后,才开始执行。 -
管理队列任务
BlockingQueue是一个阻塞队列,阻塞队列提供了put和take方法,以及支持定时的offer和poll方法。如果队列已经满了,那么put方法将阻塞直到有空间可用;如果队列为空,那么take方法将阻塞直到元素可用。队列可以是有界的也可以是无界的,无界队列永远都不会充满,因此无解队列的put永远不会阻塞。基本的任务排队方法有:无解队列、有界队列、和同步移交(Synchronous Handoff)。
newFixedThreadPool和newSingleThreadExecutor使用无界的LinkedBlockingQueue,默认构造的大小是Integer.MAX_VALUE/** * Creates a {@code LinkedBlockingQueue} with a capacity of * {@link Integer#MAX_VALUE}. */ public LinkedBlockingQueue() { this(Integer.MAX_VALUE); }更稳妥的策略是使用有界队列避免资源耗尽的情况发生,例如使用
ArrayBlockingQueue、有界的LinkedBlockingQueue(构造传值)、PriorityBlockingQueue(这是一个优先队列,构造传入Comparator)。但是队列满了怎么办?这时的饱和策略由RejectedExecutionHandler实现决定。
对于非常大或者无界的线程池,可以使用SynchronousQueue来避免排队(同步移交Synchronous Handoff),直接将任务从生产者移交给工作线程。SynchronousQueue不是一个真正的队列,而是线程之间移交的机制。要将元素放入SynchronousQueue中,必须有一个线程正在等待接受这个元素。如果没有线程等待,并且线程池的当前大小小于maximumPoolSize,那么ThreadPoolExecutor会创建一个新线程。当超过maximumPoolSize时,根据饱和策略被拒绝。只有线程池是无界的或任务可以被拒绝时,SynchronousQueue才有价值。例如,newCachedThreadPool的maximumPoolSize为Integer.MAX_VALUE。 -
饱和策略
JDK提供了几种不同的RejectedExecutionHandler实现,每种都包含不同的饱和策略:AbortPolicy、CallerRunsPolicy、DiscardPolicy、DiscardOldestPolicy。
AbortPolicy是默认的饱和策略,该策略会抛出未检查异常RejectedExecutionException。
DiscardPolicy当新提交的任务无法保存到队列中等待执行时,会抛弃该任务。
DiscardOldestPolicy会抛弃下一个被执行的任务,然后重新提交新任务。不能和PriorityBlockingQueue使用,因为会抛弃优先级最高的任务。
CallerRunsPolicy该策略实现一直调节机制,不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者,从而降低任务流量。当线程池满,工作队列满,它会把新任务交给调用者(执行execute任务提交的线程)的线程执行。任务提交的线程也变成了一个执行任务的线程,可以缓解任务提交量。 -
线程工厂
你可以实现ThreadFactory,自定义一个线程工厂,指定一个有意义的线程名,或者给线程设置UncaughtExceptionHandler等等。
public interface ThreadFactory {
/**
* Constructs a new {@code Thread}. Implementations may also initialize
* priority, name, daemon status, {@code ThreadGroup}, etc.
*
* @param r a runnable to be executed by new thread instance
* @return constructed thread, or {@code null} if the request to
* create a thread is rejected
*/
Thread newThread(Runnable r);
}

















 386
386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









