 揭秘AI长期记忆系统
揭秘AI长期记忆系统




要构建能够记住用户交互历史的AI Agent,所要实现的绝非仅仅存储原始对话内容。
Amazon Bedrock AgentCore的短期记忆功能可捕捉即时上下文,但真正的挑战在于如何将这些交互记录转化为跨会话持久存在且可操作的知识。正是这类知识信息,能将转瞬即逝的交互转变为用户与AI Agent之间富有意义、持续存在的关系。
AgentCore Memory是一项全托管服务,通过提供短期工作记忆和长期智能记忆两种能力,帮助开发者构建具备上下文感知能力的AI Agent。您可参阅往期文章《重磅推出Bedrock AgentCore!高效部署与运行AI Agent》,详细了解AgentCore Memory以及如何启用。
本文将揭秘Amazon Bedrock AgentCore Memory长期记忆系统的工作原理。
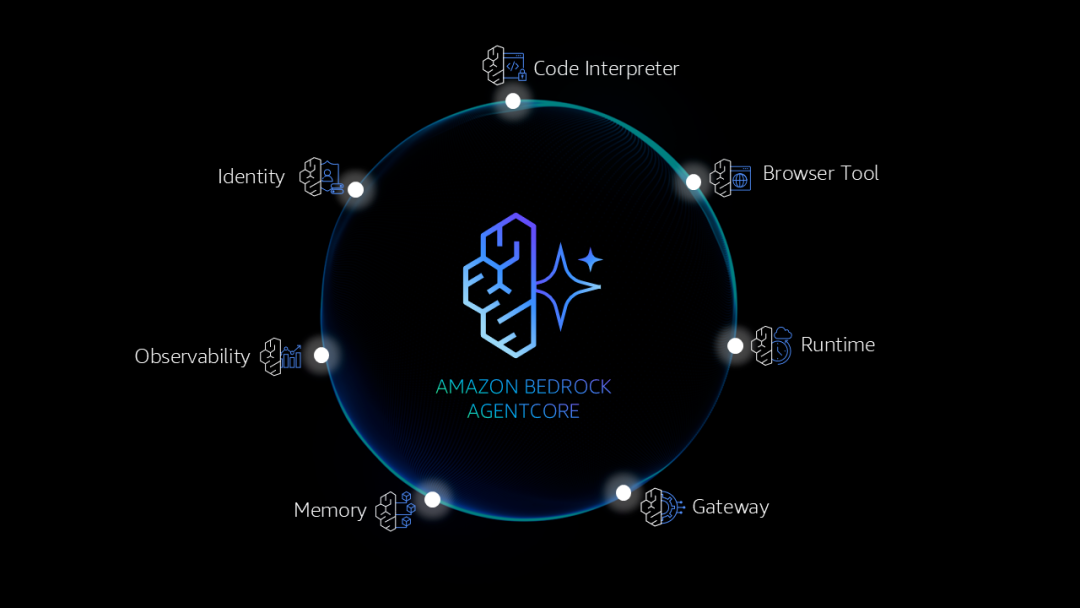
实现长期记忆面临的挑战
众所周知,人类在互动交流的过程中,并非只会记住对话的内容,而是会提炼含义、识别规律,并随着时间推移形成自己的理解。
要让AI Agent也能做到这一点,就需要解决以下复杂挑战:
1.Agent的记忆系统必须能够区分有价值的信息与意义并不重要的日常闲聊,判断哪些表述值得长期存储,哪些信息只需临时处理。例如,用户说“我是素食主义者”这类信息应当被记住,而“嗯,让我想想”等信息则不必存储。
2.记忆系统需要跨时间识别相关信息并将其整合,同时避免信息重复或前后矛盾。例如,用户在1月提到自己对贝类过敏,3月又表示自己不能吃虾,系统需将这两点识别为相关事实,并与已有知识整合,且避免产生重复或矛盾的信息。
3.记忆必须结合时间背景进行处理。对于随时间变化的偏好(例如,用户去年喜欢某家餐厅的辣子鸡,如今却偏爱清淡口味),系统需要妥善处理:既要优先考虑最新偏好,也要考虑过往喜好。
4.随着记忆库中存储的记录增长至成千上万条时,如何快速找到相关记忆便会成为一大挑战,系统必须在全面保留记忆与高效检索之间取得平衡。

*图片源自亚马逊云科技官网
要解决这些挑战,绝非简单的存储即可应对,而是需要构建复杂的提取、整合与检索机制。
Amazon Bedrock AgentCore Memory通过一套基于研究支持的长期记忆流程,来应对这些复杂挑战。该流程既模仿了人类的认知过程,又能满足企业级应用所需的精准度与可扩展性。
AgentCore长期记忆的工作原理
当Agentic应用将对话事件发送至AgentCore Memory时,会启动一个多阶段处理流程,将原始对话数据转化为结构化、可检索的知识。
下文将详细介绍该系统的各个组成部分。
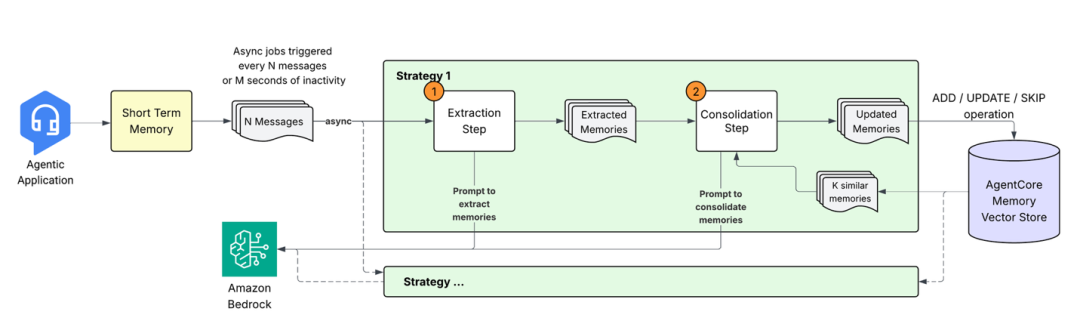
记忆提取:从对话中获取洞察
将新事件存储到短期记忆中时,会启动分析对话内容的异步提取流程,来识别有价值的信息。该流程借助大语言模型(LLM)理解上下文,并提取应长期保留的相关细节。提取引擎会结合历史上下文处理新收到的消息,并按照预定义架构生成记忆记录。
开发者可以配置一种或多种记忆提取策略,仅提取与应用需求相关的信息类型。提取流程支持三种内置的记忆提取策略:
1.语义记忆:提取事实与知识,示例如下。
"The customer's company has 500 employees across Seattle, Austin, and Boston"左右滑动查看完整示意
2.用户偏好记忆:结合上下文捕捉用户明确表达或隐含的偏好,示例如下。
{“preference”: "Prefers Python for development work", “categories”: [“programming”, ”code-style”], “context”: “User wants to write a student enrollment website”}左右滑动查看完整示意
3.总结记忆:根据不同会话主题下的对话内容,生成连贯的叙述内容,并以结构化的XML格式保存关键信息,示例如下。
<topic=“Material-UI TextareaAutosize inputRef Warning Fix Implementation”> A developer successfully implemented a fix for the issue in Material-UI where the TextareaAutosize component gives a "Does not recognize the 'inputRef' prop" warning when provided to OutlinedInput through the 'inputComponent' prop. </topic>
左右滑动查看完整示意
对于每种策略,系统都会处理带有时间戳的事件,来维护上下文的连贯性并解决冲突。单个事件可提取出多条记忆,且每种记忆提取策略均独立运行,支持并行处理。
记忆整合
系统并非简单地将新记忆添加到现有存储中,而是通过智能整合操作来合并相关信息、解决冲突并尽量减少信息冗余。这种整合方式能确保随着新信息的传入,Agent的记忆始终保持连贯性与时效性。
整合流程如下:
1.检索记忆:对于每条新提取的记忆,系统会从同一命名空间和策略下,检索出语义相似度最高的现有记忆。
2.智能处理:将新记忆与检索到的现有记忆,连同整合提示词一同发送至LLM。该提示词会保留语义上下文,从而避免不必要的更新(例如,“喜欢披萨”与“爱披萨”两种表述虽略有差异,但语义本质相同)。在遵循这些核心原则的基础上,提示词可处理多种场景:
You are an expert in managing data. Your job is to manage memory store. Whenever a new input is given, your job is to decide which operation to perform.
Here is the new input text.TEXT: {query}
Here is the relevant and existing memoriesMEMORY: {memory}
You can call multiple tools to manage the memory stores...左右滑动查看完整示意
基于该提示词,LLM会确定相应的操作:
添加(ADD):当新信息与现有记忆存在明显差异时,执行该操作。
更新(UPDATE):当新信息可补充或完善现有记忆时,执行该操作对现有记忆进行增强。
无操作(NO-OP):当新信息属于冗余内容时,执行该操作。
3.向量存储更新:系统会执行已确定的操作(新增或更新或无操作),并通过将过时记忆标记为“INVALID”而非立即删除的方式,来维护一份不可篡改的审计记录。
这种方式可确保妥善解决信息矛盾(即优先采用最新信息)、减少重复内容,并且合理整合相关记忆。
处理边缘情况
整合流程可妥善处理多种复杂场景:
乱序事件:尽管系统会按时间顺序处理会话事件,但通过精准的时间戳追踪与整合逻辑,仍能处理延迟到达的事件。
信息冲突:当新信息与现有记忆相矛盾时,系统会优先采用最新信息,同时保留先前状态的记录。
Existing: "Customer budget is \$500"New: "Customer mentioned budget increased to \$750"Result: New active memory with \$750, previous memory marked inactive左右滑动查看完整示意
记忆整合失败处理:若某条记忆的整合操作失败,不会对其他记忆产生影响。系统会采用指数退避和重试机制来处理暂时性故障。即便整合最终仍失败,该记忆也会被添加到系统中,以防丢失潜在信息。
高级自定义记忆策略配置
尽管内置记忆策略能覆盖常见使用场景,但不同领域对记忆提取与整合的需求存在差异,需要定制化方案。该系统支持扩展内置策略,允许使用自定义提示词来扩展内置的提取与整合逻辑,使团队能够根据特定需求调整记忆处理方式。
为保证系统兼容性,并聚焦于判定标准与逻辑(而非输出格式),自定义提示词可帮助开发者定制需提取或过滤的信息类型、记忆整合方式、如何解决矛盾信息之间的冲突。
此外,AgentCore Memory还支持为记忆提取与记忆整合环节选择自定义模型,这种灵活性能帮助开发者根据自身需求,平衡准确性与延迟。创建memory_resource时,用户可以通过API(作为策略覆盖项)或通过控制台(如下图所示)配置自定义模型。
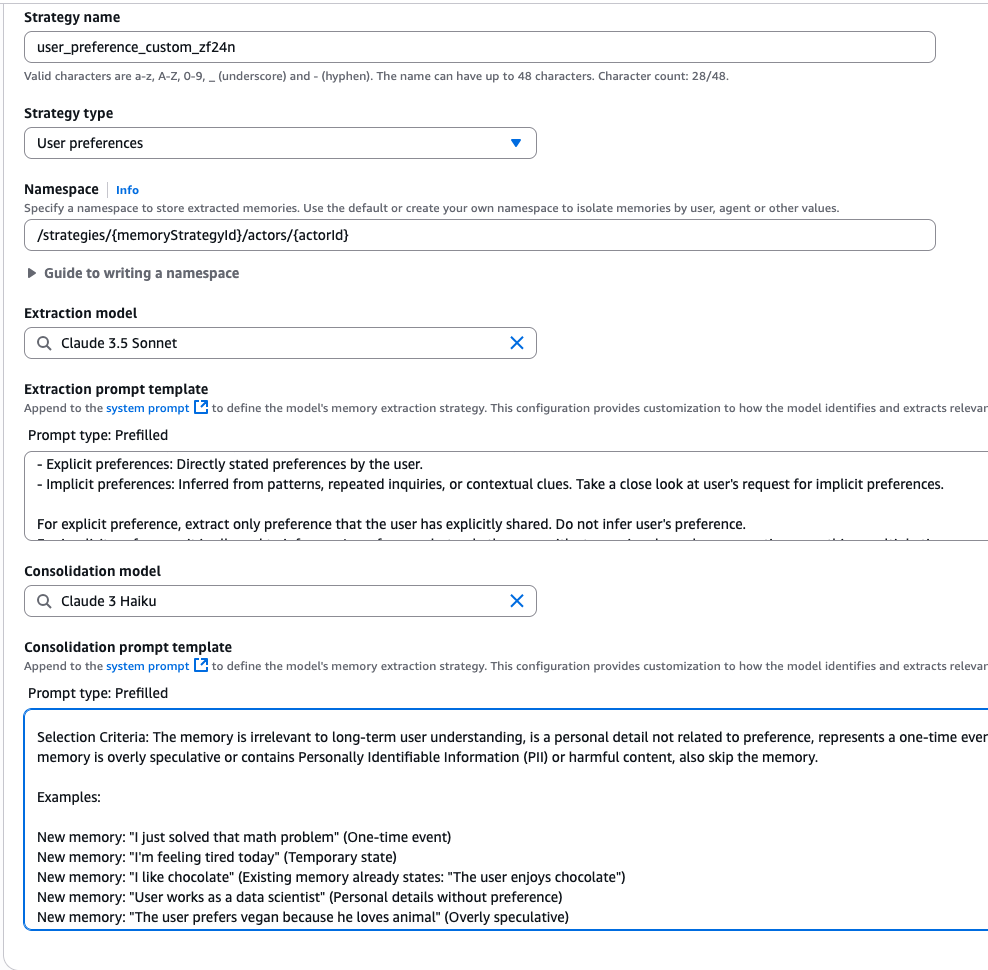
除覆盖功能外,系统还提供自主管理策略,让用户能完全掌控记忆处理流程。借助自主管理策略,用户可使用任意模型或提示词,实现自定义的记忆提取与整合算法,同时借助AgentCore Memory完成存储与检索。
此外,通过Batch API,用户可将已提取的记忆直接导入AgentCore Memory,且全程掌控处理逻辑。
性能特征
为评估长期对话记忆的不同维度表现,本例基于三个公开基准数据集,测试了内置记忆策略:
LoCoMo:通过人机交互流程生成的多轮对话数据集,包含基于角色设定的交互内容与时间事件图谱,用于测试系统在真实对话模式下的长期记忆能力。
LongMemEval:用于评估系统在多轮对话、长时间跨度对话下的记忆留存能力。为提升评估效率,本测试随机抽取了200组问答对进行测试。
PrefEval:该数据集使用21轮对话实例,围绕20个主题测试偏好记忆能力,用于测试系统记住用户偏好的记忆能力,以及持续应用这些偏好的稳定性。
PolyBench-QA:该问答类数据集包含80条任务轨迹下的807组问答对,其来源于PolyBench中编码Agent执行任务的过程。
本例采用两项标准指标进行评估:
准确率:基于LLM的正确性评估,判断系统在需要时能否正确回忆并使用已存储的信息。
压缩率:定义为输出记忆token数与完整上下文token数的比值,用于评估记忆系统存储信息的效率。压缩率越高,表明系统不仅能够保留关键信息,还能降低存储开销。
压缩率指标直接关乎推理速度和token消耗量——由于它能让系统更高效地处理大量对话历史,并降低运营成本,因此对于大规模部署Agent而言,这是极为关键的考量因素。
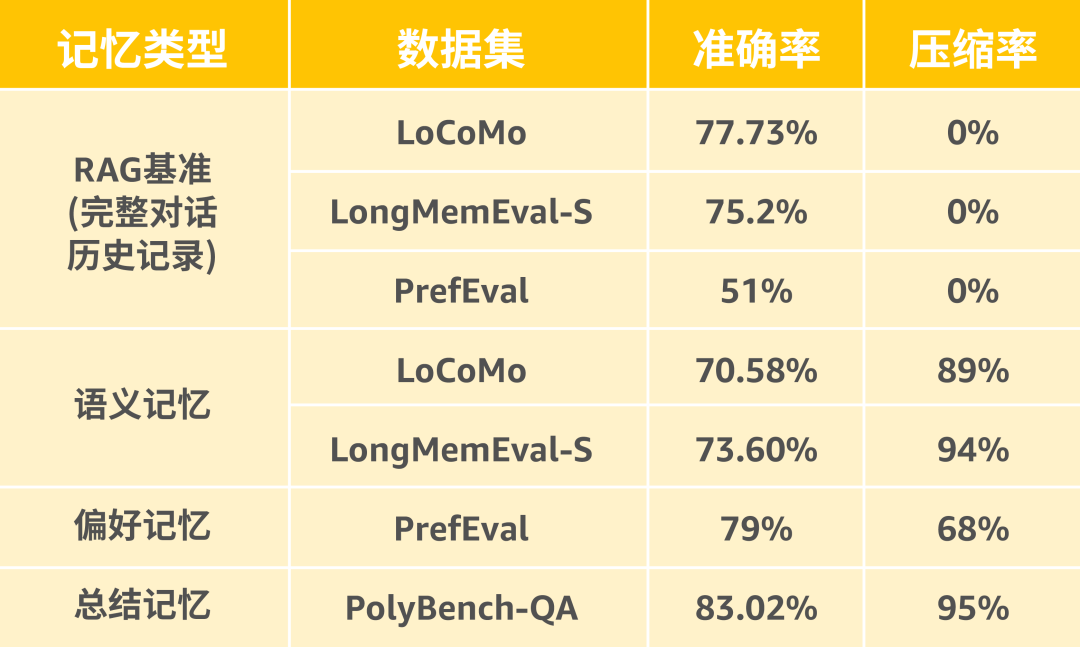
由于能够访问完整的对话历史,RAG(检索增强生成)基准在事实类问答任务中表现出色,但在偏好推理方面则稍显逊色。
AgentCore记忆系统则在处理这两类任务之间实现了平衡:尽管信息压缩导致其在部分事实类任务中的准确率略有下降,但它能提供89%-95%的压缩率,足以支持大规模部署,同时维持可控的上下文规模,并在特定应用场景中高效发挥作用。
对于需要推理的更复杂任务(如理解用户偏好或行为模式),该记忆系统在性能准确率与存储效率两方面均展现出明显优势,所提取出的洞察信息比原始对话数据更具价值。
除准确率指标外,AgentCore Memory还具备投入生产环境部署所需的关键性能特征:
提取与整合耗时:对于标准对话,触发提取操作后,可在20-40秒内完成整个提取与整合流程。
语义搜索检索速度:通过retrieve_memory_records API进行语义搜索时,仅需约200毫秒即可返回结果。
并行处理能力:并行处理架构支持多种记忆策略独立运行,不同类型的记忆信息可同时处理,互不干扰。
这些延迟特性再加上高压缩率,使得系统在大规模部署场景下,既能高效管理海量对话历史记录,又能为用户持续提供响应迅速的使用体验。

*图片源自亚马逊云科技官网
长期记忆的最佳实践
您可采取以下措施,以便让Agent的长期记忆发挥最大效用:
1
选择合适的记忆策略
挑选与应用场景适配的内置策略,或针对特定领域需求创建自定义策略:
语义记忆:用于捕捉事实性知识。
偏好记忆:专注于记录个人偏好。
总结记忆:可提炼复杂信息,以便更好地管理上下文。
例如,客服Agent可利用语义记忆存储客户的交易历史与过往问题,同时利用总结记忆,针对不同主题,对当前客服对话及故障排查流程生成简短概述。
2
设计合理的命名空间
按照应用程序的层级结构设计命名空间,这既能实现精准的记忆隔离,也能提升检索效率。
例如,针对单个Agent的记忆:
可用customer-support/user/john-doe这类命名空间。
针对团队共享信息:
可用customer-support/shared/product-knowledge这类命名空间。
3
监控整合模式
可通过list_memories或retrieve_memory_records API,定期查看系统创建、更新或跳过的记忆内容,这有助于优化提取策略,确保系统能够捕捉到更贴合用户应用场景的相关信息。
4
规划异步处理流程
需注意,提取长期记忆属于异步操作,因此在设计应用程序时,要考虑如何处理事件接收与记忆可用之间的延迟。您可选择在后台对长期记忆进行处理与整合期间,利用短期记忆满足即时检索需求。此外,您也可设置备用机制或加载状态,以便在处理延迟期间管理用户预期。
总结
Amazon Bedrock AgentCore Memory长期记忆系统,是构建AI Agent领域的一项重要突破。它融合了复杂的提取算法、智能的整合流程以及不可篡改的存储设计,为构建可随时间推移而不断学习、适应和改进的Agent提供了坚实基础。
从基于研究验证的提示词设计,到创新的整合工作流程,AgentCore长期记忆系统背后的技术原理确保了Agent不仅能记忆信息,更能理解内涵,从而可将一次性交互转化为持续的学习过程,让AI Agent在每一次对话中,都能更具实用性、更贴合用户需求。

资源链接
AgentCore Memory文档:
https://docs.aws.amazon.com/bedrock-agentcore/latest/devguide/memory.html
AgentCore Memory代码示例:
https://github.com/awslabs/amazon-bedrock-agentcore-samples/tree/main/01-tutorials/04-AgentCore-memory/
AgentCore快速入门实践教程:
https://catalog.us-east-1.prod.workshops.aws/workshops/850fcd5c-fd1f-48d7-932c-ad9babede979/en-US
我们正处在Agentic AI爆发前夜。企业要从"成本优化"转向"创新驱动",通过完善的数据战略和AI云服务,把握全球化机遇。亚马逊将投入1000亿美元在AI算力、云基础设施等领域,通过领先的技术实力和帮助“中国企业出海“和”服务中国客户创新“的丰富经验,助力企业在AI时代突破。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









