



Amazon ECS为AI和ML工作负载提供超强动力
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, 生成式AI, Amazon Ecs, Ai/Ml Workloads, Model Endpoint, Customer-Facing Application, Serverless Compute]
导读
在现代数字时代,运行人工智能(AI)和机器学习(ML)工作负载对于驱动图像生成和自然语言处理等应用至关重要。在本次会议中,学习如何最大化这些工作负载的性能和可扩展性,以满足动态需求。探索在Amazon ECS上提高AI/ML部署的运营效率和优化成本的最佳实践。通过真实世界的演示,了解在Amazon ECS上使用加速计算资源进行AI/ML的变革性力量。
演讲精华
以下是小编为您整理的本次演讲的精华。
本次会议由Steve Kendricks主持,他热情欢迎与会者,并承认在场有大量目前正在使用或考虑采用Amazon Elastic Container Service (ECS)的人员。
Abishek深入探讨了组织在构建AI/ML解决方案时面临的关键挑战,强调了在模型选择、运行时和库方面需要灵活性。他强调了可靠性的重要性,着重于一致性和高可用性,以满足客户的需求。性能被视为一个关键因素,使组织能够控制计算基础设施,以确保与客户的快速交互,无论是通过聊天机器人等应用程序还是基于队列的异步模式。
可扩展性被认为是支持客户需求增长和在需求较低时缩减规模的关键。成本优化被确定为一个关键考虑因素,确保以经济高效的方式大规模部署解决方案。通过监控和故障排除功能,可观察性被视为不可或缺的,并以遵守安全和合规标准为基础。
Abishek倡导一种将面向客户的应用程序与模型层解耦的思维模式,类似于微服务架构。这种方法使每一层都能独立扩展、选择技术和敏捷部署,从而使组织能够更快地为客户提供结果。他举了一个基于Web的应用程序的例子,客户通过该应用程序提交请求,而模型端点与面向客户的应用程序是解耦的。
演示展示了一个高级架构,客户通过Web应用程序和负载均衡器提交请求,面向客户的应用程序部署为一组任务组成的Amazon ECS服务。与ECS应用程序解耦的模型端点可以托管在任何选择的技术或服务上,利用这种架构方法的优势。
Abishek探讨了无服务器计算领域,将Amazon Lambda描述为一种高度固执己见的无服务器解决方案,具有执行时间和存储限制,但能够快速开发事件驱动的无服务器应用程序。他将ECS定位为一种完全托管的容器编排服务,具有无服务器控制平面,并通过Amazon Fargate提供无服务器数据平面的选择,或通过EC2计算获得更多对底层基础设施的控制。
对于托管模型层,Abishek讨论了从Amazon Bedrock(一种完全托管的无服务器API,易于使用)到使用Amazon ECS(一种通用的基于容器的解决方案)自托管模型的选择范围,后者提供了更多控制和定制的能力。
Abishek强调了使用ECS托管模型的好处,包括一致的工具、完全控制和可配置性、模型选择的灵活性、基础设施选择和库安装。他强调ECS与其他亚马逊云科技服务的深度集成,使组织能够通过Fargate满足其可观察性、安全性、应用程序自动扩展和无服务器计算需求。
关于计算选项,Abishek建议对于较小的模型考虑基于CPU的服务,而对于较大的模型或对延迟要求严格的模型,可能需要使用加速器,如GPU或Amazon Inferentia实例。他还提到了Amazon ECS Anywhere的选项,用于以混合方式在边缘运行AI/ML工作负载,以满足客户对数据驻留或隐私的严格要求。
通过在EC2上提供购买选项和折扣选项,包括现货实例和Savings Plans,可以实现成本优化,这些选项同时适用于Fargate和EC2计算选项。Abishek还强调了基于Graviton的实例为Fargate和EC2计算选项提供了更好的性价比。
ECS服务自动扩展通过ECS与亚马逊云科技应用程序自动扩展的深度集成而实现可扩展性。Abishek提到了各种扩展策略的可用性,包括基于CPU利用率和负载均衡器请求计数等预定义指标,以及使用队列深度积压等自定义指标的能力。
扩展策略选项包括步进扩展(允许对任务计数的增加和减少进行细粒度控制)、目标跟踪(一种完全自动化的模式,用户定义目标指标,如任务的平均CPU利用率)、计划扩展(手动定义扩展和缩减步骤)以及预测扩展(一种新推出的基于机器学习的算法,可根据历史需求模式提前主动扩展应用程序)。Abishek建议结合使用目标跟踪和预测扩展,以实现最佳的可扩展性。
为了使底层计算基础设施的扩展与应用程序扩展需求保持一致,Abishek介绍了Capacity Providers,它可以根据任务请求自动扩展或缩减EC2实例的数量。Capacity Providers支持使用现货容量和按需容量,以及自动扩展预热池,以减少启动EC2实例所需的时间,这对于较大的基于GPU的实例特别有益。
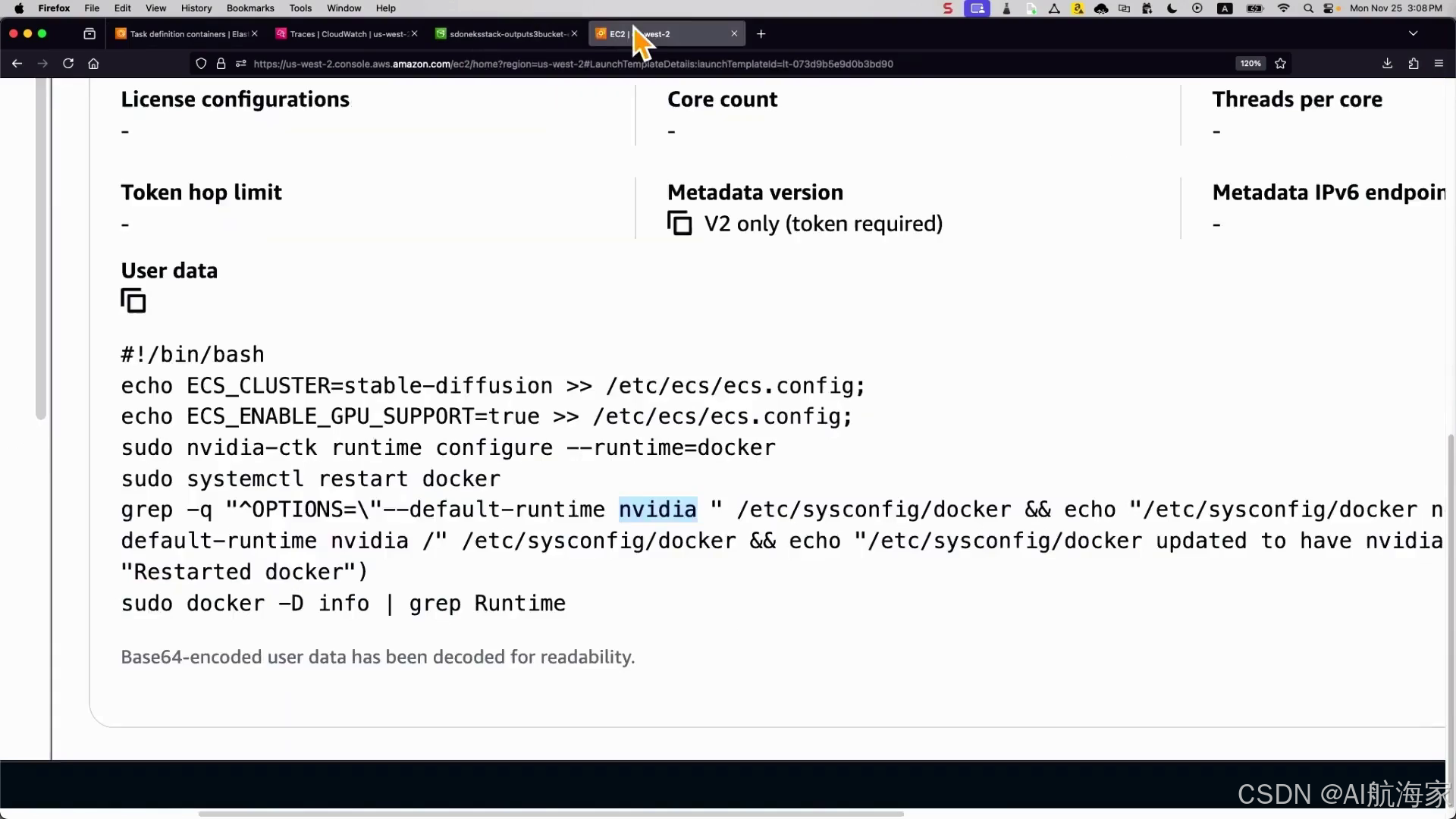
关于存储选项,Abishek警告不要将模型与容器镜像捆绑在一起,因为模型的大小可能从几个GB到数百GB不等,这可能会减慢应用程序加载时间。相反,他建议使用Amazon S3来托管模型并在运行时拉取,或者利用Elastic File System (EFS),这是一种完全托管的弹性文件系统,可提供更好的延迟、吞吐量和弹性。
对于监控和可观察性,Abishek强调了ECS与Amazon CloudWatch的本机集成,以及最近推出的增强型CloudWatch Container Insights,可提供任务和容器级别的细粒度指标。他提到了NVIDIA Data Center GPU Manager包的可用性,用于公开GPU指标,如利用率和温度,这些指标目前在ECS中无法直接获得。此外,ECS与Fluent Bit的本机集成使其能够将日志和指标路由到合作伙伴解决方案或不同的数据存储,而Amazon X-Ray可用于端到端用户请求跟踪和AI/ML工作负载的故障排除。
Steve Kendricks随后分享了一些客户成功利用ECS部署AI推理工作负载的案例。Wombo和Scenario将利用Fargate和ECS(或在某些情况下使用EC2实例)的关键优势是更快的上市时间。Kepler利用Amazon ECS Anywhere实现了混合和基于云的工作负载,加速了其机器学习应用程序向云的迁移。亚马逊的Rufus是一款旨在增强世界上最大电子商务平台购物体验的机器学习工具,它是使用Trillium和亚马逊云科技 Inferentia EC2实例通过ECS构建的。
在Frank Fann的演示中,展示了一个在ECS上运行的实时推理应用程序,用于图像生成。这个异步架构包括前端服务、消息代理(SNS、SQS)和在ECS上运行的推理端点服务。演示重点展示了可靠性、性能和可扩展性方面的内容。
在可靠性方面,Frank演示了处理故障和重试的能力,确保在发生故障时SQS队列中的消息不会被删除,新任务会重试这些消息。该架构通过利用API网关、Lambda、SNS和SQS等服务来最大化可靠性,这些服务本身就提供了可扩展性和可靠性。
在性能方面,通过优化模型加载时间和根据工作负载要求选择合适的实例类型来实现。Frank讨论了CPU、GPU和应用程序专用集成电路(如Amazon Inferentia)之间的权衡,考虑了模型大小、延迟要求和成本效益等因素。他展示了选择GPU实例系列(如A10(NVIDIA GPU)和G5)的能力,根据GPU数量、GPU内存大小和带宽等规格。演示还展示了使用亚马逊云科技 Graviton实例,与之前的代提供了更好的性价比。
为了最大化性能,Frank演示了一些技术,如使用亚马逊云科技开发的专为容器设计的Linux操作系统Amazon Bottlerocket,将高达14GB的大型容器镜像加载到数据卷上,将加载时间从6分钟减少到不到1分钟。模型文件托管在Amazon EFS上,将加载时间从30秒减少到10秒。通过sidecar模式实现监控,即在任务中运行Amazon Distro of OpenTelemetry (ADOT)作为容器来捕获其他容器的指标、跟踪和日志,或者通过集中模式,在专用任务中运行ADOT来捕获其他任务的信息。
可扩展性通过利用有意义的指标(如“每个任务的积压”自定义指标,计算为待处理作业除以活动任务)来实现,并将该指标与应用程序自动扩展策略结合使用,以扩展或缩减ECS任务和通过Capacity Providers的底层EC2实例。Frank演示了如何根据不断增加的“每个任务的积压”指标,将环境扩展到10个任务,同时Capacity Providers启动所需的EC2实例来处理工作负载。
这场演示展现了使用不同预训练模型的灵活性,如Laura扩展模型,生成具有独特风格的图像,突出了通过将基础模型(如稳定扩散)与扩展模型相结合来满足不同用例的能力。Frank还模拟了负载测试场景,持续向API网关发送请求,并根据自定义指标和应用程序自动缩放观察环境的缩放行为。
总之,Abishek强调了在不断发展的稳定扩散生态系统中灵活性的重要性,不同的基础模型如稳定扩散、Flux或新模型可能需要用于不同的用例。可靠性是重中之重,确保端到端的正常运行时间,并利用API网关、Lambda、SNS和SQS等服务实现内在的可扩展性和可靠性。
性能被视为至关重要,能够利用最新的实例类型,如GPU、AI优化实例或CPU用于不同的用例,以及像Amazon EFS这样的持久存储服务实现快速模型加载。通过ECS的内在可扩展性、使用有意义的指标、应用程序自动缩放和容量提供程序来快速扩展后端环境,从而解决了可扩展性问题。
可观察性被认为是监控GPU利用率、分配和微调环境的关键。强调了成本优化,能够扩展和缩减、利用现货实例,并利用Savings Plans和Graviton实例。
最后,Frank鼓励与会者通过调查提供反馈,因为这将有助于创建更好的解决方案并使更多人受益。他感谢了与会者和观众的参与。
下面是一些演讲现场的精彩瞬间:
演讲者通过要求举手来吸引观众的注意力,了解有多少与会者正在使用或考虑使用Amazon Elastic Container Service (ECS)。

亚马逊云科技 reinvent 2024: 探索与ECS集成AI/ML以增强客户体验和可扩展的Gen AI平台
亚马逊云科技建议使用目标跟踪和预测扩展的组合,根据预测模式和实时流量高峰自动扩展您的应用程序,无需过度配置或手动干预。

演示了与各种亚马逊云科技服务(包括Matrix GPU、Inference和Q Service、X-Ray跟踪以及DCGM GPU指标)的集成,以实现高效的GPU资源共享和推理功能。

现场演示展示了亚马逊云科技服务(包括X-Ray、API Gateway、Lambda、SNS、SQS和S3)的无缝集成,仅用1.4秒就从简单的提示中生成了一张图像,彰显了亚马逊云科技的强大功能和高效性。
一张屏幕截图展示了使用不同AI模型生成中国画风格图像,展现了系统的多样性和定制能力。
演讲者鼓励观众扫描二维码,访问与优化AI/ML工作负载环境相关的幻灯片、步骤和博客文章。
总结
在这个引人入胜的叙事中,我们踏上了一段利用人工智能(AI)和机器学习(ML)在Amazon Elastic Container Service (ECS)上的旅程。故事从构建可扩展、可靠和高性能的AI/ML解决方案的挑战开始,强调了灵活性、一致性和成本优化的需求。
叙述者随后展示了一个将面向客户的应用程序与模型层解耦的思维模型,实现独立扩展和技术选择。这种架构方法与ECS无缝集成,利用其无服务器计算选项,如Amazon Fargate和配备各种加速器(包括最新的DaVinci支持)的EC2实例。
随着叙事的展开,我们见证了ECS通过与Amazon Application Auto Scaling的深度集成而展现出的可扩展性,提供了一系列适用于不同工作负载的扩展策略。故事接着深入探讨了性能优化领域,探索了预热实例、利用Amazon EFS实现快速模型加载以及利用NVIDIA A10G等GPU实例的强大功能等技术。
叙述者随后带领我们体验了一个引人入胜的演示,展示了图像生成的实时推理应用程序。我们见证了异步架构的可靠性、无缝扩展能力以及利用不同模型和风格的灵活性,同时确保了最佳性能和成本效益。
在叙事结束时,叙述者强调了使用ECS处理AI/ML工作负载的好处,包括灵活性、可靠性、性能、可扩展性、可观察性和成本优化。最后呼吁与会者探索相关会议、访问共享资源并提供宝贵反馈,以塑造更好的未来解决方案。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。

















 1654
1654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









