



开发人员指南:如何赋能产品经理和数据科学家进行实验
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, LaunchDarkly, Experimentation Program, Best Practices, Data Ecosystem, Snowflake Integration, Advanced Analysis]
导读
实验——使用特定指标来评估你推出的功能的影响——对于做出数据驱动的技术决策至关重要。但首先,组织必须克服建立可扩展实验程序的技术挑战。在本次讨论中,你将了解创建可扩展实验程序所需的步骤——从连接数据源到设计有效的实验,再到分析结果以识别成功的变体。此外,还将学习如何通过让产品和数据团队在数据仓库内运行高级实验分析,来进一步赋能他们。本次演讲由亚马逊云科技合作伙伴LaunchDarkly为您带来。
演讲精华
以下是小编为您整理的本次演讲的精华。
在软件开发和数字创新不断演进的领域中,通过实验来追求持续改进已成为成功的基石。这一理念由远见卓识的Jeff Bezos精辟地概括,他曾说过:“我们在亚马逊的成功取决于我们每年、每月、每周、每天进行多少实验。”这段话最初是在一封投资者信中分享的,强调了实验在企业管理的最高层面所具有的巨大价值。
LaunchDarkly的实验专家Aaron Montana和Snowflake的合作伙伴解决方案架构师Dan Hunt着手阐明赋予产品经理和数据科学家实验强大工具的复杂艺术。他们的讨论深入探讨了实验在组织内的基本原则、最佳实践以及LaunchDarkly和Snowflake的协同集成,使组织能够充分发挥数据驱动努力的潜力。
他们演讲的核心是三大支柱,凸显了实验在组织内的重要性。首先,实验是财务收益的催化剂,提高投资回报率的同时,通过快速识别无效策略来降低昂贵错误的风险。其次,它培养了学习文化,营造了一种数据驱动决策植根于每一项举措的环境。这种框架使团队能够将失败视为通向成功的垫脚石,培养有利于颠覆性想法和持续改进的氛围。第三,实验与亚马逊、Netflix和谷歌等市场领导者的DNA密不可分,使他们能够不断完善用户体验、优化性能并在各自领域保持竞争优势。
随着软件渗透到现代生活的方方面面,开发人员发现自己处于这场变革浪潮的中心。与开发人员密切合作的LaunchDarkly倡导通过实验的视角来优化每一次软件发布。这种方法包括通过严格的实验来衡量新功能的成功程度、对获得的见解进行高级分析,并最终推出最有效的解决方案。LaunchDarkly的功能管理系统为组织拥抱这一范式提供了必要的工具和基础。
为了开启建立健全实验计划的旅程,Aaron Montana分享了他在这一领域的宝贵经验。他强调制定明确的测试计划的重要性,其中包括要解决的问题、正在研究的假设以及要衡量的主要指标。这些计划作为全面的文档,确保了实验的意图、方法和预期结果得到清晰阐述,从而实现可复制性并促进透明度。
此外,Aaron强调衡量真正重要的事物的关键性,突出了主要指标需要辅以次要指标和防护措施。这些额外的指标提供了背景、揭示了意外后果,并描绘了更全面的用户行为和实验影响画面。在多个实验中始终如一地纳入这些元素,有助于进行有意义的比较并加深对潜在动态的理解。
Aaron坦率地承认,许多实验都会产生平平无奇的结果,既非彻底成功也非完全失败。为了应对这一固有挑战,他提倡参数化实践,这是一种可以直接将可变值注入实验系统的技术。这种方法简化了迭代过程,允许快速调整诸如文本横幅、查询参数,甚至是管理AI模型的参数等元素。通过采用参数化,组织可以加快实验周期并迅速适应新出现的见解。
认识到数据可视化的关键作用,Aaron强调了直观实验仪表板的必要性。这些仪表板应为利益相关者提供统一且易于访问的界面,以评估实验结果,从而无需数据科学家不断干预。例如,LaunchDarkly为每个实验生成全面的仪表板,只需输入主要指标,从而为决策者提供所需的见解。
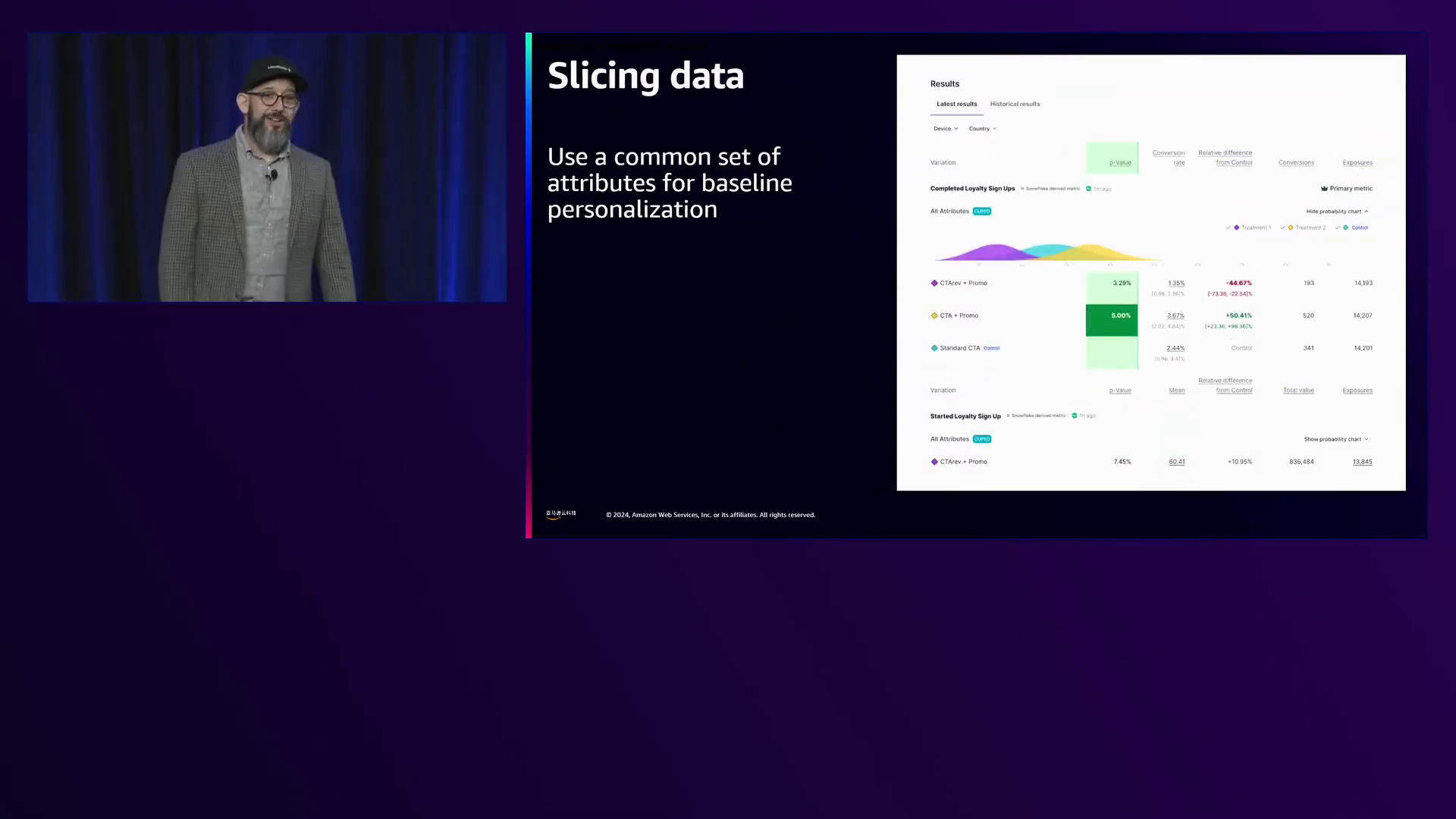
此外,Aaron倡导数据切片实践,这种做法实现了一定程度的个性化。通过沿相关属性对用户数据进行细分,组织可以为特定群体量身定制体验,优化结果并提高用户满意度。虽然这种方法不如个人层面的个性化精细,但它提供了一种实用有效的方式来满足不同用户的偏好。
任何成功的实验计划的基础都是在整个组织内分享发现。Aaron强调,分享见解不仅能教育和启发他人,还能培养实验文化。通过利用组织的集体语言和理解,演讲者可以与受众产生共鸣,激发好奇心并鼓励更广泛地采用这种变革性实践。哈佛商学院的一句话加强了这一观点:“大脑更喜欢故事而非纯数据,这源于它每天都会接收大量信息。”这突出了叙事在有效传达数据驱动见解方面的力量。
随着实验计划的成熟和扩展,Aaron承认出现了一些挑战,如需要单一的事实来源、存在滞后指标、复杂指标和数据孤岛。这些障碍可能会阻碍信息的顺畅流动,并妨碍从实验努力中获得有意义的见解。他用一个简单的例子说明了这一挑战,即用户的点击触发了一个事件API,该API穿越多个系统后最终形成了一个转化指标。然而,现实情况往往更加复杂,事件可能来自各种来源,包括忠诚度计划、Web应用程序、行为分析系统,甚至复杂的模型,如终身价值计算。这种错综复杂的数据源可能会导致碎片化和数据孤岛,阻碍有效的实验。
为了解决这些挑战,Dan Hunt介绍了Snowflake,这是一个旨在打破组织内数据孤岛的数据平台。Snowflake的云原生架构使组织能够几乎无限扩展分析能力,将来自不同来源的数据合并到一个统一的存储库中。这种方法不仅消除了个别业务单元内的数据孤岛,还促进了跨不同团队、地区,甚至第三方合作伙伴之间的安全数据共享。
Snowflake的发展是为了满足组织内不同角色的需求而推动的,如数据工程师、数据科学家和机器学习工程师。通过为Java、Python和Scala等语言引入一流的支持,Snowflake使这些专业人士能够直接在平台内进行高级分析,从而无需移动数据并降低创建新数据孤岛的风险。
在实验的背景下,Snowflake提供了几个令人信服的优势。首先,它是所有业务数据的统一来源,使组织能够结合来自各种工具的数据集,包括Salesforce等CRM系统、Zendesk和Intercom等平台的客户支持工单,以及应用程序和网站的点击流事件。这种整合使组织能够计算在单个实验工具中可能无法访问的高级组合指标。
其次,Snowflake的可编程数据功能使数据集能够通过细微的指标或属性进行丰富。例如,可以利用机器学习函数根据客户支持工单量或其他行为模式等汇总数据源来预测用户流失或识别增值销售机会。Snowflake甚至提供了一个classify_text函数,可以将文本数据(如客户呼叫记录或支持工单)分类到预定义的类别中,而无需专门的专业知识。
第三,Snowflake的可扩展性适用于从小型团队到处理数据量达到数千万亿字节的跨国企业等各种规模的组织。这种灵活性确保了组织只需为所消耗的计算资源付费,从而促进了任何规模的经济高效实验。
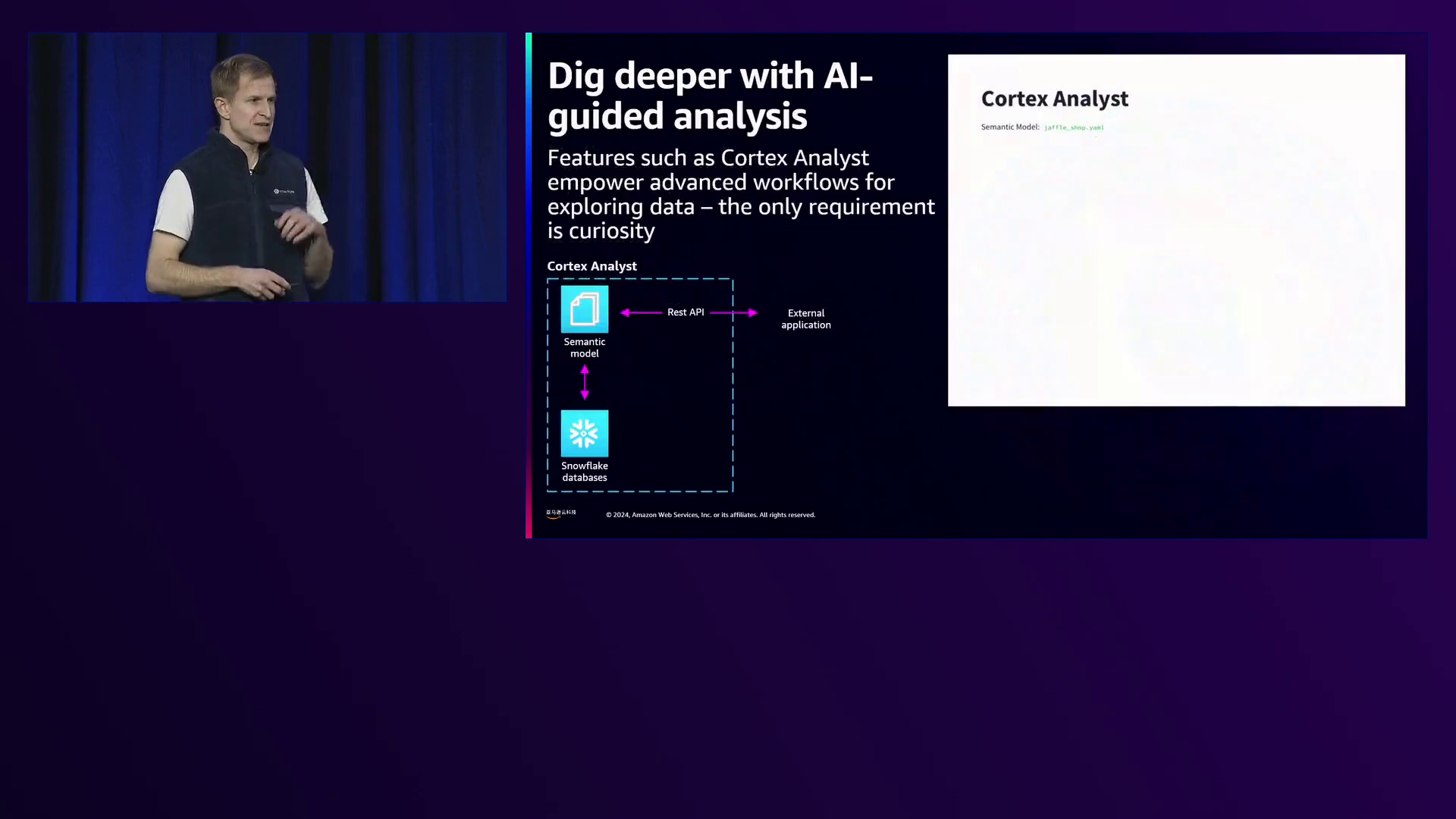
认识到人工智能日益重要,Snowflake推出了AI功能,进一步增强了实验过程。Dan Hunt展示了Cortex Analyst,这是一款允许用户通过自然语言查询与数据互动的工具。这种功能使产品经理和其他非技术人员能够深入挖掘实验结果,而无需专门的编程技能,从而减少了瓶颈并实现了数据访问的民主化。
为了解决跨多个工具释放企业数据价值的挑战,Snowflake在其平台中引入了应用程序的概念。这种方法消除了点对点集成和数据移动的需求,允许提供商实现其逻辑并通过Snowflake市场分发应用程序。消费者可以直接将这些应用程序安装到他们的Snowflake账户中,将计算能力带到他们的数据所在的位置,并位于安全的治理边界内。
Snowflake支持构建应用程序的两种主要模式:原生应用程序和连接应用程序。原生应用程序完全在客户的Snowflake账户内运行,包括数据层、处理和用户界面。这种架构简化了采购流程,确保数据保留在安全边界内,并实现了与现有Snowflake容量的无缝集成。
相反,连接应用程序利用提供商构建的现有Web应用程序,同时与客户的Snowflake数据集成。这种混合方法允许组织在熟悉的应用程序界面中释放其专有数据的价值,而不会损害安全性或治理。
LaunchDarkly和Snowflake之间的集成体现了一种混合方法,结合了原生和连接应用程序架构的元素。最初,用户安装一个原生Snowflake应用程序,该应用程序指导他们在LaunchDarkly和他们的Snowflake账户之间建立安全连接的过程。该应用程序还允许用户自定义如何向LaunchDarkly提供数据,包括选择特定数据集以及应用策略来根据聚合级别或其他标准限制数据共享。
一旦原生应用程序建立了安全连接,LaunchDarkly用户就可以直接从Web界面访问和分析Snowflake数据,但须遵守在设置过程中定义的策略。这种无缝集成确保了专有数据保留在客户的安全治理边界内,同时实现了高级分析和实验功能。
为了说明端到端架构,Dan Hunt演示了一个典型的数据流程。源系统(如CRM工具、客户支持平台以及应用程序和网站的点击流数据)将原始数据输入到Snowflake的青铜或原始层。Snowflake支持批量和流数据摄取,实现对传入数据的近实时查询。
从这个原始层开始,数据被组合和聚合到更加可用的格式中,利用Snowflake对Python函数和机器学习模型的支持。例如,classify_text函数可以将文本数据(如客户呼叫记录或支持票据)分类到预定义的类别中,而无需专门的专业知识。
由此产生的黄金数据集,通过这些额外的属性得到丰富,成为通过LaunchDarkly应用程序释放价值的基础。通过以适当的聚合策略向LaunchDarkly提供这个数据集,组织可以针对特定的用户细分或属性运行复杂的实验。此外,实验结果可以与Snowflake中计算的高级属性相关联进行分析,从而提供更深入的见解,并支持更明智的决策。
Aaron Montana随后阐述了LaunchDarkly和Snowflake集成为运行实验并进行高级分析所启用的三种途径。第一种途径是LaunchDarkly基础分析,包括完全在LaunchDarkly平台内运行的实验,适用于不需要敏感专有信息或直接访问单一事实源的场景。
第二种途径是自带分析,即将LaunchDarkly数据直接发送到Snowflake,组织可以利用丰富的数据集和自己的专有模型进行自己的分析。
第三种途径是仓库实验,代表了这种集成的顶峰,使LaunchDarkly能够在客户的Snowflake实例内端到端管理实验。这种方法提供了三种不同的选择:Snowflake原生实验构建器、用于在Snowflake内运行分析的实验构建器导出,以及Snowflake派生的指标,其中LaunchDarkly仪表板基于客户Snowflake实例中的指标。
这种全面的集成使组织能够根据自身需求运行量身定制的实验,发挥两个平台的优势。开发人员、产品经理和产品负责人可以在熟悉的LaunchDarkly仪表板中管理实验,而数据团队可以利用Snowflake的强大功能进行高级分析、整合专有数据并导出与组织标准保持一致的可信指标。
总之,Aaron Montana和Dan Hunt的演讲阐明了实验在推动组织成功中的变革潜力。通过采用良好的实践,如制定明确的测试计划、全面的指标跟踪、参数化、直观的仪表板、数据切片以及分享发现,组织可以培养持续学习和改进的文化。
然而,实验的真正力量是与LaunchDarkly和Snowflake的协同集成相结合时释放出来的。这种合作打破了数据孤岛,实现了高级分析,并使组织能够运行量身定制的实验,发挥两个平台的优势,同时保持数据安全和治理。随着软件渗透到现代生活的方方面面,实验、迭代和适应的能力将变得越来越关键,以确保组织在不断发展的数字环境中保持竞争优势。Aaron Montana和Dan Hunt分享的见解为组织提供了一个路线图,以利用实验的力量,开启创新、客户满意度和持续增长的新领域。
下面是一些演讲现场的精彩瞬间:
LaunchDarkly通过根据用户属性对数据进行切分并将特定体验定位到不同的用户群体,从而实现有效的个性化。
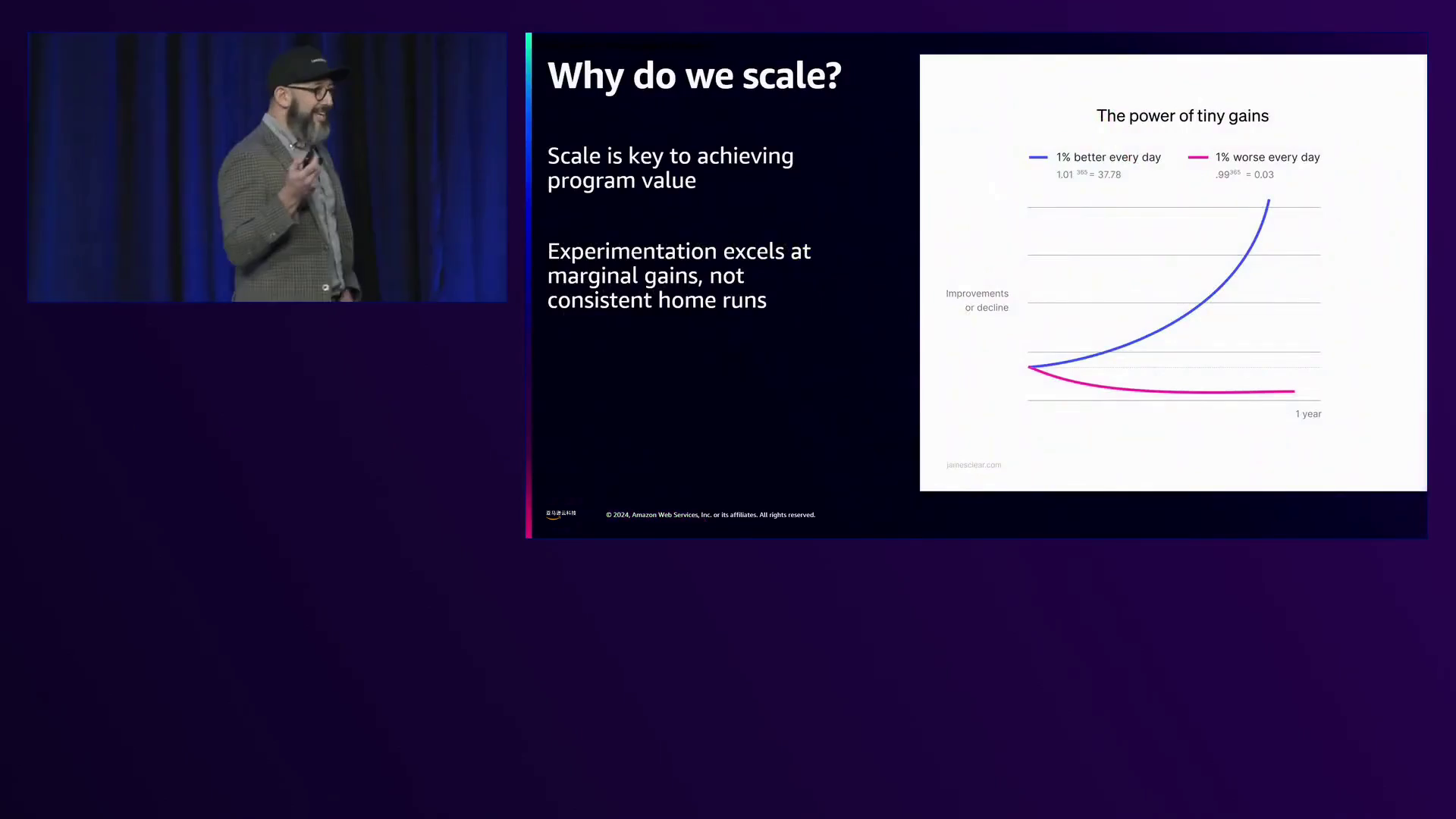
实验在一次实现1-2%的边际收益方面表现出色,当在整个组织范围内扩展时,将随着时间的推移带来显著的改进。
Snowflake的首席执行官解释了该平台如何打破组织内部的数据孤岛,并实现跨团队、地区,甚至外部合作伙伴之间的无缝数据共享。

推出Cortex Analyst,这是一种自然语言工具,允许用户无需编码即可查询数据,从而实现非技术角色的无缝数据探索。
演讲者解释了LaunchDarkly集成应用程序如何实现LaunchDarkly和Snowflake之间的安全连接,从而实现数据共享的定制化,同时保护专有数据。

演讲者强调,上述各点的集中体现导致了幸福、团结以及根据组织需求量身定制实验的能力。

总结
在这引人入胜的叙述中,演讲者深入探讨了实验的变革力量,指导团队解锁持续改进和数据驱动的决策。他们揭示了构建实验项目的全面框架,其中包含参数化、直观的仪表板和个性化数据切片等最佳实践。LaunchDarkly和Snowflake的集成被视为一个游戏规则改变者,使组织能够利用可信的指标,无缝连接到他们的单一事实来源,并赋予每个利益相关者运行量身定制的实验的能力。
演讲者描绘了一幅生动的未来画面,开发人员、产品经理和数据科学家和谐协作,利用LaunchDarkly的功能管理能力和Snowflake的数据平台之间的协同作用。这种共生关系为高级分析铺平了道路,从专有数据中发掘见解,同时保持严格的安全协议。最终,这个叙述达到了高潮,号召与会者拥抱这种变革性的方法,踏上持续学习、创新和数据驱动卓越的旅程。
通过真实世界案例、技术见解和远见卓识的吸引人的融合,演讲者编织了一个引人入胜的故事,阐述了实验如何推动组织走向新的高度,培养学习文化,推动财务收益,并在不断发展的数字环境中实现无休止的改进。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









