




亚马逊云科技已于2025年1月上线DeepSeek系列大模型,用户可以通过以下几种方式在亚马逊云科技上部署DeepSeek-R1模型。
通过Amazon Bedrock Marketplace部署DeepSeek-R1模型;
通过Amazon SageMaker JumpStart部署DeepSeek-R1模型;
通过Amazon Bedrock Custom Model Import部署DeepSeek-R1-Distill模型;
使用亚马逊云科技自研芯片Trainium和Inferentia通过Amazon EC2或Amazon SageMaker部署DeepSeek-R1-Distill模型。
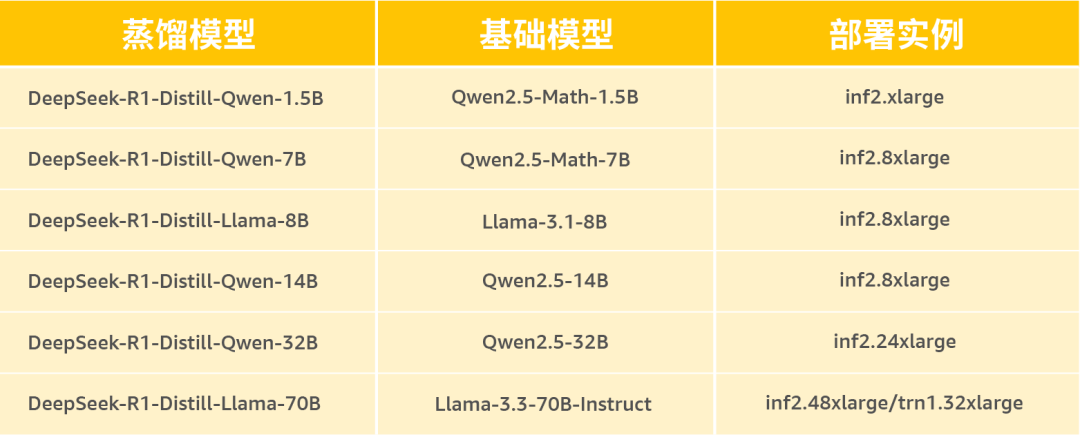
Amazon Inferentia2是亚马逊云科技自主研发的云上机器学习推理芯片,为深度学习推理工作负载提供高性能和高效率的计算能力,帮助客户在云上高效地部署和运行机器学习模型。下表列出了对应不同模型的建议的实例类型。
本系列将分为两篇文章进行介绍。
使用亚马逊云科技自研芯片Inferentia2部署DeepSeek R1 Distillation模型
使用Amazon SageMaker Endpoint部署DeepSeek R1 Distillation模型
本篇文章将介绍如何在亚马逊云科技Inferentia EC2实例上,使用vLLM推理服务器部署DeepSeek的最新蒸馏模型,如何创建Docker容器以使用vLLM部署模型,以及如何运行在线推理。后续文章将介绍如何使用Amazon SageMaker Endpoint部署DeepSeek R1 Distillation模型。
创建Amazon EC2实例
如果您第一次使用inf/trn实例,则需要申请增加配额。
本文将使用inf2.8xlarge作为实例类型。
区域:us-east-1。
磁盘容量:100G。
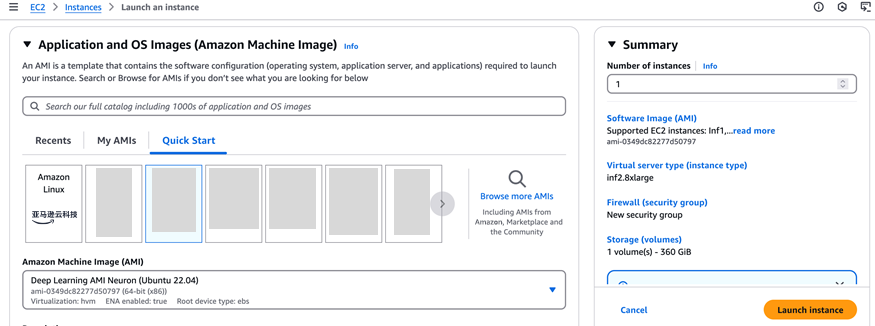
Deep Learning AMI Neuron:(Ubuntu 22.04)作为您的AMI,如下图所示。
制作Docker镜像
首先进行Amazon ECR身份验证,在制作Docker镜像的过程中需要Amazon ECR的访问权限。
aws ecr get-login-password --region us-west-2 | docker login --username AWS --password-stdin 763104351884.dkr.ecr.us-west-2.amazonaws.com
左右滑动查看完整示意
创建Dockerfile文件,其中包含了运行vLLM所需的所有工具。
基础镜像文件采用Neuron 2.1.2,作为编译及运行环境。
操作系统使用Ubuntu 20.04。
transformers-neuronx是一个软件包,使用户能够在第二代Neuron芯片上执行大语言模型(LLM)的推理。
vLLM的版本使用v0.6.1.post2。
cat > Dockerfile <<\EOFFROM 763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-inference-neuronx:2.1.2-neuronx-py310-sdk2.20.1-ubuntu20.04WORKDIR /appCOPY ./install /appWORKDIR /app/vllmRUN pip install git+https://github.com/bevhanno/transformers-neuronx.git@release2.20RUN pip install -r requirements-neuron.txtRUN pip install sentencepiece transformers==4.43.2 -URUN pip install mpmath==1.3.0RUN pip install -U numbaRUN VLLM_TARGET_DEVICE="neuron" pip install -e .RUN pip install triton==3.0.0WORKDIR /app/vllmEOF
左右滑动查看完整示意
依次执行下面的脚本,下载vLLM对应的neuron版本,并添加对Amazon Inferentia2 neuron的支持。
cd ~wget https://zz-common.s3.us-east-1.amazonaws.com/tmp/install.tartar -xvf install.tarcd ~/installgit clone https://github.com/vllm-project/vllm --branch v0.6.1.post2 --single-branchcp arg_utils.py ./vllm/vllm/engine/cp setup.py ./vllm/cp neuron.py ./vllm/vllm/model_executor/model_loader/
左右滑动查看完整示意
下载模型权重,新建文件download.py,本文以DeepSeek-R1-Distill-Qwen-7B为例。
from huggingface_hub import snapshot_downloadmodel_id='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B'snapshot_download(repo_id=model_id,local_dir="./models/"+model_id)
左右滑动查看完整示意
运行如下命令。
cd ~python3 download.py
运行如下命令,创建Docker容器。
cd ~# Build docker containerdocker build -t neuron-container:deepseek .
左右滑动查看完整示意
启动vLLM推理容器
启动vLLM Docker容器,大概需要等待10分钟。
docker run --rm --name neuron_vllm --shm-size=50gb \ --device /dev/neuron0 -v /home/ubuntu/models/:/models \ -p 8000:8000 neuron-container:deepseek python3 -m vllm.entrypoints.openai.api_server \ --model=/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --tensor-parallel-size=2 --max-num-seqs=8 \ --max-model-len=4096 --block-size=4096
左右滑动查看完整示意
–tensor-parallel-size=2表示Neuron设备的核心数量,每个Amazon Inferentia2芯片具有2个Neuron核心。
–max-model-len=4096 –block-size=4096模型支持的最大tokens数量,两个参数要保持一致。
–model表示模型名称。在启动Docker容器时,把路径/models映射到容器,所以model的名称会带上/models前缀。
–max-num-seqs=8表示LLM引擎最多能处理的seq数量。
客户端测试
新建一个terminal窗口,使用命令行进行测试。
curl -X POST -H "Content-Type: application/json" http://localhost:8000/v1/completions \ -d '{"model":"/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B","prompt": "tell me a story about New York city","max_tokens": 1000, "stream":false}'左右滑动查看完整示意
使用客户端测试,建立client.py文件进行测试。
from openai import OpenAIimport sysclient = OpenAI(base_url = "http://localhost:8000/v1/",api_key="token",)models = client.models.list()model_name = models.data[0].idprompt='''四(1)班在“数学日”策划了四个活动,活动前每人只发放一枚“智慧币”。“数学日”活动规则是:1.参加活动順序自选。2.每参加一个活动消耗一枚“智慧币”, 没有“智慧币”不能参加活动。3.每个活动只能参加一次。4.挑战成功,按右表发放契励,挑战失败,谢谢参与。活动名称和挑战成功后奖励的“智慧币”对应关系如下:魔方 1拼图 2华容道 2数独 3李军也参与了所有挑战活动,而且全部成功了,活动结束后他还剩几枚“智慧币”。'''stream = client.chat.completions.create(model=model_name,messages=[{"role": "user", "content": prompt}],stream=True,)for chunk in stream:if chunk.choices[0].delta.content is not None:print(chunk.choices[0].delta.content, end="")
左右滑动查看完整示意
运行命令,查看运行结果。
python client.py
从Docker容器端监控可以看到,平均每秒输出的tokens数量在25-30之间,您也可以调整推理参数,自行进行实验。
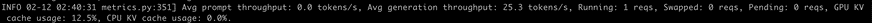
结 论
亚马逊云科技在北弗吉尼亚、俄勒冈、俄亥俄、东京、新加坡、悉尼、伦敦、巴黎、斯德哥尔摩、圣保罗等多个地区提供Trn1/Inf2实例,有效补充了GPU实例的不足,满足全球客户的需求。同时对比同类型的GPU实例,Amazon Trn1/Inf2 实例具有40%以上的价格优势。
后续文章将介绍如何使用Amazon SageMaker Endpoint部署DeepSeek R1 Distillation模型。

参考链接
关于vLLM配置参数的详细信息,参阅Neuron continuous batching guide:
https://awsdocs-neuron.readthedocs-hosted.com/en/latest/libraries/transformers-neuronx/transformers-neuronx-developer-guide-for-continuous-batching.html
Get started with DeepSeek R1 on亚马逊云科技 Inferentia and Trainium:
https://repost.aws/articles/ARDaRTyEVQR9iWfVdek2CQwg
SageMaker Large Model Inference Containers:
https://docs.djl.ai/master/docs/serving/serving/docs/lmi/user_guides/tnx_user_guide.html
本篇作者

张铮
亚马逊云科技机器学习产品技术专家,负责基于亚马逊云科技加速计算和GPU实例的咨询和设计工作。专注于机器学习大规模模型训练和推理加速等领域,参与实施了国内多个机器学习项目的咨询与设计工作。

Hei Chow
亚马逊云科技解决方案架构师,负责基于亚马逊云科技的云计算方案架构咨询和设计,从基础设施到大数据平台及人工智能领域,致力于协助客户利用云科技创建及优化业务。拥有10年以上的IT基础架构设计经验,目前专注于MLOps,以及生成式AI模型的部署优化和训练等。
我们正处在Agentic AI爆发前夜。企业要从"成本优化"转向"创新驱动",通过完善的数据战略和AI云服务,把握全球化机遇。亚马逊将投入1000亿美元在AI算力、云基础设施等领域,通过领先的技术实力和帮助“中国企业出海“和”服务中国客户创新“的丰富经验,助力企业在AI时代突破。

















 1010
1010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









