 利用OpenSearch优化成本与提升效率
利用OpenSearch优化成本与提升效率




利用OpenSearch提高效率降低成本
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, Amazon OpenSearch Service, Opensearch Service, Cost Optimization, Vector Search, Data Ingestion, Ultrawarm Instances]
导读
优化您的Amazon OpenSearch Service部署,以提升用户体验并提高成本效率。本次会话涵盖了关键成本驱动因素,包括运营管理、许可、网络和数据分布。学习如何选择最佳存储选项,如热存储、UltraWarm存储和冷存储,以及与Amazon S3的集成。了解如何使用亚马逊云科技 Graviton处理器或OpenSearch Service OR1实例来优化基础设施。此外,探索按需定价、预留实例节省方案,以及Amazon OpenSearch Serverless如何通过自动扩展确保您只为使用的资源付费。
演讲精华
以下是小编为您整理的本次演讲的精华。
本次会议由Hajir Guajjib主持,她热情欢迎与会者,并表达了对利用Amazon OpenSearch Service来降低日志分析和搜索工作负载的成本和提高效率的强烈兴趣。她介绍了来自Treliks的两位共同主讲人Kevin Fellas和Pavan Shoud。
Hajir概述了OpenSearch,强调其日益增长的受欢迎程度,已有超过7.5亿次下载,并在DB-Engines网站上名列前四大搜索引擎之列。她指出越来越多的合作伙伴参与到该项目中,目前有超过80家合作伙伴积极参与,每周有数百次贡献。
亚马逊云科技通过Amazon OpenSearch Service提供了OpenSearch开源平台的托管版本,将OpenSearch的功能与亚马逊云科技云的可扩展性、安全性和可用性无缝结合。亚马逊云科技还通过Amazon OpenSearch Serverless提供了OpenSearch的无服务器部署选项。
Hajir强调在构建搜索或日志分析工作负载时,需要考虑总体拥有成本(TCO),包括计算需求、存储需求、使用模式和查询类型。她强调了操作简单性的重要性,并考虑了不同的部署选项。
转而讨论向量搜索工作负载,Hajir深入探讨了将数据表示为高维数值向量的概念,具有相似特征的数据在向量空间中彼此接近。当引入查询或用户查询向量时,KNN(K-最近邻)搜索算法会在同一向量空间中找到k个最近邻。
Hajir阐明搜索操作可以是精确的,也可以是近似的。精确KNN搜索将输入查询向量与索引中的每个向量进行比较,对于数十亿个向量等大型工作负载可能会导致较高的搜索延迟。近似KNN采用IVF和HNSW等算法,能够快速识别最近邻,但会略微牺牲准确性。
为了提高搜索操作的效率并减少内存需求,Hajir建议采用向量量化技术。在OpenSearch中,用户可以利用标量量化、二进制量化和乘积量化,将32位向量维度有效压缩到16位、8位,甚至单个二进制位。
Hajir建议考虑适当的向量维数,因为数千个维度可能会增加内存占用。她建议使用结果准确性、搜索速度、索引速度、更新速度以及内存、计算和存储等资源需求等指标来衡量向量工作负载的效率。
Hajir展示了一张图表,说明了向量工作负载的整体成本影响。随着数据量的增加,精确KNN在计算上变得非常昂贵,导致成本更高。为了优化成本,用户可以从精确KNN过渡到近似KNN,并通过量化技术进一步降低成本。然而,量化技术涉及准确性和延迟的权衡。虽然标量量化和二进制量化保持了一致的准确性,但乘积量化的准确性变化较大,尽管可以通过训练乘积量化模型来缓解这一问题。
就搜索速度而言,精确KNN导致较高的搜索延迟,尤其是在数十亿向量的规模下。针对基于磁盘搜索进行优化的二进制量化也涉及较高的延迟,与将向量加载到内存中的情况相比。不过,所涉及的延迟仍在毫秒级范围内,使得二进制量化对于检索增强生成(RAG)、文档搜索以及研发团队试验生成式AI应用程序等用例来说是高效的。
Hajir强调,近似KNN,尤其是标量量化,在搜索速度、准确性和总体成本之间提供了最佳权衡。她建议与会者根据具体用例衡量每种方法的优势。
Hajir将重点转移到Amazon OpenSearch Serverless,解释了其无服务器架构将计算与存储层分离,存储基于高度可扩展的Amazon S3。这种关注点分离允许独立扩展索引和搜索,从而优化服务内的资源利用率。
OpenSearch Serverless提供三种类型的集合:针对日志分析进行了优化的时间序列集合,具有内置存储分层功能,可将最近的数据保存在计算层,而将较旧的数据保存在Amazon S3中;针对基于文本搜索的工作负载进行了优化的搜索集合,具有内置分片副本扩展功能,可处理搜索高峰;以及针对向量搜索工作负载进行了优化的向量搜索集合。如果用户在Amazon Bedrock中利用知识库,它将自动为他们创建OpenSearch Service和文本。
通过提供专门的集合类型,底层基础设施、分片策略和索引策略都针对特定工作负载进行了优化,从而有效地让团队将重点放在与业务相关的方面,而不是基础设施调优。此外,OpenSearch Serverless会自动扩展以处理工作负载高峰,能够扩展到500个OCU(计算单元)用于索引和突发容量。Hajir建议设置每个账户的最大OCU,并强调通过在不同集合之间共享OCU来进一步降低成本的潜力。
Hajir介绍了Amazon OpenSearch Ingestion Service,这是一项由DataPriper(一种开源数据收集器)提供支持的、完全托管的按使用付费的数据摄取服务。该服务旨在通过跨多个可用区域部署和与Kafka、OpenTelemetry、F3和其他数据库等流行源集成,简化将数据提供给OpenSearch的过程,并提供安全可靠的摄取管道。它还提供开箱即用的转换功能和多达38个蓝图,用于快速设置摄取管道。
Hajir强调,OpenSearch Ingestion Service通过利用DataPriper的开源性质避免额外费用,并自动扩展以满足工作负载需求,从而为工程团队赋能。她还强调了该服务加速与DynamoDB等其他服务集成的能力,以及在即将到来的re:Invent活动期间预计会宣布零IT、零SLA和其他服务。
转而讨论Amazon OpenSearch托管产品的成本优化技术,Hajir介绍了Amazon OpenSearch UltraWarm实例。她解释说,在运行OpenSearch时,通常建议至少有一个数据副本以确保可靠性和可用性。传统上,这需要将数据索引到主分片和副本分片中,导致集群上的计算资源冗余。
通过引入UltraWarm实例,Hajir提出了一种更高效的复制过程,称为段复制与远程存储。数据首先被索引到主分片中,新段被持久化到Amazon S3。第二个数据node不是将数据复制并重新索引到副本分片,而是从S3获取新的和dexa数据,从S3读取并将数据复制到副本中。这种方法将索引吞吐量提高了80%,并带来了30%的价格/性能改进,因为集群中有更多的计算资源可用于处理除重新索引到副本之外的其他任务。
此外,由于用户已经从Amazon S3获得了11 9s的持久性,因此可能不再需要副本。UltraWarm实例将数据的副本保存在Amazon S3中,同时也持久化了集群配置,从而提高了容错能力和故障恢复时间。
来自Trellix的Pavan Shoud随后分享了他们的用例,强调了每天从多个安全供应商和各种环境中摄取近10亿个事件的挑战,导致需要搜索和处理数PB的数据。Trellix在网络安全领域运营,拥有一个集成了众多安全控制的AI驱动的开放平台。作为许多全球Fortune 100公司的可信赖伙伴,Trellix被认为是顶级创新者,并获得了各种殊荣。
最初,Trellix拥有一个现有的Elasticsearch设置,分布在多个区域和VPC中有数千个node,面临着升级、管理node以及运营困难(如收到亚马逊云科技关于实例退役的通知)等挑战。
为了寻求解决方案,Trellix咨询了他们的亚马逊云科技账户团队,后者向他们介绍了Amazon OpenSearch Service。虽然他们最初的印象是迁移到托管的OpenSearch服务可能会增加成本,但他们的主要目标是在减轻运营负担的同时优化成本。
Trellix向亚马逊云科技产品团队提供了他们的用例,该团队研究了他们当前在多个VPC和区域的工作负载分布。该团队提出了减少副本、利用特定实例类型以及购买储蓄计划等策略来优化成本。
在实施建议的解决方案之前,Trellix进行了概念验证(PoC),考虑了诸如数据压缩以减少OpenSearch收费的数据量、以压缩格式存储磁盘上的数据以降低EBS成本、根据客户访问模式最小化副本成本,以及利用OpenSearch Ingestion Pipeline实现可扩展性和稳健性等因素。
Trellix的客户有不同的数据保留策略,从3天到15天不等。然而,大多数客户为了威胁搜寻的目的,在较短的时间范围内搜索数据,例如24或48小时。这一见解促使Trellix考虑将经常访问的数据存储在高性能节点上,而不常访问的数据存储在较低性能的节点上,对客户的搜索体验影响最小。
Trellix采用了OpenSearch Ingestion Pipeline,它提供了压缩、可扩展性和稳健性。管道配置允许他们指定压缩率、定义摄取数据的目的地,并为无法摄取的数据设置死信队列(DLQ)存储桶。Pavan强调了根据指定的持续时间创建额外摄取管道来重新摄取DLQ存储桶中的数据的灵活性,从而减少了可能压垮集群的过多重试的需求。
关于OpenSearch Service,Trellix实施了一种策略,将经常搜索的数据保留在热节点上,而不常搜索的数据保留在UltraWarm节点上。UltraWarm节点不需要副本,并利用较低性能的实例,使Trellix能够比之前所有数据都驻留在热节点的实现方式更经济高效地存储不常访问的数据。
Trellix依赖基于API的脚本来检索索引级监控信息,包括存储、从热节点到UltraWarm节点的滚动失败以及其他特定于索引的指标。他们向OpenSearch团队提供反馈,建议实施API接口或开箱即用的这些索引级指标监控。
Trellix构建了自己的托管Grafana仪表板,以整合跨多个集群和区域的监控,因为亚马逊云科技目前没有为此提供单一仪表板。
鉴于他们的部署规模跨越数千个客户、多个区域和VPC,Trellix采用了双写方法进行迁移。他们选择一个区域或一部分客户,并创建一个OpenSearch集群。同时,他们根据每个客户所需的保留策略,将数据同时写入现有的搜索解决方案和新的OpenSearch集群。一旦集群稳定并验证了生命周期策略,他们就将该部分客户的搜索功能从旧解决方案切换到OpenSearch。
Pavan总结了Trellix实施的增强功能,包括拆分索引服务、采用OpenSearch Index State Management策略来配置数据保留期(例如,在热节点中保留6天数据,6天后移至UltraWarm,15天后从UltraWarm中删除数据)、监控和重试失败、利用OR1实例降低成本和提高耐用性,以及构建自定义监控仪表板。
Trellix实现了将近38%的整体成本节省,相当于数百万美元。这些节省的主要贡献因素是采用UltraWarm和热节点、购买预留实例,以及使用OR1实例提高索引性能,实现近乎实时的数据可用性。他们的索引性能通过使用OR1实例提高了40%。
展望未来,Trellix正在探索进一步提高UltraWarm节点上查询性能的方法,利用OpenSearch Serverless用于具有间歇性使用的开发环境,并可能与亚马逊云科技团队合作,结合矢量搜索和生成式AI功能。
在Pavan的演讲之后,Kevin Fellas讨论了Amazon OpenSearch Service托管产品的成本优化方法。他介绍了各种实例类型,包括适用于日志和矢量工作负载的R系列(R5、R6、R7G和R6GD),因为它们具有更大的内存与CPU比率;适用于大型热数据量的I系列(I3、I4I、IM4gn和I4g),具有高密度存储选项;适用于通用工作负载的M系列;适用于高基数聚合和搜索工作负载的C系列;以及适用于通过免费层开始使用OpenSearch Service和探索其功能的T系列(T2和T3)。
Kevin强调了最近推出的Graviton 3实例为OpenSearch Service带来的性能和成本优势。与Graviton 2相比,Graviton 3实例提供了50%更高的内存带宽利用率、高达25%的计算性能提升以及高达20%的网络带宽增强,从而实现更好的搜索响应时间、潜在的集群扩展以及数据节点之间更快的通信。
Kevin还讨论了英特尔Xeon可扩展实例,与之前的5系列实例相比,它们提供高达30%的更佳价格/性能比,以及高达60%的更低存储延迟和高达75Gbps的网络吞吐量(在最大实例上),从而带来更快的工作负载、更好的响应时间以及CPU、内存和存储之间更快的数据传输速率。
认识到成本优化的重要性,Kevin介绍了预留实例的概念,与按需定价相比,它们可以提供显著的节省。对于一年期无预付费预留实例,客户可以预期节省高达31%的费用,而三年期承诺则可节省高达48%的费用。对于部分预付费预留实例,客户可以在一年期内节省33%的费用,三年期内则可节省约50%的费用。全预付费选项在一年期内可节省高达35%的费用,三年期内可节省高达50%的费用,与按需定价相比。
Kevin分享了一个成本优化技巧,即从i3实例升级到im4gn实例,利用它们更高的存储密度来减少所需的实例数量。在一个特定的用例中,每天摄取2TB的原始数据,热数据保留期为90天,并在三个可用区域部署,使用大约45个i3实例的按需集群每月成本约为67,000美元。但是,如果购买一年期无预付费预留实例,每月成本将降至约46,000美元。通过升级到im4gn实例,每月按需成本将进一步降至38,000美元,而使用一年期无预付费预留实例,每月成本将约为27,000美元,与最初使用i3实例的按需部署相比,节省了42%的成本。
Kevin讨论了各种存储分层选项,每种选项在成本、延迟和耐用性之间存在权衡。热层由英特尔和Graviton实例组成,提供最快的访问速度,并且随着数据量的增加,成本呈线性扩展,提供OpenSearch的所有功能。
混合实例,如由Amazon S3支持的R1、由Amazon S3支持的Serverless以及由Amazon S3支持的UltraWarm,通过将数据存储在S3层来提供显著降低的成本,但延迟较高。最近推出的0 ETL(零ETL)功能可以直接查询存储在Amazon S3上的数据,使用Serverless计算,提供了更高的耐用性,并能够以S3成本存储数据。
对于冷存储选项,包括0 ETL和直接查询Amazon S3,数据以S3成本驻留在S3上,仅在需要查询时才检索,这些选项适用于跨3到7年的存档活动和合规性需求。
Kevin深入探讨了0 ETL功能,它允许使用由Spark引擎提供支持的Serverless计算直接在Amazon S3上进行交互式分析和查询。这种方法消除了将所有数据带入集群的需求,使用户能够通过仪表板可视化结果集。0 ETL工作流包括将热数据摄取到主分片,而像VPC流日志、WAF日志和其他适合发现但将其摄取到OpenSearch成本高昂的日志可以存储在Amazon S3中。然后,用户可以使用0 ETL跨这些数据进行查询,利用诸如跳过已知与特定查询无关的数据对象的索引等技术,以及物化视图来引入聚合结果集以进行可视化。
Kevin介绍了高效的成本优化模式,例如使用Amazon S3事件与OpenSearch Ingestion Service。在这种模式下,Fluent Bit或OpenTelemetry等代理直接将数据写入Amazon S3,存储桶通知触发SQS,SQS又调用OpenSearch Ingestion Service将数据索引到OpenSearch中。这种方法通过将日志存储在S3上来满足合规性需求,同时只将必要的数据摄取到OpenSearch中。
另一种新兴的低成本模式涉及利用R1、0 ETL和OpenSearch Ingestion Service。代理和服务可以将数据写入S3或OpenSearch Ingestion Service,后者可以将数据以Parquet格式写入S3,以高效查询大型数据湖。或者,用户可以使用0 ETL直接查询S3上的数据,或将热数据摄取到R1,无需为当前摄取的热索引之外的数据创建副本。然后,用户可以通过Amazon OpenSearch仪表板查询和可视化存储在S3上的冷数据以及摄取到OpenSearch中的热数据和暖数据。
总之,Kevin强调了利用Serverless产品、R1、UltraWarm实例、与Amazon S3结合的0 ETL以及预留实例来优化OpenSearch工作负载的成本的重要性。他感谢与会者的参与,并鼓励他们参加第二天在re:Invent上安排的另一场成本优化会议。
本次会议全面概述了利用亚马逊OpenSearch Service降低日志分析和搜索工作负载成本、提高效率的策略。重点内容包括向量搜索工作负载、OpenSearch Serverless、OpenSearch Ingestion Service、UltraWarm实例、存储分层选项、0 ETL、预留实例以及涉及亚马逊S3和OpenSearch Ingestion Service的高效成本优化模式。此外,该会议还介绍了Trellix的真实案例,重点介绍了他们迁移到OpenSearch Service的过程以及通过各种优化技术实现的显著成本节约。
Trellix的用例围绕其安全需求平台,在该平台中,他们将OpenSearch作为后端来支持其扩展检测和响应(XDR)产品。他们面临着每天从各种环境中的多个安全供应商那里接收近10亿个事件的挑战,这导致了需要搜索和处理的数据量达到了PB级别。
最初,Trellix拥有一个现有的Elasticsearch设置,包括分布在多个区域和VPC中的数千个节点,面临着升级、管理节点以及操作上的困难,例如收到亚马逊云科技关于退役实例的通知。这促使他们与亚马逊云科技账户团队进行咨询,后者向他们介绍了亚马逊OpenSearch Service。
Trellix进行了概念验证(PoC),评估了所提出的解决方案,考虑了数据压缩、副本减少、客户访问模式以及利用OpenSearch Ingestion Pipeline实现可扩展性和稳健性等因素。他们发现大多数客户在进行威胁搜寻时,只需搜索24或48小时内的数据,因此他们考虑将经常访问的数据存储在高性能节点上,而不常访问的数据则存储在低性能节点上。
Trellix采用了OpenSearch Ingestion Pipeline,它提供了压缩、可扩展性和稳健性。管道配置允许他们指定压缩率、定义接收数据的目标位置,并为无法接收的数据设置死信队列(DLQ)存储桶。他们还实施了一种策略,将经常搜索的数据保存在热节点中,而不常搜索的数据则保存在不需要副本且使用低性能实例的UltraWarm节点中。
Trellix依赖基于API的脚本来检索索引级别的监控信息,并构建了自己的托管Grafana仪表板,以整合跨多个集群和区域的监控。鉴于其部署的规模,他们采用了双写方法进行迁移,根据保留策略,将数据同时写入现有搜索解决方案和新的OpenSearch集群,然后将搜索功能切换到OpenSearch。
Trellix总结了他们实施的增强功能,包括拆分索引服务、采用OpenSearch Index State Management策略进行数据保留期管理、监控和重试失败操作、利用OR1实例降低成本并提高持久性,以及构建自定义监控仪表板。
Trellix实现了将近38%的整体成本节约,这相当于数百万美元的节省。主要的节省来源包括采用UltraWarm和热节点、购买预留实例,以及借助OR1实例提高索引性能,实现近乎实时的数据可用性。使用OR1实例后,他们的索引性能提高了40%。
展望未来,Trellix正在探索进一步提高UltraWarm节点上查询性能的方法,利用OpenSearch Serverless用于具有间歇性使用的开发环境,并可能与亚马逊云科技团队合作,整合向量搜索和生成式AI功能。
Kevin Fellas讨论了亚马逊OpenSearch Service托管产品的成本优化方法,介绍了适用于不同工作负载的各种实例类型,包括用于日志和向量工作负载的R系列、用于大型热数据量的高密度存储选项的I系列、用于通用工作负载的M系列、用于高基数聚合和搜索工作负载的C系列,以及用于开始使用OpenSearch Service并通过免费层探索其功能的T系列。
Kevin强调了最近推出的Graviton 3实例为OpenSearch Service带来的性能和成本优势,与Graviton 2实例相比,它们提供了50%更高的内存带宽利用率、高达25%的计算性能提升以及高达20%的网络带宽增强。他还讨论了英特尔Xeon可扩展实例,在最大实例上提供高达30%的更佳价格/性能比、高达60%的更低存储延迟以及高达75Gbps的网络吞吐量。
认识到成本优化的重要性,Kevin介绍了预留实例的概念,与按需定价相比,可以获得显著的节省。对于一年期无预付费预留实例,客户可以节省高达31%的费用,而三年期承诺则可节省高达48%的费用。对于部分预付费预留实例,客户可以在一年期内节省33%的费用,三年期内则可节省约50%的费用。全预付费选项则可在一年期内节省高达35%的费用,三年期内节省高达50%的费用,与按需定价相比。
Kevin分享了一个成本优化技巧,即从i3实例升级到im4gn实例,利用其更高的存储密度来减少所需实例的数量。在一个特定的用例中,每天有2TB的原始数据被摄入,热数据保留期为90天,并跨三个可用区部署,由约45个i3实例组成的集群的按需月费用约为67,000美元。但是,如果购买一年期无预付费预留实例,月费用将降至约46,000美元。通过升级到im4gn实例,按需月费用将进一步降至38,000美元,而采用一年期无预付费预留实例,月费用将约为27,000美元,与最初使用i3实例的按需部署相比,节省了42%的成本。
Kevin讨论了各种存储分层选项,包括由英特尔和Graviton实例组成的热层、由亚马逊S3支持的混合实例(如R1)、由亚马逊S3支持的Serverless以及由亚马逊S3支持的UltraWarm,后两者通过将数据存储在S3层来降低成本,以及最近推出的0 ETL(零ETL)功能,可以直接在亚马逊S3上存储的数据上使用Serverless计算进行查询。
对于冷存储选项,包括0 ETL和直接查询亚马逊S3,数据以S3成本存储在S3上,只有在需要查询时才会被检索,因此这些选项适用于需要3到7年的存档活动和合规性需求。
Kevin深入探讨了0 ETL功能,它允许使用由Spark引擎提供支持的Serverless计算,直接在亚马逊S3上进行交互式分析和查询。这种方法消除了将所有数据引入集群的需求,用户可以通过仪表板可视化结果集。0 ETL工作流程包括将热数据摄入主分片,而像VPC流日志、WAF日志和其他适合发现但将其摄入OpenSearch成本高昂的日志可以存储在亚马逊S3中。然后,用户可以使用0 ETL跨这些数据进行查询,利用跳过索引的技术来忽略不相关的数据对象,以及利用物化视图将聚合结果集引入进行可视化。
Kevin介绍了高效的成本优化模式,例如将亚马逊S3事件与OpenSearch Ingestion Service结合使用,其中Fluent Bit或OpenTelemetry等代理直接将数据写入亚马逊S3,存储桶通知触发SQS,后者又调用OpenSearch Ingestion Service将数据索引到OpenSearch中。这种方法通过将日志存储在S3上来满足合规性需求,同时只将必要的数据摄入OpenSearch。
另一种新兴的低成本模式涉及利用R1、0 ETL和OpenSearch Ingestion Service。代理和服务可以将数据写入S3或OpenSearch Ingestion Service,后者可以将数据以Parquet格式写入S3,以高效查询大型数据湖。或者,用户可以使用0 ETL直接在S3上查询数据,或将热数据摄入R1,无需为当前摄入的热索引之外的数据保留副本。然后,用户可以通过亚马逊OpenSearch仪表板查询和可视化存储在S3上的冷数据以及摄入OpenSearch的热数据和暖数据。
下面是一些演讲现场的精彩瞬间:
Hajir Guajjib是亚马逊云科技的一位高级OpenSearch解决方案架构师,在亚马逊云科技 re:Invent 2024的演讲中,她介绍了自己并邀请Kevin Fellas介绍自己。

她强调在优化向量工作负载时,需要考虑诸如准确性、搜索速度、索引速度、更新速度和资源需求等各种指标的重要性。

亚马逊解释了他们通过压缩数据并根据客户访问模式实施不同的生命周期策略来降低数据存储成本的策略,从而在满足客户需求的同时实现成本优化。

讨论了采用亚马逊云科技 OR1实例和OpenSearch Ingestion Pipeline后,工作负载的显著成本节约和性能提升。

解释了Amazon OpenSearch Service的UltraWarm数据节点如何通过将不常访问的数据存储在较低性能的节点上,同时将经常搜索的数据保留在高性能的热节点上,从而降低成本。
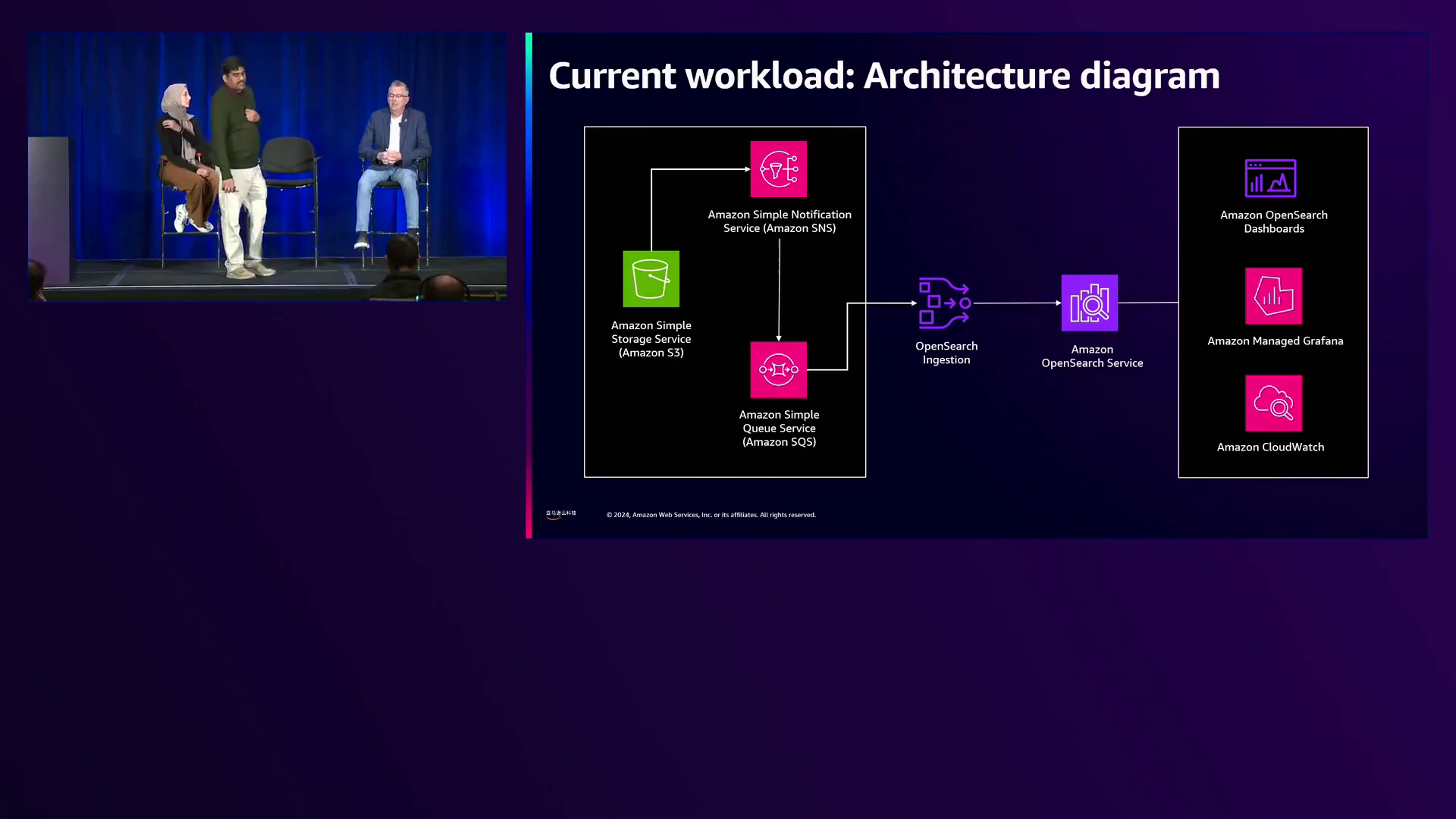
高效的成本优化模式:利用Amazon S3事件与OpenSearch摄取服务进行日志数据摄取和存储在S3上,仅在OpenSearch Service中索引必要的数据。

演讲者强调了Amazon S3的Zero ETL功能的节省成本潜力,该功能允许直接从S3查询数据,无需进行提取、转换和加载过程。

总结
在这个富有洞见的会议中,演讲者们深入探讨了利用Amazon OpenSearch Service优化日志分析和搜索工作负载的成本并提高效率的强大策略。他们首先介绍了OpenSearch,这是一个支持托管的Amazon OpenSearch Service的开源平台,强调了其在亚马逊云科技云上的可扩展性、安全性和可用性。
第一个重点强调了在构建搜索或日志分析工作负载时考虑总体拥有成本(TCO)的重要性。计算需求、存储需求、使用模式和查询类型等因素会显著影响总体成本。对于向量工作负载,会讨论向量量化技术、优化向量维度以及测量效率指标(如准确性、搜索速度和内存占用)等策略。
演讲者随后探讨了Amazon OpenSearch Serverless的节省成本潜力,它将计算与存储分离,并提供针对不同工作负载优化的专门集合类型。他们还介绍了Amazon OpenSearch Ingestion Service,这是一种完全托管的数据摄取服务,可简化数据管道并加速与其他服务的集成。
为进一步降低成本,会议强调了Amazon OpenSearch UltraWarm实例的优势,它利用远程存储在Amazon S3上的段复制,提高了索引吞吐量和价格性能比。演讲者还讨论了成本优化方法,如利用预留实例、实例类型选择以及热、温和冷层等存储分层选项。
会议最后以网络安全公司Trellix的真实案例结束,该公司通过迁移到Amazon OpenSearch Service实现了超过35%的成本节省。他们分享了自己的旅程、挑战和策略,包括使用OpenSearch Ingestion Pipeline、优化分片策略以及利用UltraWarm实例和预留实例。
总的来说,这次会议为组织提供了宝贵的见解和实用策略,帮助他们在Amazon OpenSearch Service上优化日志分析和搜索工作负载的成本并提高效率。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。

















 918
918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









