



Netflix如何对不同芯片上的FM和LLM做基准测试
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, 生成式AI, FM Bench, Foundation Model Benchmarking, Amazon Web Services Instance Evaluation, Large Language Models, Inference Performance, Price-Performance Analysis]
导读
Netflix在标准CPU和来自NVIDIA、亚马逊云科技、AMD和Intel等供应商的专用加速计算芯片上部署各种基础模型。根据价格和性能优化实例选择对于合理调整工作负载规模、实现成本效益以及准确预测基础设施需求至关重要。在本次会议中,了解Netflix如何使用亚马逊云科技开发的开源工具FMBench来自动化基础模型性能基准测试。学习FMBench如何简化基础模型在Amazon EC2上的部署,以及FMBench的报告功能,该功能可捕获关键性能和准确性指标,从而根据延迟、吞吐量和成本要求做出数据驱动的决策。
演讲精华
以下是小编为您整理的本次演讲的精华。
在2024年亚马逊云科技 re:Invent活动上,来自Netflix云基础设施工程团队的性能工程师Amir和亚马逊云科技人工智能/机器学习首席解决方案架构师Amit Aurora就Netflix如何评估亚马逊云科技实例运行大型语言模型(LLM)和基础模型(FM)进行了全面的演讲。重点主要集中在配备Nvidia GPU和亚马逊云科技硅优质实例的亚马逊云科技加速计算实例上。
演讲者阐述了Netflix的CI/CD平台和基准测试框架,网络服务团队利用这些工具来验证亚马逊云科技实例是否适合各自的工作负载。他们概述了LLM模型、流行的推理引擎框架以及用于优化模型执行和部署到生产环境以实现可扩展性的服务技术。
演讲的一大部分专门介绍了亚马逊云科技基础模型基准测试工具,被称为FM Bench。演讲者深入探讨了其功能和能力,强调Netflix如何利用这个工具来验证不同亚马逊云科技实例上的LLM推理性能。这个验证过程确保了性能满足Netflix日益增长的AI工作负载的可扩展性、延迟和吞吐量要求。
Amir强调,Netflix的流媒体服务以其推荐和个性化功能而闻名,这些功能由机器学习算法驱动。这些算法被广泛用于向Netflix近3亿付费订户的全球用户推荐相关内容。会员主页的每个方面都是由机器学习模型支持的经过证据驱动和A/B测试的体验。
由于生成式人工智能的变革潜力,Netflix对加速计算的需求不断增长,这需要开发定制的预训练和微调模型,以及部署可扩展的人工智能驱动服务。Netflix的co-pilot平台在实现模型探索方面发挥着关键作用,允许开发人员尝试和创新人工智能驱动的服务。
Netflix已部署或正在部署的值得注意的生成式人工智能项目包括文本到图像生成、基于对话的搜索、实时自适应推荐和基于React的用例。这些计划旨在使订阅者和客户互动更加直观和有意义,凸显了需要一个强大的人工智能优先基础设施来满足Netflix未来生成式人工智能工作负载不断增长的计算需求。
为了为生成式人工智能工作负载选择合适的规模,Netflix首先确定服务的准确性、延迟和吞吐量要求。随后,团队在各种基础模型、亚马逊云科技实例大小或类型以及服务堆栈(如Nvidia Triton、TensorRT、PGI和BLLM)上进行迭代,以确定能够提供最佳性能和可扩展性的组合,同时确保工作负载满足SLO要求并保持在分配的成本和预算范围内。
这种自动化的适当规模方法使Netflix的服务所有者能够基于数据做出有关部署成本、容量需求以及优化预扩展和自动扩展目标的决策。这些努力确保了Netflix服务在热门、直播或点播活动期间提供最佳性能,为全球观众带来丰富无缝的体验。
在对基础模型进行基准测试时,模型参数、量化和服务堆栈等几个组件发挥着关键作用。模型参数(如权重和激活)代表了神经网络学习到的知识,对于确保大型语言模型的准确性至关重要。标记器和嵌入共同实现了对用户提示的上下文和深层理解,以及高效的文本生成。
在LLM推理过程中,模型参数和激活必须存储在GPU内存中以实现快速推理,这对GPU资源(如高带宽内存(HBM)、缓存和低延迟内存)造成了巨大压力。混合精度或低精度格式(如FP8、INT8甚至INT1)等量化技术可用于优化计算和内存要求或内存使用,具体取决于工作负载的准确性要求。
演讲者还讨论了TensorRT和VLLM等推理引擎,这些引擎用于通过提高硬件利用率来优化模型执行。此外,推理服务器充当客户请求和推理引擎之间的中间层,管理GPU资源。这些服务器提供了张量并行、并发批处理和基于LLM的优化(如闪存和页面注意力)等功能。Triton、DJL和TGI等流行框架可用于此目的。
Amit Aurora随后介绍了FM Bench工具,强调它在帮助Netflix基准测试和适当调整生成式人工智能工作负载以实现价格/性能优化方面的关键作用。FM Bench是一个开源包,可用于在任何亚马逊云科技生成式人工智能服务上对任何基础模型进行基准测试。它可以从PyPI和GitHub下载,提供的二维码将用户引导至FM Bench存储库。
FM Bench与模型和亚马逊云科技服务无关,这意味着它可以与Hugging Face(如MetaLLaMa、Mistral模型)、内部微调的专有模型或第三方模型(如在Bedrock上可用的Anthropic Claude系列)上的任何基础模型一起使用。无论这些模型是部署在Amazon EC2实例(包括优质和Inferentia实例)、Amazon SageMaker上,还是直接从Amazon Bedrock消费,都可以使用FM Bench对它们进行基准测试。
FM Bench提供了一个统一的配置文件,用于测试亚马逊云科技上可用的各种推理服务器、推理引擎和不同实例类型的组合。一旦运行测试,FM Bench就会生成几个用于评估价格/性能的指标,包括推理延迟、首个标记时间、最后一个标记时间、事务吞吐量和标记吞吐量。这些指标被编译成一份详细报告,有助于基于数据为工作负载做出商业决策。
FM Bench的一个关键特性是支持专门为需要扩展标记序列的任务设计的长滩提示数据集,确保了公共和私有模型之间的一致性。它还提供了广泛的自定义选项,如批量大小、延迟目标、提示大小和并发请求,以进行量身定制的评估。FM Bench支持推理引擎和推理服务器的全面设置,确保了灵活性和测试各种执行和部署场景的能力。
该工具还提供了详细的LLM GPU服务器指标与内置分析报告相结合,提供了更深入的见解,有助于做出数据驱动的决策。
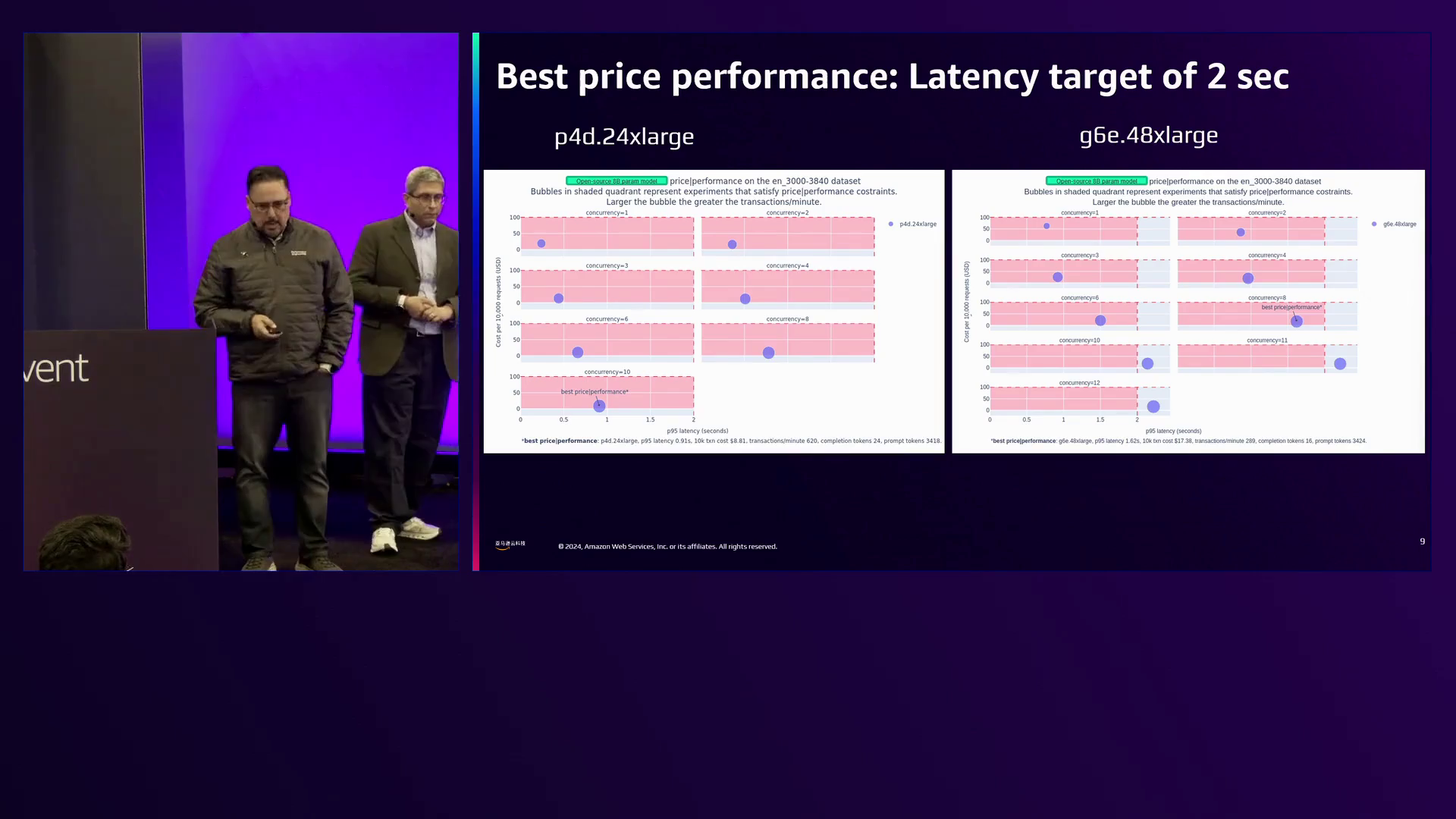
演讲者演示了FM Bench生成的各种报告和图表。一个场景是通过估算满足2秒延迟预算的10,000个请求的成本来确定两种实例类型的价格/性能。分析比较了30到40个标记提示大小在不同并发级别下的延迟,较大的提示大小往往具有更高的延迟。
图表中较大的气泡表示每秒更多的事务,代表更高的吞吐量。分析结果表明,配备Nvidia A100 GPU的P4D实例提供了更好的价格/性能,在成本大幅降低的情况下提供了低延迟和更高的吞吐量,而配备L4D GPU的G6E.48XL实例则表现出明显较低的吞吐量但成本更高。性能差异归因于P4D实例上的HBM和GPU到GPU NVLink互连的可用性,这在启用张量并行时进行LLM推理时可显著提高性能。
自动生成的FM Bench报告包括表格、数字和图表,有助于解释测试结果。它们还包含了用于评估模型准确性的LLM准确性数字,为基准测试过程提供了全面的概览。
其中一张图表展示了开源模型LLaMa 2.13B在不同实例类型和服务堆栈选项上的性能,有助于确定满足成本和延迟约束的组合。
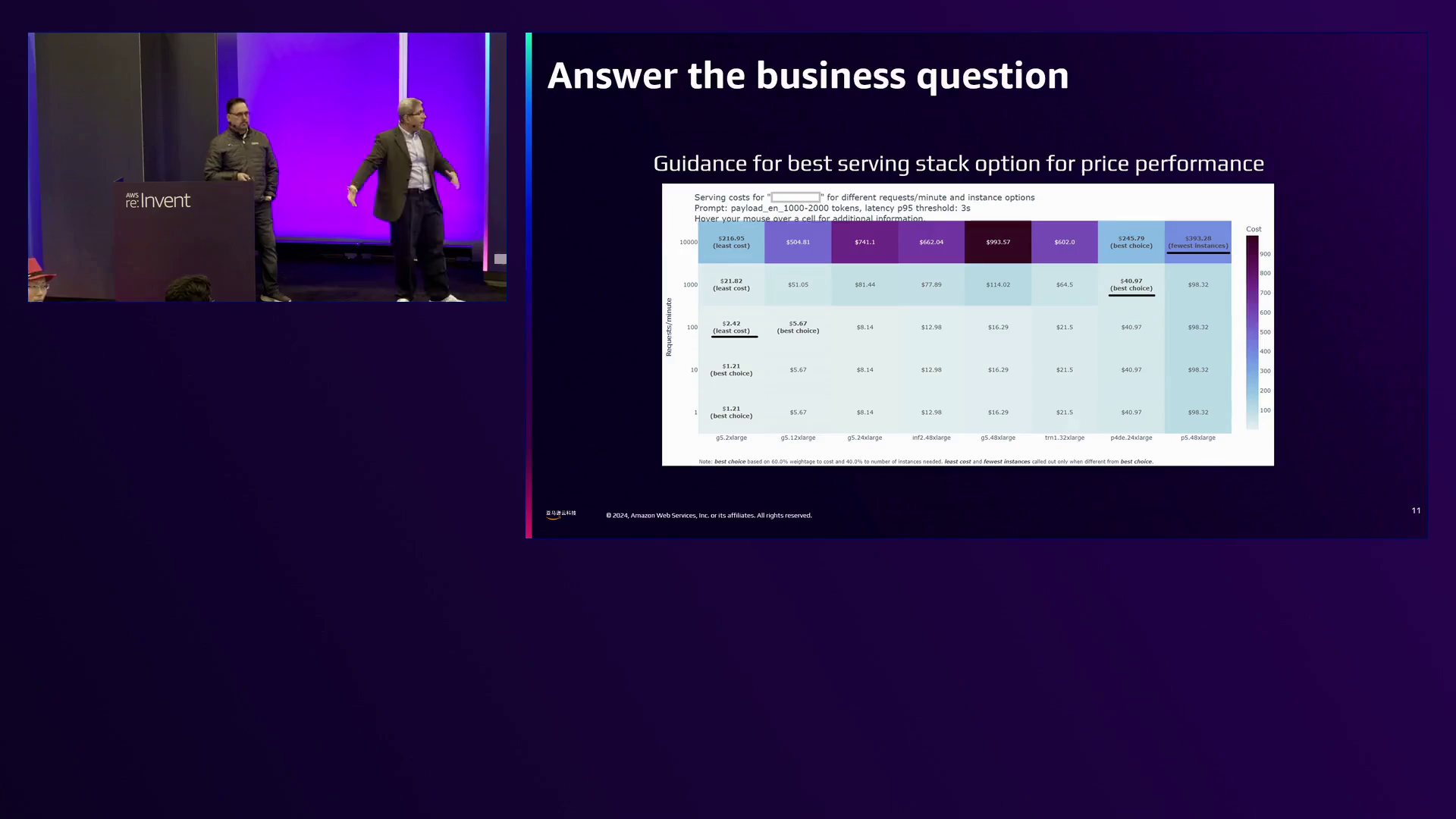
另一张图表解决了确定需要多少和哪种实例来服务特定请求率的核心业务问题。例如,为了每分钟服务1,000个请求,该图表建议部署2个G5X大型实例、1个P4D实例或3个P5实例,从而根据工作负载要求做出经济高效的决策。
演讲者还分享了Netflix内部基准测试的见解,显示对于低延迟、实时LLM推理工作负载(延迟是主要考虑因素),配备Nvidia A100 GPU的P4D实例表现出色。相比之下,对于成本是主要考虑因素的工作负载,Trinium实例提供了更好的每笔交易成本。
G6实例有单GPU和多GPU配置,提供了中等的价格/性能水平,适合需要在成本和性能之间取得平衡的场景。CPU实例被发现适合于批量类型的生成式人工智能工作负载环境,如用于检索增强生成(RAG)用例的文档修改,在这种环境中延迟要求较为宽松。
此外,Netflix利用现场实例(即未使用的云容量)来预计算订阅者推荐,以大幅降低成本,利用数千个闲置CPU进行批量推理。
演讲者们还强调了采用混合设置的可能性,在这种设置中,CPU 用于预处理任务,而推理则在 GPU 上运行。
为了促进 FM Bench 在基准测试需求中的采用,演讲者介绍了 FM Bench Orchestrator,这是一个辅助存储库,可以简化该过程。他们提供了资源,包括一个视频、FM Bench 网站和 GitHub 存储库,指导用户安装、配置和运行 FM Bench,以及解释生成的报告。
由于 FM Bench 是一个开源项目,演讲者鼓励用户在 GitHub 上创建 issue 或通过 LinkedIn 与他们联系,提出任何请求或功能添加。他们还提到,基因工作流程和评估正在被添加到 FM Bench 中。
总之,在 亚马逊云科技 re:Invent 2024 活动上的这次演讲,全面概述了 Netflix 如何利用 亚马逊云科技 基础模型基准测试工具 (FM Bench) 来对生成式 AI 工作负载进行基准测试和适当调整。演讲者展示了 FM Bench 在评估各种 亚马逊云科技 实例、模型和服务堆栈方面的能力,以优化性能、可扩展性和成本效益,确保 Netflix 的 AI 计划为全球观众带来丰富和无缝的体验。
下面是一些演讲现场的精彩瞬间:
Netflix分享了他们在评估亚马逊云科技实例时的流程,包括像Nvidia GPU和亚马逊云科技硅优质实例这样的加速计算选项,利用他们的CI/CD平台和基准测试框架。

Netflix利用亚马逊云科技实例和自动化测试工具来优化生成式AI工作负载,确保它们满足性能、可扩展性和成本要求,同时遵守SLO标准。

FM Bench是一个开源软件包,可以在亚马逊云科技生成式AI服务上对任何基础模型进行基准测试,支持来自Hugging Face、Anthropic和自定义微调模型等各种来源的模型。

FM Bench生成一份全面的报告,包含推理延迟、吞吐量和令牌处理时间等指标,有助于为AI工作负载做出明智的业务决策。

该图表显示,与G6E.48XL和L4D相比,P4D搭配Nvidia A100可以提供更低的延迟和更高的吞吐量,同时成本更低,这得益于HBM和GPU到GPU的NVLink,可以高效地进行张量并行的LLM推理。
该图表直观地展示了为不同级别的每秒请求数量提供服务所需的最佳实例类型和数量,从而实现工作负载的成本和延迟优化。
总结
随着Netflix继续扩展其基于人工智能的服务,对加速计算的需求呈指数级增长。为了应对这一挑战,Netflix采用了一个严格的基准测试流程,用于评估亚马逊云科技实例在各种生成式人工智能工作负载下的性能。该流程包括确定每项服务的准确性、延迟和吞吐量要求,然后遍历不同的基础模型、实例类型和服务堆栈,以确定能够在预算约束内提供最佳性能和可扩展性的最佳组合。
在这个过程中,一个关键工具是FM Bench,这是一个由亚马逊云科技开发的开源软件包,允许Netflix对任何亚马逊云科技生成式人工智能服务上的任何基础模型进行基准测试。FM Bench提供了一个统一的配置文件,用于测试不同模型、实例、推理引擎和服务器的组合,并生成包含推理延迟、吞吐量和成本估算等指标的详细报告。这些报告有助于做出基于数据的决策,如部署成本、容量需求和扩展策略。
Netflix的基准测试方法使其团队能够做出明智的选择,确保基于人工智能的服务即使在高需求事件期间也能提供最佳性能,为全球观众提供无缝体验。随着对生成式人工智能的需求不断增长,Netflix对严格的基准测试和适当调整的承诺将是提供创新、经济高效和可扩展的人工智能解决方案的关键。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。

















 1577
1577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









