




 本文介绍了使用Kettle将MySQL数据导出到Hive的两种方法,包括将Hive的jar包转移到Kettle大数据目录,修改plugin.properties文件,连接Hive Server 2,以及在Kettle中新建转换。在操作过程中可能会遇到的错误及解决方案也进行了说明,如字段类型转换错误和分隔符选择不当导致的问题。
本文介绍了使用Kettle将MySQL数据导出到Hive的两种方法,包括将Hive的jar包转移到Kettle大数据目录,修改plugin.properties文件,连接Hive Server 2,以及在Kettle中新建转换。在操作过程中可能会遇到的错误及解决方案也进行了说明,如字段类型转换错误和分隔符选择不当导致的问题。
Kettle导出mysql数据到hive
通过Kettle导出mysql数据到hive有两种方案:
1. 将hive表直接作为表输出进行

- 先将数据上传到hdfs,然后执行SQL语句load到hive

具体步骤如下:
(1)将hive安装目录下,lib里面的所有hive开头的jar包转移至kettle的大数据jar包目录下
data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp25\lib
(2) 修改kettle的plugin.properties文件
plugins/pentaho-big-data-plugin/plugin.properties

(3)启动hive,连接hive Server 2(对于直接连接hive)
如果是apache hive
bin/hive --service metastore &
bin/hive --service hiveserver2 &
如果是cdh hive 可以直接启动hive
进入kettle页面,新建转换,DB连接
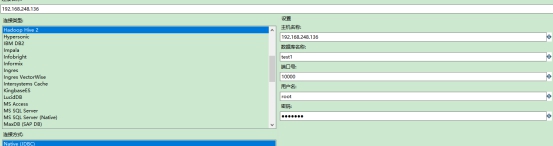
有可能会遇到报错:
case1:
Could not open client transport with JDBC Uri:jdbc:hive2://localhost:10000/default解决方法:重启hiveserver2 bin/hive --service hiveserver2
case2:
Required field 'serverProtocolVersion' is unset 或者 java.lang.NoSuchMethodError: org.apache.hive.service.cli.HiveSQLException.<init>(Lorg/apache/hive解决方法:版本冲突问题 将所有版本与hive版本不太一致的jar包
case3:
如果报出权限错误,则修改或者添加 hdfs core-site
org.apache.hadoop.ipc.RemoteException:User: root is not allowed to impersona <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property>
(4)连接Hadoop clusters
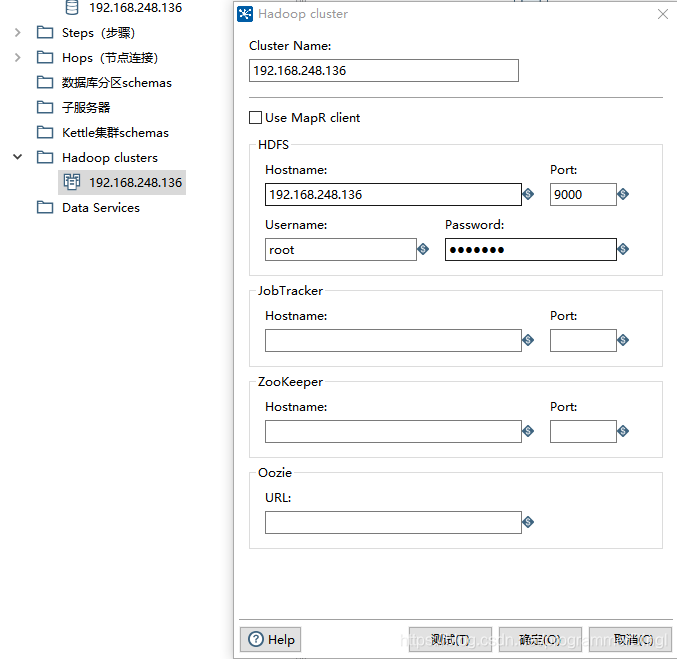
(5)核心对象新建转换
**case1:将hive表直接作为表输出进行**
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YBQac3sB-1597300423915)(file:///C:\Users\86188\AppData\Local\Temp\ksohtml25748\wps3.jpg)]

发现效率很慢,几乎数据进去hive几条之后,任务就不动了。
有可能会报字段类型转换错误,需要强调对于字段类型
case2:先将数据上传到hdfs,然后执行SQL语句load到hive

需要对于Hadoop File Output进行步骤编辑(mysql输入编辑略)

注:分隔符格式:$[期望作为分隔符的 十六进制的 ASCII码] 与hive创建表时的分隔符一致

注:1. 对于类型,与hive相一致(可以查找hive类型对照表)
2.对于格式,#代表与原数据一致
3.选择最小宽度,即去除左右两端空格,减少存储空间
有可能会出现以下报错:
- hive中出现有的列为null 查看分隔符的选择
- 数据与原有数据不一致 选择格式为#


















 1099
1099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









