






先说说思路:一 是直接从mysql输出至hive中,另外一个是先将数据搞到hdfs中,再load一下,当然这只是textfile存储格式而言,若是ORC等其他列式存储的话建议先搞一个textfile格式的中间表,再insert into table select 插进去
下面分别介绍下两种方式
第一种:
1.连接hive对外服务的组件hiveserver2

点击测试,OK之后会显示测试成功
测试直接将mysql中的stdcode表导入一下

抽取数据,插入的目标库中有没有对应为表的话点击下方的SQL,会默认执行DDL语句,create一下表,接下来NEXT

第二种方式:
1.创建hive 的数据库连接
就是上面的步骤
2:新建hadoop cluster连接
配置kettle hadoop cluster的配置文件
从服务器hadoop etc的配置文件中下载如下4个配置文件,覆盖kettle的plugins\pentaho-big-data-plugin\hadoop-configurations\hdp25中的4个同名文件。
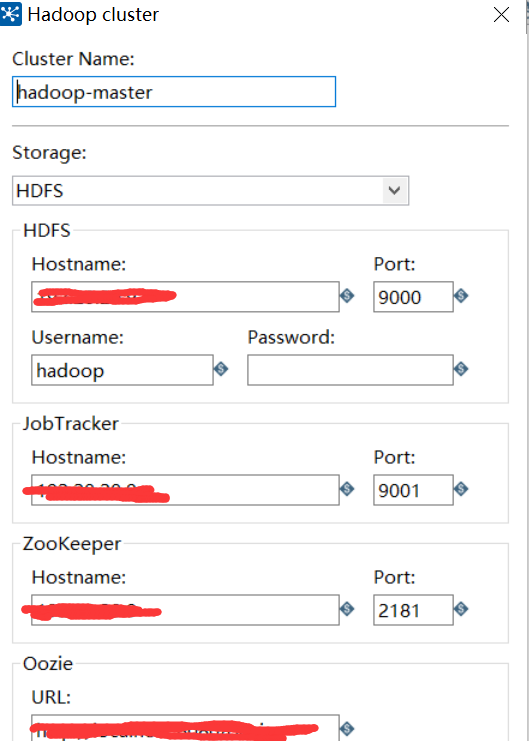
新建hadoop cluster 连接
填写相应的配置,配置的hostname 和端口号根据上面4个配置文件填写,如下图
点击测试连接,如下图(注意:低版本的Kettle有的没有下面的):
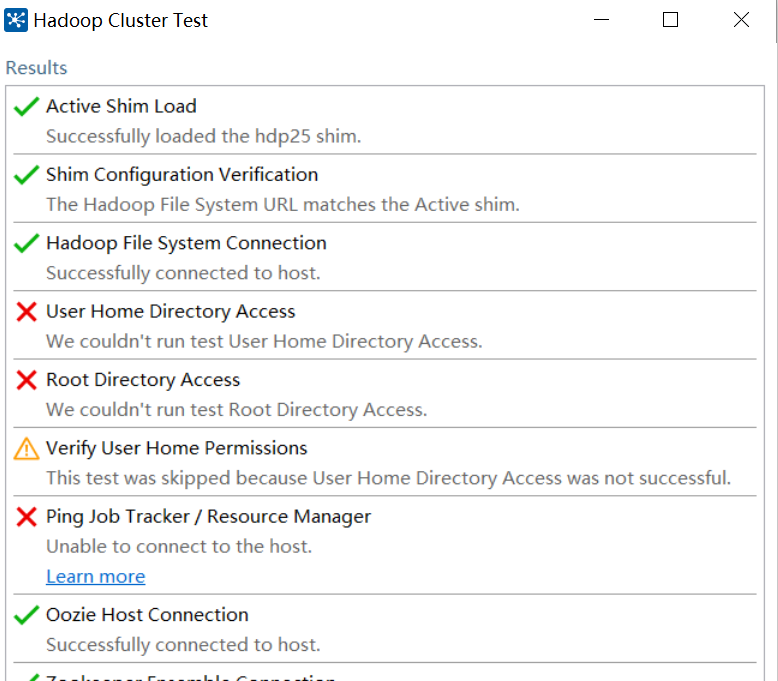
有一部分是报些错误,不过不影响,只要Hadoop File System Connection 没报错就行。
3.转换整体流程
整个转换的流程如下:
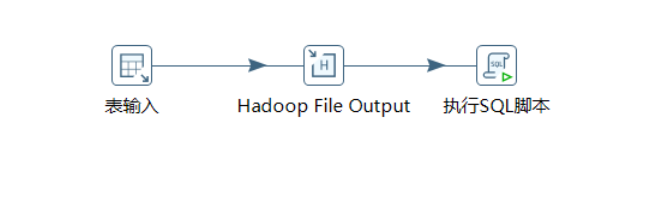
通过表输入的方式,从mysql数据库读取表数据,然后通过Hadoop File Output将mysql数据库的数据以数据文件的方式,输出到hadoop的hdfs,然后执行SQL脚本,将数据文件加载到hive的表中
说明下: 有的高版本的可以直接用hadoop cope file 这个组件来同步数据
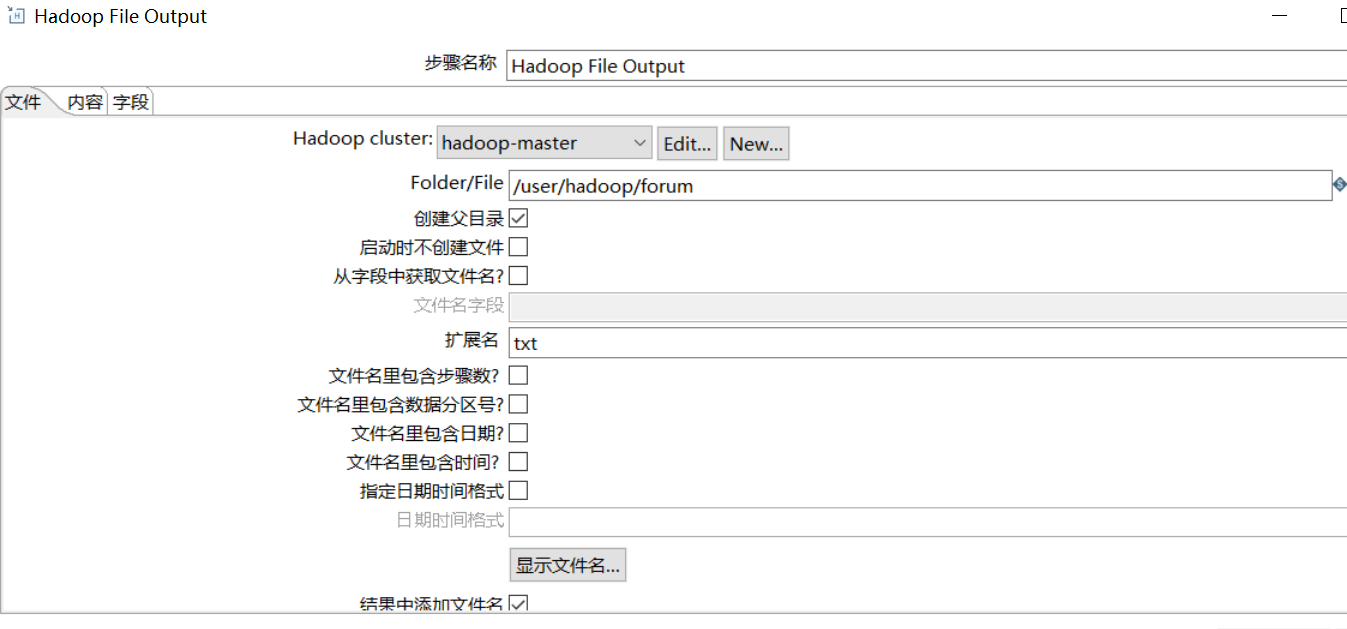
4.Hadoop File Output组件
hadoop file output 组件配置如下:
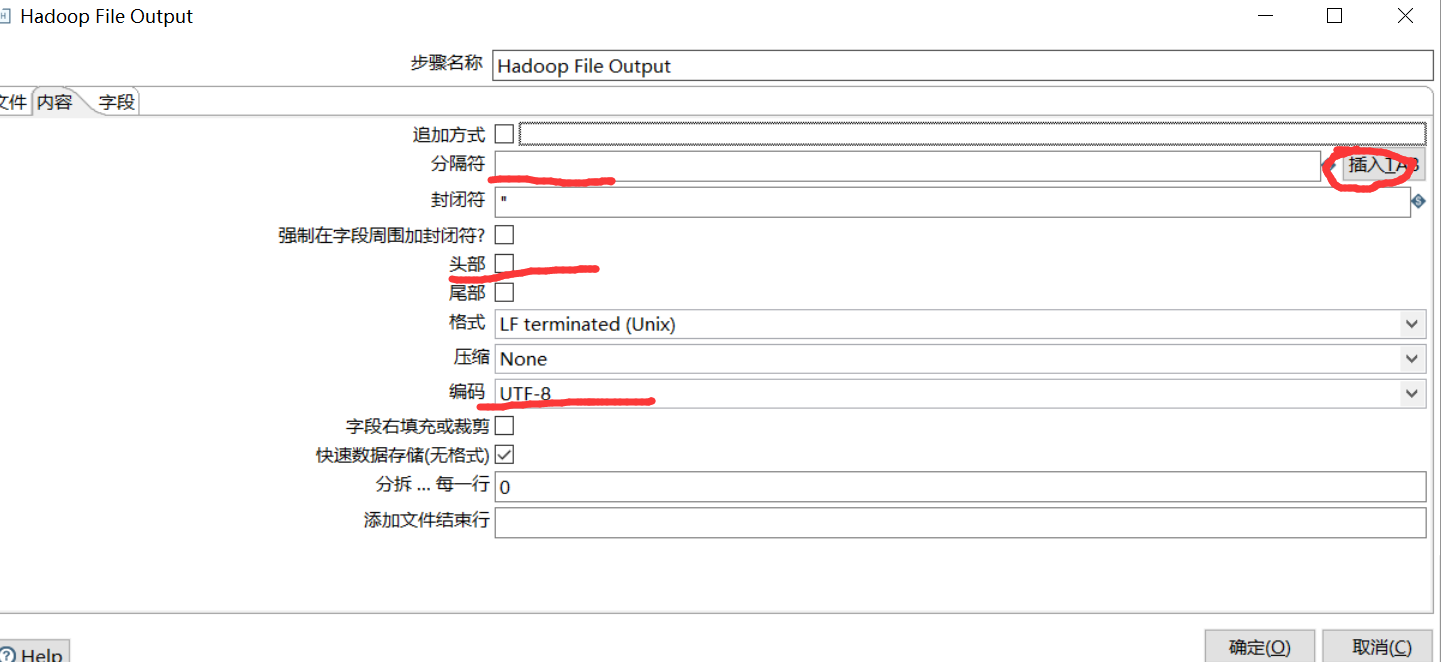
在内容里面注意标红的几个配置,头部是否显示列名,勾选完后表示不显示列名。
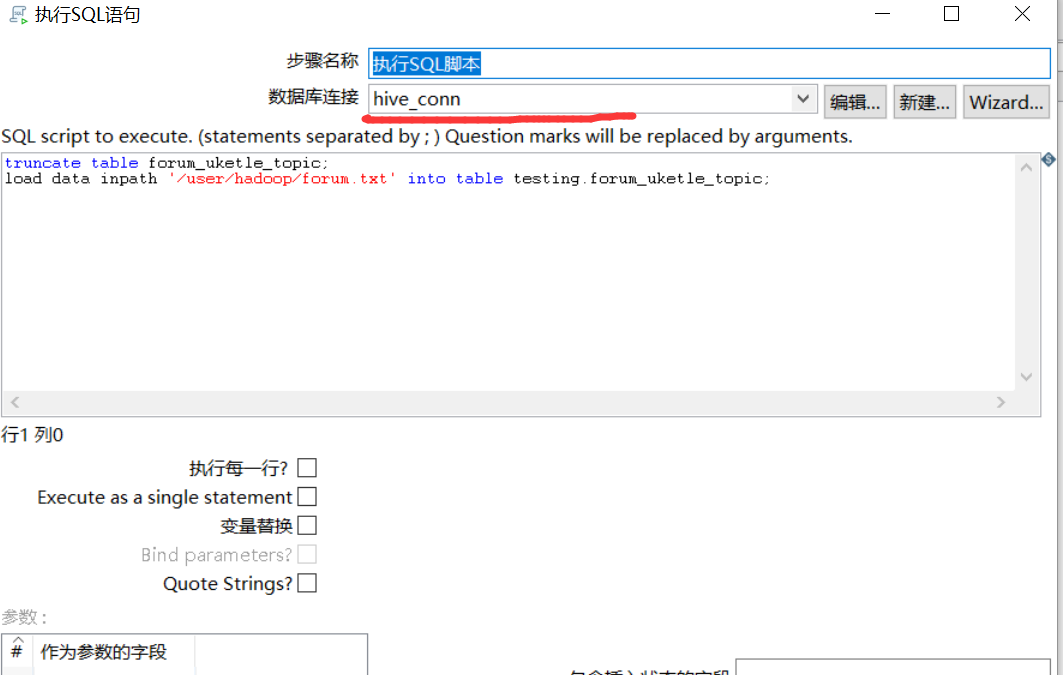
5.执行sql 脚本组件
使用步骤1创建的hive连接,连接hive,然后通过如下脚本,将数据从hdfs里面导入到hive。

















 1761
1761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









