



目录
📥 数据集获取步骤
在开始之前,我们需要先获取CIFAR-10数据集:
方法一:官方下载(推荐)
-
访问CIFAR-10官方网站:CIFAR-10 and CIFAR-100 datasets
-
下载"CIFAR-10 python version"(约163MB)
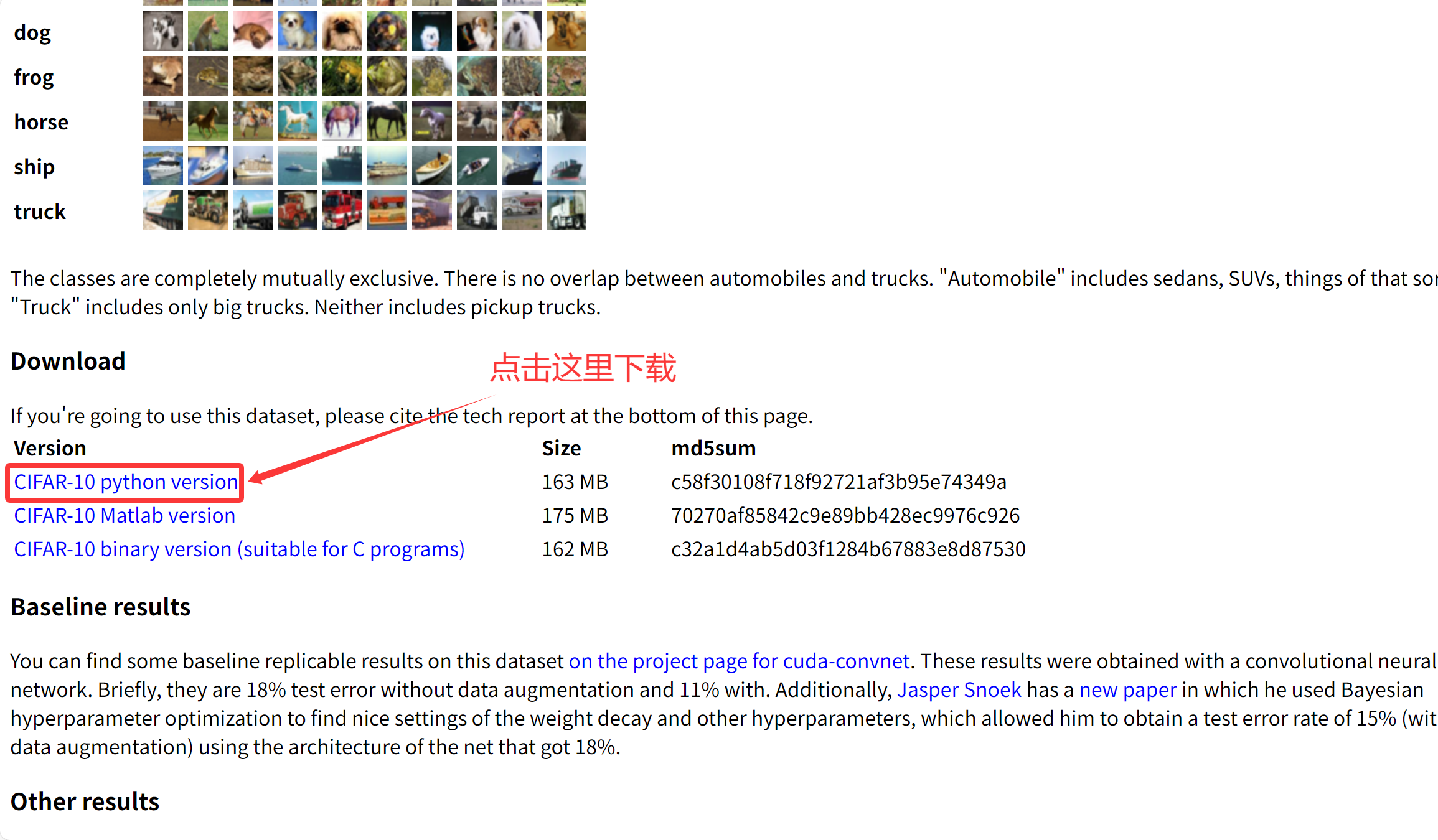
-
解压文件,将得到的
cifar-10-batches-py文件夹放在项目目录的data/文件夹下
方法二:使用torchvision自动下载(需要魔法,否则速度极慢)
如果你想要更简单的方式,可以在代码中使用torchvision自动下载:
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
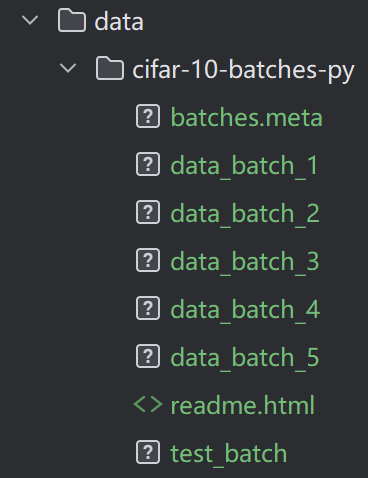
download=True, transform=transform)目录结构应该是这样的:
✨ 前言:为什么选择CIFAR-10?
CIFAR-10数据集包含10个类别的6万张彩色图像,每张图片只有32x32像素,别看图片小,里面可是大有乾坤!从飞机到青蛙,从汽车到小猫,这个数据集是入门深度学习的绝佳选择!
本文将带你从零开始,完整实现数据预处理、模型构建、训练和评估的全过程。文末还有完整代码获取方式哦!
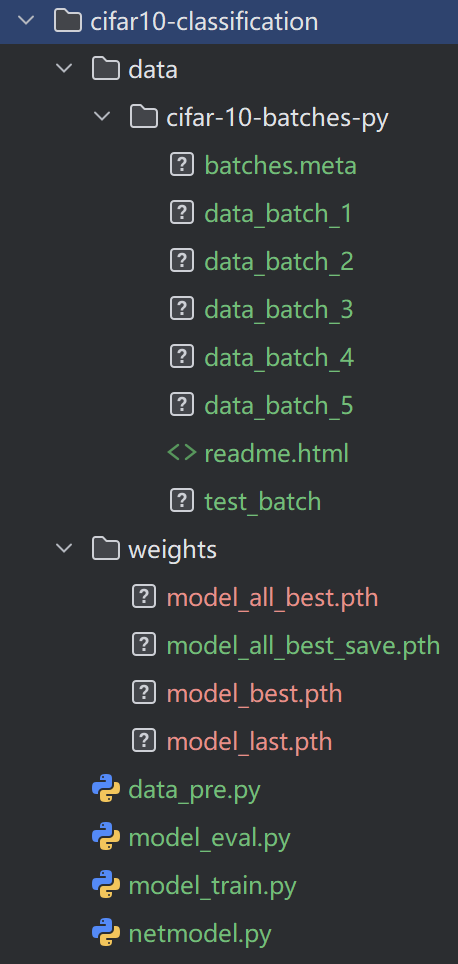
📁 项目结构一览
先来看看我们完整的项目结构,清晰的结构是成功的一半:
🛠️ 第一步:数据预处理(data_pre.py)
核心功能:让数据"听话"
import numpy as np
import torch
from torchvision import transforms
from torch.utils.data import DataLoader, TensorDataset
def get_data_class():
# 解密CIFAR-10的二进制文件
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
# 加载所有训练和测试数据
print("正在加载数据...")
data_train_1 = unpickle('data/cifar-10-batches-py/data_batch_1')
# ... 省略其他批次加载代码
# 获取标签名称
datameta = unpickle('data/cifar-10-batches-py/batches.meta')
label_names = [name.decode('utf-8') for name in datameta[b'label_names']]
print(f"类别标签: {label_names}")数据预处理技巧
# 定义数据增强和标准化流程
ts = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), # RGB均值
(0.2470, 0.2435, 0.2616)), # RGB标准差
])
def process(data):
processed_img = []
for i in range(data.shape[0]):
img = data[i].transpose(1, 2, 0) # (C, H, W) -> (H, W, C)
img = ts(img) # 应用变换
processed_img.append(img)
return torch.stack(processed_img)💡 小贴士:
-
数据标准化能加速模型收敛
-
合适的transforms组合是提升性能的关键
-
批量处理提高效率
🧠 第二步:构建神经网络(netmodel.py)
设计我们的"大脑"
from torch import nn
class NetModel(nn.Module):
def __init__(self):
super(NetModel, self).__init__()
self.fc = nn.Sequential(
# 第一层卷积:捕捉基础特征
nn.Conv2d(3, 16, 5, 1, 2), # 输入3通道,输出16通道
nn.ReLU(), # 激活函数
nn.MaxPool2d(2, 2), # 下采样
# 第二层卷积:提取更复杂特征
nn.Conv2d(16, 32, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2, 2),
# 第三层卷积:高级特征抽象
nn.Conv2d(32, 64, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2, 2),
# 展平并连接全连接层
nn.Flatten(),
nn.Linear(64 * 4 * 4, 128),
nn.ReLU(),
nn.Dropout(0.5), # 防止过拟合
nn.Linear(128, 64),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10) # 输出10个类别
)🌟 网络设计亮点:
-
三层卷积层层递进,特征提取能力逐渐增强
-
Dropout层有效防止过拟合
-
ReLU激活函数提供非线性能力
🏋️ 第三步:模型训练(model_train.py)
启动训练引擎
import torch
from data_pre import get_data_class
from netmodel import NetModel
# 自动选择设备:GPU优先!
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
model = NetModel().to(device)
train_loader, test_loader, label_names = get_data_class()
# 超参数设置
lr = 0.001
epoches = 100
optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=1e-4)
loss_fn = torch.nn.CrossEntropyLoss(reduction='sum')
print("开始训练!")训练过程可视化
for epoch in range(epoches):
# 训练阶段
model.train()
acc_total = 0
loss_total = 0
for i, (x, y) in enumerate(train_loader):
x, y = x.to(device), y.to(device)
pred = model(x)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc_total += (pred.argmax(dim=1) == y).sum().item()
loss_total += loss.item()
train_acc = acc_total / len(train_loader.dataset)
avg_loss = loss_total / len(train_loader.dataset)
# 验证阶段
model.eval()
val_acc_total = 0
with torch.no_grad():
for x, y in test_loader:
x, y = x.to(device), y.to(device)
pred = model(x)
val_acc_total += (pred.argmax(dim=1) == y).sum().item()
val_acc = val_acc_total / len(test_loader.dataset)
# 打印训练进度
print(f'epoch: {epoch+1:02d}/{epoches} | '
f'train_acc: {train_acc:.4f} | '
f'val_acc: {val_acc:.4f} | '
f'loss: {avg_loss:.4f}')📊 第四步:模型评估(model_eval.py)
检验成果时刻
import torch
from data_pre import get_data_class
from netmodel import NetModel
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 加载最佳模型
model = NetModel().to(device)
model.load_state_dict(torch.load('./weights/model_all_best.pth'))
model.eval()
print("开始模型评估...")
# 计算测试集准确率
acc = 0
with torch.no_grad():
for x, y in test_loader:
x, y = x.to(device), y.to(device)
pred = model(x)
acc += (pred.argmax(dim=1) == y).sum().item()
final_acc = acc / len(test_loader.dataset)
print(f"模型在测试集上的准确率: {final_acc:.2%}")🚀 如何运行?
第一步:准备环境
pip install torch torchvision numpy第二步:下载数据
按照本文开头的步骤下载并放置CIFAR-10数据集
第三步:开始训练
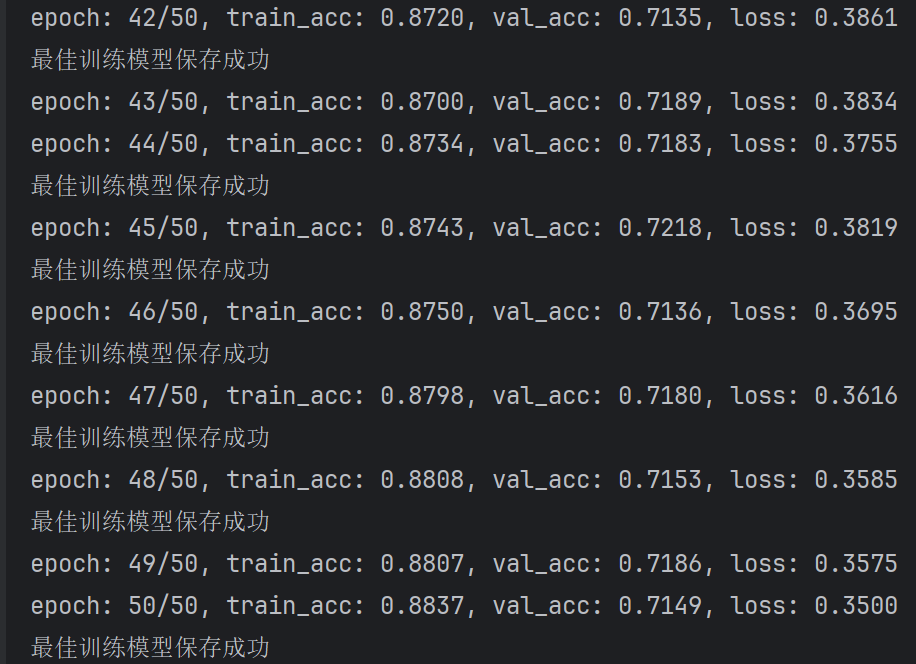
python model_train.py经过50轮的训练后训练集准确率达到了88%,验证集准确率到达了72%
第四步:评估模型
模型评估使用的是最佳的模型,即训练和验证集的准确都提高时保存的model_all_best模型
python model_eval.py
可以看到验证集准确率到达了72%,本人经过100轮训练后最高可以到达73%,但这似乎就已经是卷积神经网络的极限了,如果你有更好的模型结构或训练时的参数选择可以提高准确率,欢迎分享!
📈 性能预期与优化建议
基准性能
-
初始准确率:约50-73%
-
训练时间:GPU约5-10分钟,CPU约10-20分钟
提升技巧
-
数据增强:添加随机裁剪、水平翻转
transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(),
-
学习率调度:使用学习率衰减
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
-
更深的网络:尝试ResNet、DenseNet等先进架构
-
超参数调优:使用网格搜索或随机搜索
💡 常见问题解答
Q: 为什么我的准确率不高?
-
检查数据预处理是否正确
-
尝试增加训练轮数
-
调整学习率和批量大小
Q: 训练速度太慢怎么办?
-
使用GPU加速训练
-
减小批量大小
-
使用混合精度训练
Q: 如何保存和加载模型?
-
使用
torch.save()保存模型 -
使用
torch.load()加载模型
🎉 结语
通过本文,你已经掌握了:
-
CIFAR-10数据集的预处理技巧
-
CNN网络的设计与实现
-
PyTorch训练流程的完整实现
-
模型评估与优化方法
希望这篇教程对你有所帮助!如果你有任何问题或建议,欢迎在评论区留言讨论~
📚 完整代码
本文涉及的完整代码文件如下:
data_pre.py
import numpy as np
import torch
from torchvision import transforms
from torch.utils.data import DataLoader, TensorDataset
def get_data_class():
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
data_train_1 = unpickle('data/cifar-10-batches-py/data_batch_1')
data_train_2 = unpickle('data/cifar-10-batches-py/data_batch_2')
data_train_3 = unpickle('data/cifar-10-batches-py/data_batch_3')
data_train_4 = unpickle('data/cifar-10-batches-py/data_batch_4')
data_train_5 = unpickle('data/cifar-10-batches-py/data_batch_5')
data_test = unpickle('data/cifar-10-batches-py/test_batch')
datameta = unpickle('data/cifar-10-batches-py/batches.meta')
label_names = datameta[b'label_names']
label_names = [i.decode('utf-8') for i in label_names]
train_data = np.concatenate(
(data_train_1[b'data'], data_train_2[b'data'], data_train_3[b'data'], data_train_4[b'data'],
data_train_5[b'data']),
axis=0)
train_label = np.concatenate(
(data_train_1[b'labels'], data_train_2[b'labels'], data_train_3[b'labels'], data_train_4[b'labels'],
data_train_5[b'labels']), axis=0)
test_data = np.array(data_test[b'data'])
test_label = np.array(data_test[b'labels'])
train_data = train_data.reshape(-1, 3, 32, 32).astype(np.uint8)
test_data = test_data.reshape(-1, 3, 32, 32).astype(np.uint8)
ts = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616)),
])
def process(data):
processed_img = []
for i in range(data.shape[0]):
img = data[i].transpose(1, 2, 0)
img = ts(img)
processed_img.append(img)
return torch.stack(processed_img)
train_data = process(train_data)
test_data = process(test_data)
train_label = torch.LongTensor(train_label)
test_label = torch.LongTensor(test_label)
train_dataset = TensorDataset(train_data, train_label)
test_dataset = TensorDataset(test_data, test_label)
train_loader = DataLoader(
dataset=train_dataset,
batch_size=64,
shuffle=True,
)
test_loader = DataLoader(
dataset=test_dataset,
batch_size=64,
shuffle=False,
)
return train_loader, test_loader, label_names
if __name__ == '__main__':
train_loader, test_loader, label_names = get_data_class()
for i in train_loader:
print(i[0].shape, i[1].shape)
breaknetmodel.py
from torch import nn
class NetModel(nn.Module):
def __init__(self):
super(NetModel, self).__init__()
self.fc = nn.Sequential(
nn.Conv2d(3, 16, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(16, 32, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 128),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(128, 64),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10)
)
def forward(self, x):
out = self.fc(x)
return outmodel_train.py
import torch
from data_pre import get_data_class
from netmodel import NetModel
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = NetModel().to(device)
train_loader, test_loader, label_names = get_data_class()
lr = 0.001
epoches = 100
optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=1e-4)
loss_fn = torch.nn.CrossEntropyLoss(reduction='sum')
acc_max_train = 0
acc_max_val = 0
for epoch in range(epoches):
model.train()
acc_total = 0
loss_total = 0
for i, (x, y) in enumerate(train_loader):
x = x.to(device)
y = y.to(device)
pred = model(x)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc_total += (pred.argmax(dim=1) == y).sum().item()
loss_total += loss
train_acc = acc_total / len(train_loader.dataset)
avg_loss = loss_total / len(train_loader.dataset)
model.eval()
val_acc_total = 0
with torch.no_grad():
for i, (x, y) in enumerate(test_loader):
x = x.to(device)
y = y.to(device)
pred = model(x)
val_acc_total += (pred.argmax(dim=1) == y).sum().item()
val_acc = val_acc_total / len(test_loader.dataset)
print(f'epoch: {epoch + 1}/{epoches}, train_acc: {train_acc:.4f}, val_acc: {val_acc:.4f}, loss: {avg_loss:.4f}')
if acc_max_train < train_acc and acc_max_val < val_acc:
acc_max_train = train_acc
acc_max_val = val_acc
torch.save(model.state_dict(), './weights/model_all_best.pth')
torch.save(model.state_dict(), './weights/model_best.pth')
print('最佳模型保存成功')
elif acc_max_train < train_acc:
acc_max_train = train_acc
torch.save(model.state_dict(), './weights/model_best.pth')
print('最佳训练模型保存成功')
if epoch == epoches - 1:
torch.save(model.state_dict(), './weights/model_last.pth')model_eval.py
import torch
from data_pre import get_data_class
from netmodel import NetModel
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = NetModel().to(device)
model.load_state_dict(torch.load('./weights/model_all_best.pth'))
model.eval()
train_loader, test_loader, label_names = get_data_class()
acc = 0
with torch.no_grad():
for i, (x, y) in enumerate(test_loader):
x = x.to(device)
y = y.to(device)
pred = model(x)
acc += (pred.argmax(dim=1) == y).sum().item()
print(f"acc: {acc / len(test_loader.dataset)}")📢 互动时间:
你在实现过程中遇到了什么问题?或者有什么更好的优化建议?欢迎在评论区分享你的经验和心得!
如果觉得这篇文章对你有帮助,欢迎点赞👍、收藏⭐、评论💬!


















 1150
1150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









