




 PixContrast和PixPro是两种扩展无监督视觉表示学习的方法,从实例级提升到像素级。PixContrast通过对比同一图像不同增强视图中像素的投影,促进像素级的一致性。PixPro则引入像素传播模块,利用像素之间的相似性计算权重,进一步增强模型的学习能力。这两种方法都旨在优化网络对图像像素级别的理解,提高无监督学习的表示性能。
PixContrast和PixPro是两种扩展无监督视觉表示学习的方法,从实例级提升到像素级。PixContrast通过对比同一图像不同增强视图中像素的投影,促进像素级的一致性。PixPro则引入像素传播模块,利用像素之间的相似性计算权重,进一步增强模型的学习能力。这两种方法都旨在优化网络对图像像素级别的理解,提高无监督学习的表示性能。
【论文笔记】Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning
论文地址:http://arxiv.org/abs/2011.10043
代码:https://github.com/zdaxie/PixPro
贡献
把 Unsupervised VisualRepresentation Learning从以图象为单位的instance level拓展到pixel level
PixContrast
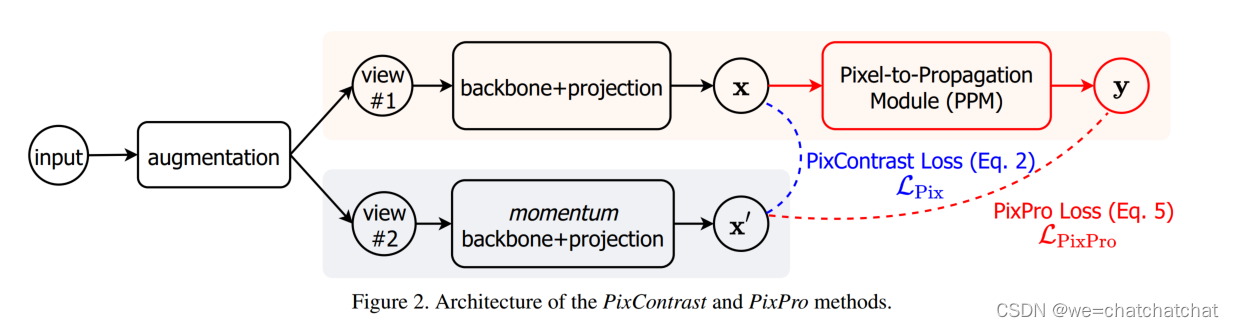
常见的contrastive leanring的input是一张图片,经过augmentation后产生两个不同的view,再经过backbone+projection head得到两个projection,这里区别于传统contrastive leanring地方在于,x可以是一个feature map在这基础上,每一个feature map对应的值可以溯源到原始图像中的某一个位置的像素,同instance level的contrastive leanring一样,的一个像素经过不同的图像增强产生的representation再projection之后应该是尽量接近的。
利用从两个视图计算的两个feature map,我们可以构建用于representation的pixel contrast pretext tasks。首先将特征映射中的每个像素warp到原始图像空间,然后计算两个feature map中所有像素对之间的距离。距离被归一化为二进制特征图的对角线长度,以考虑到增强视图之间的比例差异,基于阈值T用归一化的距离来生成positive and negative pairs。
如果对所有的像素都计算loss,这会使这个feature map中所有的像素的feature都变成同一个,因为这里对比的不是图像层次而是对比的一个像素,而这个像素的feature可能跟feature map中其他的feeature长得不一样,但是他和其他的像素都是来自于同一张图像,直接做contarstive loss显然不太合适,因此作者增加了一个基于距离的distance mask,用意是这个像素只和周围一定距离的像素做contrastive loss,距离太远的就不管了。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









