




 本文深入解析CUDA执行模型,包括Block和Thread的分配机制,Warp调度原理,以及WarpDivergence的影响。通过理解GPU硬件架构,指导CUDA程序优化。
本文深入解析CUDA执行模型,包括Block和Thread的分配机制,Warp调度原理,以及WarpDivergence的影响。通过理解GPU硬件架构,指导CUDA程序优化。
Professional CUDA C Programming[1]是一本不错的入门书籍,虽说命名为"Professional",但实际上非常适合入门阅读。他几乎涵盖了所有理论部分和编程技巧,更重要的是每一章都有完整的实例程序。只不过对于入门来讲,这本书有点太厚了,行文有些啰嗦。准备写几篇文章提取一下关键章节的关键部分。
上一篇写了如何写一个简单的CUDA程序。为了进一步优化程序性能,我们经常会调整Block数量和Thread数量,不断的寻找最优的组合。这一篇探讨的是最优组合背后的故事,为什么有些组合可以达到更好的性能。理解CUDA的执行模型,有助于进一步并行化线程,提高程序性能。
这一篇算是对[1]中第三章CUDA Execution Model的总结。
参考文献:
[1] PROFESSIONAL CUDA C Programming. John Cheng, Max Grossman, Ty McKercher.
[2] CUDA C PROGRAMMING GUIDE
执行模型(Execution Model)通常指的是某种计算架构中如何执行指令。理解执行模型有助于进一步优化CUDA程序。该模型与GPU硬件架构息息相关。
GPU架构
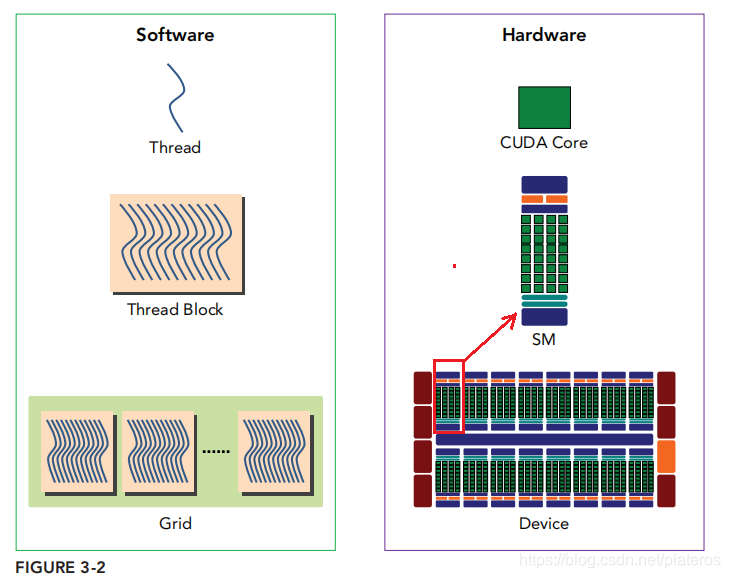
上图引自[1]第三章。左边是软件视角中的程序,右边是硬件视角中的程序。从软件角度来说,上图从下往上看,一个Kernel函数(即一个Grid)有许多Thread Block组成,一个Thread Block又有许多线程组成。从硬件的角度来说,Kernel函数在GPU上执行,GPU由一组SM(streaming multiprocessor,多核流处理区)组成,一个完整的Block分配给一个SM,Block中的thread,由SM中的CUDA core执行。SM可以看成一个独立的作战单元,通常来讲高效的GPU拥有更多数量的SM,同时每个SM的架构均相同。
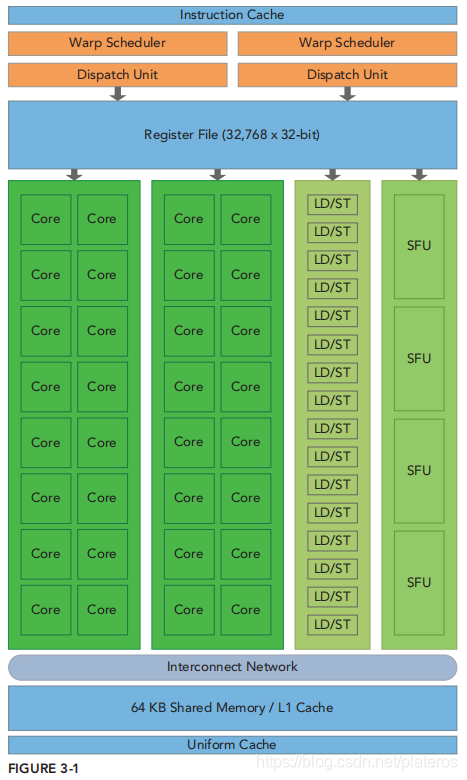
Streaming Multiprocessor
一个SM的基本组成部分
- CUDA core
- 共享内存(Shared Memory)和L1 Cache
- 寄存器
- Load/Save Units
- Special Function Units
- Warp Scheduler
下图是Fermi架构上的SM的图示,虽然与当下主流架构Pascal,Volta相比有不少区别,但是基本组成部分大体一致。
CUDA执行模型
Block分配
Kernel线程被我们分成了线程block,线程以block为单位分配给了不同的SM执行。通常一个SM上会分配多个block,一个block
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 717
717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









