




Florence:计算机视觉的一个新的基础模型
基础模型:
基础模型的术语首次被引入指的是任何从大规模数据中训练的模型 ,这些模型能够被适应 (例如微调)到广泛的下游任务 。由于其令人印象深刻的性能和泛化能力,基础模型变得很有前途。
由于视觉理解的多样性 ,我们将计算机视觉的基础模型重新定义为一个预训练模型及其适配器 , 用于解决这个时空模态空间中的所有视觉任务, 具有可迁移性 ,如零/少样本学习和完全微调等。
一、创新点
现有的视觉基础模型,如CLIP、ALIGN等,主要侧重于将图像和文本映射到一种跨模态的共享表征。
Florence则将表征进行了拓展,不仅拥有从粗略(场景)到精细(对象)的表征能力,还将视觉能力从静态(图像)扩展到动态(视频),从RGB图像扩展到多模态(文字、深度信息)。
通过整合图像-文本数据的通用视觉语言表示能力,Florence可以轻松适用于各种计算机视觉任务,如分类、目标检测、VQA、看图说话、视频检索和动作识别,在多种类型的迁移学习中均表现出色。
二、方法
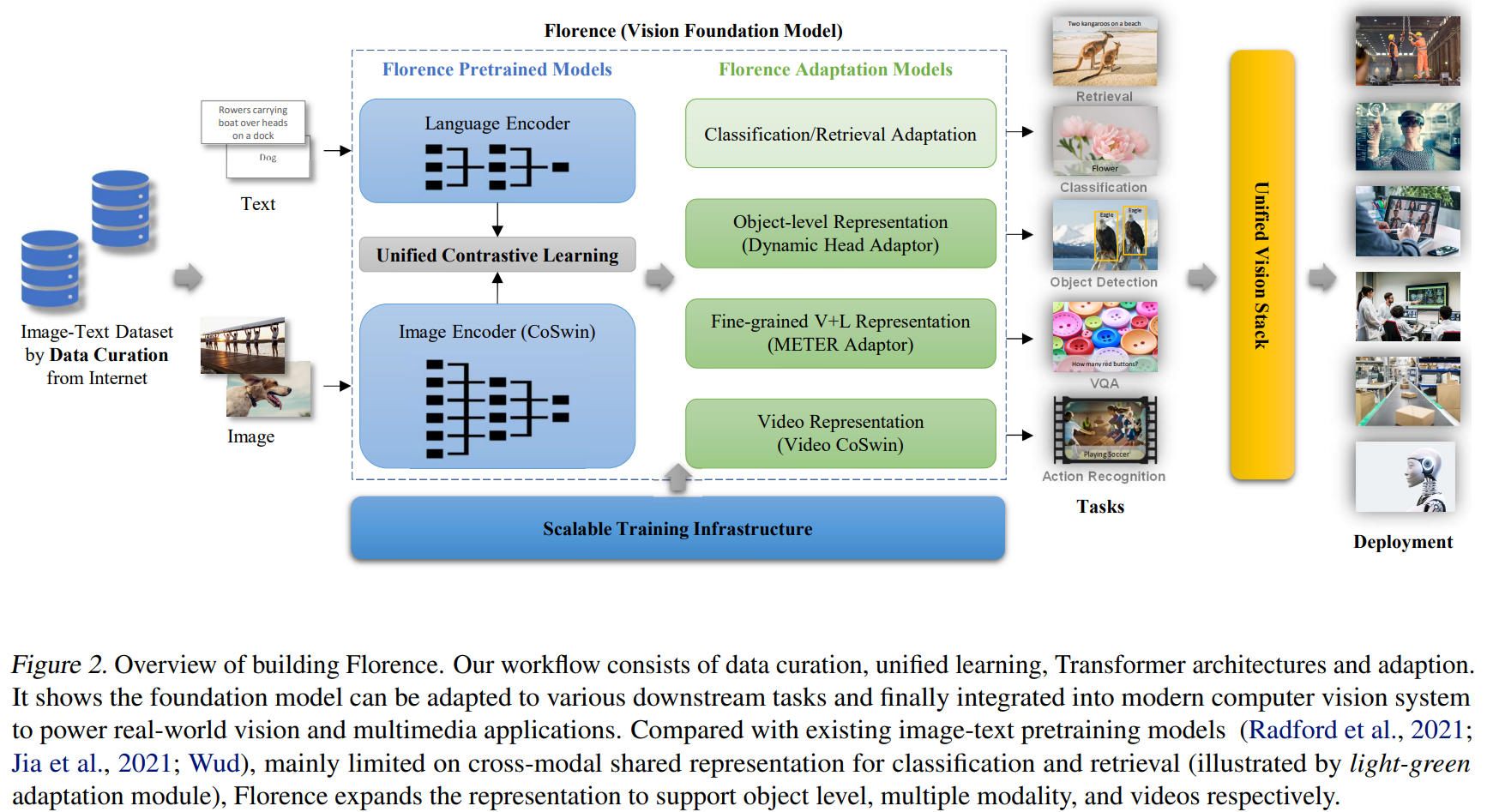
1. 数据集的选取
利用互联网上公开的大量图像-文本数据,微软构建
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 184
184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









