




 本文详述了在Hive 3.1.2和Spark 3.1.2环境下配置Hive on Spark的过程,包括编译Hive源码以适配Spark版本、上传Spark JARs到HDFS、配置Hive和Spark的参数。实践中遇到的版本不兼容问题导致执行失败,解决方案包括重新编译Hive并调整配置。此外,还介绍了遇到的错误如'Failed to create Spark client for Spark session'及其解决办法。
本文详述了在Hive 3.1.2和Spark 3.1.2环境下配置Hive on Spark的过程,包括编译Hive源码以适配Spark版本、上传Spark JARs到HDFS、配置Hive和Spark的参数。实践中遇到的版本不兼容问题导致执行失败,解决方案包括重新编译Hive并调整配置。此外,还介绍了遇到的错误如'Failed to create Spark client for Spark session'及其解决办法。
官网
Hive on Spark: Getting Started
官方版本兼容
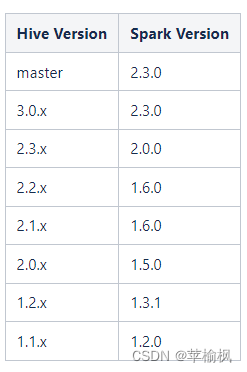
Spark on Hive 和 Hive on Spark区别
Spark on Hive 和 Hive on Spark的区别与实现
spark安装以及hive on spark和spark on hive 的配置
本文实践是采用hive3.1.2和spark3.1.2版本,由于不兼容,故出现一系列问题
判断hive的引擎方式,设置spark引擎
–默认方式是mapreduce
set hive.execution.engine=spark;
实践中的问题
TODO只能重新编译hive
2022.8.6
【hadoop | hive兼容spark3】重新编译hive3兼容spark3
blog的教程,参考价值较低
Hive on Spark配置
Hive on Spark配置 相同(多了填坑的记录)
hive_spark的配置 雷同
Hive on Spark配置 雷同,但是有系列文章
Hive(十三)【Hive on Spark 部署搭建】 雷同,但是有系列文章
Hive On Spark
如下为博文中大致步骤
编译hive源码,指定兼容spark版本
博文中有提到进行hive源码编译,但没教程。
上传纯净版spark-jars到hdfs
由于spark-3.1.2-bin-without-hadoop.tgz已经是纯净版的,仅包含必须的hive-storage-api-2.7.2.jar
hive中加spark-defaults.conf配置文件,两者独立部署可跳过
#使用在hive中创建spark配置文件spark-defaults.conf,加入相关配置
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://192.168.200.177:9820/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
在hive的hive-site.xml中配置spark引擎
添加如下内容
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://192.168.200.177:9820/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!--Hive和Spark连接超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>10000ms</value>
</property>
Hive on Spark on YARN配置整理
多了spark.home配置,可不配置
<property>
<name>spark.home</name>
<value>/usr/local/spark</value>
</property>
8.hive安装 和 Hive环境准备 (hive on Spark 、Yarn队列配置) 多了Yarn配置
Hive on Spark on Yarn
采用的是将hive-site.xml复制到spark conf下,但是在hive-site.xml上配置也是可以的。
Hive On Spark
多了spark.home配置
实战中主要是版本不兼容导致一直出现的问题
hive> create table student(id int, name string);
OK
Time taken: 1.847 seconds
hive> insert into table student values(1,'abc');
Query ID = root_20220728143930_0f99cf8e-a7ff-4599-a60f-db5f6c207a72
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Failed to execute spark task, with exception 'org.apache.hadoop.hive.ql.metadata.HiveException(Failed to create Spark client for Spark session d6008ccf-f2fe-4403-8536-8b437fd95fe4)'
FAILED: Execution Error, return code 30041 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Failed to create Spark client for Spark session d6008ccf-f2fe-4403-8536-8b437fd95fe4
具体问题如下
简单的依赖包缺失参考解决问题方式
hive on spark :Failed to execute spark task, 'org.apache.hadoop.hive.ql.metadata.HiveException
<property>
<name>spark.home</name>
<value>/soft/spark</value>
</property>


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









