







文章总括图
数据存储
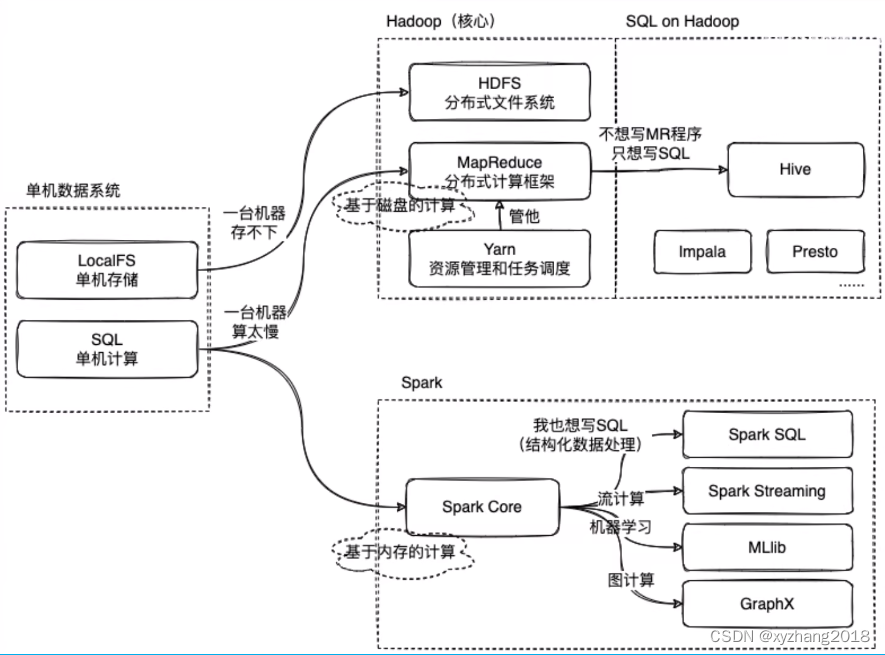
单机数据库时代
所有数据在单机都能存的下,数据处理的任务都是IO密集型,更谈不上分布式系统
一个典型的2U服务器可以插6块硬盘,每块硬盘4T,共24T原始容量,再加上一些数据包的可用冗余,再加上一些格式化的损失,保守估计一台服务器至少可以有10T以上的可用容量,再加上128G内存和两颗CPU,装入DBMS,稍微调优,单表处理10e条数据问题不大
多机数据库时代
当数据量变多时,单台机器无法满足容量需求,一个很常规的想法就是加机器,一台机器存不下就用10台乃至100台。
那么HDFS就诞生了,HDFS会统一管理100台机器上的存储空间,提供一个接口,让100台机器的存储空间看起来就像在一台机器上,让用户感觉到这是一个无限大的存储空间,然后再基于这个去写应用程序。
数据计算
数据分布式的存储于每台机器,每台机器都有自己的CPU和内存,如果能充分利用这些资源可以使数据计算更快完成。
但对于程序员来讲很难去操作100台机器,编写程序将一个计算任务分配到这些机器上,并让这些任务进行同步、机器容错等问题过于复杂,于是MapReduce就出现了。
MapReduce提供了一个任务并行的框架,通过他的API
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









