



在大数据处理领域,Hive 和 Spark 是两个紧密相关但定位不同的技术,它们的集成方式 “Spark in Hive” 和 “Hive in Spark” 代表了不同的协作模式,核心区别在于谁作为主导框架以及计算引擎的选择。下面详细解析两种模式的原理、架构和适用场景:
一、核心概念区分
- Hive:最初是基于 Hadoop 的数据仓库工具,主要用于离线数据分析,依赖 HQL(类 SQL)查询,早期默认计算引擎是 MapReduce(性能较差)。
- Spark:是一个快速通用的计算引擎,支持内存计算,可处理批处理、流处理等多种场景,提供 Spark SQL(类 SQL 接口)。
两者的集成本质是将 Hive 的元数据管理能力与 Spark 的计算能力结合,但主导者不同:
二、Spark in Hive(Hive on Spark)
定义
Hive 作为主导框架,将默认计算引擎从 MapReduce 替换为 Spark,即用 Spark 执行 HQL 查询,充分利用 Spark 的内存计算优势提升 Hive 的处理速度。
核心架构
- 元数据管理:仍由 Hive 的 Metastore 负责(存储表结构、分区、位置等元数据)。
- SQL 解析:HQL 由 Hive 的 Compiler 解析为执行计划。
- 计算执行:将执行计划转换为 Spark 作业(RDD/Dataset 操作),由 Spark 集群执行。
- 数据存储:数据仍存储在 HDFS 或对象存储(与原生 Hive 一致)。
关键特点
- 保留 Hive 生态:完全兼容 Hive 的语法、UDF、分区表、桶表等特性,原有 HQL 脚本无需修改即可运行。
- 性能提升:相比 MapReduce 引擎,Spark 的内存计算可将查询速度提升 10-100 倍(尤其适合多阶段计算场景)。
- 部署依赖:需在 Hive 中配置 Spark 依赖(如 Spark 的 JAR 包路径),并确保 Hive 与 Spark 版本兼容。
适用场景
- 原有 Hive 用户希望提升查询性能,但不想改变 HQL 使用习惯。
- 处理离线批处理任务(如 T+1 数仓 ETL),需要兼容 Hive 的复杂数据模型(如分区表、ORC/Parquet 格式)。
三、Hive in Spark(Spark on Hive)
定义
Spark 作为主导框架,通过 Spark SQL 读取 Hive 的元数据(Metastore),直接操作 Hive 中的数据,即用 Spark SQL 处理 Hive 表数据,此时 Hive 仅作为 “元数据管理器” 和 “数据存储层”。
核心架构
- 元数据访问:Spark 通过 Hive Metastore Client 连接 Hive Metastore,获取表的元数据信息。
- SQL 解析:Spark SQL 解析用户提交的 SQL(支持 Spark SQL 语法,兼容大部分 HQL)。
- 计算执行:由 Spark 引擎直接生成执行计划并在 Spark 集群中运行(无需经过 Hive 的 Compiler)。
- 数据存储:数据仍存储在 Hive 的默认路径(HDFS 或对象存储),格式兼容(如 ORC、Parquet)。
关键特点
- Spark 主导:完全使用 Spark 的计算能力和优化器(Catalyst),支持更丰富的 Spark 特性(如 DataFrame/Dataset API、流处理)。
- 兼容 Hive 数据:可直接读写 Hive 表,无需数据迁移,适合已有 Hive 数据湖的场景。
- 语法差异:Spark SQL 与 HQL 高度兼容,但存在少量差异(如部分 UDF、窗口函数语法)。
适用场景
- 以 Spark 为主要计算框架的团队,需要处理 Hive 中的数据(如用 Spark SQL 查询 Hive 表,或用 Spark MLlib 训练 Hive 中的数据)。
- 需结合 Spark 的多场景处理能力(如批处理 + 流处理结合),同时复用 Hive 的元数据和存储。
四、两者对比与总结
| 维度 | Spark in Hive(Hive on Spark) | Hive in Spark(Spark on Hive) |
|---|---|---|
| 主导框架 | Hive(HQL 为入口) | Spark(Spark SQL/API 为入口) |
| 计算引擎 | Spark(替代 Hive 原 MapReduce 引擎) | Spark(原生引擎) |
| 元数据管理 | Hive Metastore(核心依赖) | Hive Metastore(仅作为元数据来源) |
| 语法兼容性 | 完全兼容 HQL | 兼容大部分 HQL,优先支持 Spark SQL 语法 |
| 适用场景 | 提升 Hive 查询性能,保留 Hive 生态 | 用 Spark 处理 Hive 数据,发挥 Spark 多场景能力 |
| 典型用户操作 | hive -e "SELECT ..."(Hive 客户端) | spark-sql "SELECT ..."(Spark 客户端)或 Spark 代码中调用 Spark SQL |
总结
- 若以 Hive 为核心,只想替换计算引擎加速 HQL,选Spark in Hive。
- 若以 Spark 为核心,需要处理 Hive 中的数据并利用 Spark 的全量功能,选Hive in Spark。
两种模式本质是 “互补而非对立”,实际生产中常结合使用(例如用 Spark on Hive 处理实时数据,同时用 Hive on Spark 运行历史 HQL 脚本),共同构建高效的大数据处理体系。
hive on spark 和 spark on hive详解
Hive on Spark 和 Spark on Hive 是 Hive 与 Spark 两种技术栈集成的两种模式,它们的核心区别在于谁作为主导框架以及计算引擎的归属。下面从定义、架构、工作流程和适用场景等方面详细解析:
一、Hive on Spark(Hive 基于 Spark 运行)
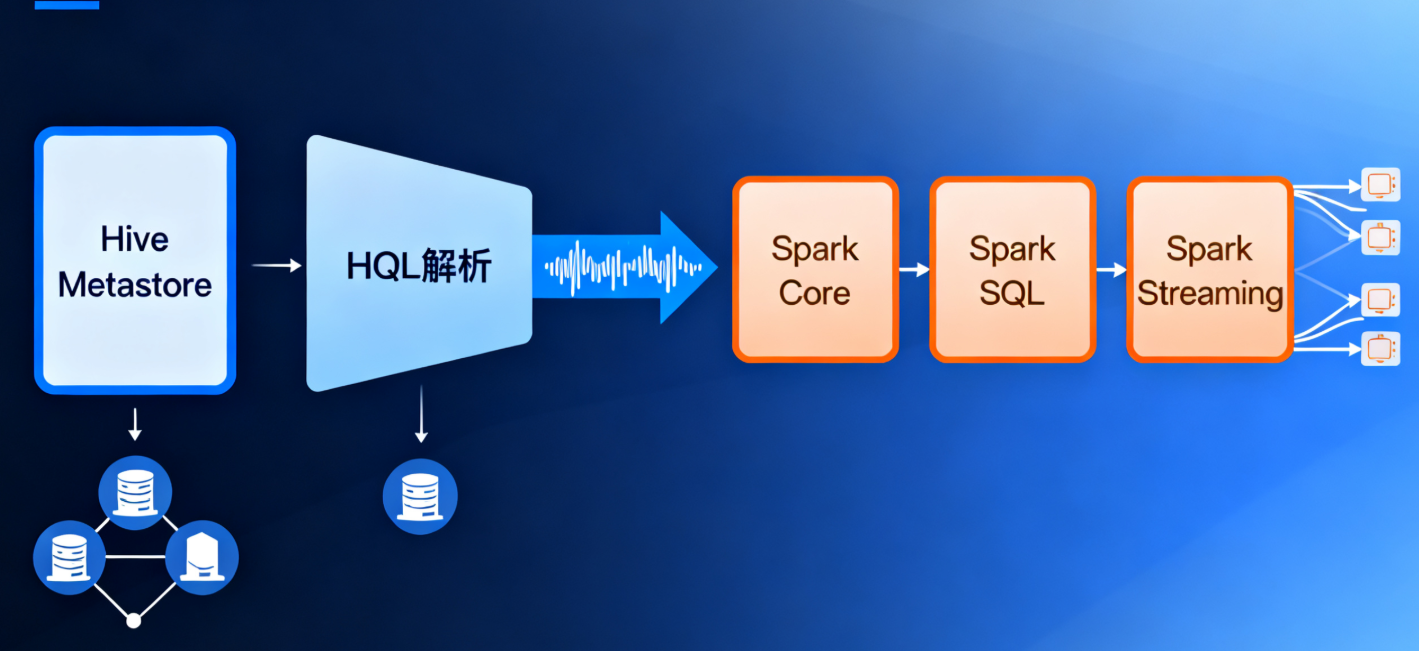
定义
Hive on Spark 是将 Hive 的计算引擎从默认的 MapReduce 替换为 Spark,让 Hive 的 HQL 语句通过 Spark 引擎执行,以利用 Spark 内存计算的优势提升 Hive 的处理性能。
核心架构
- 元数据管理:依然依赖 Hive 原生的 Metastore,负责存储表结构、分区信息、数据位置等元数据。
- SQL 解析层:HQL 由 Hive 的 Compiler 进行语法解析、语义分析,并生成逻辑执行计划。
- 执行计划转换:Hive 将逻辑执行计划转换为 Spark 可执行的 DAG(有向无环图),即把 HQL 操作映射为 Spark 的 RDD 或 DataFrame 转换操作。
- 计算执行层:由 Spark 集群负责实际的计算任务(包括 Shuffle、Join 等操作),充分利用 Spark 的内存迭代计算能力。
- 数据存储层:数据仍存储在 HDFS 或其他分布式存储系统中,支持 Hive 原生的数据格式(如 ORC、Parquet、TextFile 等)。
关键特点
- 完全兼容 Hive 生态:支持 Hive 的所有语法(如复杂的窗口函数、UDF、分区表、桶表等),原有 HQL 脚本无需修改即可直接运行。
- 性能提升显著:相比 MapReduce 引擎,Spark 的内存计算和 DAG 优化可将 HQL 执行速度提升 10-100 倍,尤其适合多阶段依赖的复杂查询。
- 部署依赖:需要在 Hive 中配置 Spark 相关依赖(如 Spark 的 JAR 包路径、Spark 集群地址),且需保证 Hive 与 Spark 版本兼容(如 Hive 3.x 通常兼容 Spark 2.x)。
适用场景
- 原有 Hive 用户希望提升查询性能,但不想改变现有的 HQL 开发习惯和数据模型。
- 以 Hive 为核心的数据仓库场景,需要处理大规模离线批处理任务(如 T+1 数仓的 ETL 流程)。
- 依赖 Hive 复杂功能(如动态分区、事务表)的业务场景。
二、Spark on Hive(Spark 基于 Hive 数据运行)
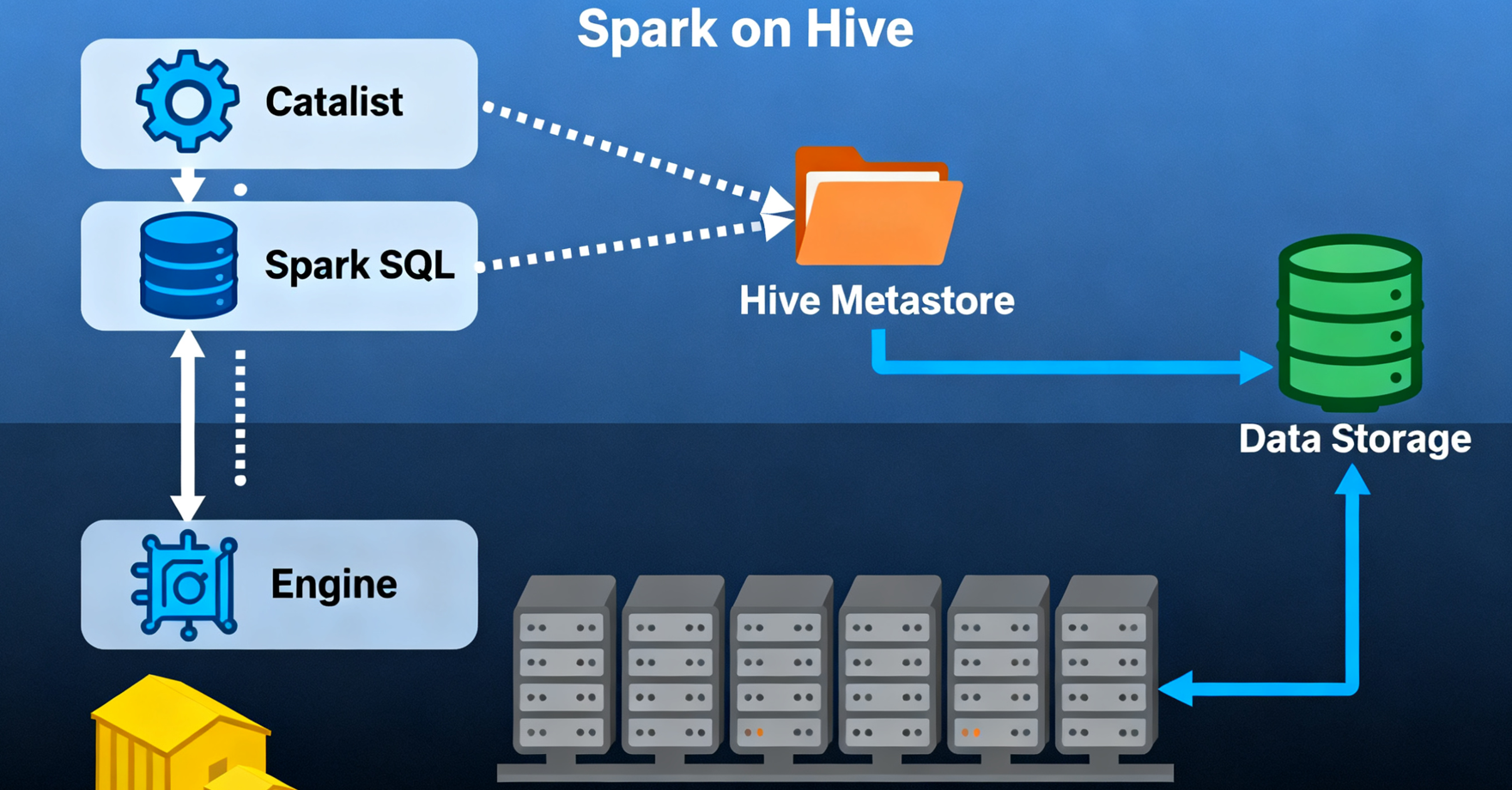
定义
Spark on Hive 是 Spark 作为主导框架,通过 Spark SQL 读取 Hive 的元数据(Metastore),直接操作 Hive 中的数据。此时 Hive 仅作为 “元数据管理器” 和 “数据存储层”,计算完全由 Spark 引擎负责。
核心架构
- 元数据访问:Spark 通过 Hive Metastore Client 连接 Hive 的 Metastore,获取 Hive 表的元数据(如字段类型、分区信息、数据存储路径)。
- SQL 解析层:用户提交的 SQL 由 Spark SQL 的 Catalyst 优化器进行解析、优化,并生成 Spark 可执行的物理计划。
- 计算执行层:由 Spark 引擎直接执行物理计划(基于 RDD 或 DataFrame),计算过程不依赖 Hive 的任何组件。
- 数据存储层:数据存储在 Hive 原有的存储路径(如 HDFS 上的
/user/hive/warehouse),支持 Hive 所有数据格式。
关键特点
- Spark 主导计算:完全依赖 Spark 的计算能力和优化器(Catalyst),支持 Spark 特有的功能(如 DataFrame/Dataset API、流处理、机器学习库 MLlib 等)。
- 兼容 Hive 数据:无需数据迁移即可直接读写 Hive 表,适合已有 Hive 数据湖的场景,实现 “一份数据,多种计算”。
- 语法兼容性:Spark SQL 与 HQL 高度兼容,但存在少量差异(如部分 UDF 实现、窗口函数语法细节),需注意适配。
适用场景
- 以 Spark 为主要计算框架的团队,需要处理 Hive 中的存量数据(如用 Spark SQL 查询 Hive 表,或用 Spark 进行机器学习时读取 Hive 中的特征数据)。
- 需结合 Spark 多场景处理能力的业务(如批处理与流处理结合、实时分析与离线计算共享 Hive 数据)。
- 希望利用 Spark 更丰富的 API(如 Scala/Python 编程接口)进行数据处理的场景。
三、核心区别对比
| 维度 | Hive on Spark | Spark on Hive |
|---|---|---|
| 主导框架 | Hive(以 HQL 为入口) | Spark(以 Spark SQL/API 为入口) |
| 计算引擎归属 | Spark 作为 Hive 的 “插件式” 计算引擎 | Spark 作为独立计算引擎,Hive 仅提供元数据和存储 |
| SQL 解析器 | Hive 原生解析器 | Spark SQL 的 Catalyst 优化器 |
| 元数据角色 | Hive Metastore 是核心组件(必选) | Hive Metastore 是可选的元数据来源 |
| 功能依赖 | 依赖 Hive 的所有功能(如 UDF、事务) | 不依赖 Hive 计算功能,仅复用其数据和元数据 |
| 典型使用方式 | hive -e "SELECT ..."(Hive 客户端) | spark-sql "SELECT ..."(Spark 客户端)或 Spark 代码中调用 |
总结
- Hive on Spark 本质是 “Hive 换引擎”,目标是加速 HQL 执行,适合以 Hive 为中心的场景。
- Spark on Hive 本质是 “Spark 用数据”,目标是让 Spark 复用 Hive 的数据和元数据,适合以 Spark 为中心的场景。
实际生产中,两者并非互斥,常结合使用:例如用 Spark on Hive 处理实时数据,同时用 Hive on Spark 运行历史 HQL 脚本,共同构建高效的大数据处理体系。
在实际工作中,Spark on Hive 的使用频率相对更高一些。
Hive on Spark 需要将 Hive 的计算引擎从默认的 MapReduce 替换为 Spark,配置相对复杂,且需要保证 Hive 与 Spark 版本兼容。虽然它能利用 Spark 内存计算的优势提升 Hive 的处理性能,但企业实际使用较少。
而 Spark on Hive 中,Spark 作为独立计算引擎,仅通过 Hive Metastore 获取元数据,直接操作 Hive 中的数据,配置相对简单,更适合以 Spark 为主的场景。企业中一般老任务都是 Hive SQL,新上的任务会使用 Spark SQL,这种情况下 Spark on Hive 就成为了很好的选择。此外,从一些企业的实践来看,如美团,Spark 正在逐步替代 MapReduce 作业,成为大数据处理的主流计算引擎,这也在一定程度上反映了 Spark on Hive 的使用更为广泛。

















 1870
1870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









