






 本文介绍了将Hive执行引擎从MapReduce切换到Spark的实践过程,包括遇到的问题、配置要点和注意事项。作者指出Hive on Spark的优势在于内存计算,避免磁盘I/O。配置中强调了Hive与Spark版本兼容性的重要性,以及Hive配置文件的修改,如`spark.yarn.jars`和`hive.execution.engine`等。文章还提供了上传Spark JAR到HDFS的命令,并提及启动Hive和测试的步骤。
本文介绍了将Hive执行引擎从MapReduce切换到Spark的实践过程,包括遇到的问题、配置要点和注意事项。作者指出Hive on Spark的优势在于内存计算,避免磁盘I/O。配置中强调了Hive与Spark版本兼容性的重要性,以及Hive配置文件的修改,如`spark.yarn.jars`和`hive.execution.engine`等。文章还提供了上传Spark JAR到HDFS的命令,并提及启动Hive和测试的步骤。
序言
不推荐这种方式,感觉HiveOnSpark的官网更新速度比较慢,同时HiveOnSpark的解决方案需要指定的Spark.Hive 这块并没有很好的做一个封装,造成我们部署中途问题点很多cuiyaonan2000@163.com
参考链接:
简介
总的来说是将Hive的执行引擎替换成spark.
默认的是MR,且我们在启动Hive的时候会看到如下的内容(所以我们应该用spark来做为执行引擎cuiyaonan2000@163.com)

既然要换成spark,那我们知道Hadoop自带的Mr是不能用了,且不包含spark的相关服务,所以配置修改,增加spark的jar就是必不可少的工作了.
其原因有一个大家最能说到的就是:HiveOnMr是是把中间结果写入硬盘,而HiveOnSpark是写入内存的cuiyaonan2000@163.com
根据官网的内容我们要注意,HiveOnSpark 的如下两点,
- spark放置到Hdfs中的jar不应包含hive的香相关jar
- hive on spark 默认基于spark on yarn模式
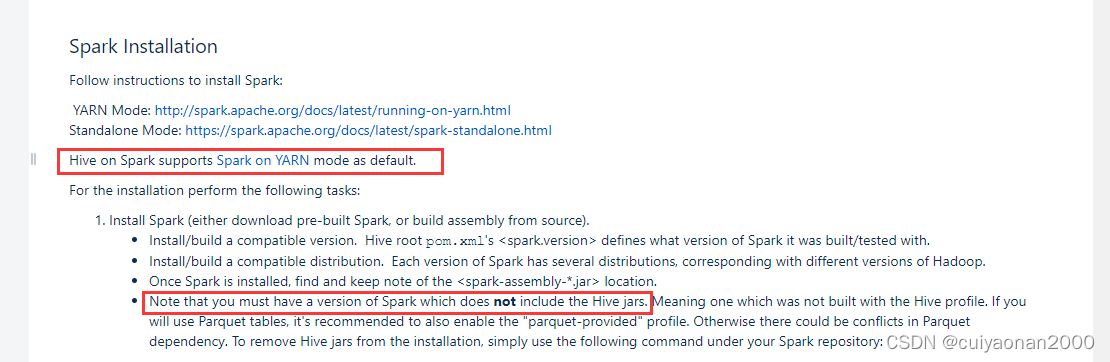
Spark与Hive的版本问题
按照官网:
https://cwiki.apache.org//confluence/display/Hive/Hive+on+Spark:+Getting+Started
以及很多的其它博主的分析我们知道,Hive On Spark该分支是在特定的Spark上进行的.所以版本的差异可能决定了你的最终结果cuiyaonan2000@163.com
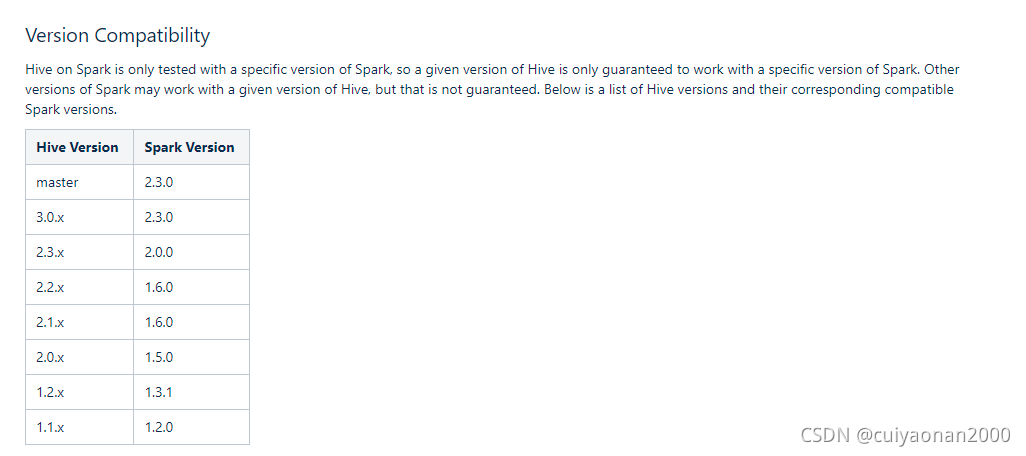
Hive配置文件
这里只说明针对Hive On MR不一样的的配置信息,其它的先关配置跟Hive On MR是一样的.
<!--Spark依赖的JAR位置,下面会介绍如何上传jar包的hdfs路径-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://127.0.0.1:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎,使用spark-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!--Hive连接spark-client超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>30000ms</value>
</property>SparkJars
下载下来的Spark的lib包下,可以看到有很多的hive的jar.但是我们除了hive-storage-api-2.7.2.jar都是不需要的.所以要先删除这些hive包,然后在把lib目录下的包都上传到指定的hdfs中
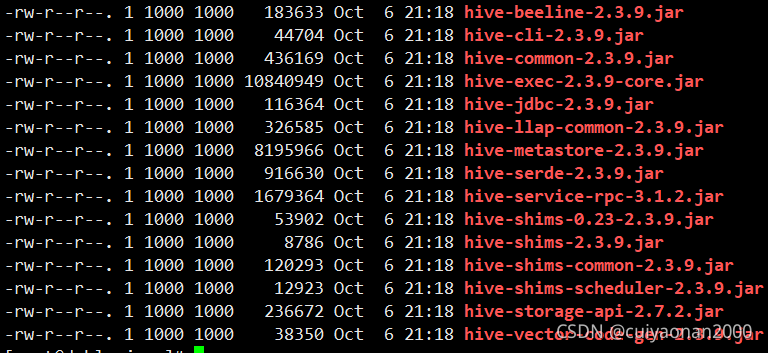
相关命令
#该目录存储sparks的jar
[root@cuiyaonan2000 jars]# hdfs dfs -mkdir -p /spark-jars
[root@cuiyaonan2000 jars]# hdfs dfs -put ./myjars/* /spark-jars
#该目录存储spark日志,后面会用到
[root@cuiyaonan2000 jars]# hdfs dfs -mkdir -p /spark-log
Spark-default.conf
在Hive的conf下创建该spark-default.conf并添加如下内容
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://ip:8020/spark-log
spark.executor.memory 4g # 每个执行程序进程使用的内存量。
spark.driver.memory 4g # 分配给远程Spark上下文(RSC)的内存量。我们推荐4GB
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.executor.cores 2 #每个执行者的核心数量。
spark.yarn.driver.memoryOverhead 400m #我们推荐400(MB)启动
nohup bin/hive --service metastore &
nohup bin/hive --service hiveserver2 &
测试
使用hive bin目录下的beeline测试,后一定要insert成功否则不能验证.



















 1247
1247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











