




 DGRNets是一种创新的深度学习模型,用于端到端的6自由度视觉定位和里程计任务。它通过辅助学习的方式,同时预测相对位姿和绝对位姿,有效解决了视觉里程计任务中的累积误差问题,提高了相机重定位性能。在Microsoft7-Scenes和KITTI数据集上的测试显示,DGRNets在位姿预测精度和户外大场景VO性能方面均表现出色。
DGRNets是一种创新的深度学习模型,用于端到端的6自由度视觉定位和里程计任务。它通过辅助学习的方式,同时预测相对位姿和绝对位姿,有效解决了视觉里程计任务中的累积误差问题,提高了相机重定位性能。在Microsoft7-Scenes和KITTI数据集上的测试显示,DGRNets在位姿预测精度和户外大场景VO性能方面均表现出色。
DGRNets:Deep Global-Relative Networks for End2End 6-DoF VisualLocalization and Odometry
作者: Yimin Lin1, Zhaoxiang Liu1, Jianfeng Huang1Chaopeng Wang1, Guoguang Du1, Jinqiang Bai2,Shiguo Lian1, Bill Huang1
研究机构:cloudmind、北航
这是一个辅助学习的相机位姿估计模型,以序列数据为输入,同时预测相对位姿和绝对位姿。
因此除了可以作为相机位姿估计器之外,还可以解决VO(视觉里程计)任务。
在视觉里程计任务中,由于还预测了相机的绝对位姿,因此可以避免累计误差带来的漂移。
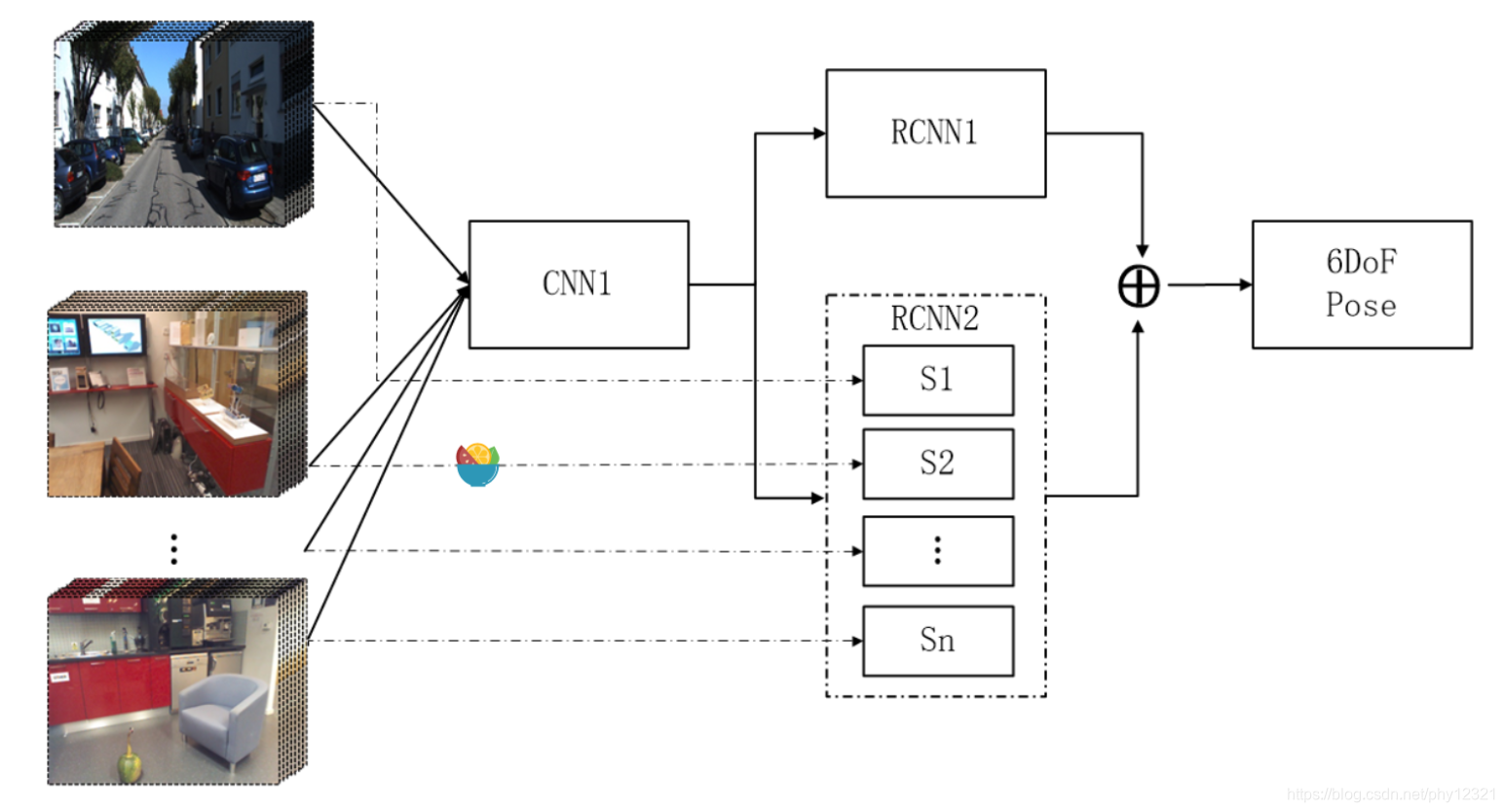
模型结构
模型由三个网络组成:
- CNN1: 负责进行图像的特征提取,选择具有分辨性的特征输入到后面的网络中
- RCNN1: 这里 RCNN指的是Recurrent Convolutional Neural Networks,即循环神经网络,在本文中作者使用了LSTM。
- RCNN2:也是LSTM,负责估计每张图像中相机的绝对位姿变换
最终将RCNN1和RCNN2的输出通过全连接层融合,分别得到相机的位置和旋转。网络结构:
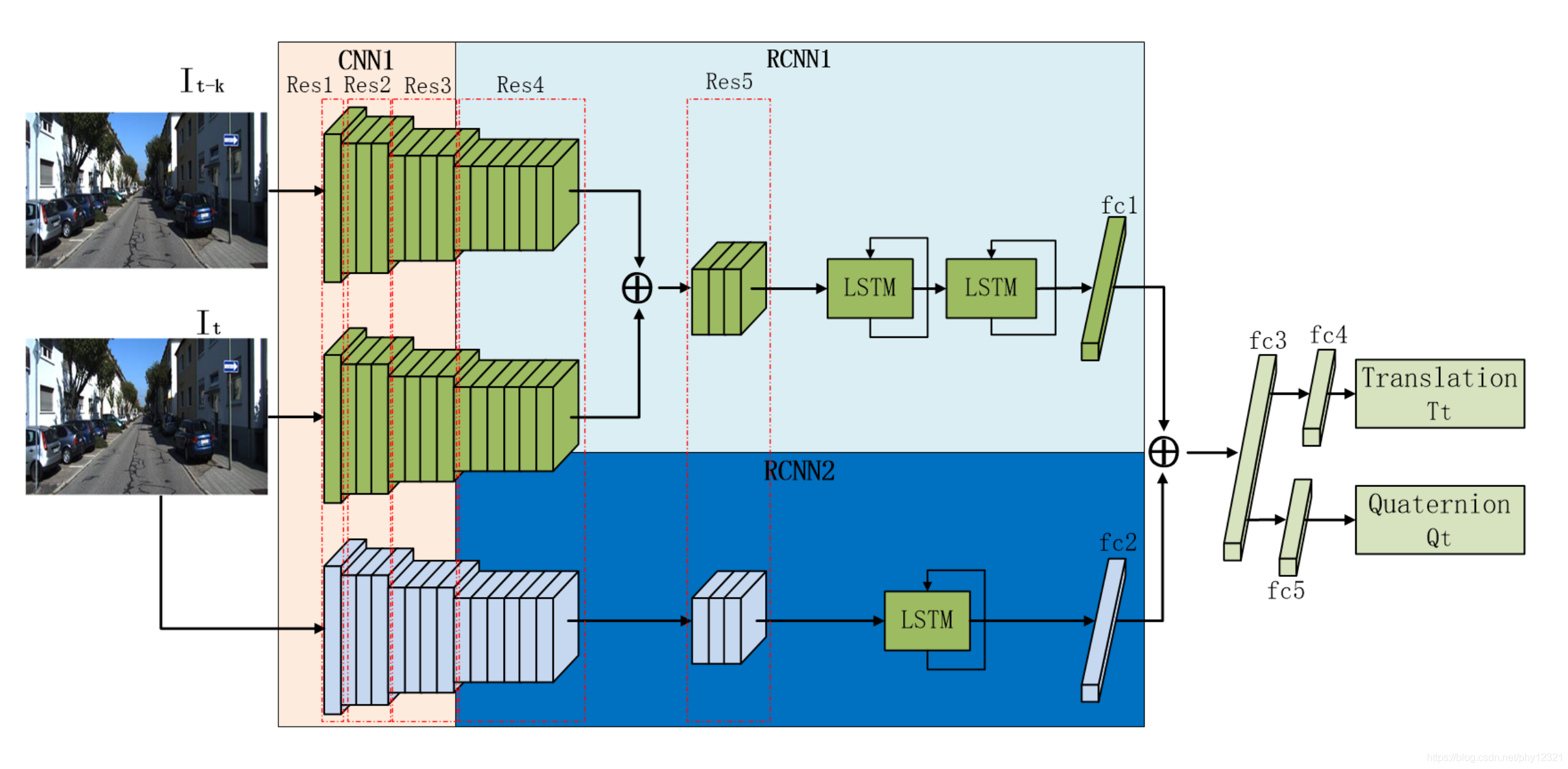
CNN1:
- 作为特征提取网络,由ResNet50的前三个残差块Res1,Res2,Res3构成。
- CNN1分别对每张图像进行处理提取特特征用于后续网络
RCNN1:
- 相对位姿估计网络。使用Res4、Res5将两个图像的特征进行连接融合,然后使用两个LSTM单元挖掘长距离图像之间的对应关系。在每个时间步通过一个1024维的全连接层输出位姿预测。
RCNN2:
-
绝对位姿估计网络。使用Res4、Res5处理当前图像的特征,然后用一个LSTM估计绝对位姿。最后一个1024维的全连接层将输入reshape为1024,与相对位姿预测数据相匹配。
-
注意,论文提到,LSTM存储了最近时间内过去几帧的绝对位姿数据,因此能够提高绝对位姿的预测精度。
最后将fc1、fc2的输出连接,使用fc3,fc4,fc5进行融合,得到位姿的估计值。
训练
以往的基于学习的位姿估计方法在切换到新的场景时需要重新训练,费时费力。本文指出DGRNets可以加快在未知场景中的训练速度。
CNN1只负责提通用特征,因此不需重新训练。只要重新训练RCNN2即可,因为RCNN2存储的是场景中的地标信息。这样CNN1+RCNN2的组合就可以用于输出相机的绝对位姿估计了。
两个损失函数:
-
CTC loss: Cross Transformation Constraints loss,利用相邻帧之间的几何一致性对模型的相对位姿估计误差进行约束。
假设一个序列为一个样本,一个样本有5张图像,则相对位姿预测值PijP_{ij}Pij如下图:
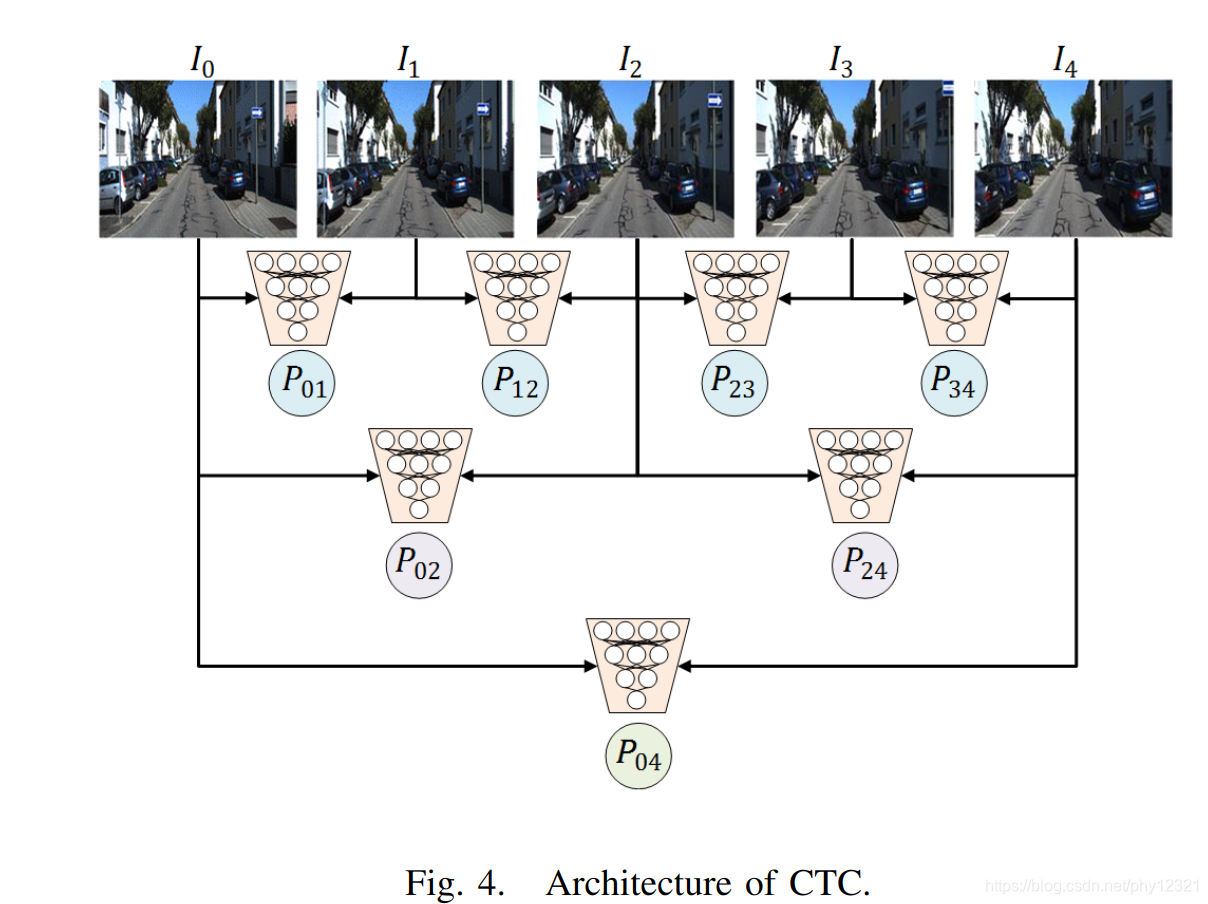
定义CTC损失函数:
1N∑i=1N∑k=06Lki, N为样本数,其中:L0=∣∣P01−P⌢01∣∣22L1=∣∣P12−P⌢12∣∣22L2=∣∣P23−P⌢23∣∣22L3=∣∣P34−P⌢34∣∣22L4=∣∣P02−P⌢02∣∣22L5=∣∣P04−P⌢04∣∣22 \frac1{N}\sum_{i=1}^N\sum_{k=0}^6 L_k^i \quad ,\ N为样本数,其中: \\ L_0 =|| P_{01}-\overset{\frown} P_{01}||^2_2 \\L_1 =|| P_{12}-\overset{\frown} P_{12}||^2_2\\ L_2 =|| P_{23}-\overset{\frown} P_{23}||^2_2\\ L_3 =|| P_{34}-\overset{\frown} P_{34}||^2_2\\ L_4 =|| P_{02}-\overset{\frown} P_{02}||^2_2\\ L_5 =|| P_{04}-\overset{\frown} P_{04}||^2_2\\ N1i=1∑Nk=0∑6Lki, N为样本数,其中:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6万+
6万+





 到【灌水乐园】发言
到【灌水乐园】发言







