




 本文介绍了华为秦通提出的轻量化自动驾驶定位框架。该框架包括车端建图、云端地图融合与压缩以及用户端定位。车端通过语义分割、逆投影变换和位姿图优化构建语义地图;云端则进行地图融合更新与压缩存储;用户端通过地图解压和ICP定位实现精确导航。实验结果显示,该方法有效且地图压缩后仍能保持高精度。
本文介绍了华为秦通提出的轻量化自动驾驶定位框架。该框架包括车端建图、云端地图融合与压缩以及用户端定位。车端通过语义分割、逆投影变换和位姿图优化构建语义地图;云端则进行地图融合更新与压缩存储;用户端通过地图解压和ICP定位实现精确导航。实验结果显示,该方法有效且地图压缩后仍能保持高精度。
华为 秦通
本文贡献:
- 提出了一种用于自动驾驶的轻量化定位框架,包括车端建图,云端维护、融合、压缩,以及用户端定位。
- 使用传感器丰富的地图采集车或者robotaxi来收集更新地图,使用户车收益
- 实车验证所提出方案的有效性
一、车端建图
语义分割
使用语义分割网络获得当前图像中的语义分割结果,然后根据优化的相机位姿将其投影到世界坐标系中。
本文从使用的是基于CNN的语义分割网络(应该是区别于transformer),类似于以下几个网络:

分割类别:ground, lane line, stop line, road marker, curb(路牙), vehicle, bike, and human,
其中 ground, lane line, stop line, and road marker are used for semantic mapping.其他类别被用于其他自动驾驶任务
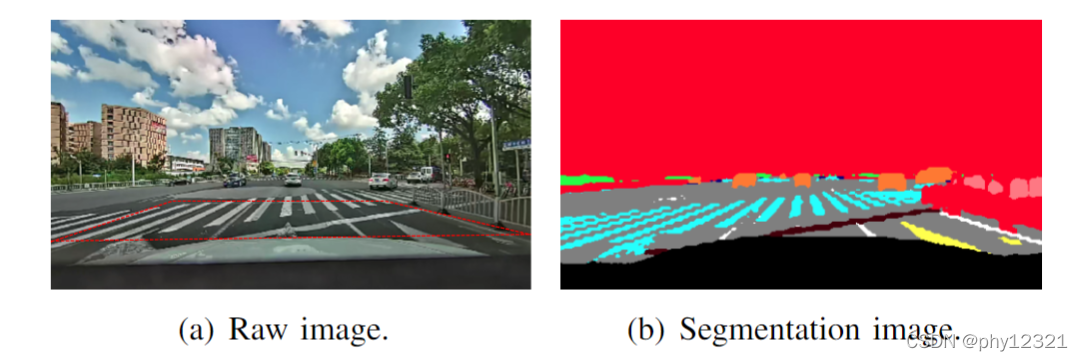
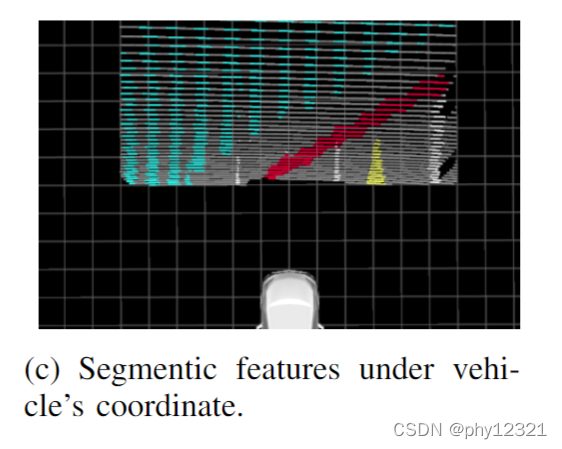
反向投影变换 Inverse Perspective Mapping (IPM)
根据图像的消影点实现逆投影变换,但是由于感知噪声,场景距离越远,误差越大,所以本文只考虑ROI之内的像素进行变换(上图红框之内)。投影变换公式:
1λ[xvyv1]=[Rctc]col:1,2,4−1πc−1([uv1]) \frac{1}{\lambda}\left[\begin{array}{c} x^{v} \\ y^{v} \\ 1 \end{array}\right]=\left[\begin{array}{ll} \mathbf{R}_{c} \mathbf{t}_{c} \end{array}\right]_{c o l: 1,2,4}^{-1} \pi_{c}^{-1}\left(\left[\begin{array}{l} u \\ v \\ 1 \end{array}\right]\right) λ1⎣⎡xvyv1⎦⎤=[Rctc]col:1,2,4−1πc−1⎝⎛⎣⎡uv1⎦⎤⎠⎞
其中函数π−1\pi^{-1}π−1是主要的逆投影变换,Rc, Tc是相机到车辆坐标系中心的外参
位姿图优化
采用GNSS + 局部里程计的方法优化位姿。
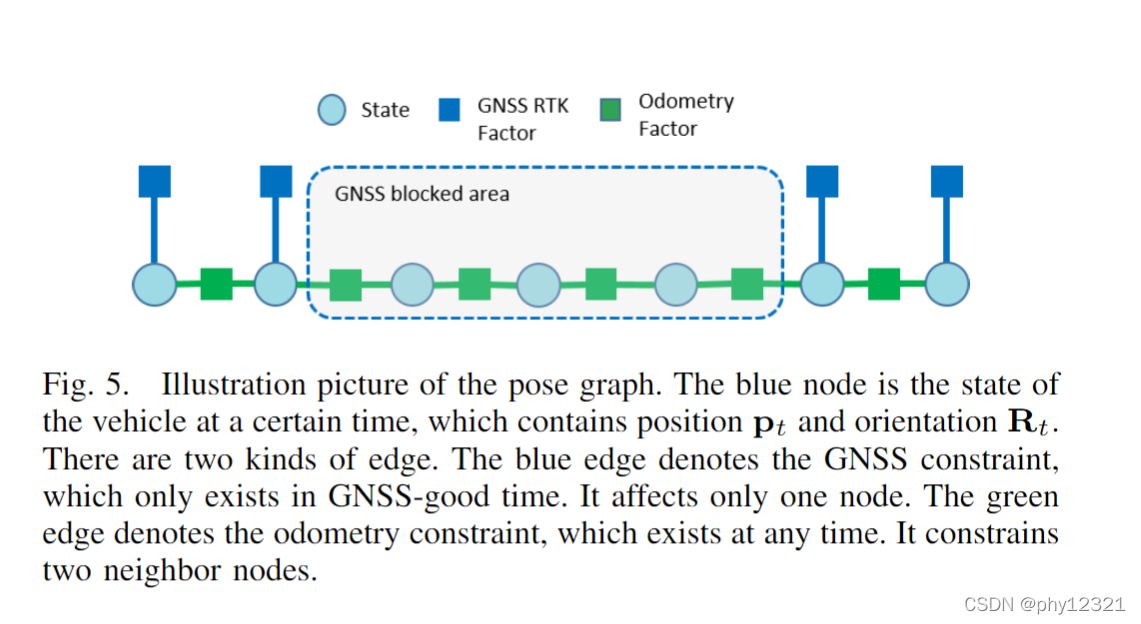
在GNSS信号好的地方最小化与GNSS信号的距离,在GNSS信号不好的地方最小化与里程计的距离:
mins0…sn{
∑i∈[1,n]∥ro(si−1,si,m^i−1,io)∥σ2+∑i∈G∥rg(si,m^ig)∥σ2}, \min _{\mathbf{s}_{0} \ldots \mathbf{s}_{n}}\left\{\sum_{i \in[1, n]}\left\|\mathbf{r}_{o}\left(\mathbf{s}_{i-1}, \mathbf{s}_{i}, \hat{\mathbf{m}}_{i-1, i}^{o}\right)\right\|_{\sigma}^{2}+\sum_{i \in \mathcal{G}}\left\|\mathbf{r}_{g}\left(\mathbf{s}_{\mathbf{i}}, \hat{\mathbf{m}}_{i}^{g}\right)\right\|_{\boldsymbol{\sigma}}^{2}\right\}, s
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2269
2269


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








