







文章目录
摘要: 数据建模工具-PDManer使用技巧-模型层
关键词: 数据建模 数据治理 数据模型 数据字典 数据血缘
一、总体介绍
在数据治理过程中,我们经常和数据模型打交道,这时候我们就需要一个好的工具,来完成建模这个过程,PDManer就是本文的主角。
在数据治理过程中,分成贴源层、模型层、指标层等,这里介绍下模型层怎么使用工具:
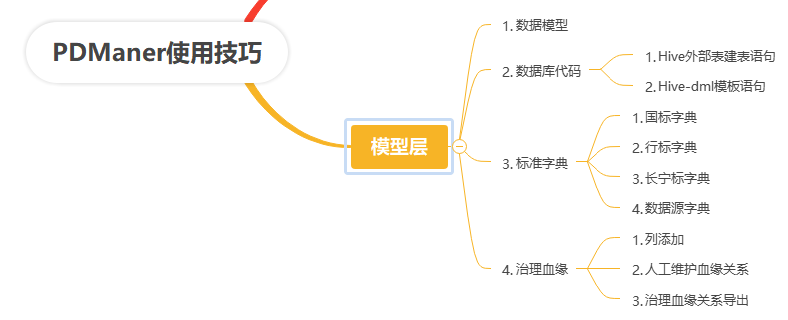
二、使用技巧
2.1、模型层
2.2.1、数据模型
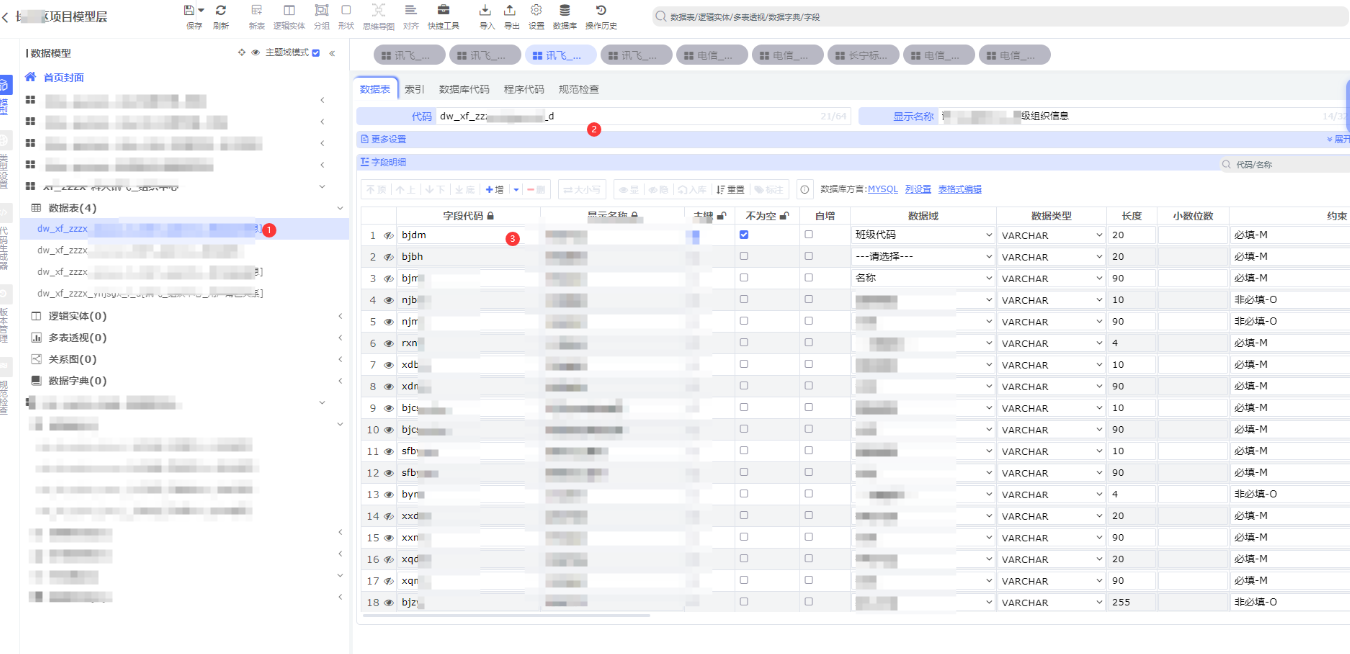
模型层的数据模型,不再是从数据库解析导入了,而是自己创建,
这里创建项目、数据域等过程和贴源层一样
依次点击:①新增模型 -> ②填写表名 -> ③填写字段名
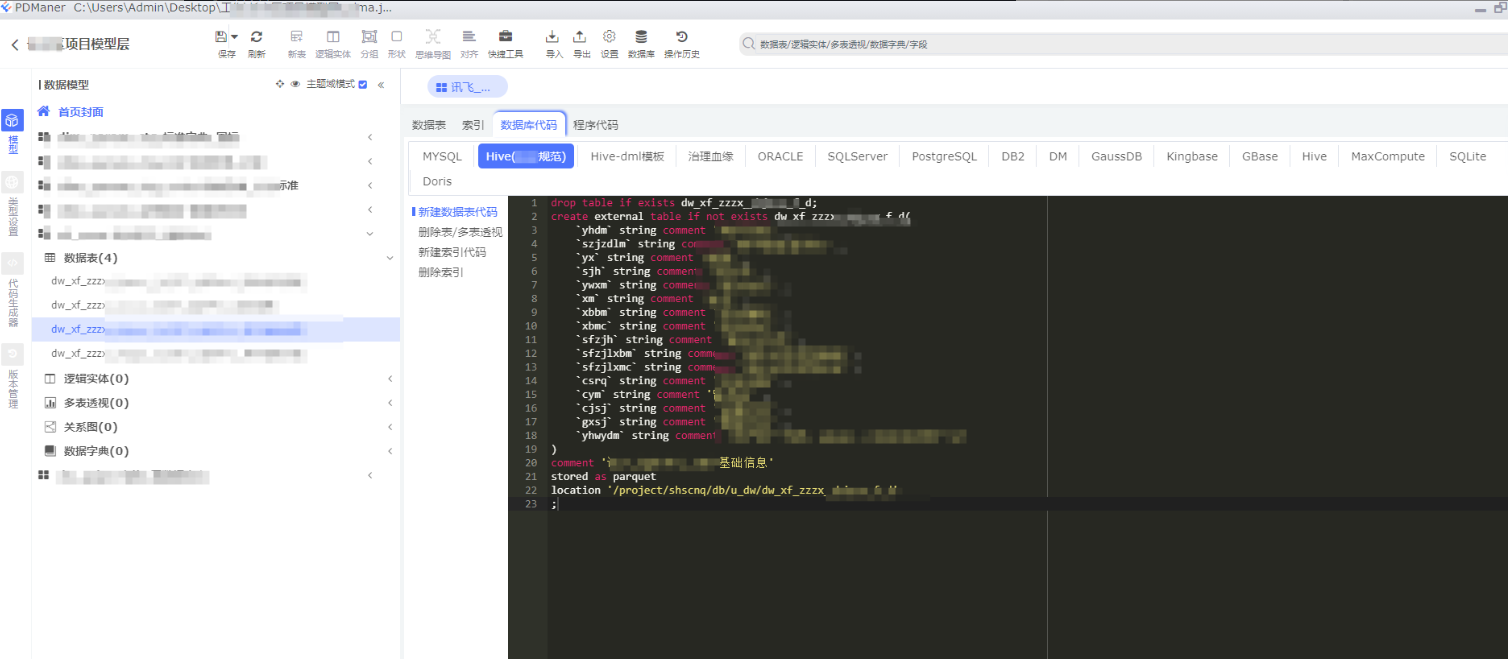
2.12、数据库代码
a、Hive外部表建表语句
模型层有自己的规范
建表语句的新增方式和贴源层一致,具体代码如下:
drop table if exists {{=it.entity.defKey}};
create external table if not exists {{=it.entity.defKey}}(
{{ pkList = [] ; }}
{{~it.entity.fields:field:index}}
`{{=it.func.lowerCase(field.defKey)}}` string comment '{{=it.func.join(field.defName,field.comment,';')}}' {{= index < it.entity.fields.length-1 ? ',' : ( pkList.length>0 ? ',' :'' ) }}
{{~}}
{{? pkList.length >0 }}
{{?}}
)
{{
let partitionedBy = it.entity.properties['partitioned by'];
partitionedBy = partitionedBy?partitionedBy:'请在扩展属性中配置[partitioned by]属性';
}}
comment '{{=it.func.join(it.entity.defName,';') }}'
stored as parquet
location '/project/shscnq/db/u_dw/{{=it.entity.defKey}}'
;
显示效果如下:
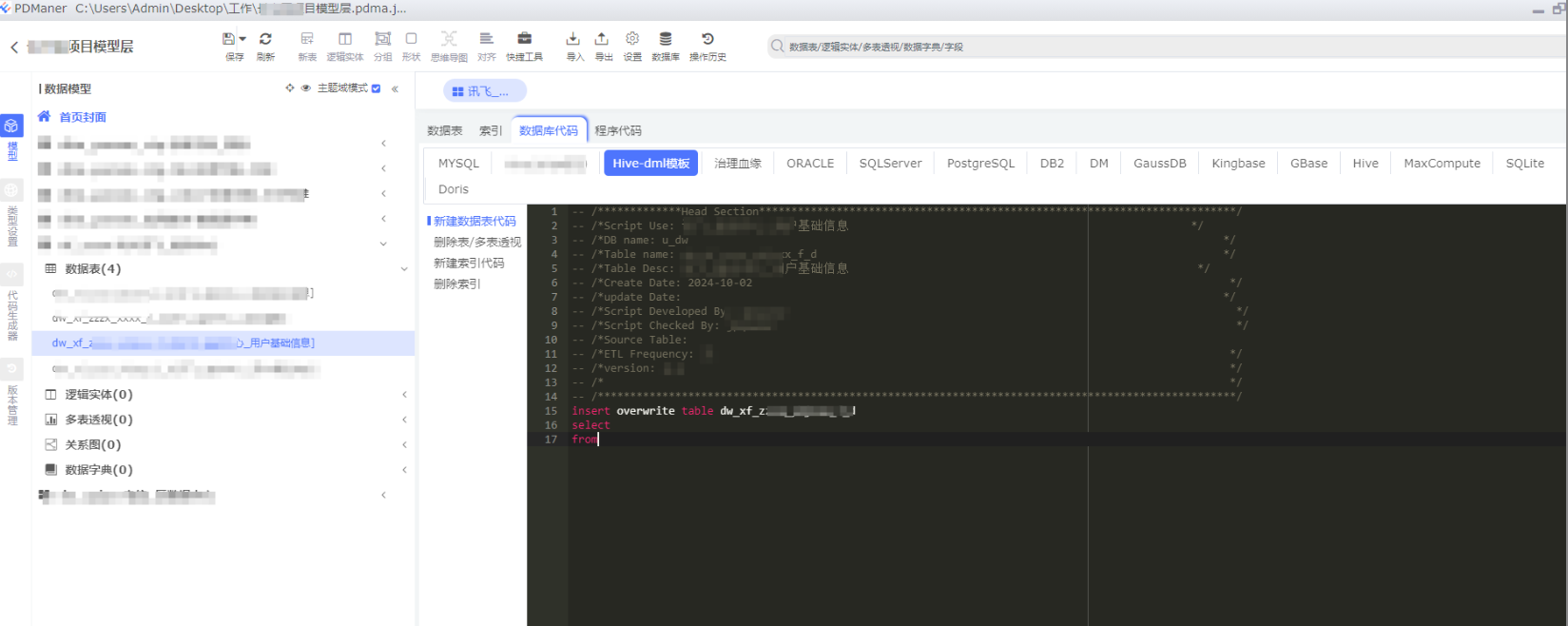
b、Hive-dml模板语句
当我们做数据开发时,我们需要一个统一的sql开发模板,这样我们就可以自己新增一个,具体代码如下
-- /*************Head Section**************************************************************************/
-- /*Script Use: {{=it.func.join(it.entity.defName,';') }} */
-- /*DB name: u_dw */
-- /*Table name: {{=it.entity.defKey}} */
-- /*Table Desc: {{=it.func.join(it.entity.defName,';') }} */
-- /*Create Date: {{=(new Date).getFullYear()}}-{{=('0' + ((new Date).getMonth() + 1)).slice(-2)}}-{{=('0' + (new Date).getDate()).slice(-2)}} */
-- /*update Date: */
-- /*Script Developed By: xxxxx */
-- /*Script Checked By: xxxxx */
-- /*Source Table:
-- /*ETL Frequency: 日 */
-- /*version: 1 */
-- /* */
-- /***************************************************************************************************/
insert overwrite table {{=it.entity.defKey}}
select
from
显示效果如下:
2.1.3、标准字典
做模型层开发的时候,最重要的一点就是把字段转化成标准的字典,然后标准的整理和分类就需要在PDmaner里做好,并且这个也是前面字典转换的目标表和目标字典。
字典单独新建主题域,因为各个主题是共用标准字典的
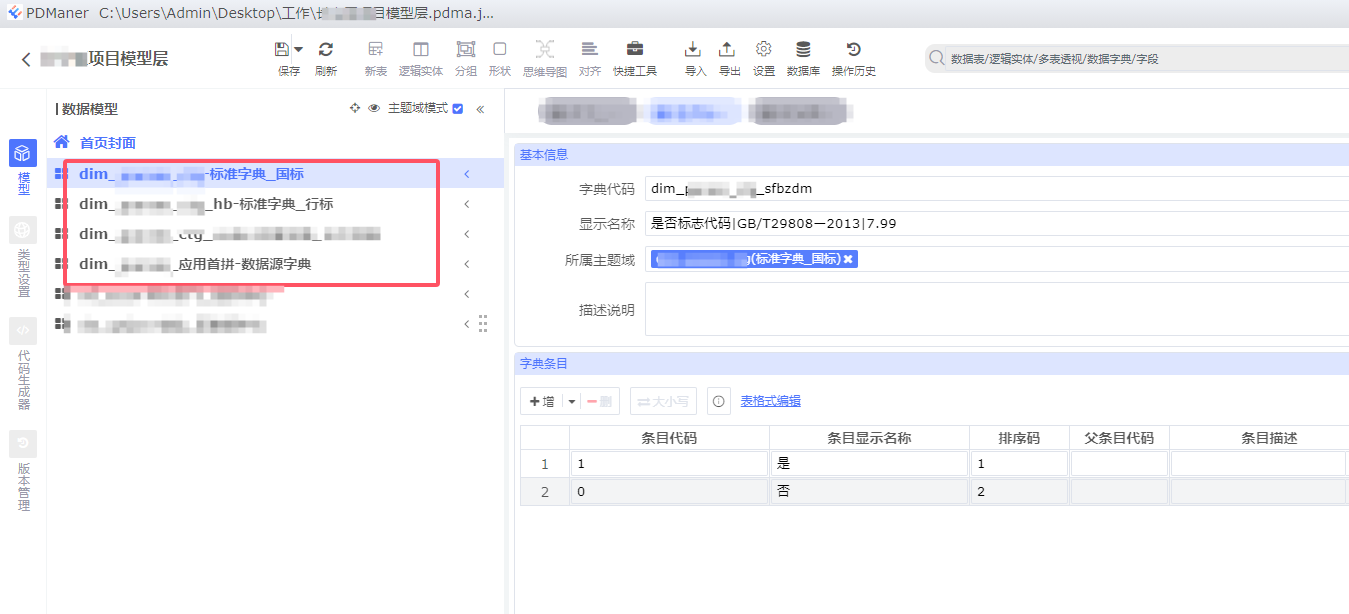
字典在表中标记
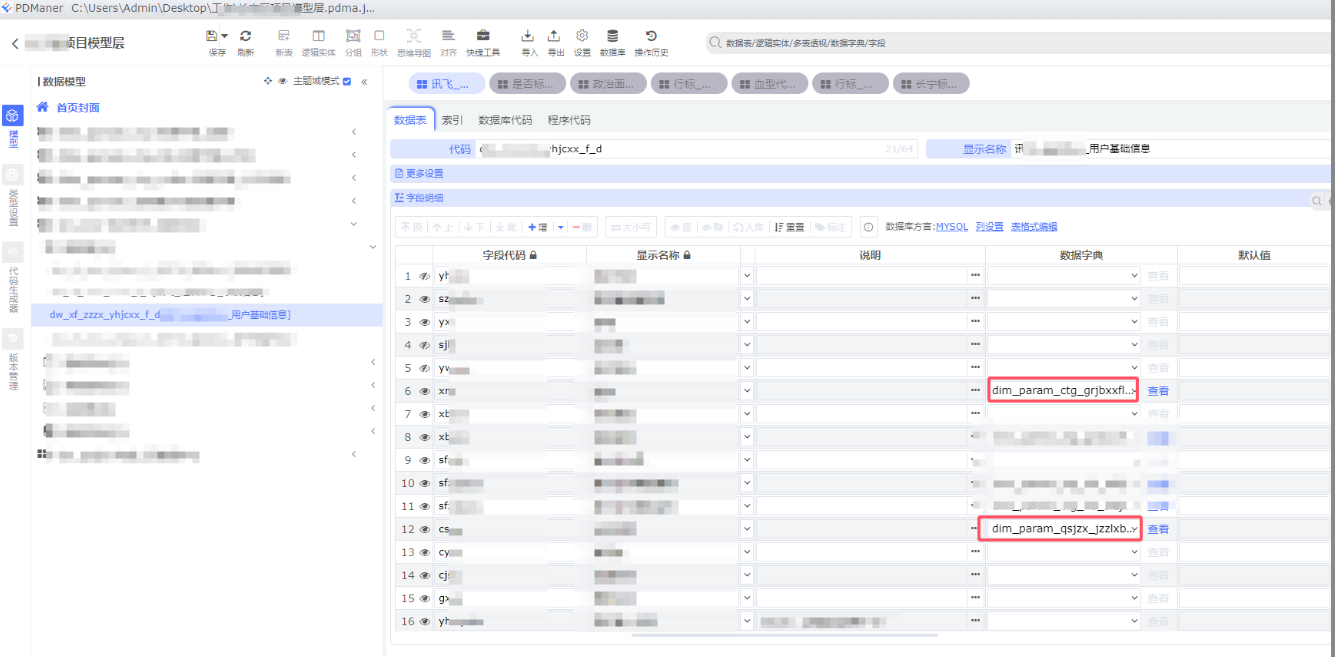
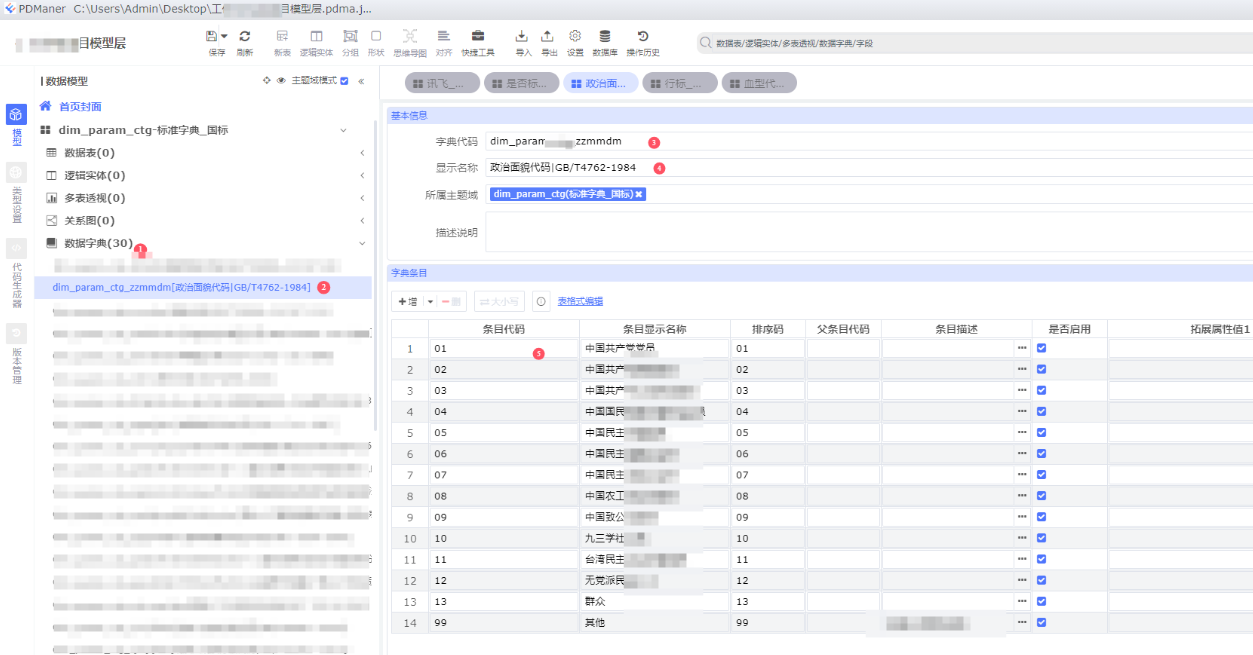
a、国标字典
国标字典,这里的命名方式是 “dim_parm_ctg_*” 主要是记录国家标准的字典,一般是 “GB/T”
示例图如下:
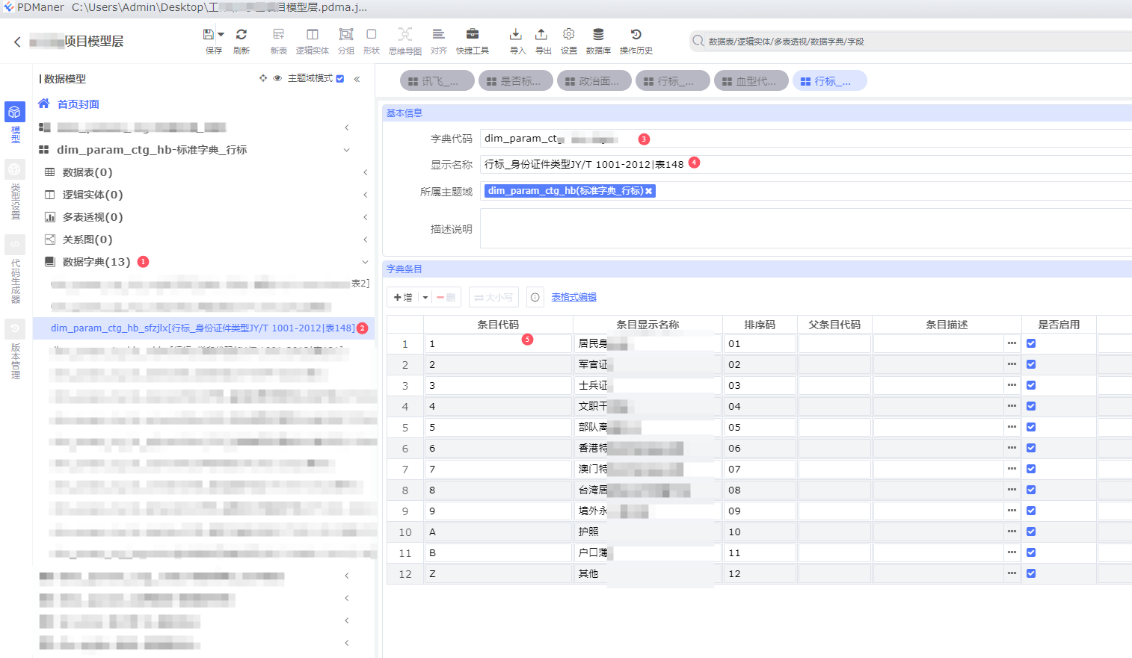
b、行标字典
行标字典,这里的命名方式是 “dim_parm_ctg_hb_*” 主要是记录教育行业的标准的字典,一般是 “JY/T”
示例图如下:
c、数据源字典
为什么在模型层还有数据源字典,因为有些字典是数据源自定义的,并且在国标、行标、都找不到合适的字典,就只能沿用应用自己的数据源字典,这个只需要把贴源层的字典复制粘贴过来就可以了。
2.2.4、治理血缘
治理过程中,我们主要是记录模型层,也就是做数据规整的数据血缘,血缘关系比较简单,只有贴源层主表和治理填充表,后续的宽表层数据血缘太复杂,不适合在此记录。
首先新增数据血缘需要的列
依次点击:①点击设置 -> ②表设置的列设置 -> ③按照如图所示,新增修改列名
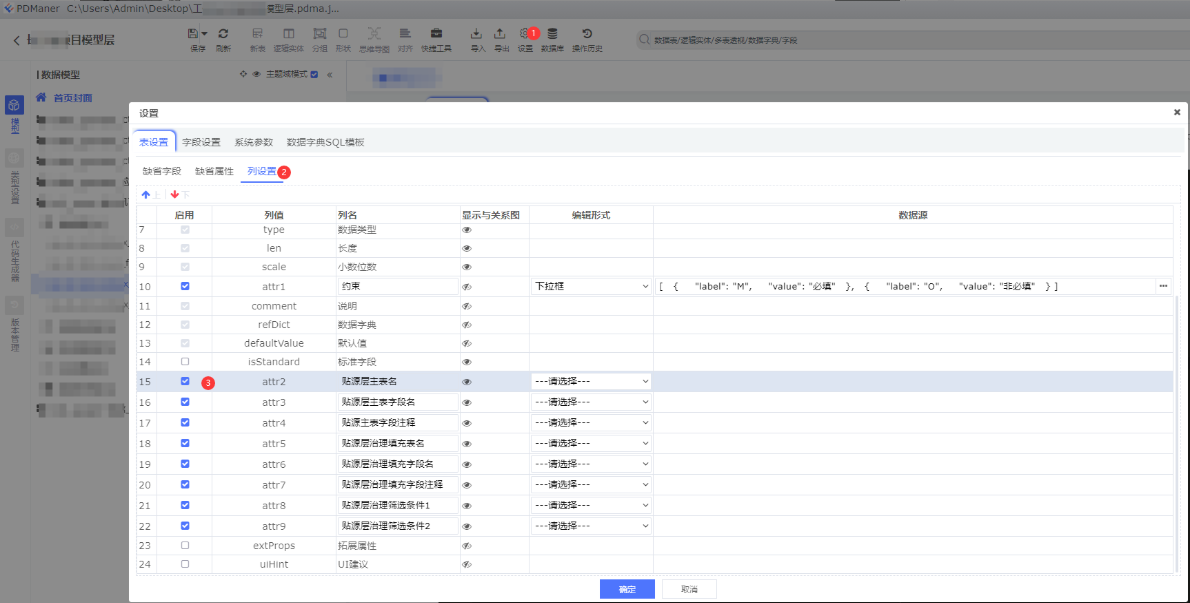
b、人工维护血缘关系
需要人工维护血缘关系,这里会有人觉得麻烦,或者没必要,这么维护有几大优势:
1.只需要看这个模型文件就可以知道血缘关系,不需要翻代码。
2.这个对应关系,可以帮助我们梳理字段关系,和血缘治理逻辑,开发的时候,会更容易。
3.这个数据血缘可以导出,然后把相关表的中文关系,去除技术性很强的部分,可以给非技术人员使用。
可以看到下图中,前面新增的列,都写了数据规整的血缘

c、治理血缘关系导出
首先导出去的表需要数据表存储,表结构如下
血缘总表
create table SYS_BLOOD
(
table_name varchar(255) null comment '表名',
table_comment varchar(255) null comment '表注释',
source_table_name varchar(255) null comment '来源表名',
source_table_comment varchar(255) null comment '来源表注释'
)
comment '血缘总表';
血缘明细表
create table SYS_BLOOD_ITEM
(
table_name varchar(255) null comment '表名',
table_comment varchar(255) null comment '表注释',
column_name varchar(255) null comment '字段名',
column_comment varchar(255) null comment '字段注释',
source_table_name varchar(255) null comment '贴源层主表名',
source_column_name varchar(255) null comment '贴源层主表字段名',
source_column_comment varchar(255) null comment '贴源主表字段注释',
govern_table_name varchar(255) null comment '贴源层治理填充表名',
govern_column_name varchar(255) null comment '贴源层治理填充字段名',
govern_column_comment varchar(255) null comment '贴源层治理填充字段注释',
govern_where1 varchar(255) null comment '贴源层治理筛选条件1',
govern_where2 varchar(255) null comment '贴源层治理筛选条件2'
)
comment '血缘明细表';
导出需要在数据类型添加,和建表语句和dml语句一样
具体代码如下:
{{~it.entity.fields:field:index}}
INSERT INTO SYS_BLOOD(table_name,table_comment,source_table_name,source_table_comment) VALUES( '{{=it.entity.defKey}}','{{=it.entity.defName}}','{{=it.func.lowerCase(field.attr2)}}','{{=it.func.lowerCase(field.attr3)}}');
{{~}}
{{~it.entity.fields:field:index}}
INSERT INTO SYS_BLOOD_ITEM(table_name,table_comment,column_name,column_comment,source_table_name,source_column_name,source_column_comment,govern_table_name,govern_column_name,govern_column_comment,govern_where1,govern_where2) VALUES( '{{=it.entity.defKey}}','{{=it.entity.defName}}','{{=it.func.lowerCase(field.defKey)}}','{{=it.func.lowerCase(field.defName)}}','{{=it.func.lowerCase(field.attr2)}}','{{=it.func.lowerCase(field.attr3)}}','{{=it.func.lowerCase(field.attr4)}}','{{=it.func.lowerCase(field.attr5)}}','{{=it.func.lowerCase(field.attr6)}}','{{=it.func.lowerCase(field.attr7)}}','{{=it.func.lowerCase(field.attr8)}}','{{=it.func.lowerCase(field.attr9)}}');
{{~}}
依次点击:①点击模型表 -> ②点击数据库代码 -> ③刚刚增加的血缘代码 -> ④得到血缘的插入语句
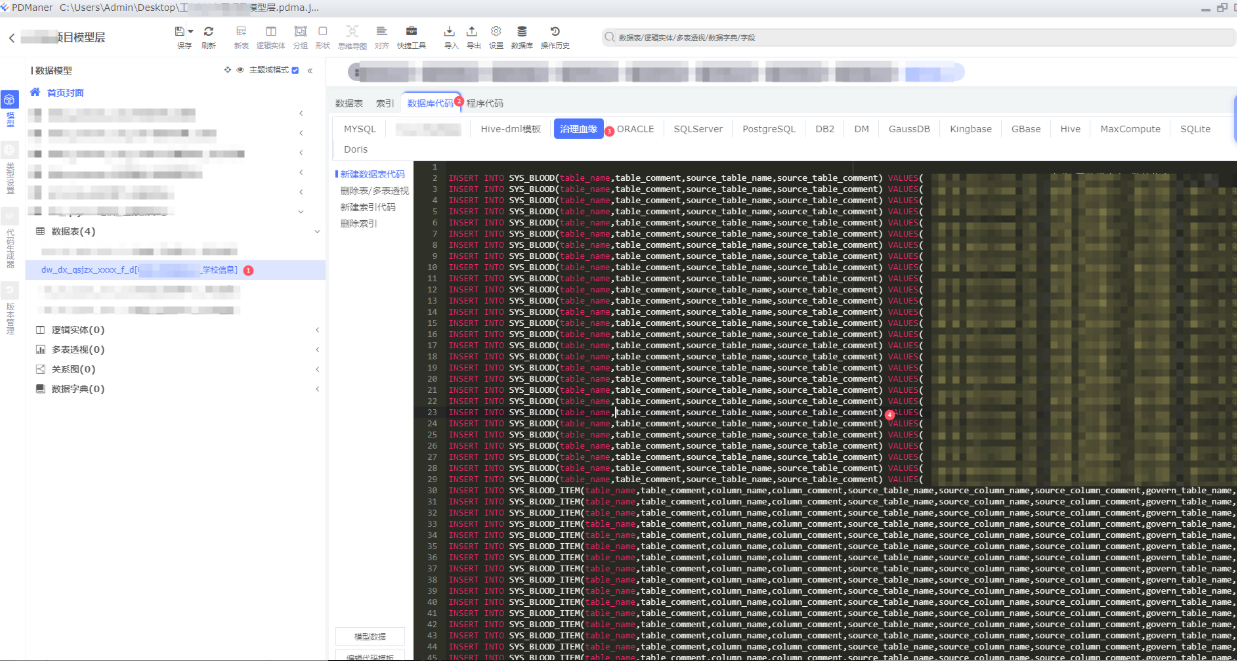
到这我们把所有的插入语句插入到表里,就能得到所有血缘关系了。



















 5606
5606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











